





Best AI Models — June 2026 Leaderboard: Ranked, Compared, Honest Verdicts
Claude Opus 4.8 took the #1 spot on the Artificial Analysis Intelligence Index on May 28, 2026. Score: 61.4. That makes it the first model to break above 60 by a clean margin — and the first time since GPT-5.5's April release that Anthropic has held the top of the Index. By June 1, it had also retaken first place on the GDPval-AA real-world economic-task benchmark with an Elo of 1,890 — 121 points ahead of GPT-5.5 in second.
That single sentence buries everything that actually matters about the June 2026 model landscape. Opus 4.8 is #1 on overall intelligence and coding. It is not the best at multimodal — Gemini 3.1 Pro wins that. It is not the best value — DeepSeek V4-Pro destroys it on cost-per-intelligence. It is not the best open-weight model — Step 3.7 Flash and Kimi K2.6 are the rational picks if you need Apache or MIT licensing. And it is not the cheapest to run high-volume agent workloads on — that's a different conversation again.
This is the comprehensive June 2026 leaderboard. Ten frontier models ranked across coding, agentic workflows, reasoning, long-context, multimodal, speed, and pricing. Every claim sourced. Category winners called out individually. Cost-per-intelligence math. And the honest recommendation for which model you should actually use for which workload.
1. The June 2026 master leaderboard
Ten frontier models, ranked by Artificial Analysis Intelligence Index v4.0 — the most comprehensive composite benchmark currently available. AA Index aggregates 10 evaluations across reasoning, coding, agentic tool use, science, and long-context retrieval.
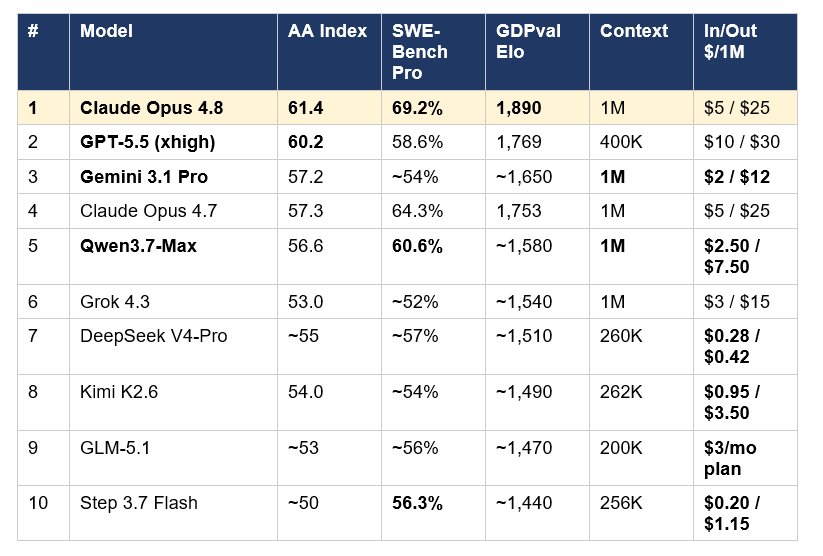
Three patterns to read in that table. First, the top tier (positions #1-#3, Index 57+) is now a three-way race between Anthropic, OpenAI, and Google. The gap from Opus 4.8 at 61.4 to Gemini 3.1 Pro at 57.2 is 4.2 points — meaningful, but small enough that workload selection matters more than picking the leader. Second, the Chinese frontier (Qwen3.7-Max, DeepSeek V4-Pro, Kimi K2.6, GLM-5.1, Step 3.7 Flash) clusters in the 50-57 Index range — close enough to Western frontier models that the cost difference becomes the dominant decision factor for high-volume workloads. Third, every closed-source model with an Index above 53 costs at least $3 per million output tokens, while every open-source frontier model costs less than $4 per million — the price discrimination between closed and open weights has held remarkably stable through 2026.
All numbers in this leaderboard are sourced from Artificial Analysis (June 1, 2026 snapshot), Anthropic's official launch posts, model providers' published cards, and independent verification on Hugging Face, OpenRouter, and Together AI. For the previous month's snapshot and how the field has moved, our May 2026 leaderboard at Build Fast with AI tracks the shifts release by release.
2. Category winners — overall, coding, agents, reasoning, multimodal, budget
The honest answer to 'which AI model is the best?' is that it depends entirely on the workload. Here is the category-by-category breakdown with the specific reason each winner wins:
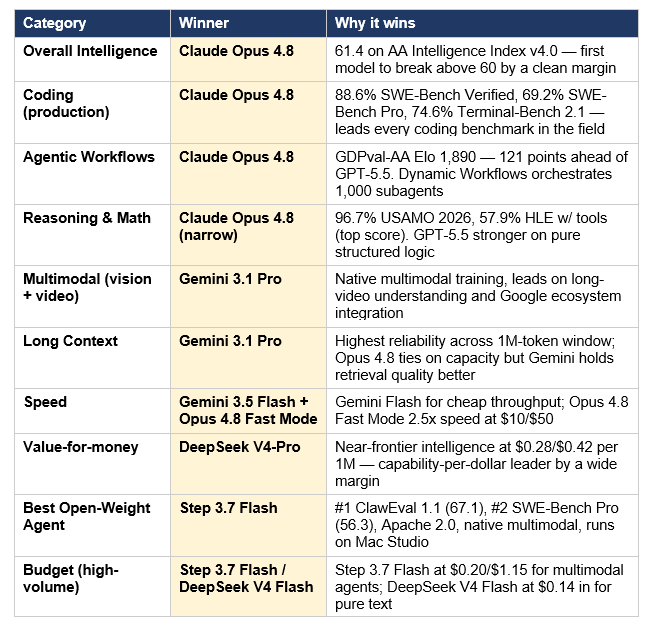
Read that table carefully. Claude Opus 4.8 wins four categories outright — overall intelligence, coding, agentic workflows, and reasoning. Gemini 3.1 Pro wins three — multimodal, long-context, and one slot of speed. DeepSeek V4-Pro wins value-for-money. Step 3.7 Flash wins best open-weight agent. Qwen3.6-35B-A3B wins consumer hardware local deployment. No model wins more than four categories — and the categories where Opus 4.8 doesn't win are the ones where its pricing makes it hard to justify.
3. The 10 frontier models — detailed breakdown
#1 Claude Opus 4.8 (Anthropic) — overall and coding winner
Released May 28, 2026. AA Intelligence Index 61.4. SWE-Bench Verified 88.6%. SWE-Bench Pro 69.2%. Terminal-Bench 2.1 74.6%. USAMO 2026 96.7%. GDPval-AA Elo 1,890. Pricing: $5/$25 standard, $10/$50 Fast Mode (3× cheaper than Opus 4.7's Fast Mode). 1M-token context. Dynamic Workflows feature spawns up to 1,000 parallel subagents.
Strengths: Wins on engineering depth, agentic execution, and overall reasoning. Honesty improvements are real — 4× less likely to ship unflagged code defects vs Opus 4.7. Weaknesses: Most expensive frontier model at $25 per million output tokens. Long-context retrieval (GraphWalks at 1M) improved 27 points but still trails Gemini. Our detailed Opus 4.8 review covers the benchmarks, Dynamic Workflows, and Bun port case study if you want the deep dive.
Best for: Production engineering teams where reliability matters more than cost. Multi-day autonomous agent runs. Codebase-scale migrations. Long-form professional writing.
#2 GPT-5.5 (OpenAI) — the structured reasoning leader
Released April 2026. AA Intelligence Index 60.2 (xhigh). SWE-Bench Pro 58.6%. Terminal-Bench 2.0 82.7%. Pricing: $10/$30 per 1M tokens. 400K-token context. Effort variants (high, xhigh, max).
Strengths: Best raw intelligence index in the field until Opus 4.8 launched. Leads on terminal/CLI workflows, structured reasoning, and academic benchmarks. Largest ecosystem of any model — integrations, plugins, Canvas, enterprise stack. Weaknesses: 86% hallucination rate on AA-Omniscience versus Opus 4.7 at 36% — a real reliability concern for high-stakes factual workloads. Smaller context window than competitors.
Best for: Dense reasoning, structured logic, academic and scientific work, enterprise teams with existing OpenAI infrastructure.
#3 Gemini 3.1 Pro (Google) — multimodal and long-context winner
Released February 2026. AA Intelligence Index 57.2 (Preview). SWE-Bench Verified 80.6%. Pricing: $2/$12 per 1M tokens. 1M-token context. Native multimodal training across text, images, video, audio.
Strengths: Best long-context reliability across the 1M-token window. Native multimodal — leads on video understanding, document analysis with mixed media. Best price-per-intelligence among the top three. Integrated into Google Workspace, Search, and Vertex AI. Weaknesses: Trails Opus 4.8 and GPT-5.5 on raw intelligence and SWE-Bench Pro. Preview status on the latest variant.
Best for: Long-document analysis, multimodal workflows, research synthesis, Google Workspace integration, cost-sensitive frontier deployments.
#4 Claude Opus 4.7 (Anthropic) — the previous flagship
Released April 16, 2026. AA Intelligence Index 57.3. SWE-Bench Verified 87.6%. SWE-Bench Pro 64.3%. Same $5/$25 pricing as 4.8.
Why it's still on the list: Some teams are still on Opus 4.7 due to provider availability or internal qualification cycles. Our Opus 4.7 review covers the benchmarks and the deliberate cybersecurity capability cap — useful context for understanding why Anthropic shipped 4.8 only 41 days later. There is no scenario in June 2026 where staying on 4.7 makes sense over 4.8 at the same price.
#5 Qwen3.7-Max (Alibaba) — Code Arena #4, agent-tier winner
Released May 20, 2026. AA Intelligence Index 56.6. SWE-Bench Pro 60.6%. Terminal-Bench 2.0 69.7%. Code Arena Elo 1,541 (#4 overall). 1M-token context. Pricing: $2.50/$7.50 per 1M (90% cached input discount). 35-hour autonomous run, 1,158 tool calls demonstrated at launch.
Strengths: Best non-Western model on Code Arena, leads on Terminal-Bench 2.0, 6× cheaper than Opus 4.8 with frontier-adjacent quality. Weaknesses: No open weights (API-only). Trails Western frontier on raw intelligence. Our Qwen3.7-Max vs Opus comparison breaks this down with cost-per-intelligence math.
Best for: Long-horizon agent loops where token cost compounds, multi-hour autonomous workflows, cost-sensitive coding teams that need closed-source reliability.
#6 Grok 4.3 (xAI) — multi-agent specialist
Released April 30, 2026. AA Intelligence Index 53. Multi-agent architecture inherited from Grok 4.20 Beta supporting up to 16 parallel agents in Heavy mode. 1M-token context. Pricing: $3/$15 per 1M. Grok Build CLI for terminal-native coding workflows.
Strengths: Multi-agent architecture is genuinely novel. Grok Build CLI is a credible Claude Code competitor at lower API cost. Real-time X integration for current events. Weaknesses: Trails the top 3 on raw intelligence. Smaller ecosystem. Our Grok Build deep-dive covers the agent CLI and 8-parallel-subagent setup in detail.
Best for: Parallel-heavy coding migrations, SuperGrok/X Premium+ subscribers, X-integrated workflows where real-time data matters.
#7 DeepSeek V4-Pro (DeepSeek) — value-for-money champion
Released April 24, 2026 under MIT license. AA Intelligence Index ~55. Pricing: $0.28/$0.42 per 1M tokens — the most aggressive price-quality ratio of any frontier model. 1.6 trillion total parameters, 49B active, 260K context. Runs on Huawei Ascend 950PR chips. 95.2% HMMT 2026 February, 89.8% IMOAnswerBench, perfect 120/120 Putnam-2025. Our DeepSeek V4 Flash review covers the cheaper Flash variant for high-volume workloads.
Strengths: Frontier-adjacent intelligence at 1/40th the cost of GPT-5.5 on output tokens. Open weights for self-hosting. Strongest math benchmarks in the field. Weaknesses: Chinese infrastructure routing for managed API (self-host for data sovereignty). 260K context smaller than Opus or Gemini.
Best for: High-volume API workloads, self-hosted deployment under MIT license, math-heavy use cases, anyone where capability-per-dollar is the dominant factor.
#8 Kimi K2.6 (Moonshot AI) — open-weight quality leader
AA Intelligence Index 54. SWE-Bench ~54%. Modified MIT license, open weights. 262K context. Pricing: $0.95/$3.50 per 1M tokens. 300-agent parallel swarm orchestration support. Our Kimi K2.6 review covers the 87/100 real-world coding tier and the multi-agent architecture.
Strengths: Best Western-quality vocal performance among open-weight models. Modified MIT license is more permissive than DeepSeek's MIT for some commercial structures. Strong multi-agent support. Weaknesses: Smaller ecosystem than Chinese closed-source peers. Long-context reliability still maturing.
Best for: Open-weight production deployment where MIT-style licensing is non-negotiable, multi-agent orchestration on a budget, teams self-hosting frontier-adjacent models.
#9 GLM-5.1 (Z.ai) — SWE-Bench Pro specialist
AA Intelligence Index ~53. 754B total / 40B active MoE. 200K context. Pricing: $3/month Coding Plan (managed) or self-host under MIT. First open-weight model to top SWE-Bench Pro earlier in 2026. Our GLM-5.1 review covers the long-horizon agentic capability and the integration with Claude Code, OpenClaw, and Kilo Code.
Strengths: $3/month Coding Plan is one of the most attractive economics in the field for individual developers. Native compatibility with Claude Code and OpenClaw. Strong on SWE-Bench Pro. Weaknesses: Smaller context window than peers. Less mature multimodal capability.
Best for: Individual developers on a tight budget, teams already using Claude Code with multi-provider routing, SWE-Bench Pro-style production engineering workloads.
#10 Step 3.7 Flash (StepFun) — best open-weight agent
Released May 28, 2026 under Apache 2.0. AA Intelligence Index ~50. ClawEval 1.1 67.1 (#1 of any model). SWE-Bench Pro 56.3 (#2 finish). 198B total / 11B active MoE. 256K context. Native multimodal (image + video). Pricing: $0.20/$1.15 per 1M tokens. Up to 400 tokens/sec. Runs on Mac Studio 128GB+ unified memory. Our Step 3.7 Flash review covers Advisor Mode and the 97%-of-Opus-at-1/9-cost result in detail.
Strengths: Best open-weight agent execution benchmarks. Native multimodal capability. Advisor Mode pattern for cost-efficient frontier-quality agent runs. Apache 2.0 licensing. Weaknesses: Trails closed-source frontier on raw intelligence. Independent reproduction of benchmarks just starting.
Best for: Open-weight production agents, multimodal agent workflows requiring vision or video, Mac Studio local deployment, cost-sensitive agentic systems with the executor-escalator pattern.
4. Cost-per-intelligence — the value-for-money ranking
Cost-per-intelligence is the framework that actually matters for production deployment. Divide AA Intelligence Index by blended cost per million tokens (70% input, 30% output) and you get a single number that tells you which model gives you the most capability per dollar.
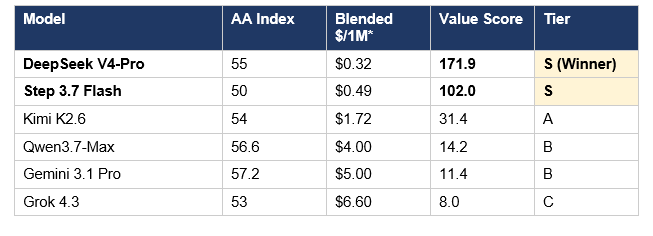
*Blended cost assumes typical agentic workload mix: 70% input tokens, 30% output tokens.
Read this table the same way developers actually pick infrastructure. DeepSeek V4-Pro wins outright at 171.9 capability-per-dollar — roughly 31× the value ratio of Claude Opus 4.8 and 45× the ratio of GPT-5.5. Step 3.7 Flash is the close second. Below those two, Kimi K2.6 holds Tier A. Everything else trades intelligence-per-dollar for absolute capability or ecosystem benefits.
🏆 Value winner: DeepSeek V4-Pro. 171.9 capability-per-dollar — 30× cheaper for the same intelligence as Opus 4.8, with frontier-grade math benchmarks and open weights under MIT. The cost difference is so large it forces every production team to evaluate whether the workload genuinely requires premium quality.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Best for coding — the production engineering pick
Coding benchmarks have stratified in mid-2026. SWE-Bench Verified has saturated at the top — every frontier model scores 80%+. SWE-Bench Pro (2,294 real GitHub issues) is now the meaningful proxy for production engineering, and Terminal-Bench 2.1 measures the agentic-coding axis.
Numbers across the field. Claude Opus 4.8: SWE-Bench Verified 88.6%, SWE-Bench Pro 69.2%, Terminal-Bench 2.1 74.6%. GPT-5.5: SWE-Bench Pro 58.6%, Terminal-Bench 2.0 82.7% (different benchmark version). Qwen3.7-Max: SWE-Bench Pro 60.6%, Terminal-Bench 2.0 69.7%. GLM-5.1: SWE-Bench Pro ~56%. Step 3.7 Flash: SWE-Bench Pro 56.3%.
🏆 Coding winner: Claude Opus 4.8. Sweeps every coding benchmark — SWE-Bench Verified (88.6%), SWE-Bench Pro (69.2%), Terminal-Bench 2.1 (74.6%) — and Cursor's CEO confirmed it 'exceeds prior Opus models across every effort level' on CursorBench. Dynamic Workflows lets it tackle codebase-scale migrations (Jarred Sumner ported ~750,000 lines of Rust in 11 days using it). The only reason not to pick it is cost — at which point Qwen3.7-Max becomes the rational alternative at 1/6 the price.
6. Best for agentic workflows — the long-horizon execution pick
Agentic workflows are where the field has shifted hardest in 2026. The benchmark that matters most: GDPval-AA, which simulates real-world economic tasks across 44 occupations and 9 industries. Models compete head-to-head in blind pairwise evaluation, producing Elo ratings that correlate directly with production agent reliability.
GDPval-AA standings as of June 1, 2026: Opus 4.8 at 1,890 Elo. GPT-5.5 (xhigh) at 1,769. Opus 4.7 at 1,753. Qwen3.7-Max ~1,580. The 121-point Opus 4.8 lead implies roughly a 67% win rate against GPT-5.5 in head-to-head agent task comparisons.
🏆 Agentic Workflows winner: Claude Opus 4.8. +121 Elo on GDPval-AA over GPT-5.5 (1,890 vs 1,769), leads OSWorld-Verified for agentic computer use at 83.4%, and ships with Dynamic Workflows — the only frontier-tier orchestration system that runs the entire plan as a JavaScript script with intermediate results stored outside the model context. Up to 1,000 parallel subagents. For multi-hour autonomous engineering work, no other model is close in mid-2026.
7. Best for reasoning — the deep-thinking pick
Reasoning is the closest contest in the leaderboard. Opus 4.8 hit 96.7% on USAMO 2026 (up from 69.3% on Opus 4.7) and leads Humanity's Last Exam with tools at 57.9%. GPT-5.5 (xhigh) holds the lead on AA-Omniscience for raw factual recall at 57%. Gemini 3.1 Pro leads CritPt physics until Opus 4.8 overtook it. DeepSeek V4-Pro posts a perfect 120/120 on Putnam-2025 and 95.2% on HMMT 2026.
🏆 Reasoning & Math winner: Claude Opus 4.8 (narrow win). Wins HLE with tools (57.9%), takes USAMO 2026 (96.7%), retook CritPt from Gemini 3.1 Pro. GPT-5.5 still wins on AA-Omniscience for pure factual recall — but it has an 86% hallucination rate on that benchmark vs Opus 4.7's 36%. For applications where the model needs to know when it doesn't know, Opus 4.8 is the rational choice. For competition math, DeepSeek V4-Pro is the dark horse — its open weights with frontier-tier math benchmarks make it the best self-host option for math-heavy reasoning.
8. Best for multimodal — the vision and video pick
Multimodal is where Gemini 3.1 Pro holds the clearest lead. Google has been training native multimodal models since Gemini 1.0 in 2023, and the architecture pays off on benchmarks involving real-world media — video summarization, document understanding with diagrams, multi-image reasoning, and audio-paired workflows. Opus 4.8 supports vision input but not native video. GPT-5.5 has solid vision but is not the leader. Step 3.7 Flash is the best open-weight option with native image and video understanding.
🏆 Multimodal winner: Gemini 3.1 Pro. Native multimodal training across text, images, video, audio. Best long-video understanding in the field. Strongest integration with Google Search, Workspace, and the broader Google ecosystem for document-heavy multimodal workflows. At $2/$12, it's also the cheapest of the top-tier multimodal options. Step 3.7 Flash is the best open-weight alternative for self-host scenarios where native vision and video understanding are required.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. Best for budget — the high-volume pick
Budget-tier picks depend on whether you want managed API or self-hosting. Managed API: DeepSeek V4-Pro at $0.28/$0.42 is unbeatable. Step 3.7 Flash at $0.20/$1.15 is close, with native multimodal as a tiebreaker. DeepSeek V4 Flash is even cheaper at $0.14 input. Self-hosting: Qwen3.6-35B-A3B on a single RTX 4090 with Apache 2.0 licensing remains the best value option for individual developers and small teams.
🏆 Budget winner: Step 3.7 Flash + DeepSeek V4 Flash (tie). Step 3.7 Flash at $0.20/$1.15 wins for multimodal agent workloads with full Apache 2.0 licensing — the value math is dramatically in its favor when vision or video is required. DeepSeek V4 Flash at $0.14 in wins for pure text high-volume workloads. For self-hosted local deployment on consumer hardware, Qwen3.6-35B-A3B running on a single RTX 4090 is the right call.
10. Best open-weight — the self-host pick
Open-weight has become a meaningful axis in 2026. The Chinese frontier (Kimi K2.6, GLM-5.1, DeepSeek V4-Pro, Step 3.7 Flash) and the major Western open-weight models (Qwen3.6-35B-A3B, Llama 4 Maverick) cover the spectrum from consumer-hardware deployment to enterprise-scale self-hosting.
🏆 Open-Weight Agent winner: Step 3.7 Flash. Apache 2.0 licensing, #1 ClawEval 1.1 (67.1, beats DeepSeek V4 Flash at 57.8), #2 SWE-Bench Pro (56.3) — leading open-weight agent execution. Native multimodal support, runs on Mac Studio 128GB+ unified memory. Advisor Mode reaches 97% of Claude Opus 4.6 coding performance at 1/9 the cost. For commercial production agent deployment under permissive open-source licensing, this is the rational June 2026 pick.
11. How to actually choose — a decision framework
The honest answer to model selection in June 2026 is that you should be using two or three models, routed by workload type. Here is the practical decision framework that holds up after evaluating all ten across real production workflows:
Use Claude Opus 4.8 when: engineering depth matters more than per-token cost. Multi-hour autonomous coding. Codebase-scale migrations. Long-form professional writing. Anything where reliability and judgment compound across a long session.
Use GPT-5.5 when: dense structured reasoning is the bottleneck. Academic and scientific work. Enterprise teams with existing OpenAI infrastructure. Workloads requiring the broadest plugin and integration ecosystem.
Use Gemini 3.1 Pro when: multimodal is non-negotiable. Long-document analysis with mixed text/image/video content. Google Workspace integration. Cost-sensitive frontier-tier workloads where Opus and GPT-5.5 are too expensive.
Use Qwen3.7-Max when: long-horizon agent loops fire hundreds of tool calls and per-token cost compounds. Closed-source reliability with frontier-adjacent quality at 1/6 the Opus price.
Use DeepSeek V4-Pro when: cost-per-intelligence is the dominant factor. Math-heavy workloads. Self-hosting under MIT for data sovereignty.
Use Step 3.7 Flash when: open-weight multimodal agent deployment is required. Mac Studio local inference. Advisor Mode patterns where a small executor escalates to a frontier advisor at planning checkpoints.
For builders composing multi-model architectures — Opus 4.8 for the deep-reasoning brain, Qwen3.7-Max or Kimi K2.6 for high-volume parallel workers, Gemini Flash for fast bulk operations — the 130+ open-source GenAI cookbooks in gen-ai-experiments cover the LangChain, LangGraph, and CrewAI orchestration patterns that compose these models into routed production systems.
Honest meta-take: the chatbot-as-single-default era ended sometime in late Q1 2026. The model-as-routed-component era is here. The teams winning with AI in mid-2026 are running 3-4 different models behind a routing layer that picks based on workload type, latency requirements, and cost constraints. The benchmark numbers above are inputs to that routing decision, not the answer itself.
12. Frequently Asked Questions
What is the best AI model in June 2026?
Claude Opus 4.8 holds the #1 position on the Artificial Analysis Intelligence Index v4.0 with a score of 61.4 — the first model to break above 60 by a clean margin. It also leads on GDPval-AA real-world economic tasks at 1,890 Elo (121 points ahead of GPT-5.5), wins every coding benchmark in the field, and leads on agentic computer use. The honest answer, however, is that 'best' depends on workload — Opus 4.8 wins on engineering and agents, Gemini 3.1 Pro wins on multimodal and long-context, DeepSeek V4-Pro wins on value-for-money.
Is Claude Opus 4.8 better than GPT-5.5?
On overall intelligence and coding, yes — Opus 4.8 leads the AA Intelligence Index by 1.2 points (61.4 vs 60.2 for GPT-5.5 xhigh) and leads SWE-Bench Pro by 10.6 points (69.2% vs 58.6%). On structured reasoning and the AA-Omniscience factual recall benchmark, GPT-5.5 still wins (but with a concerning 86% hallucination rate vs Opus 4.7's 36%). For engineering teams, agentic workflows, and production reliability, Opus 4.8 is now the rational default. For dense academic reasoning where breadth of factual recall matters more than calibration, GPT-5.5 remains strong.
Which AI model is best for coding right now?
Claude Opus 4.8 sweeps every coding benchmark — SWE-Bench Verified 88.6%, SWE-Bench Pro 69.2%, Terminal-Bench 2.1 74.6%. Cursor's CEO confirmed it exceeds prior Opus models across every effort level on CursorBench. For cost-sensitive coding teams, Qwen3.7-Max is the next-best option at 1/6 the price with strong agentic coding scores. For open-weight self-hosting, Step 3.7 Flash and GLM-5.1 are the rational picks.
What is the best open-source AI model in 2026?
Step 3.7 Flash (StepFun, Apache 2.0) wins on agent execution benchmarks — #1 ClawEval 1.1 at 67.1, #2 SWE-Bench Pro at 56.3, native multimodal capability, Advisor Mode for cost-efficient frontier-quality runs. Kimi K2.6 (Modified MIT) is the best for pure-text agent quality. DeepSeek V4-Pro (MIT) is the best for value-for-money and math benchmarks. GLM-5.1 (MIT) is the best for managed-API self-hosting with the $3/month coding plan. Qwen3.6-35B-A3B (Apache 2.0) is the best for consumer hardware local deployment on a single RTX 4090.
Which AI model has the best value for money?
DeepSeek V4-Pro at $0.28/$0.42 per million tokens has the highest capability-per-dollar ratio in the field — 171.9, compared to roughly 5.6 for Claude Opus 4.8 and 3.8 for GPT-5.5. That makes DeepSeek V4-Pro roughly 31× cheaper for the same intelligence level. Step 3.7 Flash is the close second at 102.0 capability-per-dollar with native multimodal support. For high-volume API workloads where cost dominates the decision, both are dramatically better choices than Western frontier models.
Is Gemini 3.1 Pro better than Claude Opus 4.8?
It depends on the workload. Opus 4.8 leads on overall intelligence (61.4 vs 57.2 on AA Index), coding (SWE-Bench Pro 69.2% vs ~54%), and agentic workflows. Gemini 3.1 Pro leads on multimodal (native video understanding), long-context retrieval, and value-for-money among top-tier models ($2/$12 vs $5/$25). For text-heavy engineering work, Opus 4.8 wins. For multimodal analysis, long-document research, and Google Workspace integration, Gemini 3.1 Pro is the right call.
What is the best AI model for agentic workflows?
Claude Opus 4.8 leads decisively on agentic benchmarks — GDPval-AA Elo 1,890 (121 points ahead of GPT-5.5), OSWorld-Verified 83.4% for agentic computer use, and the Dynamic Workflows feature spawns up to 1,000 parallel subagents for codebase-scale work. For cost-sensitive agent workloads, Qwen3.7-Max demonstrated 35-hour autonomous runs with 1,158 tool calls at launch and is roughly 6× cheaper per token. Step 3.7 Flash wins on the open-weight side with the #1 ClawEval 1.1 score for trajectory integrity.
Should I use Claude, GPT, or Gemini for my product?
The rational answer for most products in June 2026 is to use more than one, routed by workload type. Use Claude Opus 4.8 for engineering depth, code review, and agentic execution. Use GPT-5.5 for dense reasoning and the broadest ecosystem integration. Use Gemini 3.1 Pro for multimodal, long-context, and Google-integrated workflows. For high-volume background processing, route to DeepSeek V4-Pro or Step 3.7 Flash to capture the 5-30× cost advantage. Model-agnostic infrastructure is no longer optional when the leaderboard shifts every six weeks.
When will Claude Mythos be publicly available?
Anthropic confirmed in the Opus 4.8 launch post that Mythos-class models are 'expected in the coming weeks' for general availability. As of June 1, 2026, Mythos remains restricted to approximately 50 Project Glasswing partner organizations for defensive cybersecurity work. When Mythos ships publicly, it will become Anthropic's new flagship — and the Opus tier will shift to mid-range positioning. Plan for that transition within the next 4-8 weeks if you're making infrastructure decisions today.
Recommended Blogs
- Claude Opus 4.8 Review: Benchmarks, Dynamic Workflows, and Honest Trade-offs
- Qwen3.7-Max vs Claude Opus: Code Arena 2026 Comparison
- Best AI Models: April + May 2026 Leaderboard
- StepFun Step 3.7 Flash Review: The 198B Open MoE Agent
- DeepSeek V4 Flash: Review, Pricing & When to Use It (2026)
- GLM-5.1: #1 Open Source AI Model? Full Review (2026)
- Kimi K2.6: Open-Source Just Beat GPT-5.5 at Coding
- Grok Build: xAI's New Agent CLI Reviewed
- Qwen3.7-Max Review: Alibaba's 1M-Token Agent Model
- Claude Opus 4.7: Full Review, Benchmarks & Features
- Qwen3.6-35B-A3B: 73.4% SWE-Bench, Runs Locally
References
- Artificial Analysis — Intelligence Index v4.0 (June 2026)
- Artificial Analysis — Claude Opus 4.8 The new #1 AI model
- Artificial Analysis — GDPval-AA Leaderboard
- Anthropic — Introducing Claude Opus 4.8
- VentureBeat — Claude Opus 4.8 with 3x cheaper Fast Mode
- OfficeChai — Claude Opus 4.8 Tops Intelligence Index
- LLM Stats — 300+ AI Models Compared
- Artificial Analysis — Qwen3.7-Max Analysis
- DataCamp — Claude Opus 4.7 vs Gemini 3.1 Pro
BenchLM — Artificial Analysis Intelligence Index 126 model averages

