





Best AI Models: April + May 2026 Complete Leaderboard — GPT-5.5, Claude Opus 4.7, DeepSeek V4, and Everything That Changed
Five days. Four frontier models. Three different claims to the #1 coding spot. One month.
Between April 16 and April 24, 2026, the AI landscape shifted faster than it has at any point this year. Claude Opus 4.7 launched on April 16 and pushed SWE-bench Pro from 53.4% to 64.3%, reclaiming the coding crown. Nine days earlier, GLM-5.1 had briefly made history as the first open-weight model to ever top SWE-bench Pro. Then GPT-5.5 dropped on April 23 — the first fully retrained OpenAI base model since GPT-4.5 — and claimed its own #1 on Terminal-Bench 2.0 at 82.7%. The very next day, DeepSeek quietly released V4: a 1.6 trillion parameter open-source model built on zero Nvidia hardware, priced at $0.14 per million tokens.
I've been tracking every major AI model release for two years. This is the one where I had to stop and recalibrate. The leaderboard you bookmarked three weeks ago is already wrong.
This guide covers every major model from April 2026 and what's coming in May — text models, video models, coding agents, open-source upsets, and the ecosystem shift that no single comparison article is talking about: multi-model routing has become the only rational architecture. Here's the full picture.
At a Glance: The April-May 2026 Master Leaderboard
There is no single best AI model. What exists is a clear winner for almost every specific task. The table below reflects decisions based on verified benchmark data, real-world developer adoption, and pricing as of April 30, 2026.
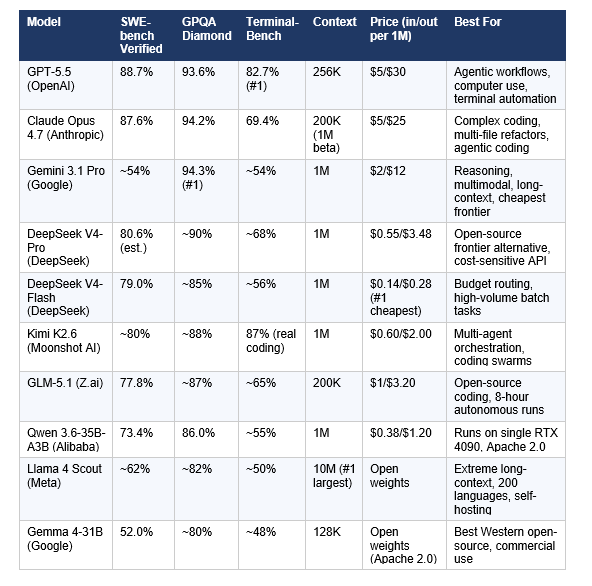
Source: OpenAI official launch benchmarks, Anthropic launch post, Artificial Analysis Intelligence Index, LLM Stats, BenchLM, independent community testing. All figures are vendor-reported unless noted as estimated. Benchmarks may be updated as independent testing progresses.
The Frontier Tier: GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro
Three labs. Three flagship models. Three different #1 claims — all of them technically accurate on different benchmarks. This is the defining feature of the April 2026 AI landscape.
GPT-5.5 — The Agentic Model (OpenAI, April 23, 2026)
GPT-5.5, codenamed "Spud" internally, is the first fully retrained OpenAI base model since GPT-4.5. Every model between GPT-4.5 and GPT-5.5 was an incremental post-training update. GPT-5.5 is a ground-up rebuild.
The architecture is natively omnimodal — text, images, audio, and video are processed in a single unified system, not stitched together from separate models. OpenAI called it "the next step toward a new way of getting work done on a computer."
The benchmark that matters most for GPT-5.5's narrative: Terminal-Bench 2.0 at 82.7%. This is a real command-line workflow benchmark — shell scripting, container orchestration, tool chaining. GPT-5.5 leads every model on this metric by a meaningful margin.
Where GPT-5.5 loses: SWE-bench Pro. Claude Opus 4.7 scores 64.3% versus GPT-5.5's 58.6% — a 5.7-point gap that represents hundreds of real GitHub issues where Claude ships working code and GPT-5.5 doesn't. For codebase-heavy engineering work, that gap is real.
The pricing math is complicated. API price doubled from $2.50/$15 to $5/$30. OpenAI says 40% fewer output tokens per task absorbs most of the hike, resulting in a net ~20% effective cost increase. Teams who benchmark carefully may find this accurate. Teams who don't may just see the doubled price.
Verdict: Use GPT-5.5 for agentic workflows with heavy terminal use, computer use tasks, and multi-tool orchestration. Route everything else elsewhere unless you're already deep in the OpenAI ecosystem.
Claude Opus 4.7 — The Coding Champion (Anthropic, April 16, 2026)
Anthropic launched Claude Opus 4.7 one week before GPT-5.5, and the timing was intentional. It pushed SWE-bench Pro from 53.4% (Opus 4.6) to 64.3% — a 10.9-point improvement that holds even after GPT-5.5's launch.
Three upgrades define Opus 4.7. First: vision. Image resolution jumped from 1.15 megapixels to 3.75 megapixels — more than 3x the pixel count of any prior Claude model. Second: the xhigh effort level, which gives developers explicit control over reasoning depth. Low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6, which means efficiency gains before you even tune effort levels. Third: OSWorld autonomous computer use hits 78% — on par with GPT-5.5's 78.7%.
On SWE-bench Pro, Opus 4.7 leads. On SWE-bench Verified (the easier benchmark), GPT-5.5 leads at 88.7% versus Opus 4.7's 87.6%. That 1.1-point gap on Verified matters less in practice than the 5.7-point gap on Pro — Pro uses harder, less contaminated tasks.
Michael Truell, CEO of Cursor (one of the two most widely used AI coding editors, alongside Windsurf), confirmed that Opus 4.7 "lifted resolution by 13% over Opus 4.6" on Cursor's internal 93-task benchmark. The new model solved four tasks that neither Opus 4.6 nor Sonnet 4.6 could touch. In the JetBrains developer adoption survey from January 2026, Claude Code reached 18% professional adoption with a 91% satisfaction score and NPS of 54 — the highest product loyalty metrics in the AI coding category.
Verdict: Use Claude Opus 4.7 for complex multi-file coding, PR review, long-context technical work, and any task where getting the code right matters more than getting it fast.
Gemini 3.1 Pro — The Multimodal Leader (Google, February 2026, still frontier-tier)
Gemini 3.1 Pro launched in February 2026 and remains one of the top three frontier models in April. Its headline is scientific reasoning: 94.3% on GPQA Diamond, leading every model tested. ARC-AGI-2 at 77.1% is more than double the previous version's score.
The practical advantage that gets undercovered: pricing. At $2/$12 per million tokens, Gemini 3.1 Pro delivers essentially the same reasoning quality as GPT-5.5 on most tasks at 40% of the cost. For high-volume API use, that difference is measured in thousands of dollars per month.
Gemini 3.1 Pro's 1 million token context window (vs GPT-5.5's 256K) means it can ingest entire codebases, long document collections, or extended conversation histories in a single pass. For document-heavy workflows, this isn't a marginal improvement — it changes what's possible.
The limitation: output quality. Gemini 3.1 Pro's 65K output window is roughly half Claude Opus 4.7's 128K. For tasks requiring very long generated outputs, Claude holds an advantage.
Verdict: Use Gemini 3.1 Pro for scientific research, multimodal tasks involving images and video, high-volume cost-sensitive API workloads, and any task requiring 1M-token context at a reasonable price.
The Open-Source Upset: How Chinese Labs Rewrote the Rules
Six months ago, the standard argument was that open-source AI was two years behind the frontier. That argument is now empirically wrong. GLM-5.1 topped SWE-bench Pro. DeepSeek V4 competes with Claude Opus 4.6 and GPT-5.4 on coding benchmarks at $0.14 per million tokens. Kimi K2.6 achieved Tier A (87/100) on real-world coding tasks. All three are built without Nvidia hardware.
DeepSeek V4 — $0.14/M Tokens, 1.6T Parameters, Zero Nvidia Hardware (April 24, 2026)
DeepSeek V4 is the release MIT Technology Review called "the most significant since R1." It comes in two variants: V4-Pro (1.6T parameters, 49B active, $0.55/M input) and V4-Flash (284B parameters, 13B active, $0.14/M input).
The architecture breakthrough is Hybrid Attention — combining Compressed Sparse Attention and Heavily Compressed Attention to handle 1 million token contexts efficiently. In the 1M-token context setting, DeepSeek V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared to V3.2. That efficiency is why it can be priced at $0.14 per million tokens without losing money.
DeepSeek V4 was built on 100,000+ Huawei Ascend 910B chips — zero Nvidia GPUs. US export controls on AI chips were supposed to slow Chinese AI development. They demonstrably did not prevent frontier-level training. Whether the controls accelerated domestic Chinese chip development or whether the trajectory was always going to converge is a question the policy community will be debating for years.
In practical terms: V4-Pro scores ~80.6% on SWE-bench Verified and ~67.9% on Terminal-Bench 2.0. That's within striking distance of Claude Opus 4.7 at a 7x output cost advantage. For teams running high-volume production workloads where open-source reliability tradeoffs are acceptable, V4 changes the economics fundamentally.
Verdict: Use DeepSeek V4-Flash for budget routing layers — the $0.14/M input price is the cheapest capable model available. Use V4-Pro as a cost-effective frontier alternative when you need open weights and MIT licensing.
GLM-5.1 — The Model That Made History (Z.ai/Zhipu AI, April 7, 2026)
On April 7, 2026, GLM-5.1 became the first open-weight model in history to top the SWE-bench Pro leaderboard, scoring 58.4%. It held #1 for nine days — until Claude Opus 4.7 reclaimed the spot on April 16.
GLM-5.1 is a 744 billion parameter Mixture-of-Experts model with 40 billion active parameters. It was trained entirely on 100,000 Huawei Ascend 910B chips with no Nvidia hardware. The model can maintain autonomous task execution for up to 8 continuous hours without performance degradation — a figure that no Western closed-source model has publicly matched.
In one demonstration, GLM-5.1 ran 655 iterations with over 6,000 tool calls to build a high-performance vector database from scratch, reaching 21,500 QPS — six times the best single-session result from any previous model. The GLM Coding Plan starts at $3 per month with MIT licensing.
I said this when it launched: a model that does 94.6% of what Claude Opus does at $3 per month versus $100+ per month is not a niche optimization. It is a pricing disruption that most enterprise teams have not processed yet.
Verdict: GLM-5.1 is the strongest open-source coding model for teams who need MIT licensing and full downloadable weights. The $3/month GLM Coding Plan is the best value in professional AI development.
Kimi K2.6 — 300-Agent Swarm Orchestration (Moonshot AI, April 20, 2026)
Kimi K2.6 is the surprise of April 2026. It beat GPT-5.4 on SWE-Bench Pro at $0.60 per million output tokens and achieved Tier A (87/100) on real-world coding benchmarks — the only Chinese model to reach that tier. More interestingly, it supports 300-agent parallel swarm orchestration, enabling it to parallelize complex coding tasks across hundreds of simultaneous sub-agents.
In real-world coding benchmarks that test more than standard SWE-bench patterns, Kimi K2.6 scored 87/100 — versus Claude Opus 4.7's ~97/100. That 10-point gap is real, but at $0.30 per run versus $1.10 per run for Opus 4.7, the cost-performance ratio is compelling for teams running high volumes of defined coding tasks.
Verdict: Use Kimi K2.6 as a specialist sub-agent in multi-agent architectures for well-defined, parallelizable coding tasks. Less suited as a top-level orchestrator on ambiguous planning work.
Qwen 3.6-35B-A3B — Frontier Performance on a Single GPU (Alibaba, April 2026)
Qwen 3.6-35B-A3B activates only 3 billion of its 35 billion parameters per token. That MoE efficiency makes it the strongest open-weight model that runs on consumer hardware — specifically a single RTX 4090 GPU with quantization. It scores 73.4% on SWE-bench Verified and 86.0% on GPQA Diamond.
The Apache 2.0 licensing means full commercial use without restrictions. For startups and indie developers who want frontier-competitive performance without cloud API costs, this is the most practical option in the open-source tier.
The Speed Tier: Best Budget Models for High-Volume Use
Not every task needs a frontier model. A smart routing architecture puts 60-70% of traffic through the cheapest capable model and reserves Opus-tier for the hard problems. Here are the best budget options in April 2026.
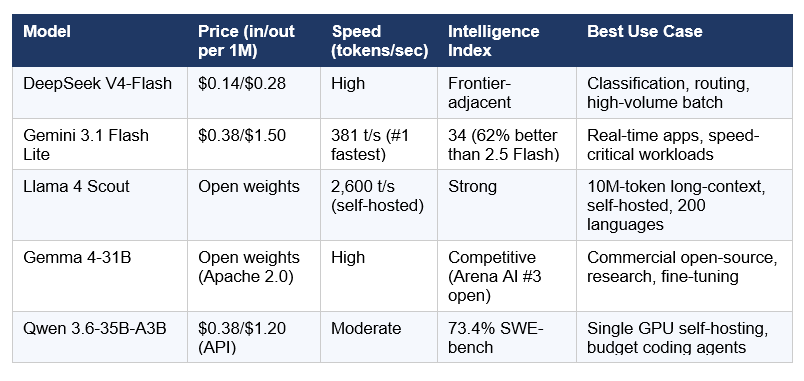
The routing math that most teams aren't doing: a single application routing 70% of traffic to DeepSeek V4-Flash, 25% to Claude Sonnet 4.6, and 5% to Claude Opus 4.7 achieves overall performance indistinguishable from routing everything to a frontier model, at roughly 15% of the all-frontier cost. LLM Stats logged 255 model releases in Q1 2026 alone — roughly three significant releases per day. Any application hardcoded to a single model is accumulating technical debt in real time.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
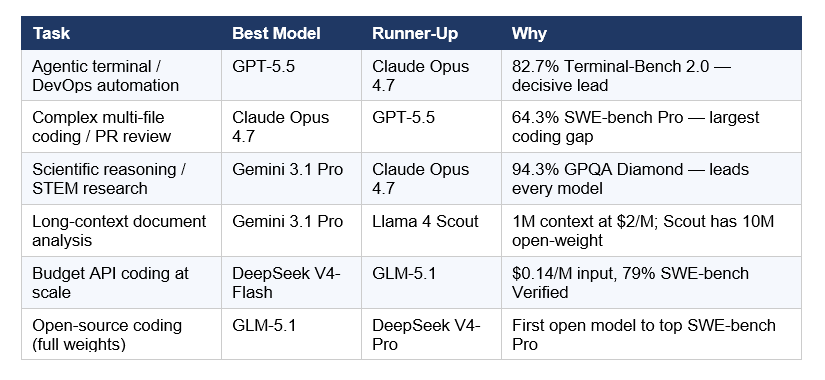
The Leaderboard by Task
There is no universally best AI model in April-May 2026. There is a clear winner for almost every specific task. Use this table as your decision framework.
The AI Video Generation Race: HappyHorse Changes Everything
Four of the top five AI video models by Elo score are Chinese-built. OpenAI shuttered Sora in March 2026. If you're building a video product in 2026, your infrastructure is almost certainly powered by a Chinese lab. That's the state of play heading into May.
HappyHorse 1.0 — Alibaba's Anonymous Leaderboard Bomb (April 7, 2026)
A mysterious model appeared on the Artificial Analysis Video Arena on April 7, 2026. No company name. No press release. Just videos that kept beating everything else in blind human preference tests.
Within 72 hours, it had the highest Elo score in AI video history: 1389. Within three days, Alibaba admitted it built it under the name Happy Horse 1.0 — a 15-billion-parameter model from the Future Life Lab inside Alibaba's Taotian Group.
The playbook is becoming a signature move: submit anonymously to a leaderboard, let blind user voting validate the model, then reveal yourself only after you've hit #1. DeepSeek used it. Xiaomi used it with MiMo-V2. Alibaba did it again with HappyHorse. When your model is genuinely good enough, it works.
Happy Horse leads Seedance 2.0 by 115 Elo points in text-to-video without audio. In categories with audio, Seedance 2.0 retains a small lead of 14 Elo points.
The Production Video Tier: Veo 3.1, Kling 3.0, Seedance 2.0
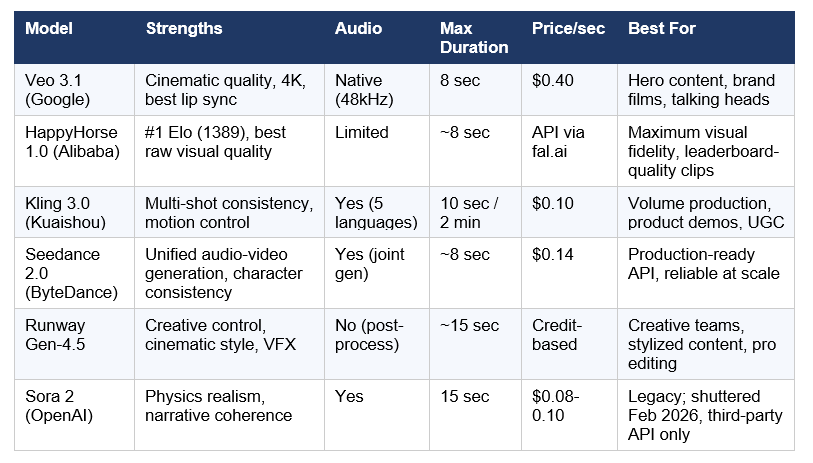
My take: Most production video teams in 2026 are routing between 2-3 models depending on the scene type. Veo 3.1 for hero shots and dialogue, Kling 3.0 for volume and motion, Seedance 2.0 for its reliable production API. HappyHorse is not yet production-API-ready for most teams but leads on raw quality. For our detailed breakdown of the HappyHorse vs Seedance battle, see the full comparison here.
The Agentic Revolution: Coding Agents in 2026
By the end of 2025, roughly 85% of developers used AI tools for coding. What changed in 2026 is not the percentage — it's the type of tool. AI coding agents that autonomously read codebases, make multi-file changes, run tests, and submit pull requests have moved from demo to production.
A notable ecosystem development: Xcode 26.3 (Apple, released ~April 2026) now natively integrates Claude Agent and OpenAI Codex for agentic iOS and macOS development. This is the first time a major IDE vendor has shipped native AI agent integration from two competing providers simultaneously. The Model Context Protocol (MCP) is the open standard that made it possible.
For developer teams choosing between Claude Code and Codex specifically, our in-depth comparison at Claude Code vs Codex: Local Agent vs Cloud Orchestration covers the execution model differences, security controls, and when each wins.
The Biggest Ecosystem Shift: Multi-Model Routing Is Now the Standard
In Q1 2026, LLM Stats logged 255 model releases from major organizations. That's roughly three significant model releases per day. Any application hardcoded to a single model is accumulating technical debt in real time.
The developers who treat model selection as a routing problem — rather than a loyalty problem — are shipping better products at lower cost. Here's the architecture that's emerging across production systems:
The Three Core Multi-Model Architectures
1. The Tiered Intelligence Stack (most common): A fast, inexpensive model handles intent classification and simple queries. A mid-tier model manages standard response generation. A frontier model handles only high-complexity tasks. A typical split: 70% DeepSeek V4-Flash, 25% Claude Sonnet 4.6, 5% Claude Opus 4.7. Overall performance: indistinguishable from all-frontier routing at roughly 15% of the cost.
2. The Specialist Routing Architecture : Each model handles its peak-performance category. Gemini 3.1 Pro for multimodal tasks with images and video. GLM-5.1 or Claude Opus 4.7 for complex coding agent work. Llama 4 Scout for long-context retrieval over large document sets. Qwen 3.6 for Asian-language tasks and cost-sensitive classification. GPT-5.5 for tool-use-heavy computer use where OpenAI's native integrations matter.
3. The Open-Source Hybrid : Proprietary models for customer-facing real-time interactions. Open-source models for internal or batch processing at near-zero marginal cost. A typical setup pairs Claude Opus 4.7 for user-facing chat with DeepSeek V4-Flash or Llama 4 Maverick running self-hosted for background processing.
The practical implication: model-agnostic infrastructure is no longer optional. When a new model releases every few weeks, applications with hardcoded provider dependencies face recurring migration projects. A unified API layer where switching is a parameter change — not a refactor — is the architectural decision that pays dividends every quarter. For builders wanting to implement multi-model routing in practice, the gen-ai-experiments agent orchestration notebooks cover multi-agent implementation patterns with Claude, GPT, Gemini, and DeepSeek.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
What's Coming in May-June 2026: GPT-6, Claude 5, and the Next Leaderboard
April 2026 was the most competitive month in AI history. May 2026 could be bigger. Two generational model upgrades are expected in the next 60-90 days.
GPT-6: Expected May-July 2026
OpenAI has not announced an official release date. Polymarket prediction markets had "GPT-6 by April 30" at 72%, falling to lower confidence after GPT-5.5 shipped as the model codenamed Spud. The most defensible window is late May to early July 2026.
Sam Altman has identified long-term memory as the headline feature of the next-generation system — recall of preferences, ongoing projects, and past conversations across weeks or months, not just within a session. Agentic capabilities are expected to expand significantly, with better goal decomposition and more tool integrations. GPT-6 will be trained on Stargate infrastructure.
My read: GPT-6 will not be an incremental update. OpenAI is positioning it as a qualitative capability jump, not a benchmark point improvement. If they deliver on the memory and agentic framing, it changes what's possible for production AI systems — not just what scores highest on SWE-bench.
Claude 5 'Fennec': Expected Q2-Q3 2026
Anthropic's Claude 5, internally codenamed "Fennec," is the most technically anticipated release among developers who've adopted Claude for coding and research. It is expected to be a full architecture upgrade — not a post-training refinement like the 4.x series.
What Anthropic is targeting: significantly improved tool use and agentic workflow reliability. The area where Claude currently has friction relative to GPT-5.4 in production systems is tool call reliability at scale. Claude 5 is expected to bring native multi-step tool calling with better state management, stronger recovery from tool call failures, and a meaningful SWE-bench leap — the developer community expects 90%+ SWE-bench Verified.
Prediction markets on Metaculus lean toward a Q2-Q3 2026 window, which is consistent with Anthropic's historical cadence: Claude 3 shipped March 2024, Claude 3.5 Sonnet shipped June 2024, Claude Opus 4.6 shipped early 2026.
The Open-Source Gap Is Closing
In 2023, open-source AI was roughly two years behind the frontier. In 2024, it was months. By April 2026, GLM-5.1 held #1 on SWE-bench Pro for nine days. The remaining advantages of closed-source models are narrowing to: safety fine-tuning reliability, agentic reasoning on open-ended tasks, and infrastructure support. On raw benchmarks for well-defined tasks, the gap is now single-digit percentage points.
Frequently Asked Questions
What is the best AI model in May 2026?
There is no single best AI model in May 2026. GPT-5.5 leads Terminal-Bench 2.0 at 82.7% for agentic terminal workflows. Claude Opus 4.7 leads SWE-bench Pro at 64.3% for complex coding. Gemini 3.1 Pro leads GPQA Diamond at 94.3% for scientific reasoning. DeepSeek V4-Flash at $0.14 per million tokens leads on cost. The right model depends entirely on your task and budget.
Is GPT-5.5 better than Claude Opus 4.7?
It depends on the task. GPT-5.5 leads on Terminal-Bench 2.0 (82.7% vs 69.4%) for command-line agentic work and overall intelligence index. Claude Opus 4.7 leads on SWE-bench Pro (64.3% vs 58.6%) for real GitHub issue resolution — a 5.7-point gap that is significant in production software engineering. Claude also leads on hallucination reliability (36% hallucination rate vs GPT-5.5's 86% per Artificial Analysis). For most teams, routing between the two based on task type is the optimal approach.
What is DeepSeek V4 and why does it matter?
DeepSeek V4 is a preview of DeepSeek's new flagship model family, released April 24, 2026. The Pro variant has 1.6 trillion total parameters (49 billion active) and supports 1 million token context. It is fully open-source under the MIT license with weights available on Hugging Face. The Flash variant costs $0.14 per million input tokens — the cheapest capable frontier-adjacent model available. It was built entirely on Huawei Ascend chips with zero Nvidia hardware, a significant milestone for Chinese AI infrastructure independence.
What is the best open-source AI model in 2026?
As of April 2026, GLM-5.1 leads all open-weight models on SWE-bench Pro (58.4%), making it the strongest open-source coding model. For overall performance at lower compute cost, DeepSeek V4-Pro scores ~80.6% on SWE-bench Verified under MIT license. For self-hosting on consumer hardware, Qwen 3.6-35B-A3B runs on a single RTX 4090 with 73.4% SWE-bench Verified under Apache 2.0 — the most commercially permissive license in this tier.
Which AI model has the largest context window?
Llama 4 Scout holds the largest context window at 10 million tokens — the biggest among any model, open or closed, available as of April 2026. For closed-source models, Gemini 3.1 Pro and DeepSeek V4 both support 1 million tokens. Claude Opus 4.7 has 200K standard with 1M in beta. GPT-5.5 has 256K tokens.
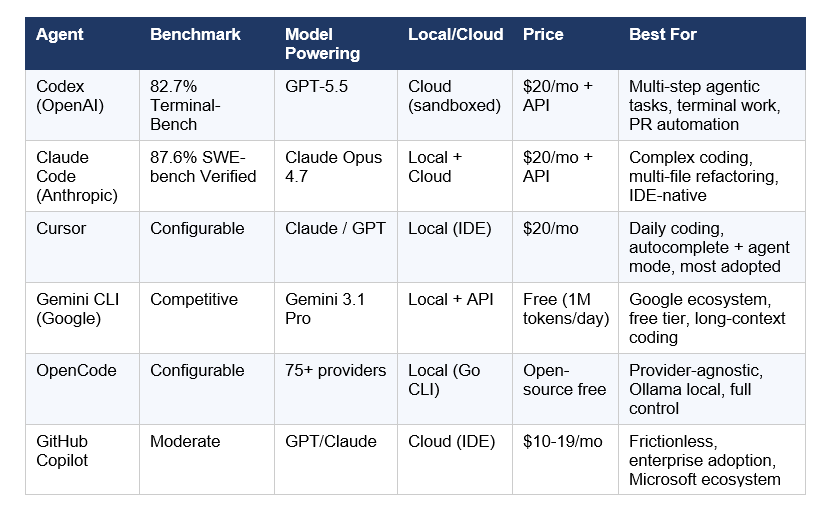
What are the best AI coding agents in 2026?
In April 2026, Codex (powered by GPT-5.5) leads on Terminal-Bench metrics and multi-step agentic workflows. Claude Code (powered by Claude Opus 4.7) leads on SWE-bench Verified at 87.6% and has the highest developer satisfaction scores — 91% CSAT and NPS of 54 per the JetBrains January 2026 developer survey. Cursor (using configurable models) remains the most widely adopted AI coding editor. OpenCode, an open-source Go-based CLI supporting 75+ providers including local Ollama models, is the fastest-growing alternative for developers who want full provider control.
When will GPT-6 be released?
OpenAI has not officially announced a GPT-6 release date. Prediction market estimates suggest a May-July 2026 window is most likely, with approximately 45-72% probability before June 30. Sam Altman has described GPT-6 as focusing on long-term memory, expanded agentic capabilities, and improved personalization. OpenAI's rapid release cadence in 2026 — GPT-5.5 launched just six weeks after GPT-5.4 — suggests the next major model is not far off.
What is Claude 5 'Fennec'?
Claude 5, internally codenamed 'Fennec,' is Anthropic's next major architecture release, expected in Q2-Q3 2026. Unlike the Claude 4.x series (which were post-training refinements), Claude 5 is expected to be a full ground-up architectural upgrade. Developer community expectations include SWE-bench Verified scores above 90%, significantly improved multi-step tool use reliability, and better state management for long-running autonomous agent workflows. Anthropic has not officially confirmed specs or a release date.
What is multi-model routing and why does it matter?
Multi-model routing is the practice of directing different types of requests to different AI models based on task requirements, rather than sending everything to a single model. In 2026, this has become standard production architecture. A typical setup routes 70% of traffic to a cheap capable model like DeepSeek V4-Flash ($0.14/M tokens), 25% to a mid-tier model like Claude Sonnet 4.6, and 5% to a frontier model like Claude Opus 4.7 for complex tasks — achieving frontier-level overall performance at roughly 15% of the all-frontier cost. With 255+ model releases in Q1 2026, model-agnostic infrastructure that supports routing is no longer optional for serious production systems.
Recommended Blogs
Related reading from Build Fast with AI:
- Best AI Models Leaderboard: April 2026 Update (April 27)
- Best AI Models April 2026: GPT-5.5, Claude & Gemini Compared
- Latest AI Models April 2026: Rankings & Features
- GPT-5.5 Review: Benchmarks, Pricing & Vs Claude (2026)
- Every AI Model Compared: Best One Per Task (2026)
- Happy Horse vs Seedance 2.0: Which AI Video Model Wins?
- Best AI for Coding 2026: Nemotron vs GPT-5.3 vs Opus 4.6
- 12+ AI Models in March 2026: The Week That Changed AI
- Grok 4.20 Beta Explained: Non-Reasoning vs Reasoning vs Multi-Agent
References
- OpenAI — Introducing GPT-5.5 (Official Launch, April 23, 2026)
- Anthropic — Claude Opus 4.7 Release Announcement
- DeepSeek AI — DeepSeek-V4-Pro on Hugging Face (April 24, 2026)
- MIT Technology Review — Three Reasons Why DeepSeek V4 Matters (April 24, 2026)
- Artificial Analysis — OpenAI GPT-5.5 is the New Leading AI Model
- CNBC — OpenAI Announces GPT-5.5, Its Latest Artificial Intelligence Model (April 23, 2026)
- DataCamp — Claude Opus 4.7 vs Gemini 3.1 Pro Comparison
- JetBrains Research — Which AI Coding Tools Do Developers Actually Use at Work? (January 2026)
- Lushbinary — GPT-5.5 vs Claude Opus 4.7: Benchmarks, Pricing & Coding
- Renovate QR — Chinese AI Models in April 2026: DeepSeek V4, Kimi K2.6, Qwen 3.6
- Apple Newsroom — Xcode 26.3 Unlocks the Power of Agentic Coding (February 2026)
- Build Fast with AI — Best AI Models Leaderboard April 2026 Updated
- AI/ML API Blog — Best AI Video Generators 2026: Veo 3.1, Kling, Sora 2, Seedance Compared
- Build Fast with AI — gen-ai-experiments: Agent Orchestration and Multi-Model Notebooks
- MightyBot — Best AI Coding Agents in 2026, Ranked (April 2026 Refresh)

