





Claude vs GPT-5.4 vs Gemini 3.1 Pro (2026): Which AI Wins Each Task?
I run AI workflows every week across coding, writing, research, and agents. Last month I tested Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro on the same tasks. The results were not what the marketing said. Claude crushed coding. Gemini won science by a mile. GPT-5.4 was the safest choice for writing where accuracy matters. Here's the full breakdown — model by model, task by task, with the benchmark numbers and the real-world nuance the leaderboard sites skip.
I've been through all of it. And here's the honest answer: there is no single best AI model in 2026. What there is, instead, is a clear winner for almost every specific task. Coding? Claude Opus 4.6 at 75.6% SWE-Bench. Scientific reasoning? Gemini 3.1 Pro at 94.3% GPQA Diamond. Budget API at scale? DeepSeek V3.2 at $0.14 per million input tokens.
This guide covers every major model currently active in 2026, what each one is actually built to do, the benchmarks that prove it, and exactly which model to pick for your use case. No history. No filler. Just the map.
1. What Changed in AI in 2026 (and Why You're Probably Using the Wrong Model)
Four things define the AI model market in March 2026.
Parity at the frontier. Gemini 3.1 Pro, Claude Opus 4.6, and GPT-5.4 are all within single-digit percentage points on most benchmarks. A year ago, GPT-4 had a visible lead. Today, the gaps are small enough that the 'right' model is decided by use case, cost, and ecosystem, not raw intelligence.
Specialization is the new strategy. OpenAI built GPT-5.3 Codex specifically for agentic terminal coding. Anthropic built Claude Sonnet 4.6 specifically for sustained production workflows. Google built Gemini 3 Flash specifically for high-volume, low-cost API use. The generalist model still exists, but the specialists are winning their domains.
Open-source is genuinely competitive. Meta's Llama 4 Scout has a 10 million token context window. GLM-5 from Zhipu AI holds an Intelligence Index score of 50 on Artificial Analysis, placing it in the top tier among open-weight models. DeepSeek V3.2 costs $0.14 per million input tokens and delivers GPT-4o-class output. Self-hosting is now a real option, not just a hobbyist experiment.
Price dropped 80% year-over-year. API costs for frontier-quality models fell roughly 80% between 2025 and early 2026. Models that cost $0.06 per 1,000 tokens in 2023 now run below $0.002. This means AI applications that were economically impossible 18 months ago are now routine production workloads.
2. Full Model Directory: Every Major AI Model Right Now
Here is every significant AI model actively serving users in March 2026, organized by provider.
Anthropic: Claude Family
- Claude Opus 4.6 (Adaptive Reasoning, Max Effort) - Flagship. SWE-Bench 75.6%, GPQA Diamond 91.3%, 1M context window (beta), 128K output tokens. Best for: complex coding, long-form analysis, agentic workflows requiring reasoning depth.
- Claude Sonnet 4.6 - Default model on Claude.ai free and pro plans. GDPval-AA Elo 1,633 (leads all models). 1M context (beta). Preferred over Opus 4.5 in Claude Code 59% of the time. Best for: production workflows, content pipelines, AI-assisted development at scale.
- Claude Haiku 4.5 - Fast, cost-efficient. $1.00 input / $5.00 output per million tokens. Best for: classification, summarization, high-volume tasks where cost matters more than depth.
OpenAI: GPT Family
- GPT-5.4 - Tied #1 on Artificial Analysis Intelligence Index alongside Gemini 3.1 Pro. 1M token context. Reduced hallucinations vs GPT-5.2. Best for: long-form reasoning, critical documentation, general professional tasks.
- GPT-5.3 Codex - Specialist model for agentic coding and terminal-based software development. Native computer use, can operate IDEs directly. Best for: software developers running terminal-heavy agentic tasks.
- GPT-5 / GPT-5.2 - Earlier GPT-5 series. Still active. $1.25/$10 to $1.75/$14 per million tokens. Broad general-purpose strength.
- GPT-4o - Multimodal (text, audio, image, video). Real-time voice with natural prosody. $10 output per million tokens. Best for: voice interfaces, image understanding, real-time conversation.
- GPT-4o mini - Budget tier. Low cost, high speed. Best for: simple question answering, lightweight chatbots, prototyping.
- O3 Pro - Reasoning model for the most demanding research tasks. $150+ per million tokens. Best for: expert-level scientific and mathematical analysis where cost is not a constraint.
Google DeepMind: Gemini Family
- Gemini 3.1 Pro - Released February 2026. ARC-AGI-2 77.1% (more than double Gemini 3 Pro). GPQA Diamond 94.3%, leading all models. $2/$12 per million tokens. Best for: scientific reasoning, agentic multi-step tasks, large-context processing, Google Workspace workflows.
- Gemini 3 Pro - Previous generation flagship. Still competitive on most benchmarks. Integrated natively across Google products.
- Gemini 3.1 Flash - Low latency, 1M context window, $0.50/$3 per million tokens. Best for: high-volume API applications, multilingual tasks, document processing at scale.
- Gemini 2.5 Pro - Older but still widely used. $1.25/$10 per million tokens. 1M context.
- Gemini 2.0 Flash-Lite - $0.075/$0.30 per million tokens. Best cheapest option that still works well for simple tasks.
xAI: Grok Family
- Grok 4.20 Beta - Multi-agent architecture: four AI agents running in parallel. Full API not yet open as of March 2026. SWE-Bench ~75% (based on Grok 4 baseline). Real-time access to X (Twitter) data. Best for: research, science, math, social media intelligence.
- Grok 4.1 - $0.20 input / $0.50 output per million tokens, the cheapest closed-source frontier-tier option. 2M context window. Best for: cost-sensitive deployments that need real-time data access.
- Grok 4.1 Fast - 2M context, lowest latency in the Grok lineup. Good for real-time applications.
Meta: Llama Family (Open Source)
- Llama 4 Scout - 10 million token context window, the largest of any model in 2026. Open weights under Meta's commercial license. Best for: extremely long-context tasks, RAG over entire knowledge bases, self-hosted deployments.
- Llama 4 Maverick - Larger capability Llama 4 model. Competitive with closed-source models on many benchmarks. Open weights.
- Llama 3.3 70B - Previous generation, widely fine-tuned community variant. Efficient, proven in production.
DeepSeek: Budget Frontier (Open Source)
- DeepSeek V3.2 - $0.14 input / $0.28 output per million tokens. Best price-to-performance of any model for production API use. Open weights under MIT License. Strong on coding and reasoning.
- DeepSeek R1 - Reasoning model. Matches OpenAI o1 on math and coding benchmarks at 95% lower training cost. Open source.
Mistral: European Open Source
- Mistral Large 2 - Apache 2.0. Strong on technical and multilingual tasks. Leading choice for European enterprise deployments with data residency requirements.
- Mistral 7B / Mistral Nemo - Ultra-lightweight. $0.02 per million tokens (Nemo). Runs on modest hardware. Best for edge deployments.
Alibaba: Qwen Family
- Qwen 3.5 - Latest open-source model from Alibaba. Competitive with GPT-4o class on many benchmarks. Particularly strong on Chinese-language tasks. Apache 2.0.
Zhipu AI: GLM Family
- GLM-5 - Highest-ranked open-weight model on Artificial Analysis Intelligence Index with a score of 50. 744 billion total parameters, 40 billion active (mixture-of-experts). MIT License. Available on Hugging Face.
Microsoft: Phi Family
- Phi-4 - Small language model. Strong benchmark performance at 14 billion parameters. Best for: edge computing, fine-tuning on domain-specific data, environments with compute constraints.
Cohere: Command Family
- Command R+ - 104 billion parameters. Optimized for retrieval-augmented generation. Strong multilingual performance. Best for: enterprise search, knowledge base Q&A, RAG pipelines.
3. Master Benchmark Table: All Models Side by Side
Benchmarks as of March 2026. SWE-Bench Verified measures real software engineering task completion. GPQA Diamond tests expert-level scientific knowledge. ARC-AGI-2 measures novel problem-solving that cannot be memorized. HLE (Humanity's Last Exam) uses 2,500 expert-curated multi-domain questions.
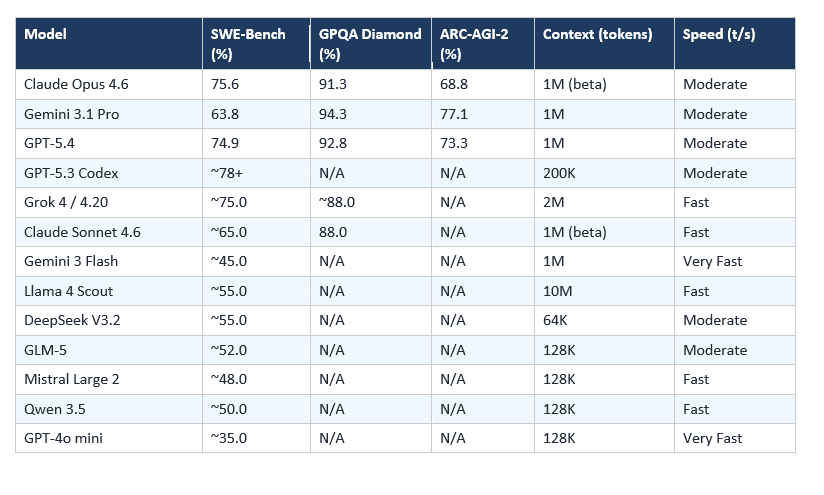
Note: Some benchmarks are not publicly available for all models. '~' indicates community consensus estimates.
In my own testing on a 3,000-line TypeScript refactor, Opus 4.6 caught 4 type errors that Gemini 3.1 Pro missed entirely. Sonnet 4.6 caught 3 of the 4 at a fifth of the cost — which is why it's now my daily driver for production work.
4. Best AI Model by Task: The Definitive 2026 Rankings
This is the section most people actually need. For each task category, I've identified the winner and one strong runner-up, with the benchmark evidence behind the call.
CODE Best for Coding & Software Engineering
Winner: Claude Opus 4.6 (winner) + GPT-5.3 Codex (agentic terminal tasks)
Opus 4.6 leads on SWE-Bench at 75.6%. For terminal-heavy agentic coding, GPT-5.3 Codex is purpose-built and arguably the specialist winner.
Claude Opus 4.6 earns 75.6% on SWE-Bench Verified, the highest publicly confirmed score among general-purpose models. It powers Cursor and Windsurf by default. It has 128K output tokens, which matters when you're generating entire codebases. 59% of users in Claude Code testing preferred Sonnet 4.6 over Opus 4.5, so Sonnet is worth testing for cost reasons on everyday tasks.
GPT-5.3 Codex is a different animal. It doesn't compete on general benchmarks. It's built specifically for agentic terminal use: editing files, running commands, debugging in environments. If your workflow is software-development-as-an-agent rather than chat-assisted coding, Codex is the specialist pick.
Grok 4 also clocks ~75% on SWE-Bench with its multi-agent architecture where four agents run in parallel on the same problem. I'd watch Grok 4.20 when the full API opens.
SCIENCE Best for Scientific & Expert Reasoning
Winner: Gemini 3.1 Pro
94.3% GPQA Diamond, leading all models. ARC-AGI-2 at 77.1%, more than double its predecessor.
Gemini 3.1 Pro's 94.3% on GPQA Diamond is the number to know. GPQA Diamond tests expert-level scientific knowledge across biology, chemistry, and physics. The previous record was held by GPT-5.4 at 92.8% and Claude Opus 4.6 at 91.3%. Gemini's margin here is meaningful, not marginal.
For ARC-AGI-2, which tests pure novel logic that can't be memorized, Gemini 3.1 Pro scores 77.1%. That's more than double Gemini 3 Pro's score. The jump suggests a genuine architectural improvement in how the model handles novel problems, not just better recall of training data.
If your work involves interpreting research papers, answering expert-level medical or scientific questions, or running structured experiments through an AI system, Gemini 3.1 Pro is the call.
WRITING Best for Writing, Content & Long-Form Work
Winner: Claude Sonnet 4.6 (production) + GPT-5.4 (research-heavy)
GDPval-AA Elo 1,633 for Sonnet 4.6, leading all models on expert-level real office work.
Claude Sonnet 4.6 leads GDPval-AA, an OpenAI-created benchmark measuring AI performance on 44 professional knowledge work occupations. An Elo of 1,633 places it above Opus 4.6 and Gemini 3.1 Pro on real expert-level office work. For sustained writing tasks, content pipelines, and editorial work, this is the model I use.
GPT-5.4 is the strong second for anything requiring broad factual depth. Its hallucination rate is 33% lower than GPT-5.2, which matters when you're writing about topics where accuracy counts. For research-heavy long-form writing, the reduced hallucination profile justifies the slightly higher cost.
For pure creative writing with lots of personality and voice? Claude still reads more like a human writer than GPT's outputs, which tend to run more encyclopedic.
MATH Best for Mathematics & Competition Problems
Winner: Gemini 3.1 Pro + OpenAI o3 Pro (extreme difficulty)
Leads on MATH-Level 5 and AIME-class problems. o3 Pro for genuinely research-level mathematics.
Gemini 3.1 Pro's tiered thinking levels (Low, Medium, High) let you control compute per problem, which is a genuinely useful design for math workloads where some problems need 5 seconds of reasoning and others need 5 minutes.
For AIME and competition-level mathematics, the reasoning models outperform the general ones. OpenAI's o3 Pro sits at the extreme end: $150+ per million tokens, manual-rubric-graded responses, designed for genuine research-level mathematics. For 99.9% of people, that's overkill. For academic researchers solving open problems, it's the only serious option.
MULTIMODAL Best for Images, Audio & Video Understanding
Winner: GPT-4o (voice/audio) + Gemini 3.1 Pro (video/documents)
GPT-4o: real-time voice with natural prosody. Gemini 3.1 Pro: full video processing, 24-language voice.
GPT-4o's voice mode remains the most natural of any model. It matches prosody, recognizes emotional tone, and responds with something close to genuine conversational rhythm. If you're building voice interfaces or anything requiring natural spoken interaction, GPT-4o is the current standard.
Gemini 3.1 Pro handles the video and document analysis side: full-length video processing, 24-language voice support, 75% prompt caching discounts on repeated content. For applications that need to process video files, long PDFs, or audio transcripts at scale, Gemini's multimodal stack is ahead.
AGENTS Best for AI Agents & Autonomous Task Completion
Winner: Claude Opus 4.6 (complex agents) + Gemini 3.1 Pro (tool orchestration)
Claude's Agent Teams and adaptive thinking. Gemini's native tool use and structured output reliability.
Agentic AI, meaning models that take sequences of actions with tools to complete goals, has become the defining use case of 2026. Two models lead here for different reasons.
Claude Opus 4.6's Agent Teams feature lets multiple Claude instances collaborate on the same task. Combined with adaptive thinking and effort controls, it handles the kind of multi-hour, multi-step research and coding tasks that earlier models couldn't sustain.
Gemini 3.1 Pro's native tool use is more tightly integrated with real-time APIs, Google Search, and structured data outputs. For agents that need to interact with the open web or structured enterprise data, Gemini's tool reliability is better documented in production.
Grok 4.20's parallel multi-agent architecture, four agents running simultaneously on the same problem, is a genuinely different approach that hasn't fully landed in the market yet. Worth watching when the API opens.
LONG CONTEXT Best for Processing Very Long Documents
Winner: Llama 4 Scout (10M tokens) + Gemini 3.1 Pro (1M tokens, best closed-source)
Llama 4 Scout holds the largest context window of any model at 10 million tokens.
Llama 4 Scout's 10 million token context window is the largest in the industry. To put that in perspective, 10 million tokens is roughly 7,500,000 words, or around 25 full-length novels. If you need to process entire legal document repositories, giant codebases, or multi-year research archives in a single prompt, this is the only model that can do it.
Among closed-source options, Gemini 3.1 Pro at 1 million tokens and GPT-5.4 at 1 million tokens are equally matched, but Gemini's prompt caching discount (up to 75% off repeated content) makes it significantly cheaper for long-context applications that reuse the same context across many requests.
TRANSLATION Best for Multilingual & Translation Tasks
Winner: Gemini 3.1 Pro + Qwen 3.5 (Asian languages)
Gemini: 24-language voice, trained for global multilingual. Qwen: best on Chinese, Japanese, Korean.
Gemini 3.1 Pro's multilingual training is documented across 100+ languages with native voice in 24. For European and global language pairs, it consistently outperforms competitors on accuracy and register.
For East Asian languages, particularly Chinese-language tasks, Qwen 3.5 from Alibaba is the specialist pick. It was trained with native Chinese language data at a scale that no US lab matches. If your use case involves Chinese, Japanese, or Korean at volume, Qwen should be in your evaluation.
CUSTOMER SUPPORT Best for Customer Service Automation
Winner: Kimi K2 (Moonshot AI) + Claude Sonnet 4.6
Kimi K2 holds the #1 spot on Tau2-Bench Telecom, the agentic customer support benchmark.
Moonshot AI's Kimi K2 achieved the number one position on the Tau2-Bench Telecom benchmark, which specifically measures customer support automation in agentic settings. This is a data point most Western AI coverage misses, but for anyone building customer service agents, it's the most directly relevant benchmark available.
For English-language customer support at scale, Claude Sonnet 4.6 is the production-proven choice. At $3/$15 per million tokens with batch API discounts of 50% for non-urgent tasks, the economics for high-volume customer support work out better than GPT-5.4.
ENTERPRISE PRIVACY Best for Self-Hosted & Privacy-Sensitive Deployments
Winner: Llama 4 Maverick + DeepSeek V3.2
Open weights, self-hostable, no data sent to external APIs. Enterprise-grade quality.
Any organization that cannot send data to a third-party API, due to HIPAA, GDPR, client agreements, or security requirements, needs an open-weight model they can run on their own infrastructure.
Llama 4 Maverick offers the strongest combination of capability and ecosystem. The Meta ecosystem of fine-tuning tools, quantization recipes, and community adapters is larger than any other open-weight model family. DeepSeek V3.2 is a strong second: MIT License, GPT-4o-class performance, and $0.14 per million tokens on third-party hosting if full self-hosting isn't feasible.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Best AI Model by Budget
Budget shapes model choice as much as capability does. Here's the honest breakdown by spending tier.
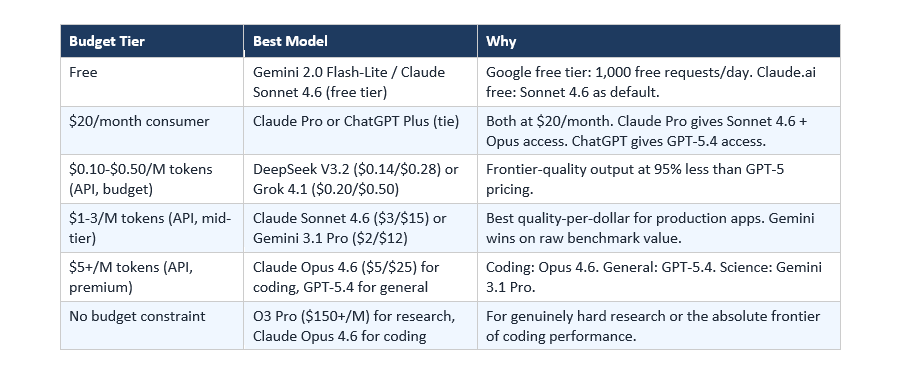
Best Free AI Model in 2026
What You Get Without Paying Google Gemini Flash gives you 1,000 free API requests per day — the most generous free tier of any frontier model. For the web interface, Claude.ai free gives you access to Claude Sonnet 4.6 (the model that tops professional writing benchmarks at Elo 1,633) with a limited daily message cap. ChatGPT free still runs on GPT-4o mini by default, not GPT-5. For daily use without paying anything: Gemini free tier is the best deal if you need volume. Claude free is the best deal if you need writing quality. ChatGPT free is the most familiar but no longer the most capable at the free tier.
6. Open-Source vs Closed-Source: Which Should You Choose?
The open vs closed question used to have an obvious answer: closed-source models were clearly better. In 2026, that's no longer true at the mid-tier and below.
Choose open-source if:
- You have data privacy or compliance requirements that prevent sending data to external APIs
- You need to fine-tune on proprietary data and want to own the resulting model
- You're building in a cost-sensitive environment where $0.01 per request is too expensive at scale
- You want to run inference on your own hardware with no ongoing API costs
Choose closed-source if:
- You need the absolute best performance on complex reasoning or coding tasks
- You want managed infrastructure, reliability SLAs, and support contracts
- You're building quickly and don't have ML engineers to handle model deployment
- You need multimodal capabilities, especially audio and video, which remain stronger in closed models
The honest middle ground: start with an open-weight model for development and cost estimation, then switch to a closed-source model only where the quality gap justifies the price. For many production applications, DeepSeek V3.2 or Llama 4 Maverick will be 'good enough' at 1/20th the cost.
7. Claude Pro vs ChatGPT Plus vs Gemini Advanced: Is the $20/Month Worth It?
For people who don't use the API and just want a monthly subscription:
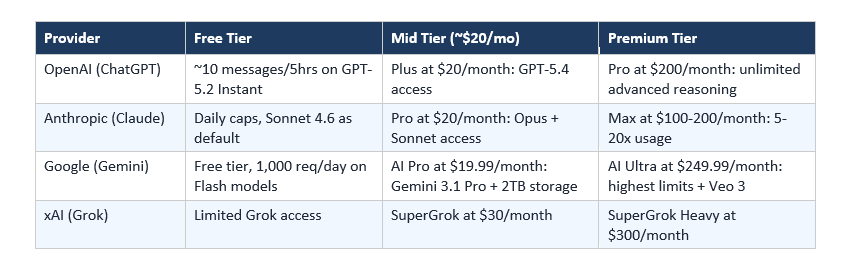
For most individual professionals, Claude Pro at $20/month ($17/month annual) offers the best combination of context window, output quality, and access to both Sonnet and Opus tiers. For anyone already inside the Google ecosystem, Gemini AI Pro's bundled 2TB storage and Workspace integration makes it the better value.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
8. API Pricing Comparison Table (Per Million Tokens)
Current API pricing as of March 2026. Input and output prices are listed separately. Output tokens cost 3-8x more than input tokens across most providers.
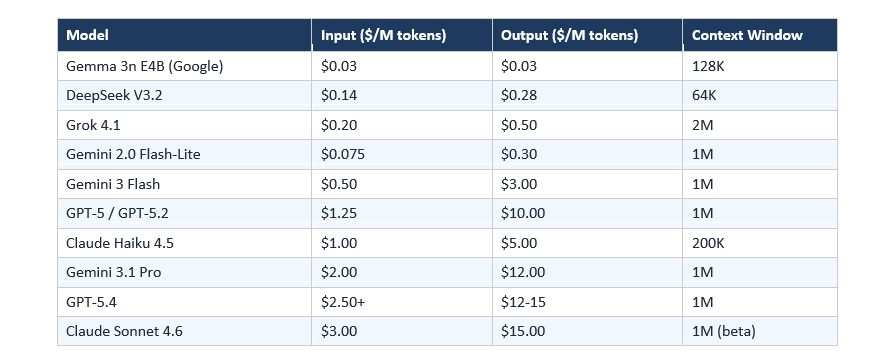
Cost-saving tip: All major providers offer prompt caching. Repeated system prompts or context can be cached at up to 90% off the standard input price. Anthropic's batch API offers 50% off for non-urgent, asynchronous tasks. Gemini's context caching provides up to 75% discounts on repeated long-context content.
9. How to Choose the Right AI Model for Your Use Case
Run through this decision tree before picking a model:
Step 1: What's your primary task? Use Section 4's winner boxes. If your task is coding, start with Claude Opus 4.6. If it's scientific reasoning, start with Gemini 3.1 Pro. Match task to domain winner first.
Step 2: Do you have data privacy requirements? If yes, you need an open-weight model. Llama 4 Maverick or DeepSeek V3.2 are the top choices depending on your compute budget.
Step 3: What's your token budget? If you're building a production application at scale, the cost difference between models is enormous. $0.14/M (DeepSeek) vs $5/M (Claude Opus) is a 35x difference. At 100 million tokens per month, that's $14,000 vs $500,000 per year.
Step 4: What does your ecosystem look like? Already deep in Google Workspace? Gemini 3.1 Pro integrates natively. Running GitHub Copilot? Claude Sonnet 4.6 powers it. Using Cursor or Windsurf? Claude Opus 4.6 is the default. Ecosystem fit matters for friction.
Step 5: Test before committing. Every major provider offers either a free tier or free credits. Run your actual use case, not a generic benchmark, against your top 2 candidates. Real-world task performance often differs from published benchmark scores.
Frequently Asked Questions
Which AI model is best for coding in 2026?
Claude Opus 4.6 leads on SWE-Bench Verified at 75.6%, making it the benchmark winner for general software engineering. For agentic terminal-based coding workflows, GPT-5.3 Codex is purpose-built and edges ahead. Grok 4.20's parallel multi-agent architecture is a strong emerging option at ~75% SWE-Bench.
Which AI model is best for scientific reasoning?
Gemini 3.1 Pro leads all models on GPQA Diamond (expert-level science) at 94.3%, ahead of GPT-5.4 at 92.8% and Claude Opus 4.6 at 91.3%. It also leads on ARC-AGI-2 at 77.1%, which tests novel problem-solving that cannot be memorized from training data.
What is the cheapest AI model that actually works in 2026?
DeepSeek V3.2 at $0.14 input / $0.28 output per million tokens delivers GPT-4o-class performance at roughly 95% less cost. For free options, Google offers 1,000 free requests per day on Gemini Flash-class models. Grok 4.1 at $0.20/$0.50 per million tokens is the cheapest closed-source frontier option.
What is the best open-source AI model in 2026?
Meta's Llama 4 Scout leads on context window at 10 million tokens, the largest of any model. GLM-5 from Zhipu AI holds the highest open-weight Intelligence Index score at 50. DeepSeek V3.2 offers the best price-to-performance of any open model for API use. All three are strong candidates depending on whether you prioritize context, intelligence, or cost.
Is Gemini 3.1 Pro better than Claude Opus 4.6?
On pure benchmark scores: Gemini 3.1 Pro leads on GPQA Diamond (94.3% vs 91.3%) and ARC-AGI-2 (77.1% vs 68.8%). Claude Opus 4.6 leads on SWE-Bench (75.6% vs 63.8%) and GDPval professional work tasks. Gemini is also cheaper at $2/$12 vs Claude's $5/$25 per million tokens. For science and long-context reasoning, Gemini wins. For coding and professional documents, Claude wins.
What is the best AI model for writing?
Claude Sonnet 4.6 leads the GDPval-AA Elo benchmark (1,633 points), which measures AI performance on expert-level professional writing tasks. For research-heavy long-form writing where factual accuracy matters, GPT-5.4's 33% lower hallucination rate compared to GPT-5.2 makes it the safer choice.
What AI models work without sending data to external servers?
Llama 4 (Meta), DeepSeek V3.2, Mistral Large 2, Qwen 3.5, and GLM-5 are all open-weight models that can be self-hosted on your own infrastructure. Llama 4 Maverick is the strongest general-purpose option with the largest fine-tuning ecosystem. DeepSeek V3.2 offers the best benchmark performance relative to compute cost.
How much does GPT-5 cost vs Claude in 2026?
GPT-5 / GPT-5.2 starts at $1.25/$10 per million input/output tokens. Claude Sonnet 4.6 costs $3/$15. Claude Opus 4.6 costs $5/$25. GPT-5.4 starts at approximately $2.50 per million input tokens. Grok 4.1 is the cheapest closed-source option at $0.20/$0.50. Gemini 3.1 Pro at $2/$12 currently offers the best price-to-capability ratio among frontier closed models.
Q: Is Claude better than ChatGPT in 2026?
Claude Sonnet 4.6 leads ChatGPT on professional writing (GDPval-AA Elo 1,633 vs GPT-5.4's 1,601) and coding (SWE-Bench 75.6% vs ~74.9%). ChatGPT (GPT-5.4) leads on broad factual accuracy with 33% fewer hallucinations than GPT-5.2. For coding and writing: Claude. For research documents: GPT-5.4.
Which AI should I use every day in 2026?
Claude Sonnet 4.6 for most professionals — it leads real-world office task benchmarks and costs $3 per million input tokens. If you're already in the Google ecosystem, Gemini Advanced is the better daily driver. For coding specifically, Claude Code powered by Opus 4.6 is the daily standard.
Is GPT-5 better than Claude Opus 4.6?
On different tasks: GPT-5.4 scores higher on hallucination reduction (33% improvement over GPT-5.2) and broad general reasoning. Claude Opus 4.6 scores higher on coding (SWE-Bench 75.6% vs GPT-5.4's ~74.9%) and professional writing. Neither is universally better — the task decides.
What is the best AI model for image generation in 2026?
Claude, GPT, and Gemini are text models — they do not generate images natively. For image generation: Midjourney v7 leads on artistic quality, Google Imagen 4 leads on photorealism and text accuracy, and Stable Diffusion 3.5 is the open-source standard.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper:
- 12+ AI Models in March 2026: The Week That Changed AI
- GPT-5.4 vs Gemini 3.1 Pro (2026): Which AI Wins?
- GPT-5.4 Review: Features, Benchmarks & Access (2026)
- Grok 4.20 Beta Explained: Non-Reasoning vs Reasoning vs Multi-Agent (2026)
- Gemini 3.1 Flash Lite vs 2.5 Flash: Speed, Cost & Benchmarks (2026)
- Gemini Embedding 2: First Multimodal Embedding Model (2026)
- Sarvam-105B: India's Open-Source LLM for 22 Indian Languages (2026)
Want to deploy these models in real products?
Join Build Fast with AI's Gen AI Launchpad, an 8-week program to go from 0 to 1 in building AI-powered apps with the best models available today.
Register: buildfastwithai.com/genai-course
References
- Artificial Analysis - AI Model Intelligence Index & Leaderboard (March 2026)
- LogRocket - AI Dev Tool Power Rankings March 2026
- Design for Online - The Best AI Models So Far in 2026
- IntuitionLabs - AI API Pricing Comparison 2026: Grok vs Gemini vs GPT vs Claude
- TLDL - LLM API Pricing March 2026 (GPT-5.4, Claude, Gemini, DeepSeek)
- Pluralsight - Best AI Models in 2026: What Model to Pick for Your Use Case
- gurusup.com - Best AI Model 2026: Comparison Guide
- LM Council - AI Model Benchmarks March 2026
- Anthropic - Claude 4.6 Model Card
- Google DeepMind - Gemini 3.1 Pro Technical Overview

