





Gemini Embedding 2: Google's First Multimodal Embedding Model (2026)
I've been building RAG systems for two years. And every single time, the messiest part wasn't the LLM - it was the embedding pipeline. One model for text. Another for images. A separate transcription step before you could even touch audio. It was duct tape all the way down.
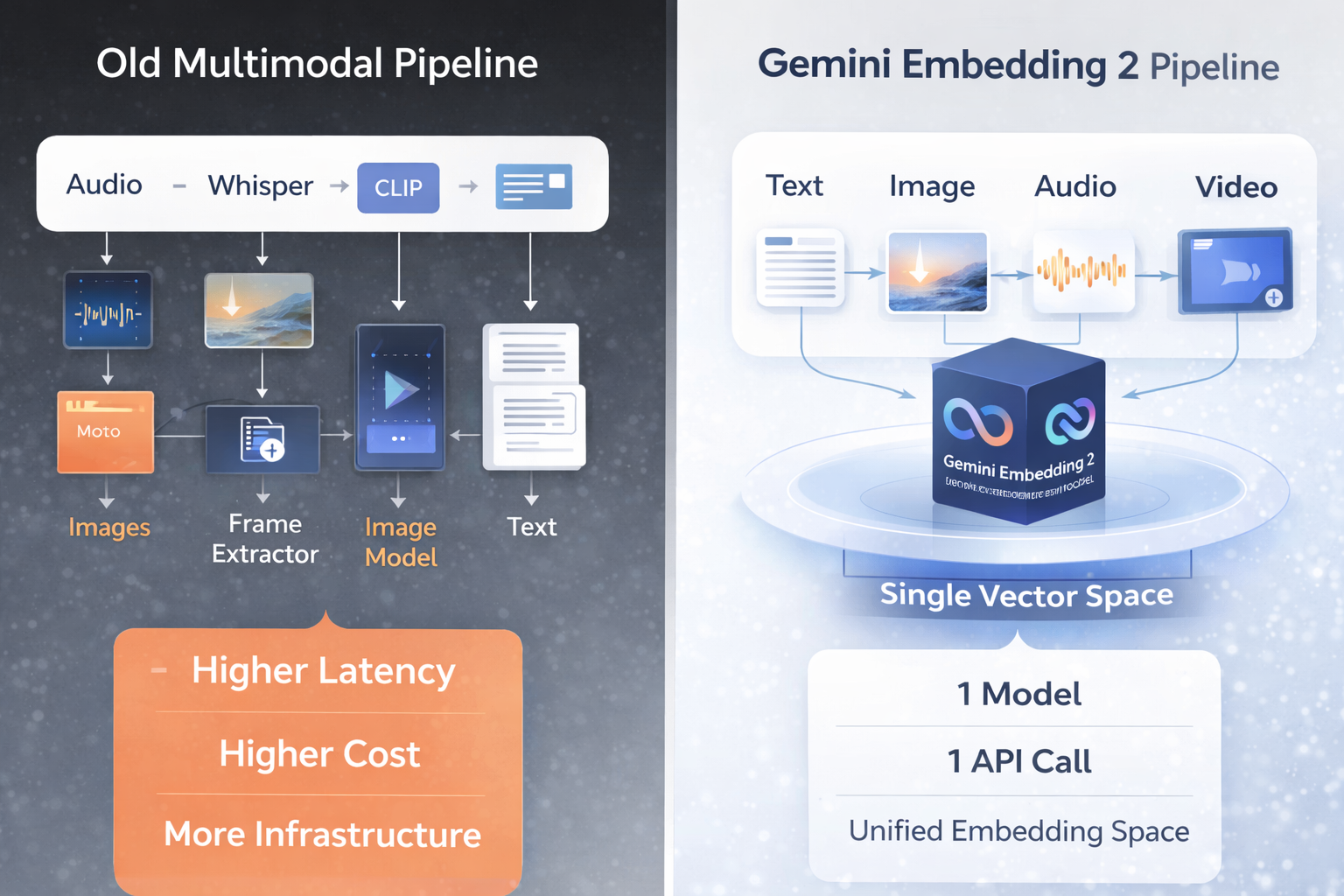
On March 10, 2026, Google changed that. Gemini Embedding 2 is the first natively multimodal embedding model from Google - one model that maps text, images, video, audio, and PDFs into a single unified vector space. No separate pipelines. No translation overhead. One API call, one embedding space, five modalities.
Early adopters are already reporting 70% latency reductions. Legal discovery teams saw a 20% improvement in recall. These aren't lab numbers - they're production results from companies that replaced 3-model pipelines with one endpoint.
Here's everything you need to know: what it is, how it compares, how to use it, and honestly - when it's worth the price and when it isn't.
1. What Is Gemini Embedding 2?
Gemini Embedding 2 is Google's first natively multimodal embedding model, available since March 10, 2026 via the Gemini API and Vertex AI under the model ID gemini-embedding-2-preview.
An embedding model converts raw content - a paragraph of text, a product photo, a customer support call recording - into a numerical vector. Once everything lives in the same vector space, you can run similarity searches across modalities. Ask a text question, get back a relevant video. Match an image to a product description. Search a PDF knowledge base by speaking into a microphone. That's the promise of unified multimodal embeddings.
Previous embedding models, including Google's own gemini-embedding-001, handled text only. If you wanted to embed images, you needed a separate model - CLIP, Voyage Multimodal, or similar. If you needed audio, you'd transcribe it first with Whisper, then embed the transcript. Each step added latency, cost, and potential information loss.
Gemini Embedding 2 collapses that entire pipeline into a single model. Logan Kilpatrick, Google DeepMind's Developer Relations lead, described the goal at launch: bring text, images, video, audio, and documents into the same embedding space without any intermediate translation.
Key Fact
Gemini Embedding 2 launched on March 10, 2026 as Google's first natively multimodal embedding model. Model ID: gemini-embedding-2-preview. Available on both the Gemini API and Vertex AI.

2. Key Features and Technical Specs
The spec sheet is where things get interesting. Gemini Embedding 2 packs a lot into a single API endpoint. Here's what matters:
Supported Input Modalities
- Text - standard text passages, queries, code snippets
- Images - up to 6 images per request
- Video - up to 128 seconds per request
- Audio -up to 80 seconds per request
- PDFs - up to 6 pages per request
Core Specs
- Input token limit: 8,192 tokens (4x more than embedding-001's 2,048)
- Output dimensions: Flexible, 128 to 3,072 (Matryoshka Representation Learning)
- Default output: 3,072-dimensional float vector
- Recommended dimensions: 768 (sweet spot), 1,536, or 3,072
- Language support: 100+ languages; top MTEB Multilingual leaderboard ranking
- Custom task instructions: Specify task:code_retrieval, task:search_result, etc. to tune embeddings
What Makes It Different
Two things stand out to me. First, the 8,192 token context window - that's four times what embedding-001 offered, and it matters enormously for embedding long documents without chunking them into tiny fragments. Second, the Matryoshka dimension flexibility: you can truncate output vectors to any size from 128 to 3,072 without retraining. Smaller vectors = cheaper storage + faster search, with minimal quality loss at 768 dimensions.
Pro Tip
Google explicitly recommends 768 dimensions as the sweet spot - 'near-peak quality at roughly one-quarter the storage footprint of 3,072 dimensions.' For most production use cases, 768 is the right default.
3. Benchmark Performance: How Good Is It Really?
Google published benchmark results across text, image, video, and multilingual tasks. The headline numbers:
- MTEB Multilingual: 69.9 - top of the leaderboard across 100+ languages
- MTEB Code: 84.0 - strongest open-API result for code retrieval
- Video retrieval (Vatex, MSR-VTT, Youcook2): outperforms all competing models by a wide margin
- Image benchmarks (TextCaps, Docci): competitive with Voyage Multimodal 3.5
The text-only MTEB gap between Gemini and competitors is real but not enormous. Where Gemini Embedding 2 has a genuine and significant lead is in the multimodal columns - especially video retrieval. No other commercial model currently handles video natively in an embedding endpoint.
I want to be honest here: for pure text RAG, OpenAI's text-embedding-3-large scores well and costs 35% less. If your pipeline is text-only with no plans to go multimodal, Gemini Embedding 2 isn't an obvious upgrade on benchmark quality alone. The story changes completely if you need cross-modal search.
Real-world production results are even more compelling. Sparkonomy (a creator platform) reported 70% latency reduction after replacing a 3-model pipeline with Gemini Embedding 2. Legal discovery platform Everlaw saw a 20% lift in recall for searching across heterogeneous legal documents. The gains aren't from faster hardware - they're from removing intermediate processing stages entirely.
4. Gemini Embedding 2 vs Competitors
Here's how Gemini Embedding 2 stacks up against the main alternatives:
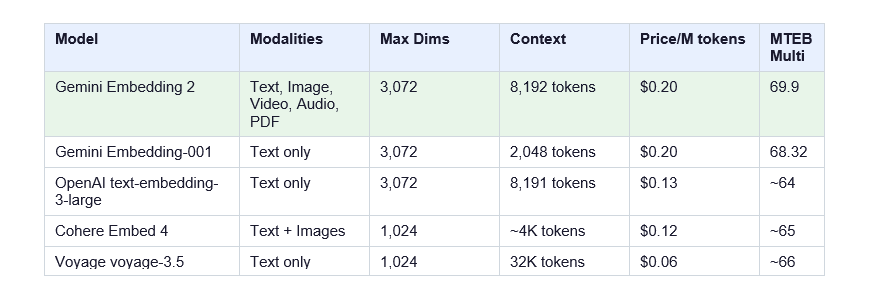
The comparison table tells you most of what you need to know. Gemini Embedding 2 is the only model covering all five modalities (text, image, video, audio, PDF) in a single vector space. OpenAI covers text only. Cohere Embed 4 handles text + images. Nobody else touches video or audio natively.
The pricing is fair for what you get. At $0.20/M tokens, it's more expensive than OpenAI's text-embedding-3-small ($0.02/M) - but that comparison is apples-to-oranges. Compare it against building an equivalent pipeline yourself (text model + CLIP for images + Whisper + audio embedding) and Gemini Embedding 2 almost certainly wins on both cost and complexity.
For more on Google's recent model releases, see our deep-dives on GPT-5.4 vs Gemini 3.1 Pro and Gemini 3.1 Flash Lite vs 2.5 Flash.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Pricing Breakdown: Is It Worth It?
$0.20 per million text tokens -that's the standard rate. The batch API cuts that to $0.10/M (50% off) for workloads that don't need real-time responses. Image, audio, and video inputs follow Gemini API's standard media token rates.
Quick math on the batch pricing: embed 1 million documents at 500 tokens each (375 words average), that's 500 billion tokens... wait, no - that's 500 million tokens total. At $0.10/M via batch, you're looking at $50 for 1 million documents. That's reasonable for most production workloads.
When It's Worth It
- You're building cross-modal search (text queries over image/video/audio libraries)
- Your pipeline currently chains 3+ specialized models together
- You need 100+ language support with high multilingual recall
- You want to embed meeting recordings, product images, and docs in the same search index
When It's Not Worth It
- Text-only RAG pipeline with no multimodal plans - OpenAI text-embedding-3-small at $0.02/M is 10x cheaper
- You need vectors compatible with existing gemini-embedding-001 indexes (embedding spaces are incompatible - you'd need to re-embed your entire dataset)
- Very long document context required - Voyage voyage-3.5 offers 32K token context vs Gemini's 8,192
Important Note
The embedding spaces between gemini-embedding-001 and gemini-embedding-2-preview are incompatible. If you're upgrading from embedding-001, you must re-embed your entire dataset. There is no migration path that preserves existing vectors.
6. Matryoshka Dimensions: Choose the Right Size
Matryoshka Representation Learning (MRL) lets you truncate the output vector to any size between 128 and 3,072 dimensions without retraining the model. Smaller vectors trade a little quality for significantly cheaper storage and faster similarity search.
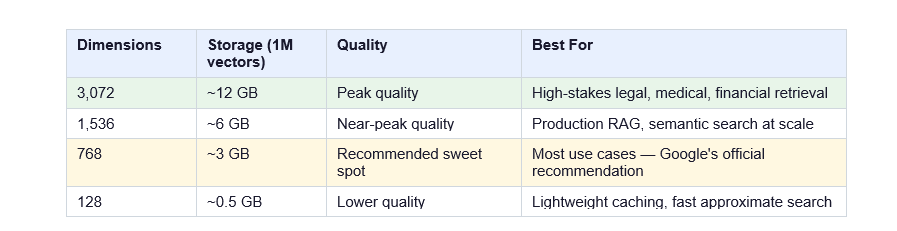
Google's own guidance: 768 dimensions delivers near-peak quality at one-quarter the storage cost of 3,072. I'd agree with that as a default starting point. If you're running high-stakes retrieval (legal discovery, medical records, financial documents), go 3,072. For everything else, start at 768 and run A/B tests before committing.
Storage perspective: 1 million vectors at 3,072 dimensions (float32) uses approximately 12 GB. At 768 dimensions, that's about 3 GB. If you're indexing tens of millions of items, that difference becomes very real in your infrastructure costs.

7. How to Use It: Python Tutorial (Step by Step)
Here's a complete walkthrough, from API key to embedding your first multimodal content.
Step 1: Install the SDK
pip install google-genaiStep 2: Basic Text Embedding
from google import genai
client = genai.Client(api_key='YOUR_API_KEY')
result = client.models.embed_content(
model='gemini-embedding-2-preview',
contents='What is the best embedding model in 2026?'
)
print(result.embeddings[0].values[:5]) # Preview first 5 dimensions
# Output: [0.023, -0.041, 0.087, 0.012, -0.065, ...]
Step 3: Multimodal Embedding (Text + Image)
from google import genai
from google.genai import types
import base64
client = genai.Client(api_key='YOUR_API_KEY')
# Load and encode your image
with open('product_image.jpg', 'rb') as f:
image_data = base64.b64encode(f.read()).decode('utf-8')
# Embed text and image together
result = client.models.embed_content(
model='gemini-embedding-2-preview',
contents=[
'Blue wireless headphones with noise cancellation',
types.Part.from_bytes(data=base64.b64decode(image_data),
mime_type='image/jpeg')
],
config=types.EmbedContentConfig(
task_type='RETRIEVAL_DOCUMENT',
output_dimensionality=768 # Use Google's recommended size
)
)
print(len(result.embeddings[0].values)) # 768Step 4: Semantic Search with Cosine Similarity
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Assume you have a list of pre-computed document embeddings
query = 'wireless headphones for travel'
query_result = client.models.embed_content(
model='gemini-embedding-2-preview',
contents=query,
config=types.EmbedContentConfig(
task_type='RETRIEVAL_QUERY',
output_dimensionality=768
)
)
query_vec = np.array(query_result.embeddings[0].values).reshape(1, -1)
# Compare against stored document vectors
scores = cosine_similarity(query_vec, document_vectors)[0]
top_k = scores.argsort()[-5:][::-1] # Top 5 results
print('Top matches:', [documents[i] for i in top_k])Notice the task_type parameter - use RETRIEVAL_QUERY for search queries and RETRIEVAL_DOCUMENT for documents being indexed. This is one of the improvements in Gemini Embedding 2 over older models: specifying intent directly improves embedding quality for your actual use case.
For a broader look at building AI pipelines, see our guide on How to Build No-Code Automation with Make.com + ChatGPT.
8. Real-World Use Cases
Where does Gemini Embedding 2 actually shine? Here are the use cases that become significantly easier when you have a single multimodal embedding space:
Multimodal E-commerce Search
Embed product titles, descriptions, and product images into the same vector space. Let customers search with text ("blue running shoes under $100") and return results ranked by similarity across both text AND visual features. Previously this required aligning CLIP vectors with text embeddings - a messy reconciliation problem Gemini Embedding 2 eliminates.
Audio Knowledge Base Search
Embed meeting recordings, podcast episodes, or support calls directly - no transcription step required. A support agent can type a customer's complaint and instantly surface similar past calls from the knowledge base, even if no one ever transcribed them.
Legal and Document Discovery
This is where the 20% recall improvement Everlaw reported comes from. Legal discovery requires searching across scanned PDFs, image attachments, video depositions, and text documents simultaneously. A unified embedding space means one query covers all of them. That's not a minor improvement - missing a relevant document in discovery has real consequences.
RAG Systems with Richer Context
Standard text-only RAG misses context that lives in charts, diagrams, and images embedded in documents. With Gemini Embedding 2, your RAG pipeline can retrieve based on visual content inside PDFs, not just the surrounding text. For technical documentation, research papers, and financial reports, this is a meaningful quality upgrade.
If you're building AI-powered tools, check out what's possible with Google Pomelli AI and NotebookLM Cinematic Video Overview - Google's broader AI tooling ecosystem is getting serious.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. Limitations and When NOT to Use It
I'd be doing you a disservice if I didn't flag the real limitations here.
- Still in preview: The model ID is gemini-embedding-2-preview. Google could change pricing or behavior before GA. They've done this with previous models, though the GA pricing typically matches preview pricing.
- Per-request media caps: 6 images, 80s audio, 128s video, 6 PDF pages per request. Fine for indexing individual items, but you'll hit limits trying to embed large documents in a single call.
- Incompatible vector spaces: Cannot migrate from gemini-embedding-001. A full re-embedding of your dataset is required. For large production indexes, this is a significant operational cost.
- Text-only use cases pay a price premium: OpenAI text-embedding-3-small at $0.02/M is 10x cheaper for text-only workloads. Unless you need cross-modal search, the premium may not be justified.
- Context window ceiling: 8,192 tokens is good, but Voyage voyage-3.5 offers 32K. For very long document embedding without chunking, Voyage still wins on context.
- No vector compatibility with older Gemini embeddings: Each generation produces fundamentally different representations. Plan for re-indexing costs in your migration budget.
My honest take: if you're building a new system from scratch with any multimodal requirements - start here. If you're migrating a large text-only production system - do the cost math carefully before committing to the re-embedding cost.
FAQ: Gemini Embedding 2
What is the Gemini Embedding 2 model?
Gemini Embedding 2 (model ID: gemini-embedding-2-preview) is Google's first natively multimodal embedding model, launched March 10, 2026. It maps text, images, video, audio, and PDFs into a single unified 3,072-dimensional vector space, eliminating the need for separate embedding models per modality.
What embedding model does Gemini use?
As of March 2026, Google offers two main embedding models: gemini-embedding-001 (text-only, generally available, GA) and gemini-embedding-2-preview (multimodal, in public preview). For new projects requiring cross-modal search, gemini-embedding-2-preview is the recommended option.
Can I use Gemini for embeddings?
Yes. Gemini Embedding 2 is accessible via the Gemini API (google-genai Python SDK) and Vertex AI. A free tier is included. Paid usage is $0.20 per million text tokens, or $0.10/M via the batch API. A Google AI Studio API key is all you need to get started.
What is the use of the Gemini Embedding model?
Embedding models convert content into numerical vectors for semantic similarity tasks. Common applications include RAG (Retrieval Augmented Generation) systems, semantic search, document clustering, recommendation systems, and content deduplication. Gemini Embedding 2 extends all of these to work across text, images, video, audio, and documents simultaneously.
What is the best Gemini model for embeddings in 2026?
For multimodal use cases: gemini-embedding-2-preview. For text-only production workloads already using embedding-001: stick with embedding-001 (generally available, no re-embedding required). For text-only workloads starting fresh and cost-sensitive: OpenAI text-embedding-3-small at $0.02/M is 10x cheaper.
How much does Gemini Embedding 2 cost?
$0.20 per million text tokens (standard), $0.10 per million tokens via the batch API (50% discount). Image, audio, and video inputs are billed at Gemini API media token rates. A free tier is available for testing and development.
What are the output dimensions for Gemini Embedding 2?
Gemini Embedding 2 uses Matryoshka Representation Learning, supporting flexible output dimensions from 128 to 3,072. The default is 3,072. Google recommends 768 as the sweet spot for production use - near-peak quality at one-quarter the storage cost.
Is Gemini Embedding 2 compatible with gemini-embedding-001?
No. The embedding spaces are incompatible. If you're migrating from gemini-embedding-001 to gemini-embedding-2-preview, you must re-embed your entire dataset. There is no migration path that preserves existing vectors.

