





GPT-5.4 vs Gemini 3.1 Pro (2026): Which AI Model Should You Use for Real Work?
On March 5, 2026, two things happened at the same time. GPT-5.4 launched. And Gemini 3.1 Pro, already sitting at the top of the Artificial Analysis Intelligence Index with a score of 57, refused to budge. No new model on top. Just a tie. For the first time in recent memory, OpenAI dropped a flagship model and it did not take the crown outright.
I have been running both models through real work over the past week, reading every independent benchmark I could find, and building a picture of what each model is actually good at. What I found surprised me. These two are not competing on the same dimension anymore.
GPT-5.4 is betting on computer use and professional document work. Gemini 3.1 Pro is betting on scientific reasoning and cost. And the gap between them on their respective strengths is bigger than most comparison articles are letting on.
Here is the full breakdown.
The March 2026 Frontier AI Landscape
March 2026 is the most competitive moment in AI history, and I do not say that loosely. Within a span of 14 days, OpenAI and Google each released their best model ever, and both of them are scoring identically on the most respected independent intelligence benchmark on the market.
Here is the quick context before you get into the numbers. Gemini 3.1 Pro launched on February 19 as Google DeepMind's strongest model yet, featuring a 2-million-token context window and a 94.3% score on GPQA Diamond, the graduate-level science reasoning benchmark. Two weeks later, GPT-5.4 arrived on March 5 with native computer use, an 83% GDPval knowledge work score, and the distinction of being the first AI model to exceed human expert performance on autonomous desktop tasks.
Both models now sit at 57 on the Artificial Analysis Intelligence Index out of 285 models evaluated. That tie is not a coincidence. It reflects how tight the frontier has become and, more practically, why picking the "best" model in 2026 requires asking "best for what" before you evaluate anything else.
I have read our own GPT-5.4 review and the data is clear: these models split categories instead of one dominating the other. Let me show you exactly how.
Benchmark Comparison: Full Data Table
These numbers are pulled from independent benchmark sources, Artificial Analysis, digitalapplied.com, and awesomeagents.ai, as of March 2026. I am not citing model cards. Model cards are marketing.
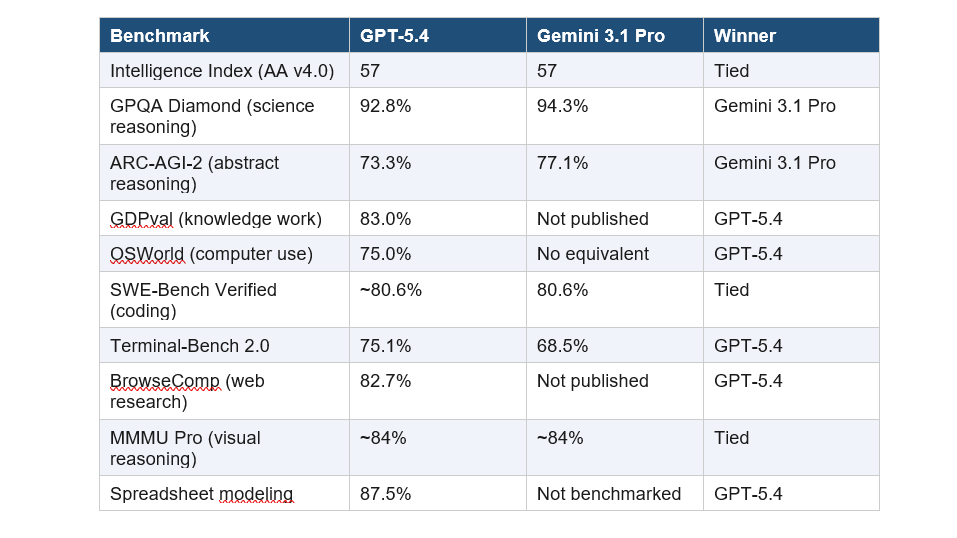
My honest read: Gemini wins on reasoning. GPT-5.4 wins on productivity and automation. On coding, they are basically identical unless you bring Claude Opus 4.6 into the comparison, at which point Opus at 80.8% SWE-Bench takes the coding crown.
Speaking of Opus, if you want the full three-way view, I covered that in our post on GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5.
GPT-5.4 vs Gemini 3.1 Pro: Reasoning and Science
Gemini 3.1 Pro is the stronger reasoning model. Full stop. Its 94.3% on GPQA Diamond is 1.5 points ahead of GPT-5.4's 92.8%, and on ARC-AGI-2, the abstract reasoning benchmark that measures genuine problem-solving rather than memorized patterns, Gemini leads 77.1% to 73.3%.
What does GPQA Diamond actually measure? It tests PhD-level biology, chemistry, and physics questions, questions that require specialist knowledge to answer correctly, not just pattern matching from training data. Gemini's lead here is meaningful.
GPT-5.4 Pro at the $30/$180 per million token tier closes the GPQA gap to 94.4%, which is marginally ahead of Gemini. But that is a completely different pricing conversation. At standard rates, Gemini reasons better and costs less.
My take: if your work involves scientific literature review, medical research, complex legal analysis, or anything requiring PhD-level knowledge synthesis, Gemini 3.1 Pro is the better tool at the standard tier. Do not let the marketing around GPT-5.4 obscure that.
Computer Use and Agentic Tasks: Where GPT-5.4 Wins
This is GPT-5.4's defining capability, and it has no real competition from Gemini at this point. GPT-5.4 scores 75.0% on OSWorld-Verified, making it the first AI model in history to exceed human expert performance on desktop computer use, where the human baseline sits at 72.4%.
What this means in practice: GPT-5.4 can click buttons, fill forms, navigate applications, draft emails with attachments, and complete multi-step workflows across software tools, entirely without browser plugins or special integrations. Gemini 3.1 Pro has no equivalent capability published at this level.
On Terminal-Bench 2.0, GPT-5.4 leads Gemini 75.1% to 68.5%, a 6.6-point gap that matters for developers running CLI-heavy workflows. GPT-5.4 also hits 83% on GDPval, which benchmarks performance across 44 professional occupations.
For teams replacing RPA tools, building desktop automation agents, or running workflows that interact with real software interfaces, this is the deciding factor regardless of how the reasoning benchmarks compare. The computer use story is one-sided right now.
GPT-5.4 ships in three variants. The base model handles general tasks. The Thinking variant adds extended chain-of-thought reasoning. The Pro variant runs parallel reasoning threads at $30/$180 per million tokens.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Coding Performance: SWE-Bench and Real Dev Tasks
On SWE-Bench Verified, the main coding benchmark, GPT-5.4 and Gemini 3.1 Pro are essentially tied at around 80.6%. If pure coding performance is your primary use case, neither model beats the other here.
The real story is that Claude Opus 4.6 at 80.8% SWE-Bench is still the marginal leader for pure software engineering precision. I noted this in our GPT-5.4 review: if you are building production code, do not make your decision based on this comparison alone.
Where GPT-5.4 differentiates in the coding context is Terminal-Bench 2.0 at 75.1% and spreadsheet modeling at 87.5% with native Excel and Google Sheets plugins. For financial analysis, business reporting, and developer workflows that blend code with business tools, GPT-5.4 is stronger.
Gemini 3.1 Pro's coding advantage is architectural. Its mixture-of-experts design and thinking-level controls are tuned for stable, high-precision outputs in long-running workflows. For codebases that exceed 200K tokens, Gemini's 2M context window means you can load entire repositories where GPT-5.4's standard 272K context cannot.
Pricing Breakdown: What You Actually Pay Per 1M Tokens
The pricing comparison is more nuanced than most articles make it sound, and getting it wrong can wildly distort your cost projections.
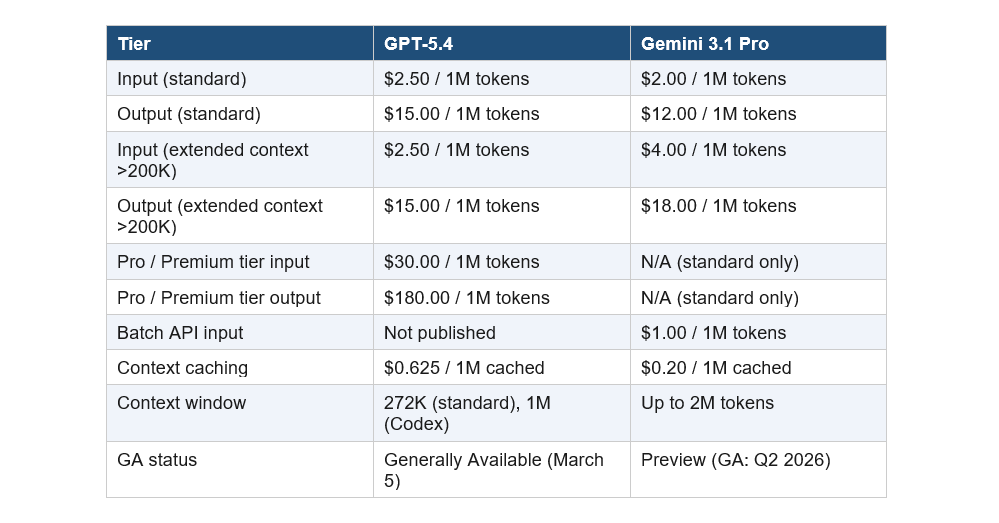
The headlines about Gemini being 15x cheaper are technically accurate but practically misleading. They compare GPT-5.4 Pro at $30/M to Gemini Standard at $2/M. Standard vs Standard, the actual gap is about 20%. That is real money at scale but not a different category.
Where Gemini genuinely wins on cost: the Batch API at $1.00/$6.00 and context caching at $0.20/M make high-volume, non-realtime workloads significantly cheaper than anything GPT-5.4 offers right now.
One important caveat on Gemini: it is still in Preview. GA is expected in Q2 2026. Developers have reported capacity issues and quota bugs during the preview period. For production workloads where reliability matters more than cost, GPT-5.4's GA status is a real advantage.
Context Window and Latency: The Numbers Nobody Talks About
GPT-5.4 standard ships with a 272K token context window. With the Codex and developer platform integrations, it scales to 1 million tokens. Gemini 3.1 Pro offers up to 2 million tokens natively.
For most tasks, 272K is enough. A full novel is around 150K tokens. A large codebase with a few hundred files sits around 200-400K. But if you are working with entire legal case files, multi-source research corpora, or large enterprise codebases, Gemini's 2M window is a genuine operational advantage.
On latency, here is the number that surprises people: Gemini 3.1 Pro has a 44.5-second Time to First Token. That is real. For real-time chat applications or anything requiring fast responses, that latency makes Gemini the wrong choice regardless of its benchmark scores. GPT-5.4 is significantly faster to first token.
This is something I also noticed in our Gemini 3.1 Flash Lite vs 2.5 Flash comparison: Google's Pro-tier models prioritize depth over speed. If latency is a product requirement, Gemini Flash variants are a better fit than Gemini Pro.
Multimodal Capabilities: Text, Images, Audio, and Video
Gemini 3.1 Pro is the only model in this comparison with true four-modality native support: text, image, audio, and video in a single model. GPT-5.4 handles text and images natively at the API level. It does not handle audio or video natively.
For most enterprise and developer workflows, this difference does not matter. The majority of production AI use cases involve text, documents, and code. But if your product involves video analysis, podcast transcription, or audio-alongside-text reasoning, Gemini wins this category without a real competitor.
On visual reasoning, MMMU Pro scores are roughly tied. Both models handle image-heavy workflows at comparable quality. GPT-5.4's native Excel and Google Sheets plugins make it stronger for visual document work in a business context. Gemini's video and audio capabilities make it stronger for media and research workflows.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Which Model Should You Choose? Use-Case Guide
There is no universal answer, and anyone claiming otherwise is not working with both models seriously. Here is my honest routing guide based on the data.
Choose GPT-5.4 if you need:
- Desktop automation and RPA replacement (75% OSWorld, first to beat human baseline)
- Professional knowledge work (83% GDPval across 44 occupations)
- Terminal and CLI-heavy developer workflows (75.1% Terminal-Bench 2.0)
- Spreadsheet modeling and financial analysis (87.5% with native Excel/Sheets plugins)
- Production-ready GA stability with broad benchmark coverage
Choose Gemini 3.1 Pro if you need:
- Scientific and graduate-level reasoning (94.3% GPQA Diamond)
- Abstract problem-solving (77.1% ARC-AGI-2)
- Massive context windows (up to 2M tokens for full codebase or legal document analysis)
- Audio and video processing alongside text in a single model call
- High-volume batch workloads where $1.00/$6.00 Batch API pricing matters)
The honest recommendation:
I use both. GPT-5.4 for document-heavy professional tasks and anything involving computer use or automation. Gemini 3.1 Pro for research synthesis, scientific analysis, and any workload where I am sending large context and want to keep costs down.
If you are building a product and want to understand how to structure your AI model stack, our Best ChatGPT Prompts guide for 2026 walks through practical prompting strategies that work across both models.
The contrariant point I want to make: the benchmark convergence happening at the frontier is the actual story of 2026. These three models, GPT-5.4, Gemini 3.1 Pro, and Claude Opus 4.6, are all within 2-3 percentage points of each other on most evaluations. At some point, pricing, developer experience, and reliability start mattering more than raw benchmark position. Build your stack around that reality, not around loyalty to a single provider.
10. Frequently Asked Questions
Is GPT-5.4 better than Gemini 3.1 Pro?
Neither model wins outright. GPT-5.4 leads on computer use (75% OSWorld), professional knowledge work (83% GDPval), and terminal tasks. Gemini 3.1 Pro leads on abstract reasoning (94.3% GPQA Diamond, 77.1% ARC-AGI-2) and costs about 20% less at standard rates. Both score identically at 57 on the Artificial Analysis Intelligence Index as of March 2026.
Which is cheaper, GPT-5.4 or Gemini 3.1 Pro?
Gemini 3.1 Pro is cheaper at standard rates: $2.00/$12.00 per 1M tokens versus GPT-5.4's $2.50/$15.00. For high-volume batch workloads, Gemini's Batch API at $1.00/$6.00 and context caching at $0.20/M make it significantly more cost-effective. The 15x cost gap cited in some articles compares GPT-5.4 Pro ($30/M) to Gemini Standard ($2/M), which is not a fair production comparison.
Is Gemini 3.1 Pro available for production use right now?
Gemini 3.1 Pro is currently in Preview status as of March 2026, with General Availability expected in Q2 2026. Developers have reported capacity issues and quota bugs during the preview period. GPT-5.4 launched as Generally Available on March 5, 2026, making it the more stable production choice right now.
What is GPT-5.4's context window?
GPT-5.4 standard ships with a 272K token context window. Through the Codex and developer platform integrations, it scales to 1 million tokens. Gemini 3.1 Pro offers up to 2 million tokens natively at $4.00/$18.00 per 1M for requests exceeding 200K tokens.
Can Gemini 3.1 Pro do computer use like GPT-5.4?
No, not at the same level. GPT-5.4 introduced native computer use scoring 75.0% on OSWorld-Verified, the first AI to exceed the human baseline of 72.4%. Gemini 3.1 Pro does not have a published equivalent computer use capability at this benchmark level as of March 2026.
Which AI model is best for coding in 2026?
For pure SWE-Bench performance, GPT-5.4 and Gemini 3.1 Pro are tied at approximately 80.6%. Claude Opus 4.6 marginally leads at 80.8% SWE-Bench Verified for production coding precision. For large codebase analysis that requires 200K-plus tokens of context, Gemini 3.1 Pro's 2M window is a practical advantage over GPT-5.4's standard 272K.
How much does GPT-5.4 cost per month for a developer?
GPT-5.4 is available via ChatGPT Plus, Team, and Pro subscriptions and via the OpenAI API at $2.50 per 1M input tokens and $15.00 per 1M output tokens (standard tier). In ChatGPT, select GPT-5.4 Thinking from the model picker on Plus, Team, or Pro plans. API access uses model ID gpt-5.4 or the pinned snapshot gpt-5.4-2026-03-05.
Is Gemini 3.1 Pro smarter than GPT-5.4?
By the independent Artificial Analysis Intelligence Index, both score identically at 57 out of 285 models evaluated. Gemini leads on scientific reasoning and abstract problem-solving. GPT-5.4 leads on computer use and professional knowledge work. Raw "smartness" is not a useful framing. The practical question is which model performs better on your specific task category.
Stay Updated
If this comparison helped, subscribe to Build Fast With AI for weekly breakdowns of the frontier model race, practical AI build guides, and the benchmark analysis nobody else is doing. New posts drop every week.
Internal References
- GPT-5.4 Review: Features, Benchmarks & Access (2026)
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 (2026)
- Gemini 3.1 Flash Lite vs 2.5 Flash: Speed, Cost & Benchmarks (2026)
- Best ChatGPT Prompts in 2026: 200+ Prompts for Work, Writing, and Coding

