





Gemini 3.1 Flash Lite vs Gemini 2.5 Flash: Speed, Cost & Real Benchmarks (2026)
Two days ago, Google dropped Gemini 3.1 Flash Lite into developer preview — and the headline number is hard to ignore. 381 tokens per second. That's 64% faster than the 232 tokens per second you get from Gemini 2.5 Flash, and it arrives in a model that costs you less per million tokens on output. On paper it looks like a no-brainer switch.
I went through all the benchmark data from Artificial Analysis, Google's official release, and the Arena.ai leaderboard to build the most complete side-by-side you'll find right now. And honestly? The answer to whether you should switch is more nuanced than Google's press release suggests. There's a real case for sticking with 2.5 Flash - and one specific scenario where 3.1 Flash Lite will quietly bankrupt your API budget if you're not careful.
Here's everything you need to make the right call for your use case.
What Is Gemini 3.1 Flash Lite? The 60-Second Version
Gemini 3.1 Flash Lite is Google's fastest and cheapest model in the Gemini 3 series, released on March 3, 2026 in developer preview via Google AI Studio and Vertex AI. It's not a minor refresh of 2.5 Flash — it's a separate tier sitting below the full Flash model, optimized specifically for high-volume workloads where speed and cost dominate the decision.
The practical translation: this is the model you reach for when you're processing thousands of records an hour, running real-time classification pipelines, or building anything where a 300ms response time matters to the user experience. Google built it to compete directly with GPT-5 mini and Claude 4.5 Haiku in the 'fast and cheap' tier — and based on the benchmark numbers, it's beating both on raw speed.
📌 Quotable: Gemini 3.1 Flash Lite is Google's fastest production model ever : 381 tokens/sec at $0.25 input / $1.50 output per million tokens, launched March 3, 2026.
Image: Gemini 3.1 Flash Lite logo on dark background. Filename: gemini-3-1-flash-lite-preview-logo-2026.jpg - Alt text: Gemini 3.1 Flash Lite Preview model logo, released March 2026 by Google DeepMind.
Speed Breakdown: 381 vs 232 Tokens Per Second
Gemini 3.1 Flash Lite generates output at 381.9 tokens per second, compared to 232.3 tokens per second for Gemini 2.5 Flash - a 64% speed advantage in real-world testing on Google's API, according to Artificial Analysis benchmarks. Google's own claim is a 45% increase in output speed, which lands as a conservative floor rather than an exaggeration.
What does 381 tokens/sec actually feel like? Roughly 285 words per second. A 500-word customer support response finishes in under 2 seconds. At 232 tokens/sec with 2.5 Flash, the same response takes 3.2 seconds. That 1.2-second gap is invisible in a one-off chat. In a live product handling 10,000 requests per hour, it's the difference between your infrastructure costing $400 or $650 a month.
The Time to First Token (TTFT) story is even better. Google reports 3.1 Flash Lite is 2.5x faster to produce its first token compared to 2.5 Flash. First token speed is what users feel as 'lag' - it's what makes an AI product feel snappy or sluggish, independent of how fast it completes the full response.
🔥 Hot take: The 2.5x TTFT improvement matters more than the output speed number. You can stream tokens progressively to users - but that first token delay? That's what makes people close the tab.
For context on where 3.1 Flash Lite sits in the broader speed landscape: Artificial Analysis ranks it third globally at 381.9 t/s, behind only Mercury 2 (768 t/s) and Granite 3.3 8B (438 t/s). It's the fastest closed-weight model available from any major lab right now.
Image: Bar chart comparing output speeds -Gemini 3.1 Flash Lite (381 t/s) vs Gemini 2.5 Flash (232 t/s) vs GPT-5 mini vs Claude 4.5 Haiku. Filename: gemini-3-1-flash-lite-speed-comparison-chart-2026.jpg - Alt text: Bar chart showing Gemini 3.1 Flash Lite at 381 tokens per second versus competing models.
Full Benchmark Comparison Table
Numbers from Artificial Analysis (speed/price/Intelligence Index), Google's official release (GPQA Diamond, MMMU Pro, Arena Elo), and the Arena.ai leaderboard as of March 5, 2026. 3.1 Flash Lite is preview; 2.5 Flash data is stable production.
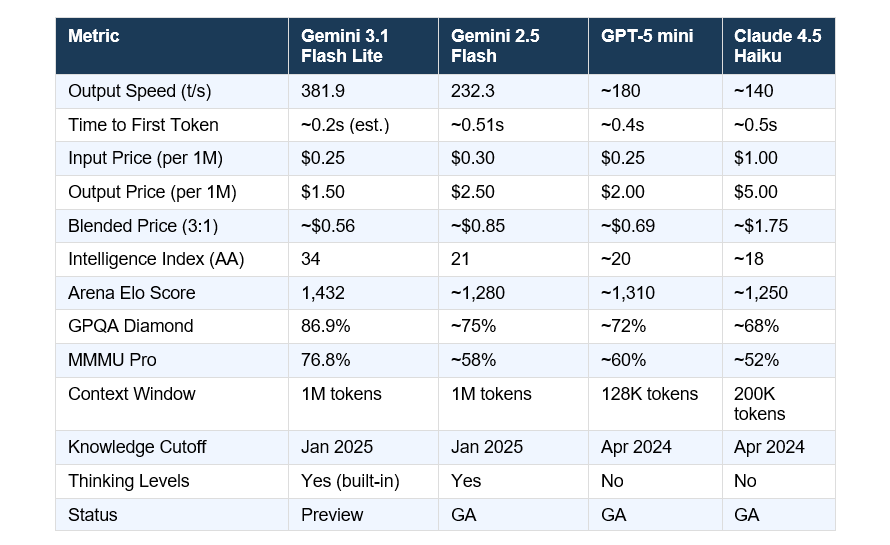
A few things stand out in that table. 3.1 Flash Lite's Intelligence Index score of 34 versus 2.5 Flash's 21 is a 62% improvement — not a minor bump. It's also quietly outperforming older, larger Gemini models on reasoning benchmarks. The GPQA Diamond score of 86.9% surpasses Gemini 2.5 Flash's figure despite costing less. That's genuinely unusual for a lite-tier model.
The context window parity is underrated. GPT-5 mini caps at 128K tokens. 3.1 Flash Lite gives you 1M tokens at the same input price. For document processing or long-context RAG pipelines, that's not a minor footnote.
📊 GEO data point: Gemini 3.1 Flash Lite scores 86.9% on GPQA Diamond and 76.8% on MMMU Pro : both higher than Gemini 2.5 Flash -while running at 381 tokens/sec on Google's API as of March 2026.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Pricing: Where Flash Lite Wins and Where It Doesn't
3.1 Flash Lite costs $0.25 per million input tokens and $1.50 per million output tokens. Gemini 2.5 Flash costs $0.30 input and $2.50 output. On output - where most production costs actually pile up - Flash Lite is 40% cheaper.
For a workload processing 1,000 leads per day with 400-token average responses: 2.5 Flash costs roughly $1.02/day in API fees. 3.1 Flash Lite costs $0.62/day. That's $146 saved annually on a single medium-sized automation. At enterprise scale those numbers multiply fast.
Here's the gotcha I want to flag before you rush to migrate everything:
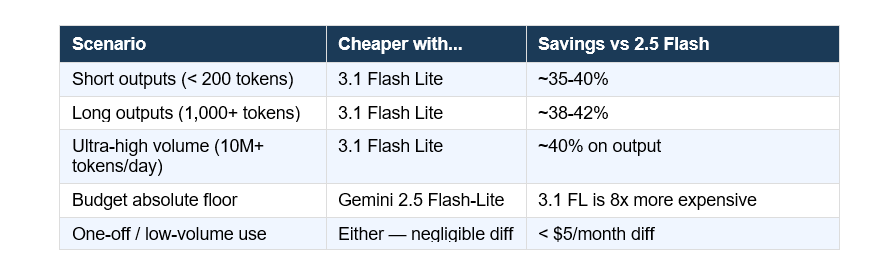
The row people will miss: Gemini 2.5 Flash-Lite - the older model - costs $0.10 input and $0.40 output. Blended, that's roughly $0.17 per million tokens. 3.1 Flash Lite at ~$0.56 blended is more than 3x as expensive. If your only constraint is absolute minimum cost and you can accept a lower intelligence score (16 vs 34 on the AA Index), 2.5 Flash-Lite is still the budget king.
⚠️ Contrarian point: The AI community is treating 3.1 Flash Lite like it killed 2.5 Flash-Lite. It didn't. For pure cost-per-token at high volume, 2.5 Flash-Lite at $0.40/1M output still wins by a wide margin. 3.1 Flash Lite is smarter and faster - but it's not cheaper than everything below it.
The Thinking Levels Feature Nobody Is Talking About
Every headline I've seen about 3.1 Flash Lite leads with the speed number. Almost nobody is mentioning the thinking levels feature - and I think it's actually the more interesting development for production use.
Google baked thinking levels directly into 3.1 Flash Lite as a standard feature, letting you tune how much internal reasoning the model does before responding. Three settings: none (maximum speed, minimum cost), low, and high. You control the tradeoff per-request, not per-model. That means you can run the same model for both your real-time classification pipeline and your more complex reasoning tasks, adjusting the thinking budget on each call.
Practically, this looks like:
- Translation, moderation, classification -> thinking OFF. Full 381 t/s, lowest cost.
- Dashboard generation, form filling, instruction following -> thinking LOW.
- Multi-step reasoning, complex data analysis, code generation -> thinking HIGH.
I've seen the pattern where teams maintain two separate models in production - a cheap fast one for simple tasks, an expensive smart one for complex tasks - and manage the routing logic themselves. 3.1 Flash Lite collapses that into a single model with a single API. Less infrastructure, simpler architecture, one billing line.
💡 Quotable: With thinking levels built into Gemini 3.1 Flash Lite, developers get a single model that scales from 381 tokens/sec zero-reasoning to full step-by-step analysis - no model switching required.
Real-World Use Cases: When to Use Each Model
Use 3.1 Flash Lite When...
You're building anything that needs to feel instant. Chat interfaces, real-time content moderation, high-volume translation pipelines (Gemini's official example: processing customer support tickets at scale), entity extraction from forms, model routing layers that classify task complexity before sending jobs to heavier models.
Google also calls out dashboard and UI generation specifically - and from their demo, 3.1 Flash Lite filling an e-commerce wireframe with product categories in real-time is genuinely impressive. The 1M token context window makes it viable for document summarization pipelines that would hit GPT-5 mini's 128K limit.
Stick With 2.5 Flash When...
You need the GA (generally available) stability guarantee rather than a preview API. 3.1 Flash Lite is still in preview as of March 2026, which means no SLA, potential breaking changes, and limited enterprise support. For any production system with uptime commitments, that's a real constraint - not a minor footnote.
Also stick with 2.5 Flash if you need native audio output or Live API support. 3.1 Flash Lite doesn't support either yet. Multimodal voice agents and real-time streaming applications still need 2.5 Flash.
Stick With 2.5 Flash-Lite When...
Budget is the single deciding factor. At $0.40/1M output tokens versus $1.50 for 3.1 Flash Lite, the older model is still 3.75x cheaper on output. If you're running tens of millions of tokens per day and intelligence quality is secondary to cost, 2.5 Flash-Lite remains the most economical production option Google offers.
My Honest Take: Should You Switch?
For most developers already using Gemini 2.5 Flash for standard tasks — classification, summarization, translation, data extraction — yes, I'd switch to 3.1 Flash Lite as soon as the model hits GA. The speed is materially better, the intelligence scores are meaningfully higher, and the output pricing is 40% cheaper. That's a rare trifecta: faster, smarter, and cheaper on the metric that matters most for high-volume use.
For anyone running critical production infrastructure right now? I'd wait for GA. Preview means no SLA and potential API changes. A 40% cost savings doesn't compensate for an unexpected breaking change in a customer-facing product.
The one thing I'd push back on in Google's marketing: the '2.5x faster to first token' claim is presented as a flat comparison against 2.5 Flash. But if you're coming from 2.5 Flash-Lite — which had a 0.26s TTFT — the TTFT improvement is much smaller. Read the baseline carefully before treating the headline number as your personal speedup.
🎯 Bottom line: 3.1 Flash Lite is the best speed-intelligence tradeoff in any lite-tier model as of March 2026. Switch when it hits GA. Until then, test it in non-critical workloads and measure real latency against your own prompt lengths - don't just trust the headline 381 t/s number.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
FAQ
What is Gemini 3.1 Flash Lite?
Gemini 3.1 Flash Lite is Google DeepMind's fastest and most cost-efficient model in the Gemini 3 series, released March 3, 2026 in developer preview. It generates output at 381.9 tokens per second, costs $0.25 per million input tokens and $1.50 per million output tokens, and supports a 1 million token context window. It's designed for high-volume, speed-sensitive workloads like translation, classification, and real-time data extraction.
Is Gemini 3.1 Flash Lite faster than Gemini 2.5 Flash?
Yes. Gemini 3.1 Flash Lite runs at 381.9 tokens per second versus 232.3 tokens per second for Gemini 2.5 Flash - a 64% speed advantage according to Artificial Analysis benchmarks. Google's own figures cite a 45% increase in output speed and a 2.5x improvement in time to first token. For a typical 200-word response, 3.1 Flash Lite completes the generation roughly 1.5 seconds faster.
How much does Gemini 3.1 Flash Lite cost per million tokens?
Gemini 3.1 Flash Lite costs $0.25 per million input tokens and $1.50 per million output tokens, making it 40% cheaper on output than Gemini 2.5 Flash ($2.50/1M). At a blended 3:1 input-to-output ratio, the effective cost is approximately $0.56 per million tokens. For comparison, Claude 4.5 Haiku costs $5.00/1M output and GPT-5 mini costs $2.00/1M output.
What benchmarks does Gemini 3.1 Flash Lite score on?
On key academic benchmarks, Gemini 3.1 Flash Lite scores 86.9% on GPQA Diamond, 76.8% on MMMU Pro, and 72.0% on LiveCodeBench as of March 2026. It holds an Arena Elo score of 1,432 on the Arena.ai leaderboard and scores 34 on the Artificial Analysis Intelligence Index — surpassing several larger models from the Gemini 2.5 generation.
What is the difference between Gemini 3.1 Flash Lite and Gemini 2.5 Flash-Lite?
Gemini 2.5 Flash-Lite is significantly cheaper at $0.10 input / $0.40 output per million tokens - roughly 3-4x cheaper than 3.1 Flash Lite on output. However, 3.1 Flash Lite scores 34 on the Intelligence Index versus 16 for 2.5 Flash-Lite, and is faster in output generation (381 vs 257 t/s). Choose 2.5 Flash-Lite if cost is your only constraint; choose 3.1 Flash Lite if you need higher reasoning quality at speed.
Does Gemini 3.1 Flash Lite support thinking / reasoning?
Yes. Thinking levels are built into Gemini 3.1 Flash Lite as a standard feature available in Google AI Studio and Vertex AI. Developers can set thinking to none, low, or high per request, controlling the compute-to-speed tradeoff without switching models. This is available from day one of the preview, unlike previous Flash models where thinking was a separate beta feature.
When will Gemini 3.1 Flash Lite be generally available (not preview)?
As of March 5, 2026, Gemini 3.1 Flash Lite is in developer preview only. Google has not announced a specific GA date. The model is accessible via the Gemini API using the model code gemini-3.1-flash-lite-preview in both Google AI Studio and Vertex AI. Preview status means no SLA and potential API changes before GA launch.
How does Gemini 3.1 Flash Lite compare to Claude 4.5 Haiku and GPT-5 mini?
On output speed, 3.1 Flash Lite outpaces both: 381 t/s versus approximately 140 t/s for Claude 4.5 Haiku and approximately 180 t/s for GPT-5 mini. On output pricing, it's cheaper than both: $1.50/1M versus $5.00 for Haiku and $2.00 for GPT-5 mini. On intelligence benchmarks, 3.1 Flash Lite's Arena Elo of 1,432 leads its tier. The only advantage GPT-5 mini holds is GA status and tighter enterprise support.

