




Best AI Models April 2026: Every Major Release Ranked by Real Benchmarks
Twelve significant AI model releases in a single week. That happened in March 2026. Not a month -- a week.
I tracked every launch, ran the benchmark numbers, and compared the specs across GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6, GLM-5, DeepSeek V4, Llama 4, and a dozen others. The short version: the gap between open-source and proprietary AI has nearly closed. The longer version is what this guide is for.
LLM Stats, which monitors 500+ models in real time, logged 255 model releases from major organizations in Q1 2026 alone. The pace is not slowing. April continues where March left off, with at least five frontier-class models now competing within a few benchmark points of each other. Picking the right one for your use case now requires actual data -- not marketing summaries.
I am going to give you that data. Model by model. Benchmark by benchmark. With honest takes on where each model actually wins.
1. The State of AI in April 2026 -- What Changed
The frontier AI landscape in April 2026 is the most competitive it has ever been, and the old framing of a two-horse race between OpenAI and Google no longer reflects reality.
Six months ago, the top closed-source models -- GPT-5.2, Gemini 3 Pro, Claude Opus 4.5 -- held a commanding lead over any open-weight alternative. That is gone. GLM-5 from Z.ai (formerly Zhipu AI) scores 77.8% on SWE-bench Verified, just three points behind Claude Opus 4.6's 80.8%. MiniMax M2.5 hits 80.2% on the same benchmark -- essentially matching the best closed models. DeepSeek V4, built on Huawei Ascend chips without a single Nvidia GPU, runs at 1 trillion parameters and costs $0.28 per million input tokens.
Three things define the April 2026 AI moment:
- Cost collapse: What cost $500/month last year runs for $50 today. DeepSeek V3.2 delivers ~90% of GPT-5.4's performance at 1/50th the price.
- Context window explosion: Llama 4 Scout ships with a 10 million token context window. Gemini 3.1 Flash Lite offers 1 million tokens at $0.25 per million. Enterprise memory constraints that defined 2024 workflows are gone.
- Architecture diversification: Grok 4.20 runs four parallel agents instead of one big model. GLM-5 uses DeepSeek Sparse Attention to cut deployment costs. Qwen 3.5's 9B model matches models 13x its size on graduate-level benchmarks.
My honest take: the model you pick still matters, but it matters less than it did 12 months ago. The gap at the top of the leaderboard is now so narrow that workflow, prompting, and integration quality account for more of your output quality than which frontier model you are running.
2. Benchmark Explainer -- How to Read the AI Rankings
Before the model breakdown, here is what each major benchmark actually tests. Knowing this matters because labs cherry-pick the metrics where they look best.
SWE-bench Verified
The most practically meaningful coding benchmark in 2026. It gives models real GitHub issues from popular Python repositories and measures whether the model can resolve them end-to-end. As of March 20, 2026, Gemini 3.1 Pro Preview leads at 78.80%, with Claude Opus 4.6 Thinking and GPT-5.4 both at 78.20%.
ARC-AGI-2
Tests novel reasoning -- the kind that cannot be memorized from training data. Gemini 3.1 Pro's 77.1% on ARC-AGI-2 is more than double the previous version's score, which tells you something real about architectural improvement.
GPQA Diamond
Graduate-level questions in biology, physics, and chemistry, written by domain experts and designed to resist simple search lookups. Gemini 3.1 Pro leads at 94.3%. Claude Opus 4.6 and GPT-5.4 cluster around 87-89%.
LM Council / LMArena Elo
Human preference ratings from blind side-by-side comparisons. GLM-5 holds the top open-source Chatbot Arena Elo at 1451. The LM Council leaderboard at lmcouncil.ai aggregates 2,500 expert-level questions across mathematics, humanities, and natural sciences -- created in partnership with the Center for AI Safety.
Artificial Analysis Intelligence Index
A composite score normalizing performance across multiple benchmarks. Gemini 3.1 Pro Preview and GPT-5.4 both score 57, with Claude Opus 4.6 at 53 and Claude Sonnet 4.6 at 52.
One rule I follow: never trust a model's self-reported benchmarks. Always look for third-party evaluation on Vals.ai, SWE-rebench.com, or LM Council. The self-reported numbers are usually the best-case scenario.
3. Top AI Models April 2026 -- Detailed Breakdown
Gemini 3.1 Pro (Google, February 19, 2026)
Gemini 3.1 Pro is the strongest all-around model available as of April 2026 by multiple independent benchmarks. It leads SWE-bench Verified at 78.80%, posts 94.3% on GPQA Diamond (ahead of both Claude and GPT-5.4 in independent testing), and scores 77.1% on ARC-AGI-2 -- double its predecessor's result.
The pricing is what makes this remarkable: $2 per million input tokens and $12 per million output tokens, unchanged from Gemini 3 Pro. Google gave users a generational upgrade at no extra cost. The Artificial Analysis Intelligence Index ties Gemini 3.1 Pro with GPT-5.4 at 57 points, both at the top of 305 models ranked.
For agentic workflows, multi-step reasoning, and large-context tasks, Gemini 3.1 Pro is the strongest general-purpose choice right now.
GPT-5.4 (OpenAI, March 5, 2026)
GPT-5.4 unifies the GPT and Codex lines into a single model for the first time. It comes in three variants -- Standard ($2.50/$15 per million tokens), Thinking (reasoning-first), and Pro ($30/$180, maximum capability). All support a 1 million token context window with a 2x cost surcharge beyond 272K tokens.
Its headline numbers: 57.7% on SWE-bench Pro, 33% fewer individual claim errors than GPT-5.2, and 83% on OpenAI's GDPval knowledge-work benchmark. The most genuinely novel feature is Tool Search, which dynamically loads tool definitions only when needed rather than bloating every prompt with your entire tool library -- a real efficiency gain for complex agentic systems.
BenchLM.ai's composite scoring puts GPT-5.4 Pro at the top with a score of 92, followed by Gemini 3.1 Pro at 87 and Claude Opus 4.6 at 85.
Claude Opus 4.6 (Anthropic, February 5, 2026)
Claude Opus 4.6 is the benchmark leader for real-world coding agent workflows. It scores 80.8% on SWE-bench Verified, and Claude Code running on Opus achieves 80.9% -- slightly above the raw model. The Adaptive Thinking mode decides autonomously when deeper reasoning is needed without requiring user configuration, which is a meaningful UX win for production deployments.
Pricing at $5/$25 per million input/output tokens puts it at the expensive end of the frontier, but for teams where code quality directly impacts revenue, the premium is often justified. The Artificial Analysis Intelligence Index ranks Opus 4.6 at 53 -- third overall behind Gemini 3.1 Pro and GPT-5.4.
Claude Sonnet 4.6 (Anthropic, February 17, 2026)
Sonnet 4.6 is the model I recommend to most development teams right now. It scores 79.6% on SWE-bench Verified -- within 1.2 points of Opus 4.6 -- and matches Opus on OfficeQA, which tests enterprise document, chart, PDF, and table comprehension. Pricing at $3/$15 per million tokens is 40% cheaper than Opus.
The 1 million token context window is currently in beta. When it goes GA, the value proposition here becomes impossible to ignore for production teams processing large codebases or document libraries.
GLM-5 and GLM-5.1 (Z.ai / Zhipu AI, February 17 -- March 27, 2026)
GLM-5 is the most important open-source release of 2026. The architecture: 744 billion total parameters, 40 billion active parameters, built on Mixture of Experts with DeepSeek Sparse Attention, trained on 28.5 trillion tokens -- entirely on Huawei Ascend chips without Nvidia hardware.
The benchmark profile: 77.8% SWE-bench Verified (best among open-weight models), #1 Chatbot Arena Elo at 1451 for open-source, and leading scores on BrowseComp, MCP-Atlas, and tau-squared-Bench for agentic tasks. On AIME 2025 mathematical reasoning, GLM-5 scores 92.7%, ahead of DeepSeek, Gemini, and Llama.
GLM-5.1, released March 27, 2026, refined the model's coding specifically. In a Claude Code evaluation, GLM-5.1 scored 45.3 versus Claude Opus 4.6's 47.9 -- 94.6% of Opus performance. The GLM Coding Plan starts at $3/month versus Claude Max at $100-200/month. For budget-constrained teams doing high-volume coding, this is the most disruptive price-performance story in the current cycle.
I will say it directly: GLM-5.1 at $3/month doing 94.6% of what Claude Opus does at $100+/month is the biggest value story in AI right now. If you have not tested it, you are leaving money on the table.
DeepSeek V4 (DeepSeek, Early March 2026)
DeepSeek V4 hits 1 trillion total parameters with 32 billion active parameters per token, using a MODEL1 architecture that delivers 40% memory reduction and 1.8x inference speedup versus V3. Native multimodal support covers text, images, and code in a single set of weights.
The geopolitical angle is significant: V4 was trained and runs on Huawei Ascend chips, not Nvidia. Given US export controls, DeepSeek has demonstrated that frontier AI is achievable without American GPU hardware. For cost-sensitive deployments, DeepSeek V3.2 (the production API version) runs at approximately $0.28/$0.42 per million tokens -- delivering roughly 90% of GPT-5.4's output quality at 1/50th the price.
Llama 4 Scout and Maverick (Meta, March 2026)
Meta's Llama 4 family introduces two models with fundamentally different value propositions. Scout ships with 10 million token context -- the largest of any open-weight model, and one of the largest available anywhere. It runs on 17B active parameters from 109B total (Mixture of Experts), making it deployable on accessible hardware while processing entire codebases or document collections in a single pass.
Maverick targets performance over context, with 17B active parameters from 400B total (128 experts), 1 million token context, and pricing at $0.19-$0.49 per million blended tokens. Both are genuinely open-weight. For teams with data sovereignty requirements or on-premise deployment needs, Llama 4 Maverick is the most compelling option available.
Qwen 3.5 Small Series (Alibaba, March 1, 2026)
Alibaba's Qwen 3.5 Small series deserves more attention than it is getting. The 9B model scores 81.7% on GPQA Diamond -- ahead of GPT-OSS-120B at 71.5%. On HMMT Feb 2025 math competition benchmarks, the 9B hits 83.2% versus 76.7% for a model 13x its size. All four models (0.8B, 2B, 4B, 9B) are natively multimodal and Apache 2.0 licensed.
The 2B variant runs locally on an iPhone in airplane mode with 4GB of RAM. At approximately $0.10 per million input tokens via API, the cost advantage over frontier closed models is staggering -- roughly 13x cheaper than Claude Opus 4.6 for a model that matches or beats much larger systems on several benchmarks.
MiniMax M2.5
MiniMax M2.5 is the most underrated model of the current release cycle. It scores 80.2% on SWE-bench Verified -- 0.6 points below Claude Opus 4.6, ahead of most other models. Pricing: $0.30/$1.20 per million tokens for standard, $0.30/$2.40 for the Lightning variant with doubled throughput. MiniMax reports that M2.5-generated code now accounts for 80% of newly committed code at their own company.
Grok 4.20 (xAI, February 17, 2026)
Grok 4.20 takes a different architectural bet from everyone else: instead of scaling a single model, it runs four agents in parallel with different specializations. Real-time access to X (formerly Twitter) data is unique in the frontier model space. With a 128K context window, it is less competitive on long-document tasks than Gemini or Claude. The API is still not fully open as of early April 2026, which limits independent evaluation.
The four-agent architecture is intellectually interesting. If xAI publishes full benchmark results and opens the API, Grok 4.20 could look very different in next month's rankings.
NVIDIA Nemotron 3 Super (NVIDIA, March 2026)
NVIDIA is now a serious model provider, not just a chip company. Nemotron 3 Super runs 120B total parameters with 12B active (Mamba-Transformer MoE hybrid), scores 60.47% on SWE-bench Verified, and delivers 2.2x throughput over previous generation models. The Nemotron Speech variant achieves 10x faster real-time speech recognition than comparable models. Fully open-source.
4. Master Comparison Table -- Every Model Side by Side
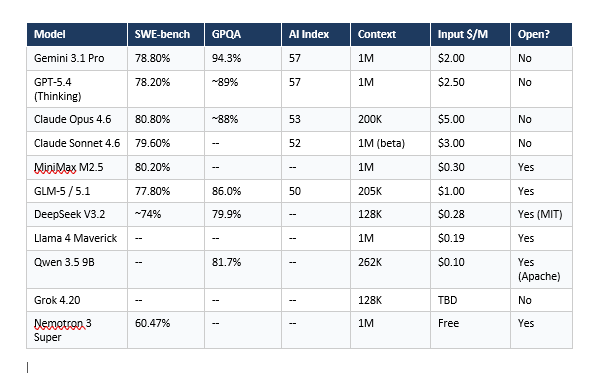
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Best AI Model for Specific Use Cases
Best AI Model for Coding (April 2026)
Claude Opus 4.6 leads on SWE-bench Verified at 80.8%, with Gemini 3.1 Pro at 78.8% and Claude Sonnet 4.6 at 79.6%. For teams running Claude Code specifically, Opus delivers 80.9% on the SWE-rebench evaluation. If budget is the constraint, GLM-5.1 hits 94.6% of Opus coding performance at a fraction of the cost.
Best pick: Claude Sonnet 4.6 for most teams (near-Opus quality, 40% cheaper). Claude Opus 4.6 for high-stakes production coding where every percentage point matters. GLM-5.1 Coding Plan at $3/month for budget-conscious individual developers.
Best AI Model for Reasoning and Research
Gemini 3.1 Pro leads on GPQA Diamond at 94.3% and ARC-AGI-2 at 77.1%. For graduate-level scientific reasoning, it is the clear choice. GPT-5.4 Thinking mode and Claude Opus 4.6 with Adaptive Thinking are close second options. Qwen 3.5's 9B model is the surprising budget pick -- 81.7% on GPQA Diamond at $0.10/million tokens.
Best AI Model for Long Documents and Large Context
Llama 4 Scout's 10 million token context is unmatched for processing entire repositories, legal document collections, or codebases in a single pass. For closed-source options, Gemini 3.1 Flash Lite offers 1 million tokens at $0.25/million -- the most affordable large-context option. Claude Sonnet 4.6's 1M context beta is worth watching for enterprise document workflows.
Best Free or Budget AI Model
Qwen 3.5 9B at $0.10/million input tokens is the benchmark leader in the sub-$0.20 tier. DeepSeek V3.2 at $0.28/million delivers frontier-adjacent reasoning. GLM-5.1 Coding Plan at $3/month is the best value for coding-heavy workflows. Nemotron 3 Super is fully open-source and free for self-hosting teams comfortable with 120B-parameter deployment.
Best Open-Source AI Model for Coding
GLM-5 leads the open-source SWE-bench ranking at 77.8%. Kimi K2 Thinking holds the best Pass@1 on SWE-rebench among open models. MiniMax M2.5 at 80.2% SWE-bench is technically open-weight and priced as aggressively as any closed model. For teams wanting full weights and Apache 2.0 licensing, Qwen 3.5 is the most commercially permissive high-performer available.
6. Open-Source vs Closed-Source -- The 2026 Reality Check
The standard argument for 12 months was that open-source models were two years behind the frontier. That argument is now empirically wrong.
GLM-5 is within 3 points of Claude Opus 4.6 on SWE-bench. Kimi K2 Thinking leads the open-source SWE-rebench Pass@1. DeepSeek V3.2 delivers 90% of GPT-5.4 quality at 1/50th the cost. Alibaba's 9B model beats 120B models on GPQA Diamond.
The remaining advantages of closed-source models in 2026 are:
- Safety fine-tuning and content policy reliability -- Anthropic and OpenAI invest more here
- Multimodal maturity -- GPT-5.4 and Gemini 3.1 Pro still lead on image, video, and audio reasoning
- Long-term model availability guarantees and enterprise SLAs
- Claude Code and similar tooling built around specific model capabilities
The remaining advantages of open-source models are costs (10-50x cheaper in many cases), data sovereignty (deploy on your own hardware), no vendor lock-in, customization via fine-tuning, and commercial licensing flexibility (MIT for DeepSeek, Apache 2.0 for Qwen).
My contrarian take: for most product teams shipping AI features in 2026, starting with an open-source model and upgrading to closed-source only where the performance gap matters is the correct default strategy. The assumption used to be the reverse. That assumption is now backwards.
7. What Is Coming Next -- Grok 5, Claude Mythos, GPT-5.5
The Q2 2026 pipeline is the most anticipated in AI history. Based on pretraining completion signals and company announcements:
- GPT-5.5 (codename Spud): Completed pretraining around March 24, 2026. OpenAI has not announced a release date publicly.
- Claude Mythos (Anthropic): Leaked context from prediction markets triggered speculation in March 2026. Anthropic has not confirmed the name or release timeline.
- Grok 5 (xAI): Elon Musk has discussed Grok 5 as significantly more capable than Grok 4.20's current offering. No confirmed date.
- Gemini 3.2 (Google): Google's pattern of quarterly major releases would put a follow-up to Gemini 3.1 in June 2026.
The pattern I am watching: every major release cycle, the open-source models close the gap further. If GLM-5.1 is 94.6% of Opus 4.6 coding performance, the next generation of open models will likely exceed current closed-source capabilities. The companies that have built sustainable moats through data, tooling, and ecosystem -- not just model weights -- will be the ones still standing in 2027.
Frequently Asked Questions
What is the best AI model in April 2026?
By composite benchmark score, GPT-5.4 Pro leads at 92 (BenchLM.ai), followed by Gemini 3.1 Pro at 87 and Claude Opus 4.6 at 85. For coding specifically, Claude Opus 4.6 leads SWE-bench Verified at 80.8%. For cost-performance, GLM-5.1 at $3/month delivers 94.6% of Claude Opus 4.6's coding benchmark score.
Is Gemini 3.1 Pro the best AI model right now?
Gemini 3.1 Pro leads three independent rankings in April 2026: SWE-bench Verified at 78.80%, GPQA Diamond at 94.3%, and ARC-AGI-2 at 77.1% (double its predecessor's score). It ties GPT-5.4 at the top of the Artificial Analysis Intelligence Index at 57 points. For general-purpose reasoning and multimodal tasks, it is the strongest option at its $2/$12 per million token price point.
What is LM Council AI and how does it rank models?
LM Council (lmcouncil.ai) is an independent AI benchmark platform created in partnership with the Center for AI Safety. It uses 2,500 expert-level, multi-modal questions covering mathematics, humanities, and natural sciences from nearly 1,000 expert contributors. Unlike self-reported benchmarks from labs, LM Council provides third-party evaluation of GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, and others on the same standardized question set.
Is Claude or ChatGPT better in 2026?
It depends on the task. Claude Opus 4.6 leads SWE-bench Verified for coding at 80.8%, while GPT-5.4 leads on the BenchLM.ai composite score at 92. Claude Sonnet 4.6 matches Opus on document comprehension at lower cost. GPT-5.4's Tool Search and built-in computer use give it unique advantages for complex agentic workflows. For most developers, Claude Sonnet 4.6 and GPT-5.4 Standard are the right comparison at similar price points ($3 vs $2.50 per million input tokens).
What are the top open-source AI models in April 2026?
GLM-5 leads open-source SWE-bench Verified at 77.8% and holds the top Chatbot Arena Elo at 1451. GLM-5.1 hits 94.6% of Claude Opus 4.6's coding score at a $3/month subscription price. Kimi K2 Thinking leads open-source SWE-rebench Pass@1. DeepSeek V3.2 (MIT license, $0.28/million tokens) delivers roughly 90% of GPT-5.4 quality. Qwen 3.5 9B (Apache 2.0, $0.10/million tokens) punches far above its parameter count on reasoning benchmarks.
What is the best AI model for coding in 2026?
Claude Opus 4.6 leads SWE-bench Verified at 80.8%, with Claude Code on Opus reaching 80.9%. MiniMax M2.5 scores 80.2% at a fraction of the cost. Claude Sonnet 4.6 at 79.6% offers near-Opus performance at Sonnet pricing. For open-source, GLM-5 at 77.8% is the strongest option with full downloadable weights. GLM-5.1 Coding Plan at $3/month is the best value for budget-constrained developers.
Which AI model has the biggest context window in 2026?
Llama 4 Scout holds the largest context window at 10 million tokens -- the biggest among any open-weight model available in April 2026. For closed-source options, Grok 4 Fast supports 1 million tokens. Claude Sonnet 4.6 has a 1 million token beta. Gemini 3.1 Flash Lite offers 1 million tokens at $0.25 per million input tokens -- the most affordable large-context option commercially available.
What is GLM-5 and how does it compare to Claude?
GLM-5 is Z.ai's (formerly Zhipu AI's) latest open-weight model, released February 17, 2026. It uses a Mixture of Experts architecture with 744 billion total parameters and 40 billion active parameters, trained on 28.5 trillion tokens on Huawei Ascend hardware. On SWE-bench Verified, GLM-5 scores 77.8% versus Claude Opus 4.6's 80.8% -- a 3-point gap. GLM-5.1, released March 27, 2026, reaches 94.6% of Claude Opus 4.6's coding benchmark score at $3/month versus Anthropic's $100-200/month plans.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
- GLM-5.1 Review vs Claude Opus -- Coding Benchmark Deep Dive:
- 12+ AI Models in March 2026 -- The Week That Changed AI:
• Qwen 3.6 Plus Preview -- 1M Context, Speed & Benchmarks 2026:
- Qwen3.5-Omni Review -- Does It Beat Gemini in 2026?:
- What Is Mixture of Experts (MoE)? How It Works (2026):
- Google Gemma 4 -- Best Open AI Model in 2026?:
Related Cookbooks
References
1. SWE-bench Official Leaderboard -- Vals.ai:
2. SWE-rebench Community Leaderboard:
3. BenchLM.ai Overall AI Rankings (April 4, 2026):
4. Artificial Analysis LLM Leaderboard:
5. GLM-5 Hugging Face Model Card (Z.ai):
6. GLM-5 arXiv Technical Report -- From Vibe Coding to Agentic Engineering:
7. LM Council AI Benchmarks (April 2026):
8. Build Fast with AI -- AI Models March 2026 Releases:

