




GLM-5.1 Review: The Open-Source Model That's 2.6 Points Behind Claude Opus 4.6
In 2023, open-source AI was two years behind frontier models. In 2024, one year. In 2025, six months. And on March 27, 2026, Z.ai dropped GLM-5.1 with a coding score of 45.3 on their internal eval - while Claude Opus 4.6 sits at 47.9. That gap is 2.6 points. I am not cherry-picking optimistic numbers. That's the headline.
GLM-5.1 is now live for all GLM Coding Plan users, trained entirely on Huawei Ascend 910B chips (zero Nvidia involvement), and Z.ai is already teasing an open-source release. If those benchmark numbers survive independent scrutiny, this is the most serious challenge any open model has posed to Anthropic's flagship coding model.
But here is what the benchmark tables won't tell you: GLM-5.1 is the slowest model in this comparison at 44.3 tokens per second, it shines hardest on long agentic tasks rather than quick code generation, and the open-source release is still just a tease. I want to walk you through exactly what this model does, where it leads, where it lags, and whether you should switch your coding workflow to it today.
What Is GLM-5.1?
GLM-5.1 is an incremental post-training upgrade to Z.ai's GLM-5 foundation model, released on March 27, 2026, specifically targeting coding performance. It does not change the base architecture - it is the same 744 billion total parameter Mixture-of-Experts model with 40 billion active parameters per inference token, a 200K context window, and DeepSeek Sparse Attention under the hood.
Z.ai (the international brand for Zhipu AI, China's third-largest AI lab by IDC's count) has been moving fast. The release cadence in 2026 alone reads like this: GLM-5 on February 11, GLM-5-Turbo on March 15, and GLM-5.1 on March 27. That's three significant releases in six weeks. The Chinese AI market is brutally competitive, and Zhipu is not letting up.
What makes .1 different from .0? Refined post-training. The base architecture is unchanged, but the reinforcement learning pipeline was retargeted specifically at coding task distributions. The result: GLM-5.1 scores 45.3 on Z.ai's coding eval versus the GLM-5 baseline of 35.4. That is a 28% improvement. In one point release. For context, Claude Opus 4.6 scores 47.9 on the same benchmark.
I think the 'point release delivers 28% uplift' story is actually more interesting than the 'we're close to Claude' story. It tells you that post-training quality, not parameter count, is the lever Z.ai is pulling right now.
How GLM-5.1 Performs on Coding Benchmarks
GLM-5.1 scores 45.3 on Z.ai's proprietary coding evaluation benchmark, placing it 94.6% of the way to Claude Opus 4.6's score of 47.9 on the same harness. The eval uses Claude Code as the harness, which introduces a notable caveat: these benchmarks are self-reported by Z.ai and have not yet been independently verified as of March 28, 2026.
That caveat matters. A lot. I have seen several Chinese labs report impressive self-benchmarked numbers that look less exciting once independent testing happens. That said, GLM-5 (the base model) already demonstrated 77.8% on SWE-bench Verified when measured externally - the highest score among all open-source models on that benchmark. So Z.ai has a track record of backing up their internal numbers.
Here is a quick look at where GLM-5 (the base for GLM-5.1) sits on established external benchmarks:
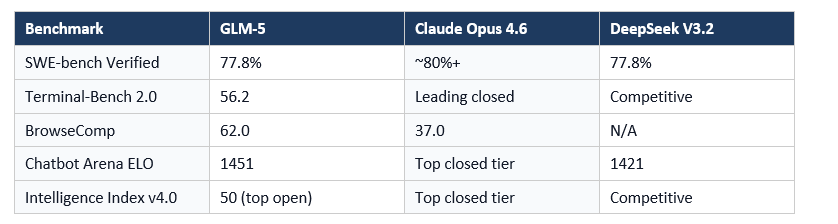
(Note: GLM-5.1 coding benchmark score is internal/self-reported. External benchmark data above reflects GLM-5 base model per Artificial Analysis and arXiv technical report.)
The BrowseComp number is the one I keep coming back to. GLM-5 scores 62.0 versus Claude Opus 4.5's 37.0 on that benchmark. That's not a gap you can explain away. Something real is happening with Z.ai's web-browsing and research capabilities.
Agent Leaderboard: Where GLM-5.1 Shines
GLM-5.1 achieves an 85.0 average score across agent leaderboards, making it among the top open-source models for long-horizon agentic tasks. Its standout capability is synthesizing long research reports - the example Z.ai highlights is autonomous synthesis of dexterous hands research documentation, a task that requires sustained multi-step reasoning over hours of compute time.
GLM-5 was already ranked #1 among open-source models on Vending Bench 2 - a benchmark that simulates running a vending machine business over a one-year horizon. The model finished with a final account balance of $4,432, approaching Claude Opus 4.5's performance. GLM-5.1 builds on this agentic foundation.
The architecture is genuinely built for this. The 'slime' asynchronous RL infrastructure means GLM-5.1 can handle long-trajectory tasks without the synchronization bottlenecks that hamper other large models. It was also trained on long-horizon agentic data specifically during mid-training, not just fine-tuned at the end.
My honest take: if your use case is short, quick code completions in a Cursor-style autocomplete setup, GLM-5.1 may not be your best option. Where it gets interesting is multi-file refactoring, backend architecture tasks, or anything that requires a model to hold context and plan across dozens of steps. That's where the 85.0 agent score actually means something in practice.
Speed, Pricing, and the Practical Tradeoffs
GLM-5.1 is the slowest model in its competitive tier at 44.3 tokens per second - which is a real limitation if you're doing real-time coding in an IDE. For context, GLM-5 Reasoning mode on Artificial Analysis generates at 69.4 tokens per second. The 5.1 variant with its additional post-training is slower.
Pricing for the GLM Coding Plan starts at $27 per quarter (roughly $9/month), with a promotional entry point of $3/month for 120 prompts. The standalone GLM-5 API costs $1.00 per million input tokens and $3.20 per million output tokens - which is approximately 6x cheaper on input and 10x cheaper on output than Claude Opus 4.6's pricing of $5/$25 per million tokens.
Here is the tradeoff summary you actually need:
- Speed: 44.3 tokens/sec (slowest in class). Not ideal for autocomplete.
- Price: $27/quarter for plan access. Dramatically cheaper than Opus 4.6 API pricing.
- Context: 200K tokens, 131,072 max output. Excellent for long tasks.
- Open-source: Teased but not yet released as of March 28, 2026.
- Compatibility: Works with Claude Code, Cursor, Cline, Kilo Code, OpenCode, and more.
The speed issue is the one I'd push Z.ai on. 44.3 tokens per second on a model positioned as a coding assistant is a friction point. Developers will notice it. That said, for batch tasks or agentic workflows where you're not watching tokens stream in real time, it matters far less.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
GLM-5.1 vs Claude Opus 4.6: Side-by-Side Comparison
Coding eval scores are only one slice of this comparison. Let me put the practical differences side by side.
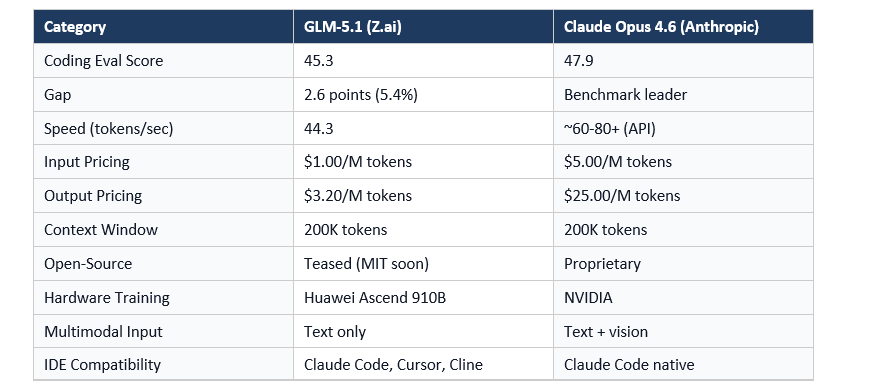
The pricing gap is extraordinary. For teams running high-volume coding workflows through the API, $3.20 versus $25 per million output tokens is not a rounding error. It's the difference between a $3,000 monthly AI budget and a $30,000 one.
The text-only limitation is real though. Claude Opus 4.6 can accept image inputs, which matters for UI tasks, diagram analysis, and debugging visual output. GLM-5.1 cannot. That's a genuine capability gap, not just a benchmark number.
The Huawei Hardware Story Behind GLM-5.1
GLM-5.1 was trained entirely on 100,000 Huawei Ascend 910B chips using the MindSpore framework, with zero Nvidia GPU involvement. Zhipu AI has been on the US Entity List since January 2025, which means they cannot access US-manufactured semiconductor hardware for AI training.
This context changes how you read the benchmark numbers. Z.ai built a model within 2.6 eval points of Anthropic's best coding model, using hardware that the US government classified as less capable than Nvidia's offerings. Whether you think the Entity List is good policy or not, the technical achievement is real.
Zhipu AI also completed a Hong Kong IPO on January 8, 2026, raising approximately HKD 4.35 billion (roughly USD $558 million). That capital has directly accelerated the GLM-5 family's development pace. The one-release-per-month cadence in 2026 is not a coincidence.
I think the deeper story here is that the assumption 'you need Nvidia to build frontier AI' is increasingly wrong. GLM-5 scored 50 on the Artificial Analysis Intelligence Index - the first open-weight model to hit that threshold. It was done on Huawei chips. That's a geopolitically significant data point.
Should You Use GLM-5.1 Right Now?
GLM-5.1 is worth using if you run long-horizon coding tasks, want 10x cheaper API costs than Claude Opus 4.6, and can tolerate 44.3 tokens per second. It's not the right choice if you need fast autocomplete, multimodal input, or fully verified independent benchmark scores.
Here's how I'd break down who should actually switch:
- Use GLM-5.1 if: You're running backend refactoring, multi-file architecture tasks, or long research synthesis. The 85.0 agent average and 200K context window are genuinely useful here.
- Use GLM-5.1 if: You're cost-sensitive. At $27/quarter for the coding plan, this is dramatically cheaper than comparable Claude API access.
- Wait on GLM-5.1 if: You need independent benchmark verification before committing workflow changes. Self-reported scores are a starting point, not a guarantee.
- Wait on GLM-5.1 if: Speed matters for your use case. 44.3 tokens per second will feel slow in an interactive coding context.
The open-source release is the thing I'm most interested in. Z.ai has a consistent track record of open-sourcing GLM models (GLM-4.7 is already on Hugging Face under MIT). When GLM-5.1 weights drop, the conversation about running frontier-adjacent coding AI locally changes significantly. I'll be watching for that announcement.
Want to build AI agents and coding tools like these from scratch? Join Build Fast with AI's Gen AI Launchpad, an 8-week structured program to go from 0 to 1 in Generative AI. Register here:
Frequently Asked Questions
What is GLM-5.1?
GLM-5.1 is Z.ai's (Zhipu AI's) latest coding-focused AI model, released on March 27, 2026. It is a post-training upgrade to GLM-5, built on the same 744 billion parameter Mixture-of-Experts architecture with 40 billion active parameters per token and a 200K context window. The upgrade targets coding benchmark performance specifically.
How does GLM-5.1 compare to Claude Opus 4.6 in coding benchmarks?
GLM-5.1 scores 45.3 on Z.ai's internal coding evaluation benchmark, compared to Claude Opus 4.6's score of 47.9 on the same harness. That puts GLM-5.1 at 94.6% of Claude Opus 4.6's performance. These benchmarks are self-reported by Z.ai and had not been independently verified as of March 28, 2026.
What is the GLM Coding Plan pricing?
The GLM Coding Plan starts at a promotional price of $3/month for 120 prompts, with the full plan at $27 per quarter. The standalone GLM-5 API is priced at $1.00 per million input tokens and $3.20 per million output tokens, which is roughly 6x cheaper on input and 10x cheaper on output versus Claude Opus 4.6.
How fast is GLM-5.1 in tokens per second?
GLM-5.1 generates at approximately 44.3 tokens per second, making it the slowest model in its competitive tier. For context, GLM-5 in reasoning mode generates at 69.4 tokens per second. The speed limitation is worth considering for interactive coding and autocomplete use cases.
Is GLM-5.1 open source?
As of March 28, 2026, GLM-5.1 is not yet open-source, but Z.ai has teased an open-source release. Z.ai has a consistent track record of open-sourcing its models: GLM-4.7 is available on Hugging Face under the MIT License. The GLM-5 family is expected to follow the same precedent.
What hardware was GLM-5.1 trained on?
GLM-5.1 was trained on approximately 100,000 Huawei Ascend 910B chips using the MindSpore framework, with no Nvidia GPU involvement. Zhipu AI has been on the US Entity List since January 2025, making this an independent Chinese AI compute stack.
What agent benchmarks does GLM-5.1 score on?
GLM-5.1 achieves an 85.0 average score across agent leaderboards. The GLM-5 base model scored #1 among open-source models on Vending Bench 2 (a one-year business simulation) with a final account balance of $4,432, and recorded 62.0 on BrowseComp versus Claude Opus 4.5's 37.0.
Which coding tools support GLM-5.1?
GLM-5.1 is compatible with Claude Code, Cursor, Kilo Code, Cline, OpenCode, Droid, and OpenClaw via the GLM Coding Plan. It can be accessed through the Z.ai API using an OpenAI-compatible endpoint, making integration straightforward for most developer tooling.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
Kimi 2.5 Review: Is It Better Than Claude for Coding? (2026)
GLM OCR vs GLM-5-Turbo: Which AI Model Should You Use? (2026)
Claude Code Auto Mode: Unlock Safer, Faster AI Coding (2026 Guide)
LLM Scaling Laws Explained: Will Bigger AI Models Always Win? (2026)
7 AI Tools That Changed Developer Workflow (March 2026)
References
- GLM-5 Technical Report (arXiv:2602.15763) - Zhipu AI / Z.ai
- GLM-5 Official Hugging Face Model Card - Z.ai
- GLM-5.1 Benchmark Analysis - Digital Applied
- GLM Coding Plan Pricing - Z.ai
- GLM-5 Overview - Z.AI Developer Documentation
- z.ai's GLM-5 Achieves Record Low Hallucination Rate - VentureBeat
- GLM-5 Intelligence Index Analysis - Artificial Analysis
- GLM-5 GitHub Repository - Z.ai Org

