




Kimi 2.5 Review: Is Moonshot AI's Open-Source Giant Better Than Claude for Coding in 2026?
I didn't expect much. Honestly. Another Chinese AI lab dropping a benchmark-topping model that sounds incredible on paper and disappoints in practice. That was my attitude when Moonshot AI quietly shipped Kimi K2.5 on January 27, 2026. Then I started running it.
The headline numbers alone are hard to ignore: 76.8% on SWE-Bench Verified, 96.1% on AIME 2025, and a Humanity's Last Exam (HLE) score of 50.2% that actually beats Claude Opus 4.5's 32.0% and GPT-5.2 High's 41.7%. All of this at $0.60 per million input tokens. Claude Opus charges $5 per million. That's an 8x price gap.
But the thing that made me stop scrolling was Agent Swarm: the ability to coordinate up to 100 specialized AI sub-agents working in parallel on a single task. No other frontier model does t
his. Not GPT. Not Claude. Not Gemini.
So I spent three weeks running Kimi K2.5 through real workflows. Coding, research, visual tasks, document analysis. Here is everything I found, including where Kimi genuinely shines and where Claude still wins.
1. What Is Kimi 2.5?
Kimi K2.5 is Moonshot AI's most advanced language model, released on January 27, 2026. It is a multimodal, open-source AI model with 1.04 trillion total parameters and 32 billion active parameters, built on a Mixture-of-Experts (MoE) architecture. The model processes both text and visual inputs, supports a 256,000-token context window, and runs in four distinct operational modes.
Moonshot AI is a Chinese AI startup founded in 2023. Their previous model, Kimi K2, earned a strong reputation as a coding-focused model. K2.5 takes that foundation and adds native vision capabilities, Agent Swarm technology, and significant improvements in reasoning and document understanding.
My hot take: Kimi K2.5 is the most significant open-source model release since Meta's Llama 3. Not because it beats everything. It doesn't. But because it genuinely closes the gap with closed-source giants at a fraction of the cost, and introduces a capability (Agent Swarm) that nobody else has shipped yet.
The model is available for free on kimi.com with usage limits, and commercially via API through Moonshot AI's platform at platform.moonshot.ai.
2. Kimi K2.5 Key Features and Architecture
The architecture choices behind Kimi K2.5 explain why it performs the way it does. Here is what matters.
Mixture-of-Experts (MoE) Design
Kimi K2.5 uses a 1.04 trillion parameter MoE model with only 32 billion parameters active per token inference. This means it achieves the intelligence of a trillion-parameter model while running at the speed and cost of a much smaller one. The model has 384 specialized experts, with a routing mechanism that selects 8 experts per token. It also uses Multi-head Latent Attention (MLA) and native INT4 quantization for a 2x generation speedup on standard hardware.
Native Multimodal Architecture
Unlike earlier models that bolt a vision adapter onto a text backbone, Kimi K2.5 was trained from scratch on approximately 15 trillion mixed visual and text tokens. This native approach is why visual coding tasks work so well. You can drop a Figma design screenshot into the model and get working React or Vue code out. Feed it a Loom video of a bug and it watches, reasons, and suggests a fix.
Four Operational Modes

Each mode uses the same underlying model weights. The switching happens through decoding strategy and tool permissions.
256K Context Window
Kimi K2.5 supports 256,000 tokens natively, which is 28% more than Claude's default 200K context.
In practical coding terms, 256K tokens means you can load approximately 200,000 lines of code into a single conversation without chunking. You can maintain full project context across a long refactoring session. For developers working on large monorepos, this is genuinely useful.
3. Kimi K2.5 Benchmark Performance
Let's get into the actual numbers. I'm going to focus on the benchmarks that matter for real-world use, not academic demonstrations.
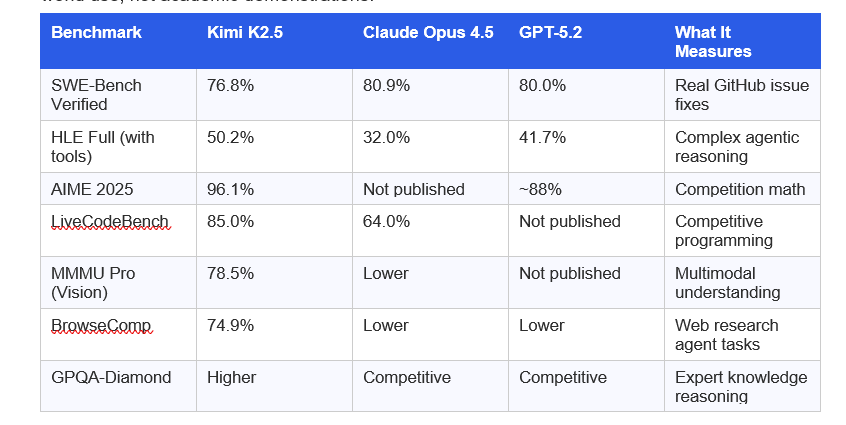
What the numbers actually mean: Kimi K2.5 trails Claude by about 4 points on SWE-Bench, which is the benchmark most developers care about for real code quality. That 4-point gap translates to slightly more debugging cycles and fewer first-attempt solutions on hard engineering problems. It's real. But on competitive programming (LiveCodeBench: 85.0% vs 64.0%) and agentic research tasks, Kimi leads by substantial margins.
My honest read: the gap between Kimi and Claude has closed to the point where the right choice depends almost entirely on your use case and budget, not raw capability.
4. Is Kimi K2.5 Better Than Claude for Coding?
This is the question everyone is asking. Short answer: it depends on the type of coding.
Where Kimi K2.5 Wins
- Frontend and UI development from screenshots, Figma exports, or screen recordings
- Competitive programming and algorithm challenges (85.0% LiveCodeBench vs Claude's 64.0%)
- Large codebase analysis that needs the full 256K context window
- High-volume batch code generation where the 8x cost difference matters
- Visual debugging: upload a screen recording of a bug and get a fix
Where Claude Still Wins
- Production-grade code quality on complex engineering problems (80.9% SWE-Bench vs 76.8%)
- Terminal-intensive agentic workflows requiring consistent tool use
- Code review with nuanced judgment about architecture and maintainability
- Enterprise environments where proven reliability matters more than cost savings
- Projects needing the largest possible context window (Claude Opus 4.6 supports 1M tokens)
I ran the same complex refactoring task through both models over several weeks. Claude's output required fewer iterations. Kimi's output was faster to generate and cost roughly a tenth as much. For a startup burning through API tokens on code generation, that math is hard to ignore.
Contrarian take: The narrative that Claude is simply 'better' for coding is becoming less accurate. For visual-first workflows and competitive algorithms, Kimi K2.5 is actually the stronger choice right now. The benchmark gap on SWE-Bench is 4 points. That's narrow enough to matter only at the edges.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Kimi K2.5 Agent Swarm: How It Works
This is the feature that has no equivalent anywhere else in the market. Agent Swarm is currently in research preview and represents a fundamentally different approach to complex task execution.
Standard AI models process tasks sequentially. One step, then the next, then the next. Agent Swarm deploys an orchestrator that analyzes the task, identifies parallelizable subtasks, spins up specialized sub-agents (think: AI Researcher, Physics Expert, Fact Checker, Code Reviewer), and runs them simultaneously.
The result: 4.5x faster task completion on wide-search tasks and an 80% reduction in end-to-end runtime compared to sequential single-agent approaches, according to Moonshot AI's January 2026 testing data.
Agent Swarm vs Standard Agent: Real Numbers
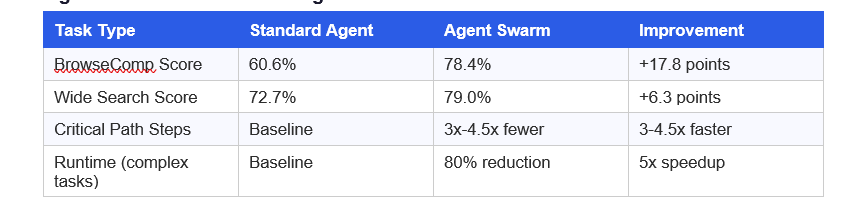
Moonshot AI trained Agent Swarm using a new technique called Parallel Agent Reinforcement Learning (PARL). Early training rewards parallel execution. Later training shifts to task quality. The final reward function balances completion quality (80%) with critical path efficiency (20%). This prevents the model from artificially splitting tasks without any actual performance benefit.
For a 50-competitor market research task that would take a single agent 3+ hours, Agent Swarm completes it in 40-60 minutes. At 9x lower cost than Claude Opus, that's a genuinely different economic proposition.
6. Kimi K2.5 Pricing: Is It Free?
Kimi K2.5 has three access tiers, and the pricing structure is one of its strongest selling points.

The cost comparison is stark.
- Kimi K2.5 API: $0.60 per million input tokens
- Claude Opus 4.5: $5 per million input tokens
- GPT-5.2: approximately $2.50-10 per million input tokens
For a fintech startup running one million API requests annually with typical 5K output token responses, the annual cost breaks down to roughly $13,800 for Kimi K2.5 versus $150,000 for Claude Opus 4.5. That's a $136,000 difference on a single workload.
The open-source license (modified MIT) allows commercial use with attribution required only if you exceed 100 million monthly active users or $20 million monthly revenue. For the vast majority of companies, that means effectively free commercial use of the model weights.
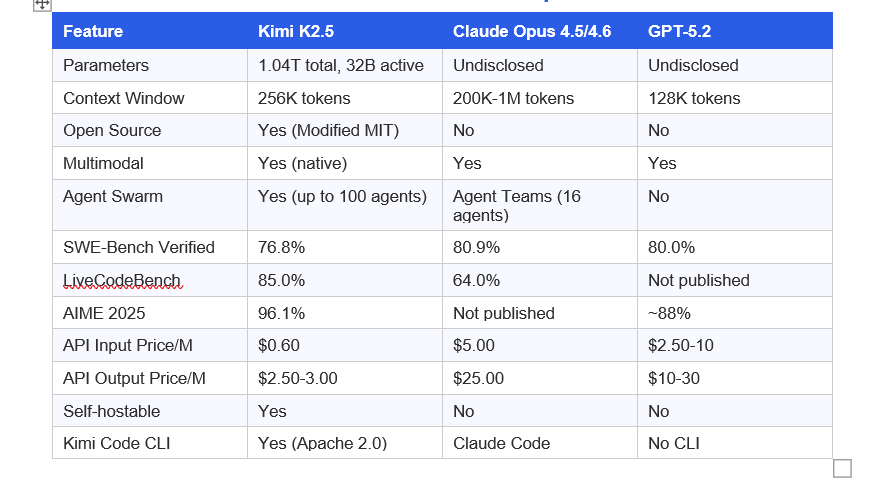
7. Kimi K2.5 vs Claude vs GPT-5.2: Full Comparison
8. Kimi K2.5 API and Kimi Code CLI
API Access
The Kimi API is fully compatible with OpenAI's API format, meaning existing codebases can switch with minimal changes. The model string is 'kimi-k2.5' and the API endpoint runs through platform.moonshot.ai. Moonshot also provides an Anthropic-compatible API.
Two key parameters for API usage: set temperature to 1.0 for Thinking mode and 0.6 for Instant mode. Set top_p to 0.95 for both. To disable thinking mode and run in Instant mode, pass {'chat_template_kwargs': {'thinking': false}} in extra_body.
Kimi Code CLI
Moonshot AI released Kimi Code CLI as a direct Claude Code alternative. It's open-source under Apache 2.0, has 6,400+ GitHub stars as of February 2026, and supports MCP tools, VS Code, Cursor, and Zed integration. Install via pip: 'pip install kimi-cli'. The CLI acts as an autonomous coding agent that can handle debugging, refactoring, and multi-step development workflows in your terminal.
Where Claude Code has an edge: web search reliability is noticeably better, and the artifact rendering inside the chat interface means you can test interactive components without leaving the conversation. Where Kimi Code CLI holds up: context persistence across long agent sessions, strong execution discipline on multi-step tool chains, and meaningfully lower rate limit friction at the $60/month tier versus Claude's $200/month.
9. Who Should Use Kimi K2.5?
Use Kimi K2.5 if:
- You're building frontend applications and want to generate code directly from design files
- You run high-volume batch coding tasks and the 8x cost difference actually matters to your budget
- You need Agent Swarm for complex parallel research or analysis tasks
- You want to self-host a frontier-class model on your own infrastructure
- You're working with competitive programming problems where LiveCodeBench performance matters
Stick with Claude if:
- Code quality on complex engineering problems is the top priority and you need that 80.9% SWE-Bench reliability
- You need a context window larger than 256K (Claude Opus supports up to 1M tokens)
- You're doing terminal-heavy agentic workflows where Claude's tool use consistency still leads
- Enterprise procurement processes require proven production case studies and reliability SLAs
My personal recommendation for most teams: run Kimi K2.5 for frontend work, batch operations, and research tasks. Route to Claude for complex backend architecture, code review, and production-critical code. Model routing is the actual winning strategy in 2026.
Frequently Asked Questions
What can Kimi 2.5 do?
Kimi K2.5 handles text generation, code writing, visual understanding, document analysis, and agentic tasks. Its standout capabilities are visual-to-code generation (turning UI screenshots into working React or Vue code), Agent Swarm coordination (up to 100 parallel sub-agents), and competitive programming. It supports 256K token contexts and runs in Instant, Thinking, Agent, and Agent Swarm modes.
Is Kimi better than Claude for coding?
It depends on the coding type. Kimi K2.5 leads Claude on LiveCodeBench (85.0% vs 64.0%) and visual coding tasks. Claude Opus 4.5 leads on SWE-Bench Verified (80.9% vs 76.8%), terminal-intensive agentic workflows, and production code quality for complex engineering problems. For daily development and frontend work, Kimi K2.5 offers roughly 80-90% of Claude's capability at approximately 8x lower API cost.
Is Kimi 2.5 free to use?
Yes. Kimi K2.5 is free on kimi.com with usage limits across all four operational modes. The model weights are also freely available on Hugging Face for self-hosting under a modified MIT license. Commercial API access costs $0.60 per million input tokens through Moonshot AI's platform.
What is Kimi K2.5's context window?
Kimi K2.5 supports 256,000 tokens natively, implemented using the YaRN extension. This is 28% larger than Claude's default 200K context and double GPT-5.2's 128K. In practical terms, 256K tokens can hold approximately 200,000 lines of code, making it suitable for analyzing large monorepos in a single session.
Is Kimi AI good for coding?
Yes, particularly for frontend development, visual programming, and high-volume tasks. Kimi K2.5 scores 85.0% on LiveCodeBench and 76.8% on SWE-Bench Verified as of January 2026. Its native multimodal architecture allows direct code generation from UI design screenshots, and the Kimi Code CLI provides a full terminal-based coding agent experience as an alternative to Claude Code.
What is the Kimi K2.5 API price?
Kimi K2.5 API pricing is $0.60 per million input tokens and $2.50-3.00 per million output tokens through platform.moonshot.ai. This is approximately 8x cheaper than Claude Opus on input tokens ($5/M) and 3-4x cheaper than most GPT-5.2 tiers. The API is fully compatible with OpenAI's format, allowing drop-in migration from existing integrations.
Is Kimi K2.5 open source?
Yes. Kimi K2.5 is released under a modified MIT license. Model weights are freely downloadable from Hugging Face and support deployment via vLLM, SGLang, or KTransformers. Commercial use requires attribution only above 100 million monthly active users or $20 million monthly revenue.
What is Kimi K2.5's Agent Swarm?
Agent Swarm is Kimi K2.5's most distinctive feature. It coordinates up to 100 specialized sub-agents working simultaneously on a complex task. An orchestrator decomposes the task, assigns subtasks to specialists, and manages parallel execution. In Moonshot AI's testing from January 2026, Agent Swarm delivered 4.5x faster task completion and 80% runtime reduction compared to sequential single-agent execution.
Recommended Blogs
If you found this useful, these posts from Build Fast with AI cover related topics worth reading:
References
- Kimi K2.5 Official Tech Blog - Moonshot AI:
- Kimi K2.5 on Hugging Face - moonshotai/Kimi-K2.5:
- Kimi API Platform Documentation:
- Kimi K2.5 Developer Guide - NxCode (February 2026):
- Kimi K2.5 Complete Guide - Codecademy:
- Moonshot AI Releases Kimi K2.5 - InfoQ (February 17, 2026):
- Kimi K2.5 vs Claude Opus 4.5 Comparison (January 28, 2026):
- NVIDIA NIM - Kimi K2.5 Model Card:

