




What Are LLM Scaling Laws and Will Bigger Models Always Win?
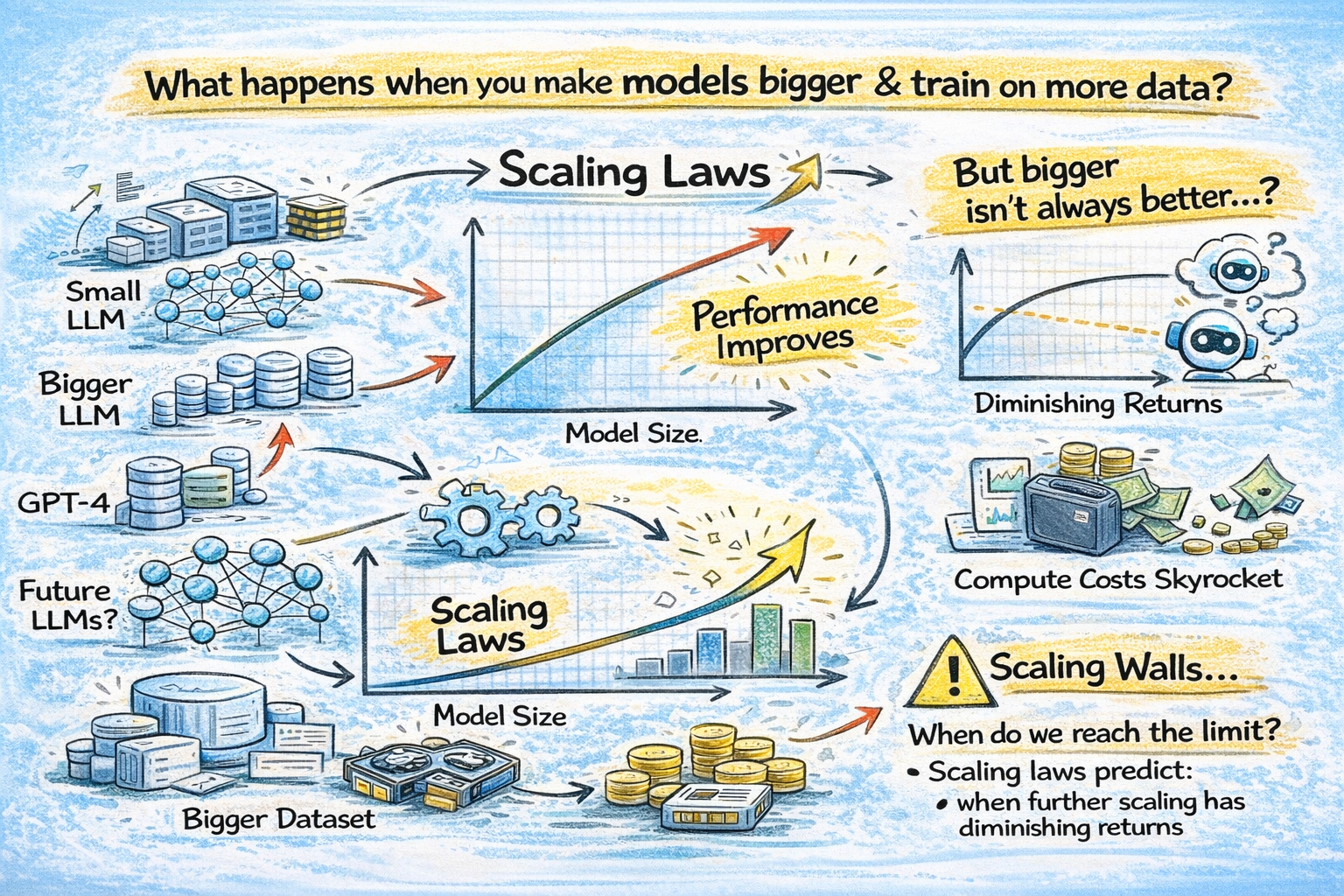
The entire trajectory of modern AI has been guided by one deceptively simple question: what happens when you make models bigger, train them on more data, and throw more compute at them?
The answer, discovered through years of empirical research, is that performance improves predictably. Not randomly. Not chaotically. It follows clean mathematical curves called scaling laws. These laws are the reason OpenAI built GPT-4, the reason Google trained Gemini Ultra, and the reason companies are collectively spending nearly $700 billion on AI infrastructure in 2026. Every major decision about model size, training budget, and data collection at frontier AI labs is informed by these equations.
But here's the thing most people don't talk about: scaling laws also tell you exactly when bigger stops being better. And we may be approaching that point faster than the hype suggests. Let's break down what scaling laws actually say, how they evolved, whether they're hitting a wall, and why training LLMs from scratch remains one of the most expensive things humans have ever done.
What Are Scaling Laws in AI?
Scaling laws are empirical relationships that describe how a neural network's performance changes as you increase three key variables: model size (number of parameters), training data (number of tokens), and compute (total floating-point operations used during training).
The core discovery is that the model's loss (a measure of how wrong its predictions are) decreases as a power law when any of these variables increases. A power law means the relationship follows the form: Loss = constant / variable^exponent. On a log-log plot, this shows up as a straight line, which makes the relationship both predictable and useful for planning.
There are two landmark papers that defined this field, and they reached notably different conclusions about how to allocate resources. Understanding both is essential because the tension between them has shaped every major AI model released in the last five years.
The Kaplan Scaling Laws (OpenAI, 2020)
In January 2020, a team at OpenAI led by Jared Kaplan (with co-authors including Dario Amodei, who later founded Anthropic, and Sam McCandlish) published "Scaling Laws for Neural Language Models." This paper ran systematic experiments varying model size, data, and compute, and found three power-law relationships.
Performance improves predictably with model size, dataset size, and compute, with trends spanning more than seven orders of magnitude. The paper also found that architectural details like network width or depth had minimal effects within a wide range. What mattered most was the total parameter count and the amount of training data.
The critical conclusion from Kaplan's work was that model size matters more than data. Given a fixed compute budget, the optimal strategy was to train a very large model on a relatively modest amount of data and stop early. The allocation split roughly 73% toward parameters and 27% toward data.
This finding directly influenced the design of GPT-3. OpenAI trained a 175 billion parameter model on "only" 300 billion tokens, a ratio of roughly 1.7 tokens per parameter. At the time, this was considered the right approach: build the biggest model you can afford and don't worry too much about data volume.
GPT-3 was a sensation. It could write essays, code, and poetry. And the lesson the industry took from it was simple: bigger is better. The parameter race was on.
The Chinchilla Scaling Laws (DeepMind, 2022)
Two years later, a team at DeepMind led by Jordan Hoffmann flipped the script entirely.
Their paper, "Training Compute-Optimal Large Language Models," showed that Kaplan's conclusions were biased by experimental choices. Specifically, Kaplan's team used smaller models (up to 1B parameters), didn't count embedding parameters, and used learning rate schedules that were suboptimal for longer training runs. When DeepMind ran more carefully controlled experiments with models up to 16B parameters and properly tuned cosine learning rate schedules, they found something different.
The Chinchilla conclusion: model size and data are equally important. For a given compute budget, you should scale both parameters and training tokens in roughly equal proportion. The optimal ratio is approximately 20 tokens per parameter.
To prove this, DeepMind trained a model called Chinchilla with 70 billion parameters on 1.4 trillion tokens (exactly 20:1). Despite being 4x smaller than Gopher (280B parameters), Chinchilla outperformed it on nearly every benchmark. It also beat GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG (530B).
The implication was devastating for the parameter-maximization approach: most existing LLMs were massively undertrained. They had too many parameters relative to their training data. GPT-3, by Chinchilla's math, should have either been trained on 3.5 trillion tokens (at 175B parameters) or been a 15B parameter model (at 300B tokens). It was neither.
This single insight reshaped the entire industry. Meta trained Llama 2 70B on 2 trillion tokens. Llama 3 8B was trained on a staggering 15 trillion tokens, roughly 1,875 tokens per parameter, far beyond even Chinchilla's recommendations. The era of "train smaller models on way more data" had begun.
Beyond Chinchilla: The Inference-Aware Scaling Laws
The Chinchilla scaling law optimized for one thing: minimizing training compute. But in the real world, training is a one-time cost. Inference, serving the model to millions of users every day, is the recurring expense that dominates total cost of ownership.
Researchers at MosaicML (now Databricks) identified what they called the "Chinchilla Trap." If you follow Chinchilla's recommendations exactly, you end up with a model that's optimally trained but potentially too large to serve cheaply at scale. A 70B model costs much more to run per request than a 7B model, even if the 70B model is slightly better.
Their analysis showed that if you expect high inference demand (say, billions of API requests over a model's lifetime), you should train a smaller model on significantly more data than Chinchilla recommends. The inference-optimal ratio could be 100-200 tokens per parameter, not 20.
This is exactly what we've seen in practice. Llama 3 8B was trained on 15 trillion tokens (1,875:1 ratio). Microsoft's Phi series of small language models was trained on "textbook-quality" synthetic data specifically to squeeze maximum capability into tiny models. DeepSeek pushed efficiency even further, training their V3 model (671B total parameters, but a Mixture of Experts with only 37B active per token) on 14.8 trillion tokens for a reported compute cost of just $5.6 million.
The lesson: scaling laws aren't just about making the best model. They're about making the best model that you can afford to serve.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Will Scaling Laws Always Work?
This is the billion-dollar question, and the honest answer in 2026 is: probably not in their current form.
Scaling laws predict that loss decreases as a power law with more compute. But there's a catch that's easy to miss. On a log-log plot, power-law improvements look like a straight line, which feels exciting. On a linear plot, however, the same curve looks like exponential decay, with massive initial gains that flatten out quickly. Each doubling of compute gives you less improvement than the last one. This is diminishing returns baked into the math itself.
Several concrete signs suggest that brute-force scaling is reaching practical limits.
The data wall. Chinchilla-optimal training for a 1 trillion parameter model would require roughly 20 trillion tokens of training data. High-quality text data on the internet is estimated at somewhere between 10-50 trillion tokens depending on how you count. We are approaching a point where the largest models may need more unique training data than exists. Synthetic data generation is one solution, but research shows that over-reliance on synthetic data can introduce diversity issues and "model collapse" where models trained on their own outputs gradually degrade.
GPT-5's reception. The launch of GPT-5 was met with what many described as a muted response compared to GPT-4's debut. While technically more capable, the gap between GPT-4 and GPT-5 felt smaller to users than the gap between GPT-3.5 and GPT-4. This aligns with what scaling laws predict: the closer you get to the performance ceiling, the harder each incremental improvement becomes.
Different capabilities plateau at different points. Research on model size versus performance shows that knowledge tasks (like MMLU) show diminishing returns beyond 30B parameters. Reasoning tasks (like GSM8K) plateau around 70B+ parameters. Code generation diminishes after 34B+. Language understanding flattens at 13B+. Only creative tasks continue benefiting significantly from larger scales.
Industry leaders are signaling a shift. Ilya Sutskever stated at NeurIPS 2024 that "pretraining as we know it will end" and that "the 2010s were the age of scaling, now we're back in the age of wonder and discovery." Sara Hooker's 2026 essay "On the Slow Death of Scaling" documented how smaller models are rapidly closing the gap with larger ones through better training techniques. Falcon 180B (2023) was outperformed by Llama 3 8B (2024) just one year later.
The sub-scaling phenomenon. Recent research studying over 400 models found that as datasets grow very large, performance improvements decelerate faster than standard scaling laws predict. The culprit is data density: as you consume more data, the marginal uniqueness of each new sample decreases, leading to redundancy and diminishing returns that compound.
None of this means scaling is dead. It means that pure parameter scaling, training bigger dense models on more data with more compute, is no longer the only path forward. The frontier is moving toward smarter scaling: test-time compute (letting models "think" longer during inference, as in OpenAI's o1 and o3), Mixture of Experts architectures (activating only a fraction of parameters per token), better data curation, and distillation (smaller models learning from larger ones).
Why Training LLMs From Scratch Is So Expensive
Even with all the scaling law research telling you exactly how much data and compute you need, actually training a frontier LLM from scratch remains one of the most expensive engineering endeavors in human history.
Let's look at the numbers. The original Transformer paper (2017) cost roughly $900 to train. GPT-3 (2020) cost between $500,000 and $4.6 million in compute. GPT-4 (2023) reportedly cost over $100 million, with Stanford's AI Index calculating $78 million in compute alone. Google's Gemini Ultra was estimated at $191 million. Meta's Llama 3.1 405B came in around $170 million.
On average, companies spent 28x more training their most recent flagship model compared to its predecessor. Training costs for frontier models have been growing 2-3x per year for the past eight years.
Anthropic's CEO Dario Amodei has publicly stated that current frontier model training costs span $100 million to $1 billion, with projections reaching $5-10 billion by 2025-2026 and potentially $10-100 billion within three years.
These costs break down across several categories.
Compute infrastructure is the largest line item. Training GPT-4 consumed an estimated 21 billion petaFLOPs of computation. At current prices, an NVIDIA H100 costs roughly $25,000 per unit, with additional infrastructure costs of $5,000-$50,000 per GPU for power, cooling, and networking. A single frontier training run might occupy thousands of GPUs for months. Meta's Llama 3 training cluster used 16,000 H100 GPUs.
Data acquisition and management has become surprisingly costly. The global data annotation market is projected to grow from $2.32 billion in 2025 to $9.78 billion by 2030. Human-in-the-loop annotation for RLHF (reinforcement learning from human feedback) costs approximately $100 per high-quality annotation, and expert annotation rates can exceed $40 per hour.
Energy consumption is substantial and growing. A single modern AI data center campus can consume 500 megawatts to 1 gigawatt of power. OpenAI's Texas data center alone consumes roughly 300 megawatts, enough to power a mid-sized city, and is set to hit 1 gigawatt by mid-2026.
Failed experiments are rarely discussed but add significantly to total costs. The $5.6 million figure DeepSeek reported for training their V3 model excluded infrastructure, experimentation, and failed training runs. Real-world training involves multiple attempts, hyperparameter sweeps, and debugging sessions that can double or triple the final compute bill.
This is precisely why the industry has shifted heavily toward fine-tuning, distillation, and open-source models. Fine-tuning a pre-trained model like Llama 3 on domain-specific data can cost as little as $500-$5,000 with LoRA adapters, a fraction of the millions required for training from scratch. For most organizations, training a frontier model is not feasible, not necessary, and not the right approach. The smart play is to leverage existing open-source models and customize them for your specific use case.
Want to master LLM training, fine-tuning, and deployment?
Join Build Fast with AI's Gen AI Launchpad, an 8-week structured bootcamp to go from 0 to 1 in Generative AI.
Register here: buildfastwithai.com/genai-course
Frequently Asked Questions
What are scaling laws in large language models?
Scaling laws are empirical power-law relationships that describe how LLM performance improves as you increase model size (parameters), training data (tokens), and compute (FLOPs). The two most important scaling laws are the Kaplan laws (OpenAI, 2020) which favored larger models, and the Chinchilla laws (DeepMind, 2022) which showed that model size and data should be scaled equally, with an optimal ratio of roughly 20 tokens per parameter.
What is the Chinchilla scaling law?
The Chinchilla scaling law, published by DeepMind in 2022, states that for a given compute budget, the optimal training strategy allocates resources equally between model parameters and training data. The recommended ratio is approximately 20 tokens per parameter. DeepMind proved this by training Chinchilla (70B parameters, 1.4T tokens), which outperformed models 4x its size including Gopher (280B) and GPT-3 (175B).
Are LLM scaling laws hitting a wall?
Frontier labs are seeing diminishing returns from pure parameter scaling. Different capabilities plateau at different model sizes, high-quality training data is becoming scarce, and smaller models trained with better techniques are rapidly closing the gap with larger ones. However, new scaling dimensions like test-time compute, Mixture of Experts, and synthetic data are opening alternative paths to improvement.
How much does it cost to train a large language model?
Costs vary enormously. The original Transformer (2017) cost about $900. GPT-3 cost $500K-$4.6M. GPT-4 exceeded $100 million. Gemini Ultra was estimated at $191 million. Frontier model costs are projected to reach $5-10 billion by 2026. Fine-tuning existing models is far cheaper, often $500-$5,000 with LoRA adapters, making it the practical choice for most organizations.
Why are companies still investing in bigger models if scaling has diminishing returns?
Because even diminishing returns at the frontier can be valuable. A small improvement in reasoning capability can unlock entirely new use cases. Labs are also exploring new scaling dimensions beyond raw parameters, including inference-time compute (o1/o3 reasoning models), Mixture of Experts architectures, and higher-quality training data. The shift is from "bigger models" to "smarter scaling."
References
Scaling Laws for Neural Language Models - arXiv (Kaplan et al., OpenAI)
Training Compute-Optimal Large Language Models (Chinchilla) - arXiv (Hoffmann et al., DeepMind)
LLM Scaling Laws: Analysis from AI Researchers - AI Multiple
Scaling Laws for LLMs: From GPT-3 to o3 - Cameron R. Wolfe
Chinchilla Data-Optimal Scaling Laws: In Plain English - Alan D. Thompson
AI Model Scaling Isn't Over: It's Entering a New Era - AI Business
Machine Learning Model Training Cost Statistics 2026 - About Chromebooks / Stanford AI Index
How Much Does LLM Training Cost? - Galileo AI
AI Beyond the Scaling Laws - HEC Paris
A Riff on "The Slow Death of Scaling" - BlackHC Blog

