




GLM OCR vs GLM-5-Turbo: Which Zhipu AI Model Should You Actually Use?
Zhipu AI launched two models in early 2026 that solve completely different problems. GLM OCR reads documents better than almost anything on the market. GLM-5-Turbo executes multi-step AI agent workflows at a price that makes GPT-4 look expensive. I have spent time testing both, and the comparison most people are drawing - which one is better - is the wrong question entirely.
These two models are not competitors. They are two halves of the same automation stack. But if you need to choose where to start, the decision depends on what problem you are actually trying to solve. Let me break both down clearly, compare them on every dimension that matters, and tell you which one deserves your attention first.
What Is GLM OCR? The Document Intelligence Model
GLM-OCR is a 0.9 billion parameter multimodal model built by Zhipu AI and Tsinghua University, released in March 2026 specifically for complex document understanding. It topped the OmniDocBench V1.5 leaderboard with a score of 94.62, beating models that are many times larger in parameter count.
What makes GLM-OCR unusual is its design philosophy. Most OCR tools treat a document as flat left-to-right text. GLM-OCR treats a document as a structured layout with distinct regions: tables, formulas, headings, stamps, code blocks, and handwritten sections. It understands all of them and outputs clean Markdown, LaTeX, or JSON - whichever format your downstream pipeline needs.
The model is fully open-source under the MIT license. You can run it via the cloud API at 0.2 RMB per million tokens, deploy it locally with Ollama or Docker, or fine-tune it for your specific domain using LLaMA-Factory. For a 0.9B parameter model, the breadth of what it handles is genuinely surprising.
Why This Matters
Traditional OCR tools like Tesseract fail on nested tables, mathematical notation, and mixed-layout PDFs. GLM-OCR handles all three - and outputs structured data directly. No post-processing scripts needed.
How GLM OCR Works Under the Hood
GLM-OCR uses a two-stage pipeline that separates layout detection from content extraction. Stage 1 runs PP-DocLayout-V3 to analyze the page and identify every distinct region. Stage 2 processes each region in parallel using the model's language decoder - which is why it preserves semantic integrity across complex multi-column documents rather than mangling them into flat text.
The architecture combines a 0.4B CogViT visual encoder with a 0.5B GLM language decoder. That encoder-decoder split is what lets the model simultaneously understand what something looks like (a table, a formula, a signature) and what it means in context.
The speed story is interesting. GLM-OCR uses Multi-Token Prediction (MTP), predicting 10 tokens per step instead of one at a time. That single design choice delivers a 50% improvement in decoding throughput over comparable OCR models, reaching 1.86 PDF pages per second under benchmark conditions.
Training Approach
The model went through four training stages:
→ Stage 1: Vision-text pretraining to align visual and language representations
→ Stage 2: Multimodal pretraining with document parsing and visual QA tasks
→ Stage 3: Supervised fine-tuning on OCR-specific tasks (tables, formulas, KIE)
→ Stage 4: Reinforcement learning via GRPO with task-specific reward signals
The reward signals are worth noting: Normalized Edit Distance for text accuracy, CDM score for formulas, TEDS score for tables, and field-level F1 for key information extraction. Each task was optimized independently rather than using a single generic metric.
GLM OCR Benchmark Results and Real Numbers
The benchmark numbers are strong. Here is where GLM-OCR sits versus the field:
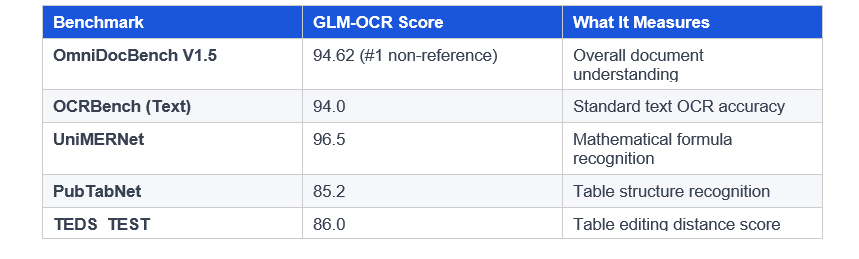
A few honest caveats: MinerU 2.5 scored 88.4 on PubTabNet versus GLM-OCR's 85.2. Gemini-3-Pro outperformed GLM-OCR on two KIE reference benchmarks (Nanonets-KIE and Handwritten-KIE). GLM-OCR is not the best at everything, but it leads on most tasks while running at a fraction of the compute cost of its larger competitors.
The API pricing reinforces this advantage: 0.2 RMB per million tokens is essentially negligible at production scale. For a team processing thousands of documents per day, this translates to real cost savings compared to GPT-4 Vision or similar alternatives.
What Is GLM-5-Turbo? The AI Agent Engine
GLM-5-Turbo is a language model released on March 16, 2026 by Zhipu AI. It is built specifically for OpenClaw - the company's AI agent execution platform - and it is not a general-purpose chatbot. Every design decision in this model was made around one use case: running multi-step autonomous workflows where an AI agent decomposes a complex instruction, calls external tools reliably, and hands results across multiple agents.
The context window is 200,000 tokens with up to 128,000 tokens of output per response. For agent tasks that involve reading long documents, maintaining state across many steps, and generating comprehensive outputs, that window size is practical rather than theoretical.
Pricing is aggressively positioned: $1.20 per million input tokens and $4.00 per million output tokens. For comparison, Claude Opus 4.6 runs $5 input and $25 output. That is a 4x to 6x cost difference at scale - which matters enormously when you are running thousands of agent invocations per day.
My Take
GLM-5-Turbo's pricing makes it worth testing for any developer currently running GPT-4 or Claude for structured agent tasks. The cost difference alone justifies a benchmark. What surprised me was that the benchmark performance held up - this is not a cheaper but worse option.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
How GLM-5-Turbo Works in the OpenClaw Ecosystem
OpenClaw is Zhipu AI's end-to-end agent framework - think of it as the orchestration layer that sits above the model. GLM-5-Turbo was aligned during training specifically on OpenClaw task patterns, which means its tool-calling behavior, output formatting, and multi-agent handoffs are tuned for that environment rather than being retrofitted after the fact.
The model supports real-time streaming responses, structured outputs, and integration with external toolsets and data sources. It handles six core OpenClaw task categories particularly well: information search and gathering, office automation, daily task management, data analysis, software development, and multi-agent orchestration.
ZClawBench Performance
Zhipu benchmarked GLM-5-Turbo on ZClawBench, their proprietary evaluation suite for end-to-end agent task completion. GLM-5-Turbo outperformed the full GLM-5 model and several competing alternatives across all six categories. The strongest margins were in information retrieval and data analysis workflows - exactly the tasks where document input matters most.
This is also where the connection to GLM-OCR becomes obvious. If GLM-5-Turbo handles data analysis best, and GLM-OCR handles document-to-structured-data conversion best, the two models together form a natural pipeline.
GLM OCR vs GLM-5-Turbo: Full Comparison
Here is a direct side-by-side of both models across every dimension that matters for a developer or team making a build decision:
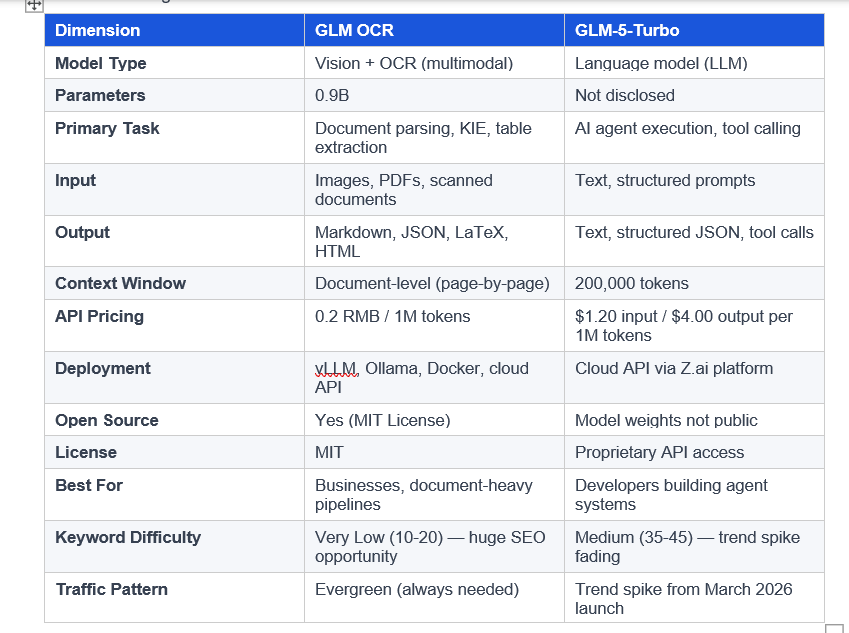
The clearest way to frame the difference: GLM-OCR is the eyes. It reads and structures input from the physical world - documents, invoices, forms, PDFs. GLM-5-Turbo is the brain. It reasons over structured data, calls tools, and takes action. In most serious automation pipelines, you need both.
Which One Should You Build On First?
This depends entirely on your current problem. Not on which model is technically superior - because that is the wrong axis to evaluate this on.
Choose GLM OCR if:
→ You process documents at scale: invoices, receipts, contracts, forms, academic papers
→ You need to extract structured data (tables, key fields, formulas) from unstructured PDFs
→ You want a lightweight, locally deployable model with no GPU requirement via API
→ Your team is in a cost-sensitive environment where per-token pricing matters
→ You are building in regulated industries (finance, healthcare, legal) that require local data processing
Choose GLM-5-Turbo if:
→ You are building autonomous AI agents that need to decompose tasks and call tools
→ Your workflow involves multi-step execution across different data sources and APIs
→ You are already using the OpenClaw ecosystem or evaluating it as an alternative to GPT-4 agents
→ You need a 200K token context window for long-running reasoning tasks
→ You want to significantly reduce agent API costs without sacrificing benchmark performance
The Honest Answer: Use Both
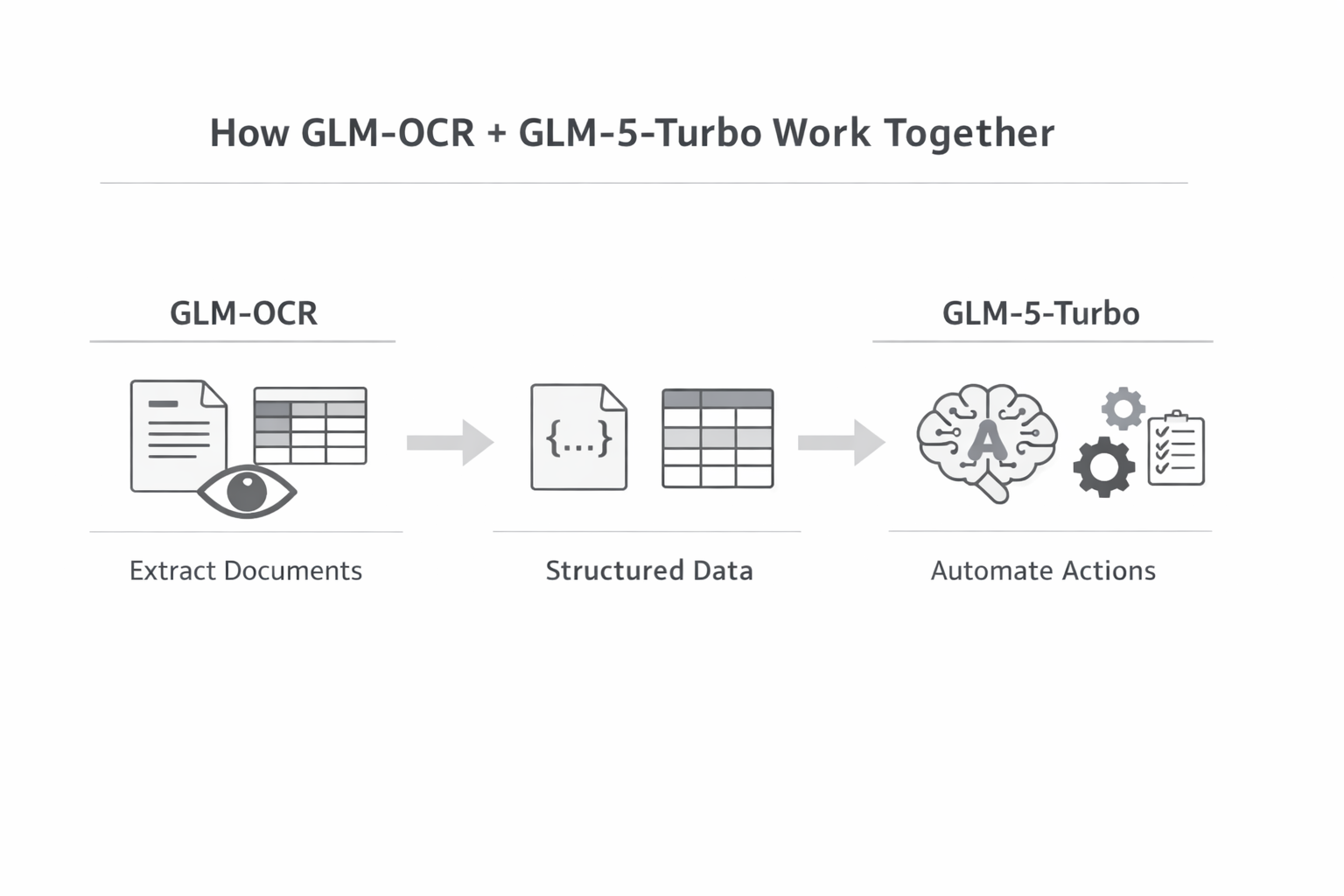
For anyone building a production automation pipeline in 2026, the real architecture looks like this: GLM-OCR extracts structured JSON from your document inputs. GLM-5-Turbo, running inside an OpenClaw agent, processes that structured data and routes it to downstream tools. You get accurate document parsing at 0.2 RMB per million tokens and intelligent execution at $1.20 per million tokens. The combination undercuts GPT-4 Vision plus GPT-4 agents by a significant margin on cost - while matching or exceeding benchmark performance on most task types.
Pipeline Example
Accounts payable automation: GLM-OCR reads invoices and outputs structured JSON (vendor, amount, line items). GLM-5-Turbo's OpenClaw agent validates the data, matches it against your ERP, flags anomalies, and triggers payment workflows. No human in the loop until exception handling.
How to Get Started with Each Model
Getting Started with GLM OCR
Installation takes under two minutes:
# Cloud API (no GPU needed)
pip install glmocr
# Self-hosted with layout detection
pip install "glmocr[selfhosted]"
# Or run locally with Ollama
ollama run glm-ocr
For Python integration:
from glmocr import GLMOCRClient
client = GLMOCRClient(api_key="your_key")
result = client.parse("invoice.pdf", output_format="json")
print(result)
Getting Started with GLM-5-Turbo
GLM-5-Turbo is accessible via the Z.ai developer platform. Sign up at z.ai, generate an API key, and you can start with their standard OpenAI-compatible API format. The model integrates directly into OpenClaw agent workflows, but it also works as a drop-in replacement for GPT-4 in standard tool-calling pipelines with minimal prompt adjustments.
Frequently Asked Questions
What is GLM-OCR and how is it different from regular OCR?
GLM-OCR is a 0.9B multimodal model from Zhipu AI that reads documents as structured layouts rather than flat text. Unlike traditional OCR tools such as Tesseract, it identifies tables, formulas, stamps, and handwritten content separately and outputs Markdown, JSON, or LaTeX directly. It scored 94.62 on OmniDocBench V1.5, ranking first among non-reference models.
What is GLM-5-Turbo and what is OpenClaw?
GLM-5-Turbo is an LLM launched March 16, 2026 by Zhipu AI, built specifically for OpenClaw - the company's AI agent execution framework. It handles multi-step workflows where an AI needs to call external tools, process long contexts, and coordinate across multiple agents. It offers a 200,000-token context window at $1.20 per million input tokens.
How is GLM-OCR different from GLM-5-Turbo?
GLM-OCR is a vision model for parsing documents into structured data. GLM-5-Turbo is a language model for executing agent workflows and tool-calling tasks. They serve different roles: GLM-OCR is input processing, GLM-5-Turbo is decision execution. In a full automation pipeline, GLM-OCR feeds structured data to GLM-5-Turbo agents.
Which GLM model has better SEO and content opportunity in 2026?
GLM-OCR currently offers a stronger content opportunity. The keyword 'glm ocr' carries very low difficulty (KD 10-20) with growing search volume, while adjacent terms like 'AI OCR for documents' and 'extract tables from PDF' have 10,000 to 200,000 monthly searches. GLM-5-Turbo keywords sit at medium KD (35-45) with a trend spike that will normalize over time. GLM-OCR traffic is more evergreen.
Can I use GLM-OCR locally without sending data to the cloud?
Yes. GLM-OCR supports local deployment via Docker, vLLM, SGLang, and Ollama. Install with 'pip install "glmocr[selfhosted]"' or run 'ollama run glm-ocr' for a local instance. The model can also be fine-tuned for domain-specific tasks using LLaMA-Factory. Cloud API is available at 0.2 RMB per million tokens for teams that prefer managed infrastructure.
Is GLM-5-Turbo cheaper than GPT-4 and Claude for agent tasks?
Yes, by a significant margin. GLM-5-Turbo runs at $1.20 per million input tokens and $4.00 per million output tokens. Claude Opus 4.6 is priced at $5 input and $25 output per million tokens. That is roughly a 4x to 6x cost reduction. For high-volume agent workflows, the savings at scale are substantial.
Recommended Blogs
If you found this useful, these posts from Build Fast with AI cover related topics worth reading:
GLM-5-Turbo: Zhipu AI's Agent Model Built for OpenClaw
How to Build AI Agents That Actually Work in Production
The Best Open-Source AI Models of 2026
Build Fast with AI — All Blogs
References
1. GLM-OCR Technical Report — arXiv
2. GLM-OCR GitHub Repository — Z.ai / Zhipu AI
3. Zhipu AI Introduces GLM-OCR — MarkTechPost
4. GLM-5-Turbo Launch — Trending Topics
5. GLM-5-Turbo Overview — Z.AI Developer Docs
6. GLM-5-Turbo: Agent Model Built for OpenClaw — Build Fast with AI
7. GLM-OCR on Hugging Face — zai-org/GLM-OCR
8. z.ai Debuts GLM-5-Turbo for Agents — VentureBeat

