




What Is Mixture of Experts (MoE)? How It Works and Why It Beats Dense Models
By Satvik Paramkusham, Founder of Build Fast with AI | Updated March 2026
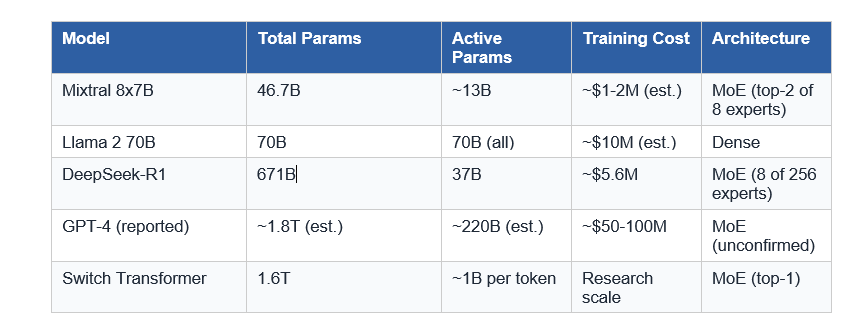
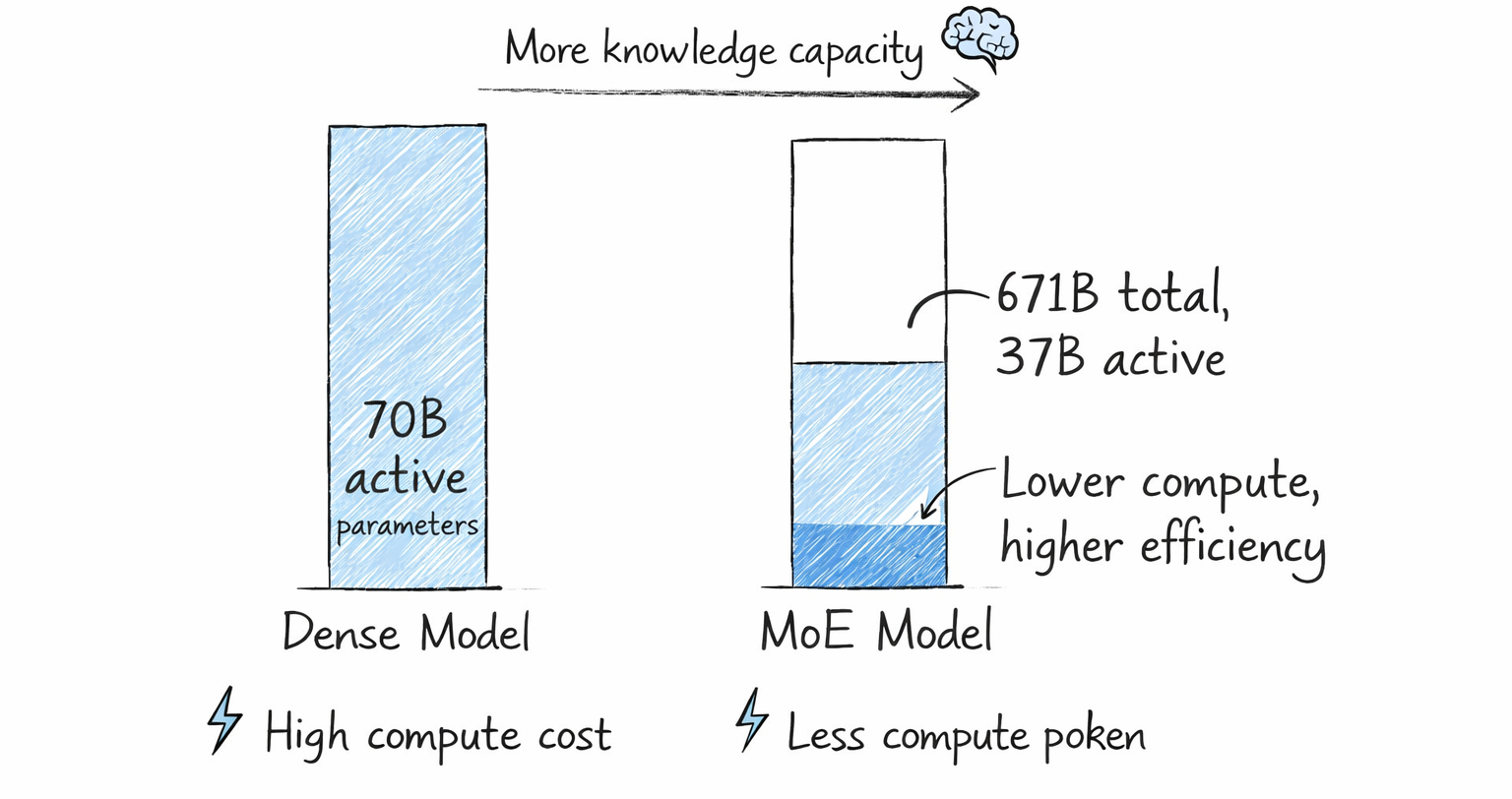
The biggest AI models in the world no longer activate all their parameters for every token. DeepSeek-R1 has 671 billion parameters, but only 37 billion fire per token. Mixtral 8x7B holds 46.7 billion parameters but runs inference at the speed of a 13B model. The architecture making this possible is called Mixture of Experts, or MoE, and in 2026, it's practically the default choice for any serious frontier model.
I've spent a lot of time studying MoE architectures while building with DeepSeek and Mixtral, and I'll be honest: when I first heard "37 billion out of 671 billion parameters active," I thought someone was lying about the math. They weren't. MoE genuinely lets a model carry enormous knowledge while spending a fraction of the compute cost to use it. That trade-off is the entire reason the top 10 open-source models as of 2025 almost all use this design.
Whether you're fine-tuning models, building RAG pipelines, or just trying to understand why DeepSeek-R1 trained for $5.6 million while GPT-4 reportedly cost $50 to $100 million, this is the architecture you need to understand. Let's break it down properly.
What Is Mixture of Experts in AI?
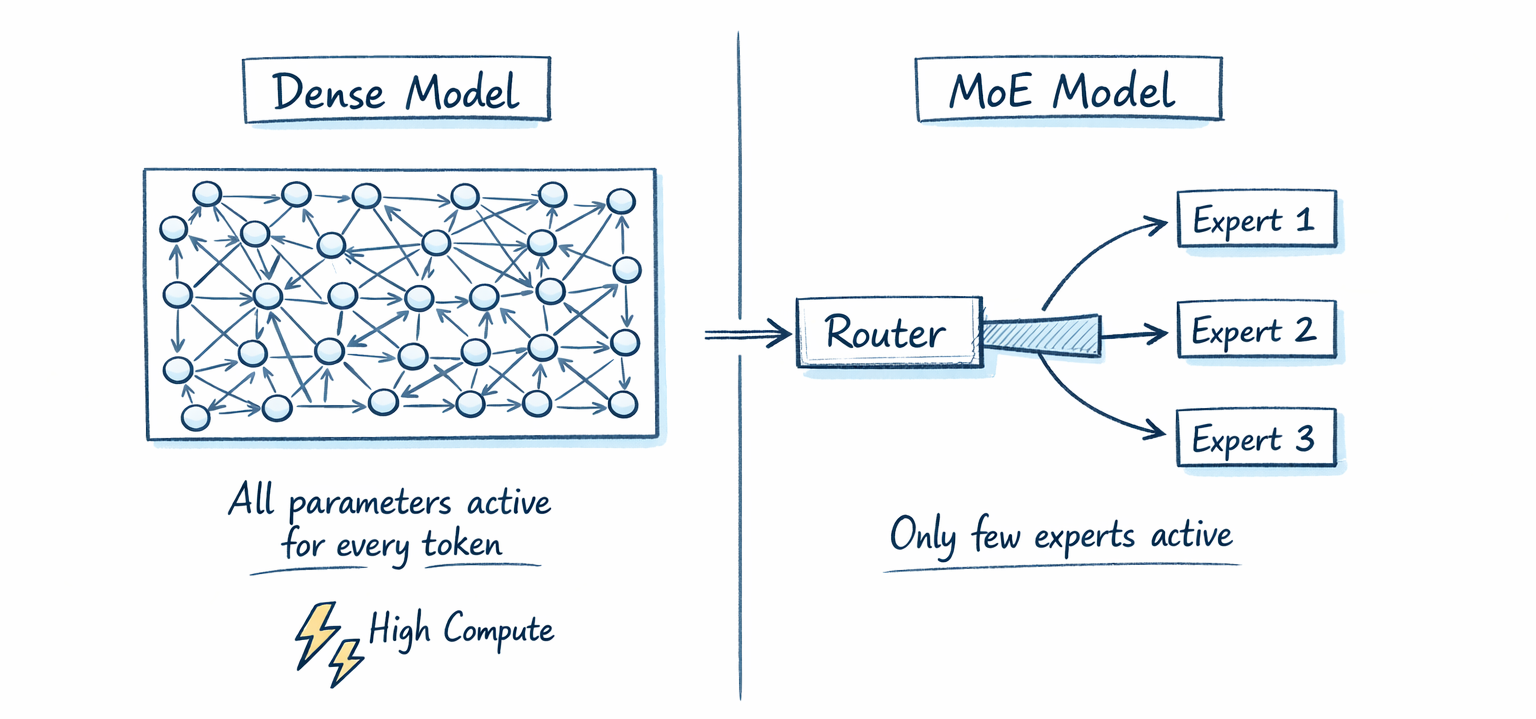
Mixture of Experts is a neural network architecture that routes each input token to a small subset of specialized sub-networks, called experts, instead of activating the entire model for every token. The result is a sparse model: total parameter count stays large (good for knowledge capacity), but computation per token stays small (good for speed and cost).
The concept isn't new. In 1991, Robert Jacobs, Michael Jordan, Steven Nowlan, and Geoffrey Hinton published "Adaptive Mixtures of Local Experts" in Neural Computation. They proposed training a group of separate networks, each learning to handle a different subset of training cases, controlled by a gating network that decided which expert to activate. At the time, they demonstrated this on vowel discrimination tasks. Simple problem, massive idea.
For two decades, MoE stayed mostly academic. Then in 2017, Noam Shazeer (alongside Geoffrey Hinton and Jeff Dean at Google) scaled MoE to a 137 billion parameter LSTM model using sparse gating. By 2021, Google's Switch Transformer scaled it further to 1.6 trillion parameters. The architecture crossed a threshold from interesting to unavoidable.
Key stat: As of 2025, the top 10 most capable open-source AI models all use MoE architecture. This isn't a niche technique anymore.
Why Dense Models Hit a Wall
To understand why MoE matters, you need to understand the problem it solves. In a dense transformer (think GPT-2, original Llama, or Mistral 7B), every single parameter activates for every single token. When you prompt a dense 70B model, all 70 billion parameters fire for every token in your input and every token generated.
This creates a brutal scaling problem. Want a smarter model? You need more parameters. More parameters means more compute per token, more memory, more GPUs, and more cost per inference. Training GPT-4 reportedly cost between $50 million and $100 million. Dense scaling is a linear tax.
The deeper issue: not all parameters are useful for all inputs. A question about Python syntax probably doesn't need the same neural pathways as a question about Roman history. But in a dense model, every neuron fires regardless, wasting computation on parameters contributing nothing to the current task.
MoE breaks this link between parameter count and compute cost. You can double the knowledge capacity without doubling inference cost. That's the insight everything else follows from.
What Are Experts and Why Are They Called That?
In an MoE model, each "expert" is a standard feed-forward neural network (FFN) with its own independent set of parameters. In a transformer architecture, experts replace (or augment) the feed-forward layer inside each transformer block. The analogy to "experts" comes from the 1991 Jacobs et al. paper, which compared them to human specialists: a cardiologist for heart issues, a dermatologist for skin problems.
Here's the important counterintuitive part: experts don't specialize in topics the way people assume. A common misconception is that one expert handles math, another handles code, another handles creative writing. Research on Mixtral 8x7B shows that experts tend to specialize in syntactic and computational patterns, not semantic domains. One expert might handle certain token types or linguistic structures across many topics.
In Mixtral 8x7B, each transformer layer has 8 feed-forward expert networks. For every token, a router selects exactly 2 of those 8. Each expert has identical internal architecture (same FFN dimensions), but their weights diverge during training as they see different token distributions. Nobody manually assigns roles. The model learns specialization entirely on its own.
My take: This emergent specialization is fascinating and slightly humbling. We design the architecture, set up the training incentives, and the model figures out its own division of labor better than we could prescribe manually.
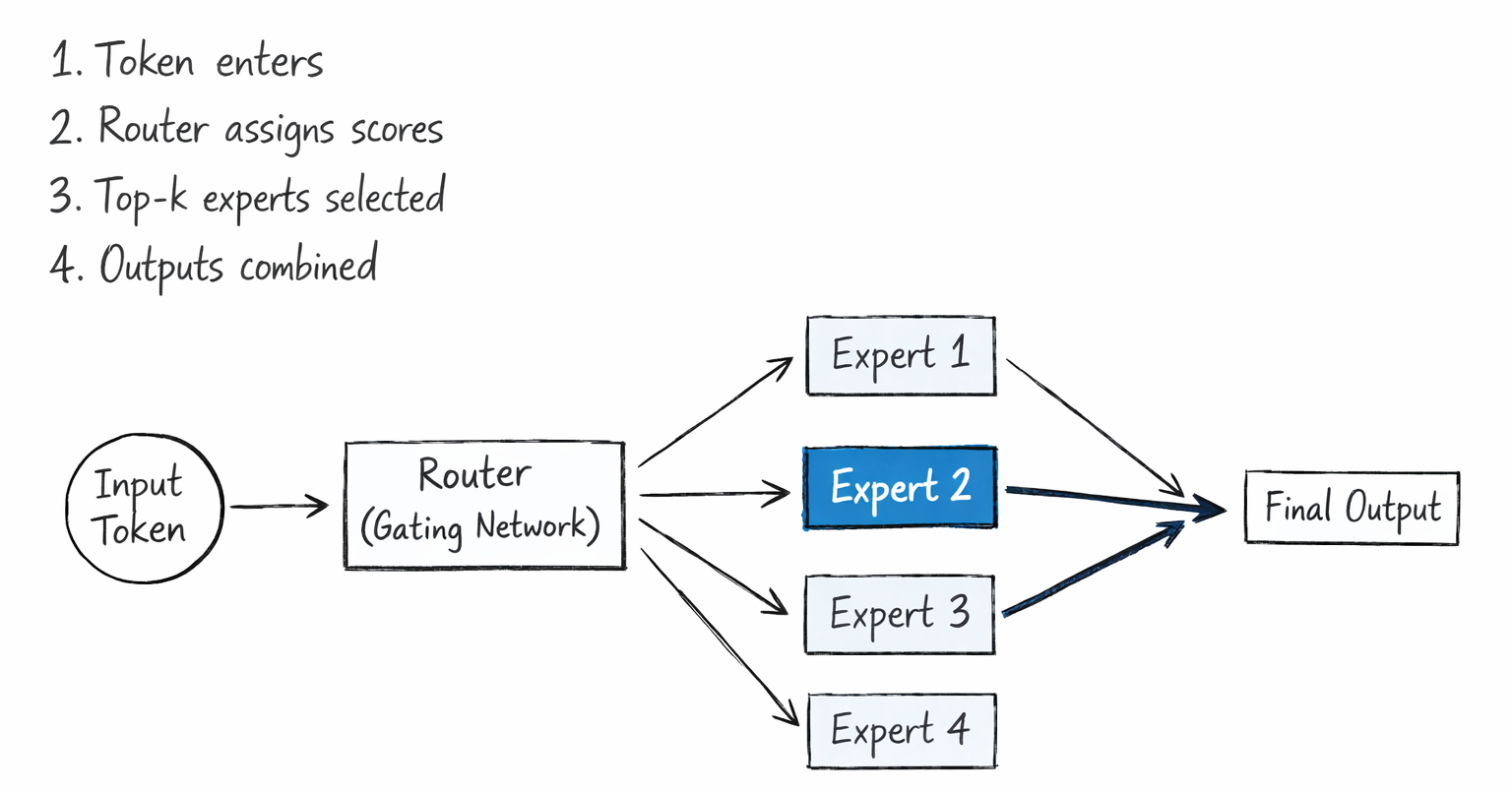
How the Router Decides Which Expert to Use
The router (gating network) is a small, trainable linear layer followed by a softmax function. It takes each token's representation as input and outputs a probability score for every expert. The top-k experts with the highest scores are selected, and only those experts process the token.
Here's the step-by-step process:
- Token arrives at an MoE layer as a representation vector
- Router multiplies that vector by its weight matrix to produce one score per expert
- Softmax converts scores to probabilities across all experts
- Top-k experts (typically 1 or 2) are selected based on highest probability
- Selected experts process the token independently
- Expert outputs are combined as a weighted sum, using the router's probability scores as weights
Different models choose different top-k values. The Switch Transformer uses top-1 (simplest, lowest overhead). Mixtral uses top-2. DeepSeek-V3 takes it to an extreme: 256 experts per layer with 8 active per token.
Load balancing is the critical engineering challenge here. If the router sends most tokens to a few popular experts while ignoring others, those experts get overloaded and the rest go undertrained. This is called routing collapse. The Switch Transformer solved this with auxiliary load-balancing losses during training. DeepSeek-V3 took a different approach entirely, eliminating auxiliary losses and instead using a bias term on gating values that adjusts dynamically when experts become imbalanced.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
MoE vs Dense Models: Efficiency Comparison
The efficiency advantage is simple: massive increase in knowledge capacity, without proportionally increasing compute per token. Here's what that looks like in practice.
Consider Mixtral 8x7B. It has 46.7 billion total parameters but activates only roughly 13 billion per token during inference. The result: it outperforms Llama 2 70B on 9 out of 12 evaluated benchmarks, including mathematics, code generation, and multilingual understanding, while running approximately 6x faster at inference. Llama 2 70B is a dense model. It always activates all 70 billion. Mixtral routes smarter.
Google's research comparing MoE and dense models at 6.4B, 12.6B, and 29.6B scales found MoE models consistently outperformed dense baselines. At the 6.4B scale, an MoE model was 2.06x faster per training step while achieving better benchmark performance. A separate study found MoE models show approximately 16.37% better data utilization than dense models under similar computational budgets.
The trade-off nobody mentions enough: MoE saves compute, not memory. All experts must be loaded into GPU memory because the router needs access to all of them for dynamic decisions. DeepSeek-R1 still requires around 800 GB of GPU memory in FP8 format. If you're trying to run it locally, you need a server with 8 NVIDIA H200 GPUs minimum. This distinction trips up a lot of practitioners.
Real-World MoE Models You Should Know (2026)
The MoE landscape exploded in 2023-2025. Here are the models that define the current state of the art:
Mixtral 8x7B (Mistral AI, December 2023)
The model that brought MoE to the open-source mainstream. 46.7B total parameters, ~13B active per token. Matched or beat GPT-3.5 and Llama 2 70B across most benchmarks, released under Apache 2.0. It proved MoE could work brilliantly at consumer-accessible scales.
DeepSeek-V3 and DeepSeek-R1 (DeepSeek, Dec 2024/Jan 2025)
The current MoE benchmark. 671B total parameters, 37B active, 256 experts per layer with 8 active per token. R1 added reinforcement learning on top, achieving 79.8% on AIME and 2,029 Elo on Codeforces-style challenges, on par with OpenAI's o1. Trained for approximately $5.6 million in GPU hours.
Google Switch Transformer (2021)
The first 1.6 trillion parameter model. Used top-1 routing (single expert per token), demonstrating that one expert was sufficient for strong performance. It was 4x faster than T5-XXL at reaching equivalent quality benchmarks.
GPT-4 (OpenAI, March 2023)
Widely reported (though not officially confirmed by OpenAI) to use an MoE architecture. If accurate, it would explain strong performance across diverse tasks while maintaining manageable inference speeds. OpenAI has never officially confirmed the architecture details.
Gemini 1.5 (Google, February 2024)
Google's multimodal MoE model, notable for its 1 million token context window. Google's official technical report confirms an MoE architecture, though specific expert counts are not disclosed
Key Challenges and Trade-Offs
MoE isn't a free lunch. Here are the real challenges, ranked by how much they'll actually affect you as a practitioner:
1. Memory Requirements
All experts must reside in GPU memory simultaneously, even though only a subset fires per token. A model like DeepSeek-R1 requires around 800 GB of GPU memory in FP8 format. For local deployment, quantized versions or distilled dense variants like DeepSeek-R1-Distill-Qwen-32B are the practical option.
2. Training Stability
Hard routing decisions can cause instability, especially in lower precision formats like bfloat16. The Switch Transformer team solved this by selectively casting router computations to float32 precision while keeping everything else in bfloat16. Worth knowing if you're doing any custom training.
3. Fine-Tuning Behavior
MoE fine-tunes differently than dense models. Research from the ST-MoE project found that freezing only the MoE layer parameters (roughly 80% of the model) during fine-tuning preserves nearly all performance while significantly reducing training time. Sparse models also tend to benefit from smaller batch sizes and higher learning rates.
4. Expert Utilization Imbalance
Routing collapse, where a few experts handle most tokens while others are undertrained, remains an active research problem. The evolution from auxiliary losses (Switch Transformer) to bias-based routing (DeepSeek-V3) shows the field is still iterating on this.
How to Get Started with MoE Models
If you want to experiment today, here are the practical entry points:
- Mixtral 8x7B locally: Fits on consumer GPUs with quantization (4-bit or 8-bit). Use Ollama or llama.cpp for the simplest setup. Best starting point if you're new to MoE.
- DeepSeek-R1 distilled variants: The 32B distilled version retains most of R1's reasoning capability at a fraction of the cost. Runs on vLLM and SGLang. This is what I'd recommend for most production use cases today.
- API access: Both Mixtral and DeepSeek-R1 are available via Together AI, Fireworks AI, and other inference providers if you want to skip the infrastructure entirely.
For application developers, MoE models are especially well-suited for RAG pipelines, multi-turn agents, and real-time assistants. The reduced per-token compute cost compounds significantly when your application makes many sequential model calls.
If you're on the research side, the active frontier questions include: optimal activation rates (recent work suggests around 20% activation is a sweet spot), better routing mechanisms beyond simple linear routers, and scaling expert counts into the hundreds while maintaining training stability.
People Also Ask (FAQ)
What is Mixture of Experts (MoE) in simple terms?
MoE is a model architecture that splits the model into multiple specialized sub-networks called experts, then uses a router to activate only a few of them for each input token. Instead of running all parameters every time, it routes each token to the most relevant experts. This lets a model have more total knowledge without proportionally more compute cost.
How is MoE different from a dense model?
A dense model activates 100% of its parameters for every token. An MoE model might have 671 billion total parameters but only activate 37 billion (about 5.5%) per token. Dense models scale compute linearly with parameter count. MoE breaks that relationship.
Why does MoE use less compute but not less memory?
Because the router needs access to all experts to make dynamic routing decisions per token. All expert weights must be loaded into GPU memory at inference time, even if only a few fire. This is the core trade-off: MoE saves FLOPs (compute), not memory footprint.
Which AI models use Mixture of Experts architecture?
Confirmed MoE models include Mixtral 8x7B and 8x22B (Mistral AI), DeepSeek-V3 and DeepSeek-R1, Google Switch Transformer, and Gemini 1.5. GPT-4 is widely reported to use MoE, but OpenAI has not officially confirmed this.
What is routing collapse in MoE models?
Routing collapse happens when the gating network learns to send most tokens to a small subset of popular experts while ignoring others. The overloaded experts become undertrained on diverse data, while the neglected ones waste capacity. Load balancing losses during training (or dynamic bias adjustments in DeepSeek-V3's approach) prevent this.
Can I fine-tune a Mixture of Experts model?
Yes. Research from the ST-MoE project recommends freezing the MoE layer parameters (about 80% of the model) and fine-tuning only the attention layers and other non-expert components. This preserves performance while dramatically reducing fine-tuning cost and improving stability.
Is Mixture of Experts better than dense models?
For most large-scale tasks, yes on compute efficiency. MoE models consistently match or outperform dense models of equivalent compute cost, and outperform dense models with similar total parameter counts. The catch is the memory requirement: MoE models still need large GPU memory to hold all experts, even if only a fraction activate per token.
What does "top-k routing" mean in MoE?
Top-k routing means the gating network selects the k experts with the highest probability scores for each token. Top-1 routing (one expert per token, used in Switch Transformer) minimizes overhead but loses some representational richness. Top-2 (used in Mixtral) is the most common balance. DeepSeek-V3 uses top-8 out of 256 experts.
Recommended Blogs
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
Claude Code vs GitHub Copilot: Which AI Coding Tool Is Actually Better in 2026?
DeepSeek-R1 Deep Dive: Architecture, Benchmarks, and How to Run It
How to Build a RAG Pipeline with Mixtral 8x7B (Step-by-Step)
LLM Benchmarks Explained: What MMLU, HumanEval, and AIME Actually Test
Want to Build With Cutting-Edge AI Architectures Like MoE?
Join Build Fast with AI's Gen AI Launchpad, an 8-week structured bootcamp to go from 0 to 1 in Generative AI. Register at buildfastwithai.com/genai-course.
References
Adaptive Mixtures of Local Experts (1991) - MIT Press / Neural Computation
Switch Transformers: Scaling to Trillion Parameter Models - JMLR (2022)
Applying Mixture of Experts in LLM Architectures - NVIDIA Technical Blog (2024)
Revisiting MoE and Dense Speed-Accuracy Comparisons - arXiv (2024)
Scaling Laws Across Model Architectures: Dense and MoE Models - arXiv (2024)
A Visual Guide to Mixture of Experts - Maarten Grootendorst (2024)

