




Google Gemma 4: The Best Open AI Model in 2026?
I woke up on April 2, 2026, opened my feed, and Google had quietly dropped the biggest open-model release of the year. Four models. Apache 2.0 license. Built on the same research as Gemini 3. Runs on your phone, your laptop, a Raspberry Pi, or a single NVIDIA H100. I have been waiting for Google to go fully open for years, and Gemma 4 is that moment.
Google DeepMind's Gemma 4 launched on April 2, 2026, as a family of four open-weight AI models designed to run on everything from Android smartphones to developer workstations. The 31B Dense model currently ranks #3 on the Arena AI text leaderboard, beating models 20x its size. And every variant ships under a fully permissive Apache 2.0 license for the first time in the Gemma family's history.
This is not a small release. It is a statement.
What Is Google Gemma 4?
Google Gemma 4 is Google DeepMind's latest family of open-weight AI models, released on April 2, 2026, under the Apache 2.0 license. Built from the same research and architecture that powers Gemini 3, the commercial flagship, Gemma 4 brings that frontier-level intelligence to the open-source community.
The name "Gemma" (from the Latin for gem) has been Google's open-model brand since 2024. The first Gemma models launched in 2B and 7B sizes. Since then, the series has crossed 400 million total downloads and spawned over 100,000 community variants. Gemma 4 is the fourth generation, and by every measurable metric, it is the biggest leap yet.
What separates Gemma 4 from every previous Gemma release comes down to three things: intelligence-per-parameter efficiency that beats models 20x its size, native multimodal capabilities baked into the architecture from day one (not bolted on after), and a truly permissive license that enterprise legal teams will actually accept.
Google DeepMind CEO Demis Hassabis called them "the best open models in the world for their respective sizes." That is a bold claim. The benchmarks, which I will walk through below, mostly back it up.
Gemma 4 Model Sizes and Variants Explained
Gemma 4 ships in four sizes: E2B, E4B, 26B MoE, and 31B Dense. These are split into two deployment tiers: edge models for phones and embedded devices, and workstation models for GPUs and servers.
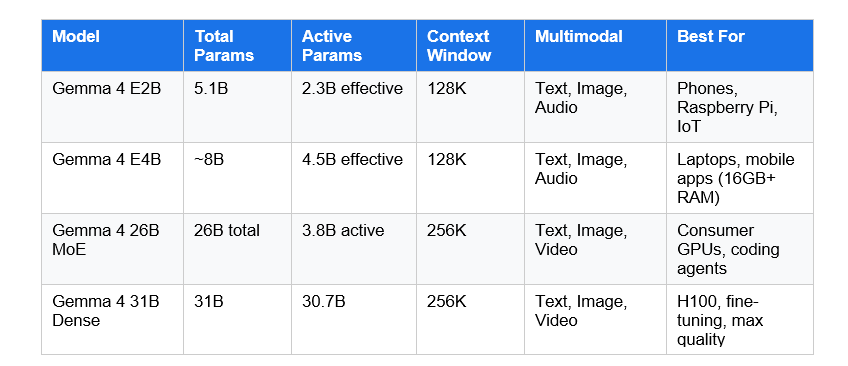
The naming convention here trips people up. The 'E' prefix in E2B and E4B stands for effective parameters, not total parameters. The E2B has 5.1 billion total parameters but activates only 2.3 billion during inference, which is what matters for speed and memory consumption.
The 26B MoE is my personal pick for most developers. It activates only 3.8 billion parameters per token during inference while delivering 97% of the dense 31B model's output quality. That ratio is remarkable. You get 27B-class reasoning at 4B-class speed. Running it on a 24GB GPU with Q4 quantization is entirely realistic.
The E2B and E4B models also include native audio processing, meaning speech recognition and speech-to-translated-text entirely on-device. The larger models process images and video but not audio. It is an unusual split that probably surprised a few people.
Gemma 4 Benchmarks: How Good Is It Really?
On AIME 2026, the mathematical reasoning benchmark, Gemma 4 31B scores 89.2%. Gemma 3 27B scored 20.8% on the same test. That is not incremental improvement. That is a completely different model.
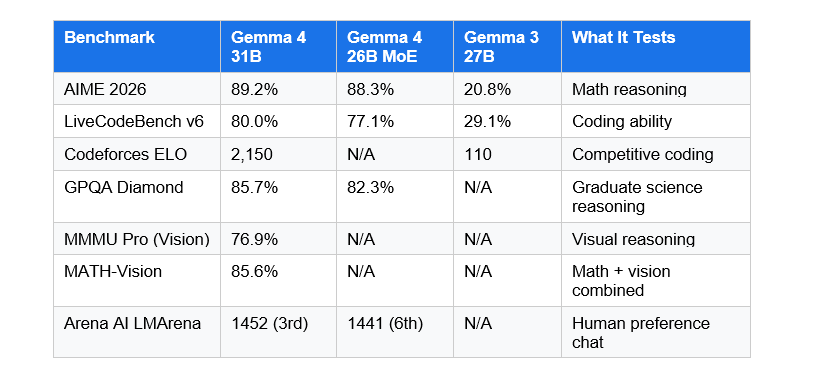
I will be honest: I was skeptical reading these numbers. A 31B model ranking third on the Arena AI leaderboard against models with hundreds of billions of parameters felt like benchmark cherry-picking. But the Codeforces ELO jump from 110 to 2,150 is not a cherry-picked stat. That is a real, independently measured signal about coding capability.
The 26B MoE model deserves a separate call-out. It scores 88.3% on AIME 2026 with only 3.8B active parameters. For comparison, the dense 31B activates 30.7B parameters for every token. You are getting nearly identical reasoning quality at roughly one-eighth the inference compute. If you are building a production coding assistant or agentic workflow, the MoE variant is almost certainly the right choice on cost grounds alone.
The long-context story is also genuinely improved. On multi-needle retrieval tests, the 31B model went from 13.5% accuracy with Gemma 3 to 66.4% with Gemma 4 at a 256K context window. That is the difference between a model that loses track of what you told it 50 pages ago versus one that actually uses your entire document.
Is Gemma 4 Open Source? (The Apache 2.0 License Shift)
Yes. Gemma 4 is fully open source under the Apache 2.0 license. This is a significant change from every previous Gemma release, which shipped under a custom 'Gemma License' with usage restrictions and terms Google could update at will.
For enterprise teams, this matters more than most people realize. The old Gemma license required legal review. Compliance teams flagged edge cases. Some organizations simply could not use Gemma because their legal frameworks required standard open-source terms. Apache 2.0 eliminates all of that friction.
Hugging Face co-founder Clement Delangue described the licensing shift as "a huge milestone" for the open-source AI ecosystem. The Qwen and Mistral model families have both used Apache 2.0 for a while, which pushed enterprise adoption toward them over Gemma. That competitive disadvantage is now gone.
Apache 2.0 means you can use Gemma 4 commercially, modify it, redistribute it, fine-tune it and sell the result, and deploy it in products without restriction. The only requirement is attribution. For AI developers building products, this is the license you want.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Gemma 4 Architecture: What Makes It Different
Gemma 4 uses a hybrid attention architecture that alternates between local sliding-window attention and global full-context attention layers. This design enables the 256K context window without exploding memory consumption, which is the hard engineering problem that has limited most open models.
There are two architectural features worth understanding if you plan to deploy or fine-tune Gemma 4.
Per-Layer Embeddings (PLE): A second embedding table feeds a small residual signal into every decoder layer. Each layer gets a token-identity component tailored specifically to its role in the network. This is a quiet innovation that contributes to the quality jump, and it is not something competitors have widely adopted yet.
Shared KV Cache: The final N decoder layers share key-value states from earlier layers, eliminating redundant KV projections. This reduces memory usage during long-context inference without a meaningful quality hit. For teams running 256K-token inference on codebases or long documents, this translates directly to GPU memory savings.
The MoE architecture in the 26B model is also worth a note. Google chose 128 small experts with 8 active per token plus one always-on shared expert, rather than the pattern of a handful of large experts used by other models. The result is a model that benchmarks at 27B-to-31B dense quality while running at roughly 4B-class throughput. That is not just a benchmark curiosity. It directly affects what hardware you need and what it costs to serve.
How to Download and Run Gemma 4 with Ollama
Ollama is the fastest way to get Gemma 4 running locally. You can have the E2B model generating responses in under five minutes on any modern laptop. Here is exactly how to do it.
Step 1: Install Ollama
Download Ollama from ollama.com/download. It supports Windows, macOS, and Linux. Run the installer and confirm it works:
ollama --versionStep 2: Pull Your Preferred Gemma 4 Model
# Smallest — runs on most phones and laptops (5GB RAM)
ollama run gemma4:e2b
# Recommended for 16GB+ RAM laptops
ollama run gemma4:e4b
# MoE — best quality/cost ratio on 24GB GPU
ollama run gemma4:26b
ollama run gemma4:31b # Max quality — needs 80GB H100Hardware Requirements at a Glance
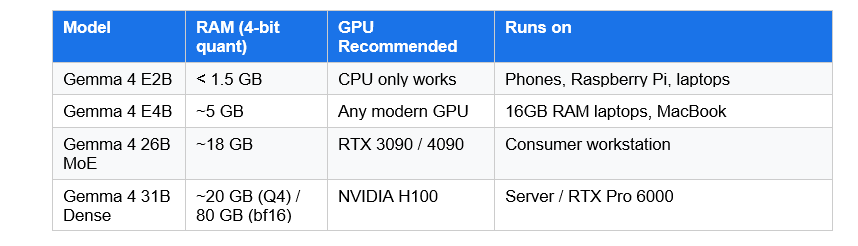
Ollama handles the chat template complexity automatically. Once the model is running, it exposes a local API at http://localhost:11434, which is compatible with the OpenAI SDK. Any application that supports OpenAI models can be pointed at your local Gemma 4 instance with no code changes.
If you prefer a GUI, LM Studio and Google AI Edge Gallery both support Gemma 4 on day one. You can also access the 31B and 26B models directly in Google AI Studio without any local setup.
Gemma 4 vs Qwen3 vs Llama 4: Which Should You Use?
At the small-to-medium size tier, Gemma 4 now leads. Qwen 3.5 still holds an edge at massive scale (the 397B flagship is a different class of model), and Llama 4 offers a 10-million-token context window that Gemma 4 does not match. But for most practical deployments, Gemma 4 wins on the metrics that matter.
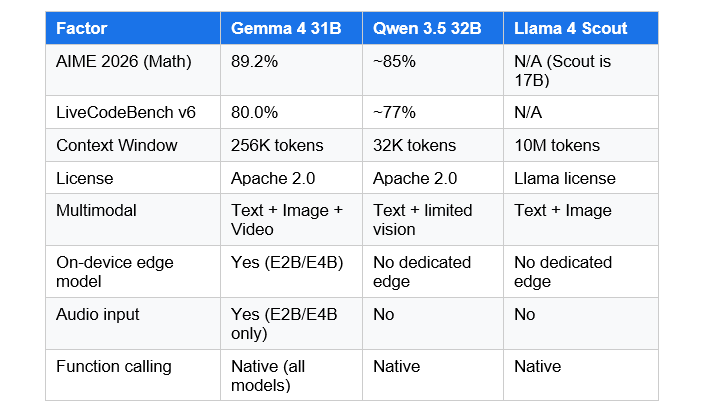
My honest take: use the Gemma 4 26B MoE if you are building a coding assistant, document processing pipeline, or agentic workflow and your documents fit in 256K tokens. Use Llama 4 Scout if you need that absurd 10-million-token context for truly massive codebases or multi-document reasoning. Use Qwen 3.5 if you need deep multilingual support for CJK or other non-Latin scripts, where Qwen's 250K-vocabulary advantage still holds.
The bigger shift in this release is not benchmark position. It is the Apache 2.0 license. Enterprises that had been blocked by Gemma's custom license terms now have no reason to avoid it.
Gemma 4 Real-World Use Cases
Gemma 4 is built for agentic workflows first. Google designed function calling and structured JSON output into the architecture from the ground up, not as a post-training patch. Here are the concrete use cases this unlocks:
Private coding assistant: Run the 26B MoE locally on a workstation. Feed your entire codebase in a single 256K-token prompt. Get bug fixes and feature implementation without sending a single line of proprietary code to a cloud server. This is directly supported in Android Studio using Agent Mode with Gemma 4 as the local model.
On-device multilingual voice interface: The E2B and E4B models support native audio input for automatic speech recognition and speech-to-translated-text. 140+ languages, processed entirely on the phone, with no internet connection required. For healthcare, field service, or multilingual customer interaction use cases, this replaces an external ASR pipeline entirely.
Edge AI and robotics: On a Raspberry Pi 5, Gemma 4 E2B achieves 133 tokens per second prefill throughput and 7.6 tokens per second decode throughput via LiteRT-LM. That is fast enough for real-time smart home controllers and voice assistants running completely offline.
Long-document analysis: At 256K tokens, Gemma 4 can process approximately 200 pages of text in a single prompt. The multi-needle retrieval accuracy of 66.4% (up from 13.5% in Gemma 3) means it actually uses that context rather than losing information halfway through.
Fine-tuning for specialized domains: Under Apache 2.0, you can fine-tune Gemma 4 and distribute the result commercially. Google has already demonstrated this with Yale University's Cell2Sentence-Scale for cancer research and INSAIT's Bulgarian-first language model. Your fine-tuned variant is yours to deploy however you want.
FAQ: Everything People Are Asking About Google Gemma 4
What is Google Gemma 4?
Google Gemma 4 is a family of four open-weight AI models released by Google DeepMind on April 2, 2026. The models come in four sizes (E2B, E4B, 26B MoE, 31B Dense), support multimodal input including text, images, audio, and video, and are built from the same research as the Gemini 3 commercial model. The entire family is released under an Apache 2.0 license.
Is Gemma 4 open source?
Yes. Gemma 4 is released under the Apache 2.0 license, which is the most permissive open-source license widely used in AI. This is a change from previous Gemma versions, which used a custom Gemma License with commercial restrictions. Apache 2.0 allows commercial use, redistribution, and modification with no special restrictions beyond attribution.
How do I download and run Gemma 4 with Ollama?
Install Ollama from ollama.com/download. Then run 'ollama run gemma4:e2b' for the smallest model or 'ollama run gemma4:26b' for the recommended MoE variant. The E2B model runs with under 1.5 GB of memory. The 26B MoE needs approximately 18 GB in Q4 quantization. Ollama handles the full setup automatically.
What is the parameter count of Gemma 4 E4B?
The Gemma 4 E4B has approximately 8 billion total parameters but only 4.5 billion effective parameters during inference. The 'E' in the name denotes effective parameters, which is what determines actual speed and memory requirements. This makes E4B well-suited for 16GB laptops and modern mobile devices.
Is Qwen3 better than Gemma 4?
It depends on the task and size tier. Gemma 4 31B outperforms Qwen 3.5 32B on AIME 2026 math reasoning (89.2% vs approximately 85%) and LiveCodeBench coding. However, Qwen 3.5 has superior multilingual vocabulary coverage (250K-token vocab vs Gemma 4's 256K context) for CJK and non-Latin scripts. For most English-language and coding tasks, Gemma 4 now leads at the 26-31B size tier.
What is Google Gemma 4 31B performance on benchmarks?
Gemma 4 31B Dense scores 89.2% on AIME 2026, 80.0% on LiveCodeBench v6, a Codeforces ELO of 2,150, 85.7% on GPQA Diamond graduate-level science reasoning, and 76.9% on MMMU Pro visual reasoning. It currently ranks third on the Arena AI text leaderboard with an estimated LMArena score of 1,452, outperforming models with up to 20x more parameters.
Can Gemma 4 run on a consumer GPU?
Yes. The Gemma 4 26B MoE runs on a 24GB GPU such as an NVIDIA RTX 3090 or 4090 with Q4 quantization. The 31B Dense model fits on a single 80GB NVIDIA H100 at full bfloat16 precision, or on consumer GPUs using quantized versions. The E2B and E4B models run on CPUs, including Raspberry Pi 5 and Apple M-series Macs.
What platforms support Gemma 4 on day one?
Gemma 4 has day-one support across Hugging Face Transformers, Ollama, LM Studio, llama.cpp, MLX, vLLM, NVIDIA NIM and NeMo, Unsloth, SGLang, Docker, Keras, and Google AI Studio. The model weights are downloadable from Hugging Face, Kaggle, and Ollama. Google AI Edge Gallery supports E2B and E4B for mobile devices.
Recommended Blogs
These are real, published posts from buildfastwithai.com that are directly relevant to readers of this Gemma 4 piece:
Google Releases Gemma 3 — Here's What You Need To Know
How to Run Google's Gemma 3 270M Locally: A Complete Developer's Guide
Supercharge LLM Inference with vLLM
How to Build a General-Purpose LLM Agent
Sarvam-105B: India's Open-Source LLM for 22 Indian Languages (2026)
Related Cookbooks
References
All sources cited in this blog post. Every link verified as live on April 3, 2026.
Google DeepMind
Hugging Face
VentureBeat
Unsloth
Ollama Library
Google AI Developers
Lushbinary

