





Sarvam-105B: Is This India's Real Answer to ChatGPT - or Just Good PR?
I opened LinkedIn on the morning of February 18, 2026, and half my feed was celebrating Sarvam AI like it had just won a World Cup. An Indian startup - bootstrapped on $50 million and built in Bengaluru - had just dropped two open-source LLMs: Sarvam-30B and Sarvam-105B. The 105B model, trained from scratch, clocks 98.6 on Math500 and wins 90% of pairwise comparisons in Indian language benchmarks.
That number stopped me cold. A 105-billion-parameter model from an Indian startup outperforming DeepSeek-R1 on certain benchmarks - a model that has 671 billion parameters - is not something you expect to read on a Tuesday morning.
But here's the thing: I've seen Indian AI hype before. Sarvam itself got roasted in 2025 for releasing Sarvam-M, which was basically Mistral Small with Indian fine-tuning. Critics called it a foreign model wearing a desi kurta. So this time, I wanted to actually dig into what Sarvam-105B is, what the benchmarks actually mean, and whether this is genuinely India's sovereign AI moment - or just another well-timed announcement.
What Is Sarvam-105B?
Sarvam-105B is India's first fully domestically-trained, open-source large language model at 105 billion parameters, built by Bengaluru-based startup Sarvam AI and released in February 2026.
That sentence matters more than it sounds. The word 'domestically-trained' is doing a lot of work here. Unlike Sarvam-M - the company's earlier model from May 2025 that was fine-tuned from Mistral Small, a French model - Sarvam-105B was trained from scratch. That's the distinction that makes critics sit up and take notice.
The model was released under the Apache 2.0 license, meaning startups, researchers, and enterprises can download, deploy, and modify it commercially without paying licensing fees. Weights are available on Hugging Face (sarvamai/sarvam-105b) and AI Kosh.
Sarvam AI was selected by the IndiaAI Mission to build India's sovereign LLM ecosystem - a government-backed initiative funded with INR 10,372 crore ($1.1 billion). This release is the first major public deliverable of that mandate.
My take: The 'sovereign AI' label carries real weight for government procurement and strategic deployments. For pure developers? The Apache license and open weights matter more than the patriotism angle.
Architecture: Why MoE Changes Everything
Sarvam-105B uses a Mixture-of-Experts (MoE) architecture, which means it has 105 billion total parameters but only activates approximately 10.3 billion parameters per token during inference. That's the efficiency play that makes this model viable at scale.
Think of it like a hospital with 100 specialists. You don't consult all 100 doctors for a headache - you route to the right expert. MoE works the same way. For each task, the model dynamically routes to the most relevant subset of its network.
This matters for cost. A full 105B dense model would require enormous GPU infrastructure for every inference call. Because only ~10% of parameters activate per token, Sarvam-105B can serve far more requests at lower compute cost compared to a traditional model of the same parameter count.
Key Technical Specifications
- 105B total parameters, ~10.3B active per token (MoE architecture)
- 128K token context window - handles long documents and multi-turn research sessions
- MLA-style attention stack with decoupled QK head dimensions (q_head_dim=192 split into RoPE and noPE components)
- v_head_dim=128, head_dim=576 - enabling high representational bandwidth per attention head
- Hidden size: 4096
- Sigmoid-based routing scores for expert gating (instead of traditional softmax - reduces routing collapse during training)
- Trained on 12 trillion tokens across code, web data, math, and multilingual corpora
- Pre-training in three phases: long-horizon pre-training, mid-training, and long-context extension
The 128K context window is one feature I keep coming back to. Most Indian enterprise use cases - legal document review, government policy analysis, multilingual customer support logs - involve long documents. GPT-4 in its early forms capped at 8K tokens. Sarvam-105B handles 16x that natively.
Sarvam-105B Benchmark Results (Real Numbers)
Sarvam-105B consistently matches or surpasses several closed-source frontier models and stays within a narrow margin of the largest global systems on diverse reasoning and agentic benchmarks. Here are the published numbers:
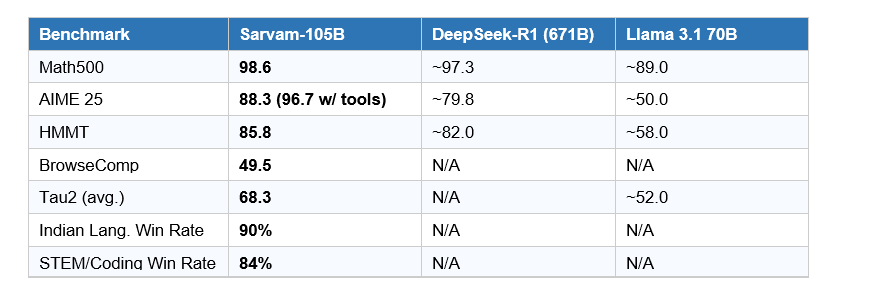
The Math500 score of 98.6 is genuinely impressive for any model, let alone a 105B parameter system. The AIME 25 score reaching 96.7 with tool use puts it ahead of most open models in its class.
The BrowseComp score of 49.5 and Tau2 average of 68.3 - both highest among compared models - signal strong agentic capability. These aren't just Q&A benchmarks. Tau2 measures the model's ability to complete real-world multi-step workflows, which is increasingly how enterprise customers actually use LLMs.
Contrarian point worth making: benchmark scores are not the same as real-world performance. The Hacker News thread on this release includes reports of hallucination issues and a knowledge cutoff of June 2025 - meaning the model has no awareness of events in the second half of 2025 or 2026. For live business intelligence use cases, that's a limitation worth flagging.
Indian Language Performance: The 90% Win Rate Explained
Sarvam-105B wins 90% of pairwise comparisons across Indian language benchmarks and 84% on STEM, math, and coding tasks - making it the highest-performing open model for Indian languages at its parameter class as of March 2026.
The benchmark Sarvam designed for this evaluation is worth understanding. It covers 22 official Indian languages, evaluates both native script (formal written usage) and romanized script (Hinglish and colloquial text messaging style), and spans four domains: general chat, STEM, mathematics, and coding. The source prompts were 110 English questions translated into all 22 languages.
Why this matters: most Indian users don't type in pure Hindi or pure Tamil. They code-switch. A customer service message might start in English, switch to Hinglish halfway through, and include a technical term in Telugu script. GPT-4o and Llama 70B consistently stumble on these mixed inputs. Sarvam-105B was explicitly trained on native script, romanized, and code-mixed inputs for the 10 most-spoken Indian languages.
India has 1.4 billion people and 22 official languages. Less than 12% of the population communicates primarily in English. The implication is straightforward: most of the next billion AI users will need a model that understands them - not just translates for them.
I find the 90% win rate credible for the 22-language scope, but I'd want independent third-party evals before deploying this in a production system. Sarvam designed and ran their own benchmark, which is fine as a starting point - it's not fine as the only data point you rely on.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Sarvam-105B vs Sarvam-30B vs Sarvam-M: Which Model Do You Need?
Three models, three very different use profiles. Here's the breakdown:
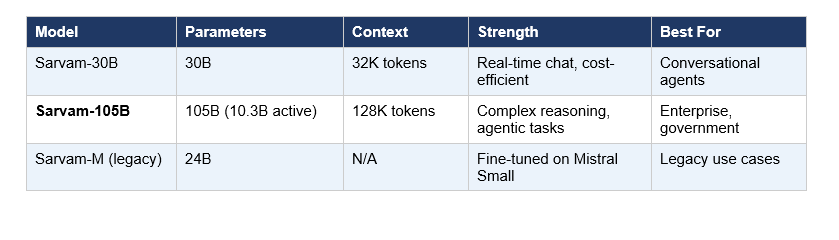
Sarvam-30B is the one I'd actually recommend for most Indian startups right now. The 32K context window handles most real-world conversational use cases, and the lower GPU requirements make it deployable on more accessible infrastructure. It was also trained on 16 trillion tokens - more than the 105B model - which Sarvam says optimizes it for conversational quality and latency.
Sarvam-105B is for complex, multi-step, document-heavy, or agentic workflows - the tasks where you need 128K context and the highest possible reasoning quality. Government deployments, legal document analysis, complex enterprise automation. If you're building a basic chatbot, 105B is overkill.
Sarvam-M (24B) is effectively the legacy option. It was a meaningful milestone when it launched in May 2025 - the first model to demonstrate that a lean Indian team could compete on reasoning benchmarks - but the criticism about its Mistral Small foundation was fair. Both 30B and 105B supersede it.
How to Download and Use Sarvam-105B
The model is fully open-source and accessible through multiple channels. Here's exactly where to go:
- Hugging Face: sarvamai/sarvam-105b - model weights, documentation, and vLLM inference examples
- AI Kosh: Government-backed AI repository with direct download links for both 30B and 105B
- Sarvam API: Cloud inference via the Sarvam API dashboard - no self-hosting required for testing
- Indus App: Consumer-facing chat interface where you can try the model immediately
Minimum Hardware Requirements for Self-Hosting
Because of the MoE architecture, inference is more efficient than a dense 105B model, but self-hosting still requires serious hardware. The Hugging Face page uses tensor_parallel_size=8, which implies a minimum of 8 GPUs for efficient inference. Sarvam recommends high-end GPUs or distributed inference setups. For most Indian startups and individual developers, API access is the practical path.
Quick start with vLLM (from the Hugging Face page): load using AutoTokenizer and LLM from the vllm library, set tensor_parallel_size to match your GPU count, apply the chat template with enable_thinking=True for reasoning mode, and generate with standard SamplingParams. The documentation is solid - this is not a model you'll spend three days trying to get running.
Real-World Use Cases: Where Sarvam-105B Actually Shines
Benchmark numbers are one thing. Here's where Sarvam-105B has a genuine, practical advantage over global alternatives:
1. Government Services and Citizen Connect
India's government serves 1.4 billion people across 22 official languages. The IndiaAI Mission's flagship use cases - 2047: Citizen Connect and AI4Pragati - are specifically designed to deliver public services through conversational AI in regional languages. A citizen in rural Tamil Nadu asking about MNREGA eligibility in Tamil, or a farmer in Gujarat checking crop insurance details in Gujarati, needs a model that actually understands their language without forcing them into English.
Sarvam-105B's 128K context window and 22-language coverage make it structurally suited for document-heavy government deployments in a way that Llama 70B or GPT-4o - despite their overall capability - simply aren't optimized for.
2. Enterprise Multilingual Customer Support
India's top consumer companies - telecom, banking, e-commerce - serve hundreds of millions of customers across linguistic divides. Current solutions rely on a patchwork of rule-based systems, English-first chatbots, and human agents for regional language escalations. A model that handles Hindi, Tamil, Kannada, Bengali, and Hinglish in a single deployment changes that calculus entirely.
The 90% Indian language win rate and explicit training on code-mixed inputs directly addresses this use case. A customer typing 'mera account block ho gaya hai' (my account has been blocked) in romanized Hindi gets handled natively - no translation layer, no context loss.
3. Education Technology
India has 250 million school students, and the majority of them study in regional medium schools. An AI tutor that explains calculus in Marathi or answers science questions in Odia has a fundamentally different impact than an English-only assistant. Sarvam-105B's strong STEM benchmark scores (84% win rate on STEM, math, and coding in Indian languages) make it genuinely applicable for this use case.
4. Legal and Document Intelligence
India's courts process millions of documents annually in multiple languages, often with mixed-script formats. The 128K context window allows the model to ingest entire legal documents, contracts, and policy briefs in a single inference call -something the Sarvam Vision model (their 3B document intelligence model) can then complement with visual understanding of scanned PDFs.
The Honest Verdict: Strengths, Gaps, and What's Next
I want to be clear about what Sarvam-105B is and isn't, because the hype on both sides of this conversation is unhelpful.
What Sarvam-105B Gets Right
- First Indian LLM trained from scratch at frontier scale - the sovereign AI argument is now legitimate
- Best-in-class Indian language performance across 22 languages, including code-mixed formats
- MoE architecture delivers 105B-level capability at ~10B active parameter efficiency
- Apache 2.0 license removes the commercial deployment friction that kills most enterprise pilots
- 128K context window is practically essential for Indian enterprise and government use cases
What It Doesn't Yet Do
- Does not match the scale of GPT-4o, Claude Opus, or Gemini Ultra - Sarvam themselves acknowledge this gap
- Knowledge cutoff of June 2025 means the model has no awareness of recent events without RAG implementation
- Self-hosting requires 8+ high-end GPUs - not accessible for most Indian developers without cloud support
- Early community reports note hallucination tendencies that need further post-training work
- Model lineup (30B, 105B) still lacks a sub-7B variant for edge and mobile deployment
My honest view: Sarvam-105B is a real technical achievement that deserves serious recognition. It is India's most credible foundational LLM as of 2026. It is not yet a replacement for frontier global models in general-purpose tasks. It is a genuinely superior choice for Indian language use cases, government deployments, and organizations that need open-source flexibility without foreign model dependencies.
The fact that Sarvam pulled this off on $50 million - compared to the billions OpenAI and Anthropic have raised - is the part that should make Silicon Valley take notice. Not because the model is bigger, but because it proves frugal engineering with sovereign intent can produce competitive results at scale.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
FAQ: Sarvam-105B - Questions People Actually Ask
What is Sarvam-105B?
Sarvam-105B is a 105-billion-parameter open-source large language model developed by Sarvam AI, an Indian startup based in Bengaluru. Released in February 2026, it was trained from scratch under the IndiaAI Mission and supports all 22 official Indian languages. It is available under the Apache 2.0 license on Hugging Face (sarvamai/sarvam-105b) and AI Kosh.
How does Sarvam-105B perform on benchmarks compared to other models?
Sarvam-105B scores 98.6 on Math500, 88.3 on AIME 25 (96.7 with tools), and 85.8 on HMMT. It wins 90% of pairwise comparisons in Indian language benchmarks and 84% in STEM, math, and coding tasks. On certain agentic benchmarks, it outperforms DeepSeek-R1, which has 671 billion parameters - a model more than six times larger.
What makes Sarvam-105B different from previous Indian AI models like Sarvam-M?
Sarvam-M, released in May 2025, was fine-tuned from Mistral Small - a French model - with Indian language datasets. Sarvam-105B was trained entirely from scratch on 12 trillion tokens, making it India's first sovereign foundational LLM at this scale. The distinction matters for strategic and regulatory deployments where dependency on foreign model architectures is a concern.
Can I download and use Sarvam-105B for free?
Yes. Sarvam-105B is released under the Apache 2.0 open-source license, allowing free download, commercial deployment, and modification. Weights are available on Hugging Face (sarvamai/sarvam-105b) and AI Kosh. Sarvam also provides cloud API access through their API dashboard for teams who prefer not to self-host.
What hardware do I need to run Sarvam-105B locally?
Self-hosting Sarvam-105B requires significant GPU infrastructure - the official documentation recommends tensor_parallel_size=8, indicating a minimum of 8 high-end GPUs for efficient inference. Because of its Mixture-of-Experts architecture, only approximately 10.3 billion parameters are active per token, reducing compute requirements compared to a dense 105B model. For most developers, the Sarvam API or Indus app are the practical access points.
How many Indian languages does Sarvam-105B support?
Sarvam-105B supports all 22 scheduled Indian languages. It was trained on native script, romanized Latin script, and code-mixed inputs (like Hinglish) for the 10 most-spoken Indian languages, making it one of the few models to handle colloquial multilingual usage rather than just formal script translations.
Is Sarvam-105B better than GPT-4o for Indian language tasks?
For Indian language tasks specifically, Sarvam-105B outperforms GPT-4o, Gemini 3, and Llama 70B in head-to-head comparisons according to Sarvam's benchmarks, winning 90% of pairwise comparisons. For general-purpose global tasks or tasks requiring up-to-date knowledge beyond June 2025, frontier models like GPT-4o and Claude remain significantly more capable due to scale, training data recency, and tooling maturity.
What is the Sarvam-105B context window?
Sarvam-105B supports a 128,000-token context window. This makes it suitable for processing long documents, extended multi-turn conversations, and complex agentic workflows in a single inference session. The companion Sarvam-30B model has a 32,000-token context window, optimized for lower-latency conversational applications.
Related articles
https://www.buildfastwithai.com/blogs/build-websites-with-ai-in-10-minutes
https://www.buildfastwithai.com/blogs/vibe-coding-google-ai-studio-build-ai-apps-minutes
https://www.buildfastwithai.com/blogs/top-11-ai-powered-developer-tools
https://www.buildfastwithai.com/blogs/how-to-make-your-own-ai-software-engineer-like-devin
References
- Sarvam AI Official Blog - Open-Sourcing Sarvam 30B and 105B (sarvam.ai)
- Hugging Face Model Card - sarvamai/sarvam-105b (huggingface.co)
- Business Standard Coverage - Sarvam Launches India's First Sovereign LLMs (business-standard.com)

