




Are you waiting for the future to happen or ready to make it happen?
Don’t miss your chance to join Gen AI Launch Pad 2025 and shape what’s next.
The idea of an "AI software engineer" isn't a very far off concept.
There have already been pieces of tech that have been making software engineering incrementally easier.
- Devin, marketed as the world's first AI software engineer, came out last year.
- Cursor, an alternative to VS Code has been growing in popularity for getting easy access to AI while working on projects.
- LLMs like Claude and GPT-4 that can help you write code and fix bugs in code files.
Things will only keep getting easier as more and more humans research on LLM reasoning.
AI software engineer v/s regular LLM
What's the difference between a regular LLM and an AI software engineer? LLMs can write code too, can't they?
In that case, we need to define the terms a bit more precisely:
An AI software engineer is an AI assistant that can look at multiple code files in a git repository, and can determine which files to change depending on the exact task the assistant is trying to carry out.
For example, suppose you have a repository where you're working on an AI project, and you need to fix some bug where the AI assistant is not loading properly whenever the user selects the Mistral model.
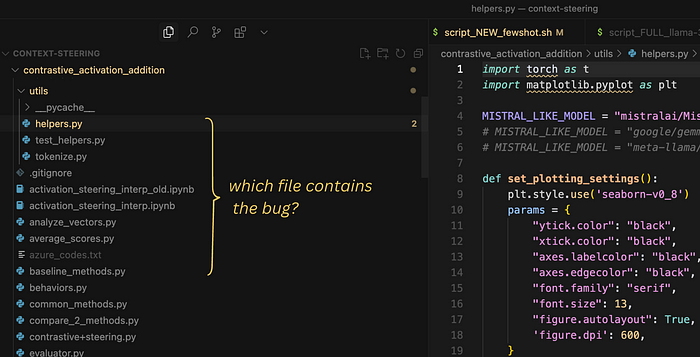
As a software engineer, you need to find the file containing the bug AND fix it. (Image by author)
As a software engineer, you would need to first find out which code file to change to fix the bug. For example, you could check in the file where the model is loaded if the issue can be figured out there. If there is some variable or function involved in the corresponding code that's imported from another file, you would go through those files too as potential sources of the bug.
A regular LLM couldn't solve this issue, since we can't provide all the files into the LLM whenever we're asking a question. We'd probably have to find the file ourselves before passing it into the LLM asking it to fix the bug.
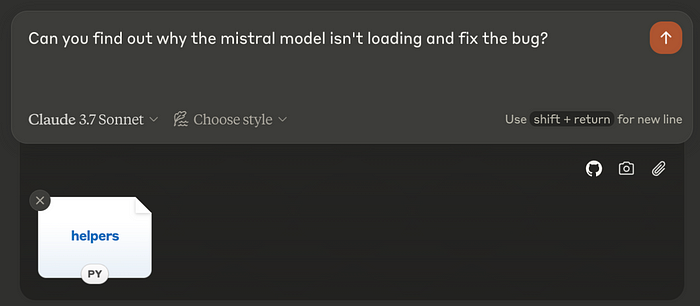
So how do we define an AI software engineer?
An AI software engineer, just like a regular software engineer, executes incremental PRs (pull requests) to fix some aspect of the code. For instance, if we want to create an AI assistant with improved reasoning ability, the first PR might involve setting up the AI assistant, the second might involve setting up the training workflow, and so on.
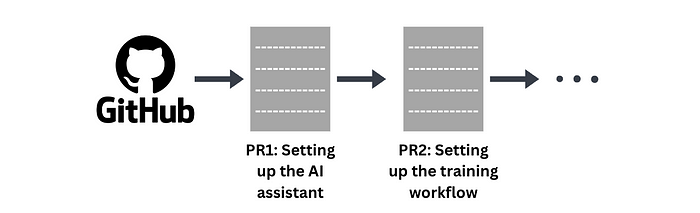
Each PR is a commit that expands the code base.
An AI assistant would need to write code for these PRs sequentially, either on its own or prompted by the user.
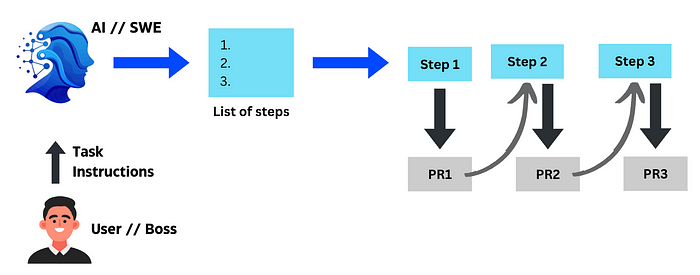
What the AI software engineer might do to execute some task provided by the user/boss.
How do you create an AI software engineer (SWE)?
With the recent DeepSeek model, you might be curious as to whether LLMs could use Reinforcement Learning (RL) to learn to be better software engineers. I wrote a blog recently about how versatile the RL training technique is, which you should check out if you haven't already.
RL is super versatile because LLMs develop the ability to solve a problem on their own without having to explicitly teach them.
Can we do the same for the software engineering task?
Let's first define the task.
Our goal is to get our AI assistant to automatically make the required changes in a repository given the current state of the repository and the task to be completed, just like a software engineer would.
How to train an AI to become a SWE?
To get an AI to do the same thing, we'll use the same RL training pipeline that DeepSeek used to improve reasoning.
RL is a super generalisable technique. This means that applying it in one context (to improve reasoning) can allow it to work better in other contexts too. That means whatever DeepSeek did to improve reasoning probably improves its performance on our task as well.
But can we make it even better by explicitly using software engineering examples to teach it?
To carry this out, we first need to collect some data to train the LLM.
Collecting the data
To train the LLM, we need to collect data that can teach it what changes to make, given:
- the current state of the code, and
- the function that needs to be changed.
Where can we get this information?
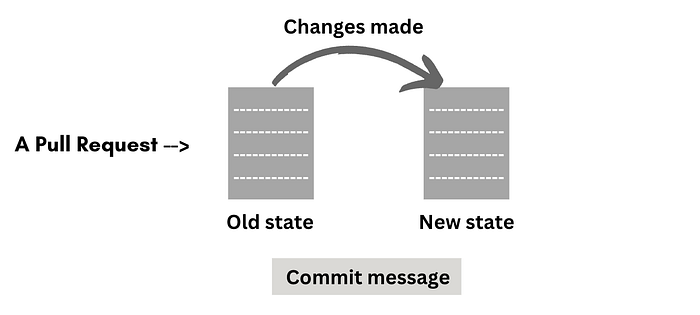
Git PRs.
A Git PR (Pull Request) is basically a proposal to merge a set of changes from one branch to another. When you're working on a project using GitHub, you would usually make changes to the repository, and then commit those changes with a commit message that describes the task you completed. You would then pull the current state of the repository and merge your changes with the repository.
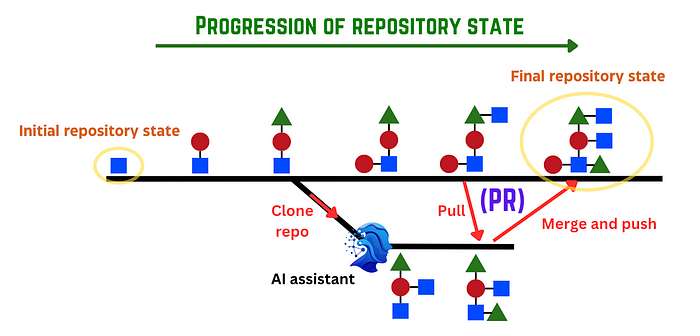
Thus, a pull request has all the information we need — previous state of the repository, the task to be completed, and the changes made to complete that task.
Thus, if we collect the millions of pull requests on public repositories, we should have a decent bit of information to start teaching the LLM how to change the code given the task to be completed and the old state of the code.
Prompting the LLM
Now that we have a dataset, we need to figure out how to prompt the LLM during the training process, or during inference.
We want to provide the old state of the code and the task to be completed from the dataset, expecting it to output the changes to be made.
But the entire code can't be uploaded, so we might decide to only provide two types of files:
- The files that changed between before and after the commit
- Other relevant files that didn't change
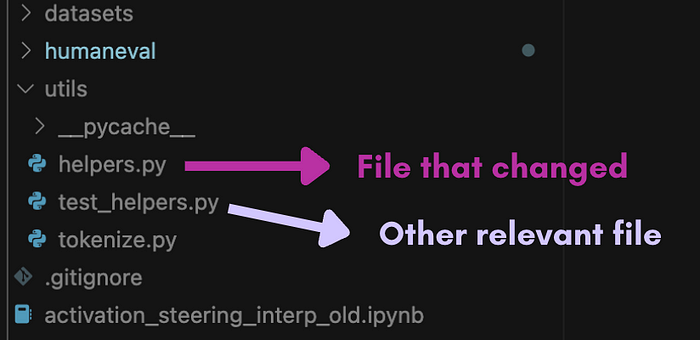
We can use an LLM to determine the relevant files that didn't change based on the file names. The idea is that the LLM should not only know which files to change but also the files it shouldn't change, so incorporating this into the training process is essential to help it learn.
Defining the Reward
Coming to the exact RL process, how do we define the reward to provide incentives to the LLM to learn?
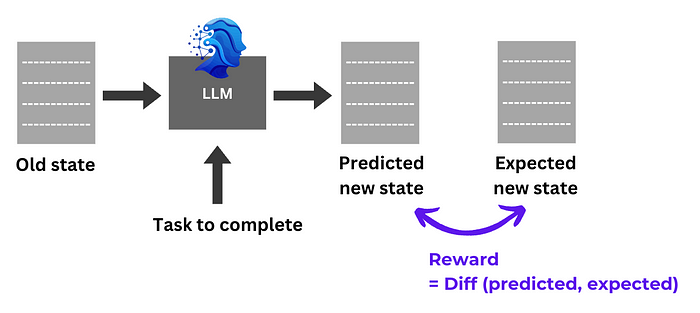
We're going to define the reward in a simple way: quantify the difference between the output code of the LLM and the actual new state of the file in the PR. The more similar they are, the higher the reward.
The training process
The overall process is simple: pass each data point into the LLM, extract the output, compare the output against the expected output code, and provide a reward based on the sequence similarity. The LLM alters its policy to optimise the overall reward.
How can we improve this further?
Curriculum learning
It's been shown that increasing the difficulty of problems as the RL training loop progresses helps the LLM learn more effectively, just as it would help a student learn more effectively.
Since currently, we took PRs in a random order from public repositories on GitHub, we could order them based on the size of the commit, i.e., the number of changes made within the commit, with the assumption that commits involving fewer changes are easier to reason than others.
Alternately, we could think of another metric to judge the difficulty of reasoning within each PR and order the data points in increasing difficulty.
Cleaner dataset and reward function
The cleanliness of the dataset is one of the major bottlenecks when it comes to improving LLM performance at the end of the RL training process. DeepSeek and other researchers have shown this extensively.
- The dataset: One of the major problems with this approach is that the cleanliness of the data itself isn't guaranteed. We'd ideally want all our PRs to represent "good software engineering skills", which obviously isn't possible if we're taking all PRs from public repositories on the internet.
- The reward function: What if there are multiple ways of solving a specific problem? If the LLM's approach doesn't match the approach followed by the code, the LLM gets a negative reward even if its approach is actually better than the approach followed in the repository. This is a bad signal and isn't guiding the LLM properly.
Conclusion
The idea of an AI software engineer isn't that far away. And it will probably soon be open-sourced and therefore highly accessible to software developers across the world.
We went over one possible approach to build an AI software engineer. The process itself could be made more efficient through various ways. Training LLMs with RL is still a nascent field, with so many low-hanging fruits and a lot of potential for research. I'm personally getting into this field this year, and if any of you are interested, I'd recommend exploring it too.
References
- Anthropic. (2024). Claude: A next-generation AI assistant.
- OpenAI. (2023). GPT-4 Technical Report.
- DeepSeek. (2024). DeepSeek
- The Cursor Team. (2023)
- Cognition Labs. (2024). Devin.
- GitHub. (2024). GitHub Copilot.
---------------------------
Stay Updated:- Follow Build Fast with AI pages for all the latest AI updates and resources.
Experts predict 2025 will be the defining year for Gen AI Implementation. Want to be ahead of the curve?
Join Build Fast with AI’s Gen AI Launch Pad 2025 - your accelerated path to mastering AI tools and building revolutionary applications.
---------------------------
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Resources and Community
Join our community of 12,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, our resources will help you understand and implement Generative AI in your projects.
- Website: www.buildfastwithai.com
- LinkedIn: linkedin.com/company/build-fast-with-ai/
- Instagram: instagram.com/buildfastwithai/
- Twitter: x.com/satvikps
- Telegram: t.me/BuildFastWithAI

