



The best time to start with AI was yesterday. The second best time? Right after reading this post.
Join Build Fast with AI’s Gen AI Launch Pad 2025—a 6-week transformation program designed to accelerate your AI mastery and empower you to build revolutionary applications.
1- What is a transformer?
The Transformer model has revolutionized Natural Language Processing (NLP) with its innovative design, built around three core components: Self-Attention, Positional Encoding, and Feed-Forward Neural Networks. These groundbreaking ideas were first introduced in 2017 in the now-famous paper “Attention is All You Need” by Vaswani et al. Since then, Transformers have become a cornerstone of deep learning, powering tasks like machine translation, text generation, sentiment analysis, and more. Their versatility and efficiency continue to shape the future of AI.

2 — How does the transformer work?
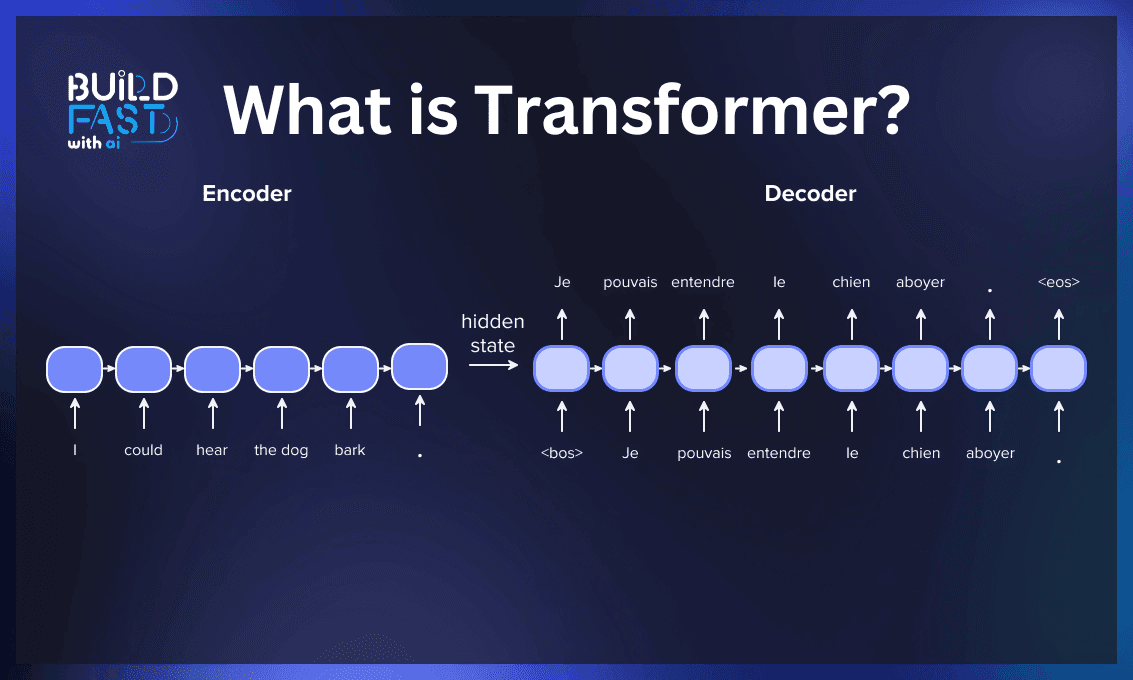
Transformers are made up of two main components: an encoder and a decoder, both of which utilize self-attention mechanisms and feed-forward neural networks. Imagine translating the English sentence "I love flowers" into Vietnamese. The encoder takes in the English sentence, processes it, and passes the information to the decoder, which generates the output: "Tôi yêu thích những bông hoa." Every layer within the encoder and decoder is equipped with self-attention mechanisms and feed-forward neural networks to carry out this process effectively.
Input Embedding:
The first stage involves processing English sentences as input data. Unlike word-for-word translation, converting English to Vietnamese isn’t straightforward due to differences in grammar, word order, and word count. This is where Tokenization and Embedding come into play.
Tokenization breaks the text into smaller units called tokens, which can be either words or subwords, depending on the specific use case. Embedding, on the other hand, transforms each token into a dense vector representation using an embedding layer.
Think of embeddings as a “vector world” where similar words cluster closely together, reflecting their related meanings. Meanwhile, words with different meanings are positioned far apart. While embeddings may seem complex at first, they provide a powerful way to capture relationships between words.
Positional Encoding:
Positional encoding plays a critical role in the transformer architecture by embedding information about a token’s position within a sequence. Without it, the model could lose vital context, leading to potential misunderstandings. Positional encoding works by adding a unique positional vector to each token’s embedding, allowing the model to understand both the meaning of the token and its position within the sequence.
For example, consider the sentence, “I love the movie so bad.” Without positional encoding, the model might misinterpret the context, associating “bad” with negativity and “love” with positivity, treating them separately. This could result in a jumbled output like, “So I love the bad movie.” Positional encoding ensures that the sequence’s structure and meaning remain intact, making it indispensable in the transformer architecture.
Encoder:
The encoder, shown on the left in Figure 1, is designed to process and comprehend the input sentence. Its primary goal is to create a meaningful representation of the input while capturing the relationships between its elements. This processed information is then passed to the decoder to generate the output.
The encoder consists of multiple identical layers, and each layer is made up of two key sub-layers: the Multi-Head Self-Attention mechanism and the Feed-Forward Neural Network. These sub-layers are applied sequentially within each encoder layer, ensuring an effective transformation of the input data into a form the decoder can utilize.
Self-attention operates by calculating the relationships between elements in a sequence through the Query (Q), Key (K), and Value (V) matrices. The process begins by multiplying these matrices and applying a softmax function to generate attention weights. These weights determine the importance of each element relative to the others. Finally, the attention weights are used to compute a weighted sum of the value vectors, producing the output of the self-attention mechanism.
A straightforward example makes the concept of self-attention easier to grasp. Consider the sentence: “I love the fat cats; they will never mess up my house because they never want to run.” Here, the word “they” refers to “cats.” Self-attention enables the model to make this connection, linking “they” back to its proper context—the subject of the previous clause, “cats.”
For a computer, identifying such relationships isn’t a simple task. Self-attention provides the mechanism to capture and understand these dependencies, even across different parts of the sentence, ensuring the correct interpretation of the text.
Multi-Head Attention is essentially a collection of self-attention mechanisms working in parallel. Think of it as having multiple perspectives on the same text, where each "head" focuses on a specific detail. For instance, one head might track who is performing an action, another might identify what the action is, and yet another might consider the context of when or where it happens.
This is similar to applying different filters in a neural network layer to capture various aspects of an image. In Multi-Head Attention, the input information is divided among the heads, allowing each to process a smaller portion of the data. This approach makes handling large datasets more efficient. Once all heads complete their tasks, their outputs are combined and transformed into a unified representation. This transformation ensures the output is in a format that the next stage of the neural network can effectively use.
The next step is the Feed-Forward Neural Network, applied to the output of the self-attention mechanism. This network consists of two linear transformations with a ReLU activation function in between. The combination of these layers enables the model to learn and represent complex patterns and relationships within the data, enhancing its ability to process and understand intricate structures in the input.
Decoder
The decoder, shown on the right in Figure 1, is responsible for generating the output text sequence (in this case, the Vietnamese sentence). It combines Masked Multi-Attention, Multi-Head Attention, and Feed-Forward components. While we've already discussed Multi-Head Attention and Feed-Forward, these components in the decoder function similarly to those in the encoder. However, their role in the decoder is to interpret the information passed from the encoder, align the input and output sequences, and generate accurate translations or responses.
For the example above, once the encoder has processed the English sentence, the decoder's task is to generate the corresponding Vietnamese sentence based on the encoded information.
Masked Multi-Head Attention allows the decoder to focus on different parts of the sequence, but with the added constraint of masking. This masking is the key difference in how attention scores are calculated in the decoder’s first multi-headed attention layer. The purpose of masking is to prevent the model from seeing future words in the sequence, ensuring it only attends to the words that have already been processed.
For example, in the sentence “Once upon a time, there was a…”, when processing the word “time”, the model can only "see" the part of the sentence up to “Once upon a time”. It cannot access the upcoming words, like “there was a”, and instead focuses solely on the word “time”. This ensures the model generates text one word at a time, building upon what’s already been written.
Without masking, the model would have access to the entire sentence at once, leading to inaccurate predictions, poor generalization, and issues with word order. Masking ensures that the decoder’s predictions are grounded in the context of previously generated words, maintaining the logical flow of the output.
Summary
The Transformer architecture has proven to be incredibly valuable for Natural Language Processing (NLP). By combining self-attention mechanisms, Positional Encoding, and Feed-Forward neural networks, Transformers provide a powerful framework for a wide range of tasks, including machine translation, text summarization, sentiment analysis, question answering, and more.
This architecture has significantly advanced the capabilities of NLP models, elevating them to new levels of performance. As a result, Transformers are now fundamental tools in developing diverse applications that rely on understanding and generating human language. Their flexibility and efficiency continue to push the boundaries of what’s possible in the field of NLP.
Resources Section
- Transformer: A Novel Neural Network Architecture for Language Understanding
- Generative AI for Excel?
- Web Scraping with AI
- How to Fine-Tune LLM?
---------------------------
Stay Updated:- Follow Build Fast with AI pages for all the latest AI updates and resources.
Experts predict 2025 will be the defining year for Gen AI implementation.Want to be ahead of the curve?
Join Build Fast with AI’s Gen AI Launch Pad 2025 - your accelerated path to mastering AI tools and building revolutionary applications.
---------------------------
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Resources and Community
Join our community of 12,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, this tutorial will help you understand and implement AI agents in your projects.
- Website: www.buildfastwithai.com
- LinkedIn: linkedin.com/company/build-fast-with-ai/
- Instagram: instagram.com/buildfastwithai/
- Twitter: x.com/satvikps
- Telegram: t.me/BuildFastWithAI

