





Qwen3.6-27B Review: The 27B Model That Just Outperformed a 397B on Coding Benchmarks
55.6 gigabytes beat 807 gigabytes. A 27-billion-parameter model outperformed a 397-billion-parameter model on agentic coding benchmarks. And it runs locally on an 18GB GPU.
That is Qwen3.6-27B, released by Alibaba on April 22, 2026 under the Apache 2.0 license. No commercial restrictions. Full weights on Hugging Face. Free to download, modify, and deploy.
I have been watching the Qwen3.6 family roll out since the Plus Preview dropped in late March, and each release has pushed further than I expected. But this one is genuinely different. Not because of the benchmark scores alone — it is the combination: a dense architecture that eliminates MoE routing complexity, a 262K-token context window extensible to 1 million tokens, native multimodal support, and a brand-new Thinking Preservation mechanism that nobody in the open-source world has shipped before.
The size-to-performance ratio here changes the economics of running your own coding agent. Let me show you exactly what that means.
What Is Qwen3.6-27B? (And Why Dense Matters)
Qwen3.6-27B is Alibaba's first dense open-weight model in the Qwen3.6 family — a 27-billion-parameter multimodal language model built for agentic coding, repository-level reasoning, and frontend development workflows. It was released on April 22, 2026 on Hugging Face and ModelScope under the Apache 2.0 license.
The 'dense' distinction matters more than it sounds. Most large open-source models in 2026 use Mixture-of-Experts (MoE) architectures — they activate only a fraction of their total parameters per inference pass. The 397B model Qwen3.6-27B just outperformed (Qwen3.5-397B-A17B) only activates 17B parameters per token despite its enormous total size. MoE is efficient at scale but introduces routing complexity and makes local deployment extremely hardware-hungry.
Qwen3.6-27B is fully dense: all 27 billion parameters are active on every inference pass. This sounds less efficient, but it has real advantages. Simpler deployment — no expert routing to configure. Better quantization behavior — dense models compress more predictably than MoE models. Easier integration with inference stacks like llama.cpp, SGLang, and vLLM. And in practice, the Gated DeltaNet hybrid architecture (combining linear attention with traditional self-attention) lets this dense 27B model punch well above its weight.
The model also supports text, image, and video natively through an integrated vision encoder — this is not a bolt-on adapter. A 262,144-token context window is the default, extendable to 1,010,000 tokens via YaRN scaling for users who need to process entire codebases in one pass.
If you want to see where Qwen3.6-27B sits within the full Qwen3.6 family — including the closed-source Qwen3.6-Max-Preview that claims the top spot across six coding benchmarks — our Qwen3.6-Max-Preview benchmarks and API review covers the proprietary top-tier model in detail.
Full Benchmark Breakdown
Qwen3.6-27B outperforms the 397B Qwen3.5-397B-A17B across every major coding benchmark Alibaba reported. Here is the full comparison, including relevant open-source competitors and the closest closed-source reference point:
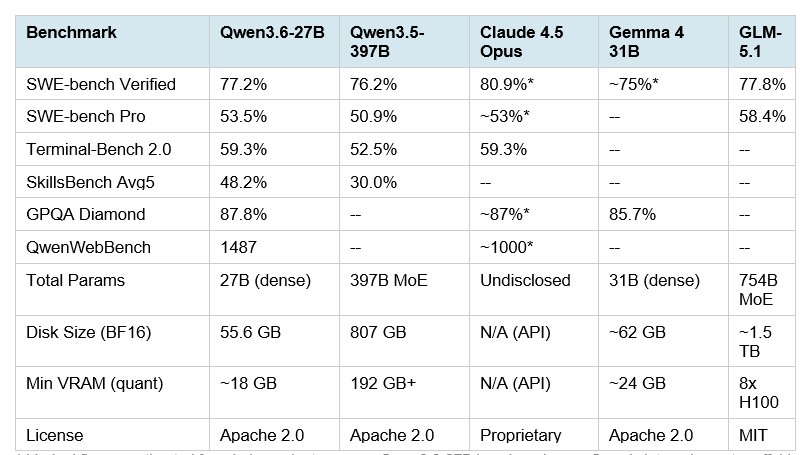
The numbers that demand attention: SWE-bench Verified at 77.2% puts Qwen3.6-27B within 3.7 points of Claude Opus 4.6 (80.8%) at a fraction of the hardware cost and zero API fees. SkillsBench at 48.2% versus the 397B model's 30.0% is the most striking result — a 77% relative improvement despite 14.8 times fewer parameters.
Terminal-Bench 2.0 at 59.3% matching Claude 4.5 Opus exactly is the stat driving the most community excitement. Terminal-Bench 2.0 runs a 3-hour timeout with 32 CPUs and 48GB RAM, measuring real autonomous terminal execution — not single-turn code generation. Matching a closed-source Anthropic flagship on that benchmark with a self-hostable model is a meaningful result.
My honest take: Qwen reports these benchmarks using their own internal agent scaffold (bash + file-edit tools). Independent third-party reproductions outside Qwen's scaffolding are limited as of April 23, 2026. The numbers are impressive, and early community tests from Simon Willison and others are positive — but treat the exact figures as directional until broader independent verification emerges. The GPQA Diamond score of 87.8% on scientific reasoning is externally verifiable and aligns with other sources.
For the full 2026 leaderboard context across 20+ models, our April 2026 AI model benchmark rankings covers where Qwen3.6-27B slots into the broader competitive picture.
Thinking Preservation: The Feature Nobody Is Talking About
Qwen3.6-27B introduces Thinking Preservation — and I think this is the most architecturally interesting part of this release, even though most coverage has focused on the benchmark numbers.
Here is the problem it solves. Standard reasoning models generate a chain-of-thought during each response, but discard that reasoning trace before the next turn. The next message starts from scratch — the model has to re-derive context it has already worked through. This is wasteful in multi-turn agent workflows where the model is iteratively developing the same codebase across dozens of turns.
Thinking Preservation allows Qwen3.6-27B to optionally retain its full reasoning traces across conversation history. The model can reference and build on earlier thinking blocks rather than re-reasoning from the same base context. The practical effects are reduced redundant token generation, improved KV cache utilization, and more consistent decision-making across long agent sessions.
Enable it via the API parameter preserve_thinking: True in your chat template kwargs. The Hugging Face model card includes working code examples for both OpenAI-compatible endpoints and Alibaba Cloud Model Studio.
Qwen recommends maintaining at least 128K tokens of context to preserve the model's thinking capabilities. Reducing below that threshold can degrade the reasoning coherence that makes Thinking Preservation valuable in the first place.
I expect this feature to become a standard expectation in agentic coding models within 6 months. Qwen3.6 ships it first in the open-source space.
How to Run Qwen3.6-27B Locally
The headline local stat: a Q4_K_M GGUF of Qwen3.6-27B weighs 16.8GB and runs on approximately 18GB of total RAM or VRAM. That puts it within reach of a single RTX 4090 (24GB), a Mac with 24GB unified memory, or any system with 18GB+ of combined RAM and VRAM using CPU offloading.
Important warning: do NOT use CUDA 13.2. Unsloth's documentation flags that outputs may be gibberish on this driver version. NVIDIA is working on a fix. Use an earlier CUDA version until resolved.
Also note: Qwen3.6 GGUFs currently do NOT work in Ollama due to separate mmproj vision files. Use llama.cpp or Unsloth Studio instead.
Quantization Options and Hardware Requirements
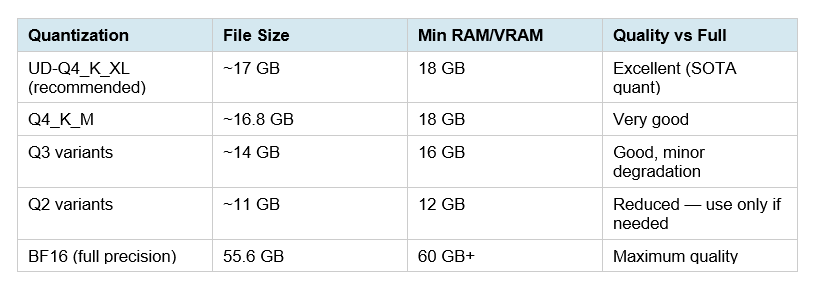
Unsloth's UD-Q4_K_XL is the recommended starting point — their Dynamic 2.0 quantization is calibrated on real-world datasets and upscales important layers, giving you close-to-full-precision results at Q4 file sizes.
Method 1: llama.cpp (Recommended for Most Developers)
This is the fastest path if you have an NVIDIA GPU or Apple Silicon:
Install llama.cpp: brew install llama.cpp (Mac) or build from source on Linux
Download GGUF: Pull unsloth/Qwen3.6-27B-GGUF:UD-Q4_K_XL from Hugging Face
Run the server: llama-server -hf unsloth/Qwen3.6-27B-GGUF:UD-Q4_K_XL --temp 0.6 --top-p 0.95 --top-k 20 --presence_penalty=1.5 --min-p 0.00
Enable Thinking Preservation: Add --chat-template-kwargs '{"preserve_thinking": true}' to retain reasoning traces across turns
The server exposes an OpenAI-compatible endpoint at localhost:8080, which you can point Claude Code, OpenCode, or any other tool at directly.
Method 2: Unsloth Studio (Easiest for Beginners)
Unsloth Studio is a browser-based local AI interface that handles model download, configuration, and serving automatically. It supports Qwen3.6-27B with day-zero GGUFs and developer role support for agentic coding tools like OpenCode and Codex. Install via their one-line script, open localhost:8888, search for Qwen3.6-27B, and select your quant. No terminal configuration required.
Method 3: SGLang or vLLM (Production Serving)
For production workloads or multi-user deployments, SGLang (version 0.5.10+) and vLLM both support Qwen3.6-27B with full tool-calling and reasoning parsing. These frameworks provide batched inference and much higher throughput than single-user llama.cpp setups.
For hands-on code patterns that apply directly to Qwen3.6's OpenAI-compatible endpoint, the Qwen 3.6 Plus API cookbook covers the same integration patterns — swap the model string for qwen3.6-27b and the local base URL.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
API Access: Qwen Studio, Alibaba Cloud, and OpenRouter
If you want to test Qwen3.6-27B without any local setup, three API routes exist today:
Qwen Studio (chat.qwen.ai): Direct access at chat.qwen.ai/?models=qwen3.6-27b. Free to use via the web interface. Best for initial testing and prompt evaluation before committing to local deployment.
Alibaba Cloud Model Studio: Production API access via DashScope at dashscope.aliyuncs.com. OpenAI-compatible endpoint. Use model string qwen3.6-27b. Standard API billing applies. Supports Thinking Preservation via extra_body parameters in the API call.
OpenRouter: Available on OpenRouter for developers already using it for multi-model routing. Pricing aggregated — check current rates at openrouter.ai.
The API uses an OpenAI-compatible format, so any tool already talking to OpenAI can point at Qwen3.6-27B with a base URL change and a model name swap. For Claude Code users: set ANTHROPIC_BASE_URL to Alibaba's endpoint and ANTHROPIC_AUTH_TOKEN to your DashScope API key.
Who Should Use Qwen3.6-27B (And Who Should Not)
Qwen3.6-27B is the right call if you are:
Running AI coding agents locally and have 18–24GB of VRAM or RAM — this is the most capable model in that hardware tier as of April 2026
Building on sensitive or proprietary code where sending data to cloud APIs is not acceptable — Apache 2.0, full weights, deploy on your own infrastructure
Doing frontend development or repository-level code work where the QwenWebBench and NL2Repo scores matter
Using agentic frameworks like OpenCode, Claude Code (via local routing), or OpenClaw and want a local backbone that supports 1,000+ tool call sequences
Running multi-turn agent workflows where Thinking Preservation reduces token overhead and improves decision consistency across turns
Stick with a different model if:
You need the absolute best SWE-bench Verified scores — Claude Opus 4.6 (80.8%) and Claude Opus 4.7 (84.3%) still lead meaningfully on that benchmark
You want open-source but need the strongest SWE-bench Pro scores in April 2026 — GLM-5.1 leads at 58.4% versus Qwen3.6-27B's 53.5%
Speed is your top priority over quality — the Qwen3.6-35B-A3B (MoE, 3B active) is faster at inference on the same hardware
You're in a regulated environment where Chinese-origin model provenance is a compliance consideration
For a direct comparison between Qwen3.6-Plus, GLM-5.1, and Kimi 2.5 on real coding tasks, our Chinese AI coding model comparison covers the full three-way test with benchmark tables and use-case breakdowns.
Qwen3.6-27B vs Gemma 4 31B vs GLM-5.1: Open-Source Showdown
Three open-source models are competing for the 'best local coding AI' title in April 2026. Here is how they actually differ:
Qwen3.6-27B vs Gemma 4 31B. Both are dense models in the 27–31B range, both Apache 2.0, both multimodal. Gemma 4 31B scores 89.2% on AIME 2026 math reasoning versus Qwen3.6-27B's implicitly lower math performance. Qwen3.6-27B leads on agentic coding benchmarks — SWE-bench Verified 77.2% versus Gemma 4's estimated 75% range. The practical hardware gap: Qwen3.6-27B needs 18GB minimum, Gemma 4 31B Dense needs 24GB+ for the 4-bit quant. For pure coding workflows, Qwen3.6-27B is the stronger pick. For math-heavy or reasoning tasks, Gemma 4 31B competes harder.
Qwen3.6-27B vs GLM-5.1. GLM-5.1 is a completely different class of local deployment. It is a 754B MoE model requiring a minimum of 8x H100 GPUs at full precision — this is enterprise infrastructure, not a developer workstation. GLM-5.1 leads on SWE-bench Pro (58.4% vs 53.5%) and has demonstrated long-horizon autonomous operation (1,700 autonomous steps versus Qwen3.6-27B's more typical agent session lengths). If you have the hardware, GLM-5.1 is the more capable coding agent. If you are running on a single GPU or workstation, Qwen3.6-27B is not just the practical choice — it is the only realistic one.
For a deeper look at GLM-5.1's architecture and what makes it the top open-source SWE-bench Pro leader, our GLM-5.1 full review covers the technical details and hands-on testing.
My overall read: Qwen3.6-27B occupies the most valuable slot in the 2026 open-source model landscape — the best performance you can get on commodity GPU hardware. GLM-5.1 is better on benchmarks but requires enterprise infrastructure. Gemma 4 31B is competitive but trails on coding-specific tasks. For the developer who wants to run a serious coding agent locally without renting a GPU cluster, Qwen3.6-27B is the model to start with right now.
For hands-on implementation, the Gemma 4 cookbook demonstrates the same local deployment patterns — useful for comparing Gemma 4 and Qwen3.6-27B inference setups side-by-side.
Frequently Asked Questions
What is Qwen3.6-27B?
Qwen3.6-27B is Alibaba's open-weight dense language model released on April 22, 2026, under the Apache 2.0 license. It has 27 billion parameters, supports text, image, and video inputs, carries a native 262,144-token context window extensible to 1,010,000 tokens, and is the first open-source model to introduce Thinking Preservation — a feature that retains chain-of-thought reasoning traces across multi-turn conversations.
How does Qwen3.6-27B compare to Claude Opus 4.6?
On SWE-bench Verified, Qwen3.6-27B scores 77.2% versus Claude Opus 4.6's 80.8% — a 3.6-point gap. On Terminal-Bench 2.0, Qwen3.6-27B scores 59.3%, matching Claude 4.5 Opus exactly. Claude Opus 4.6 still leads on instruction following nuance, safety reliability, and overall agentic benchmark leadership as of April 2026. The practical tradeoff: Claude Opus 4.6 costs $5/$25 per million input/output tokens via API with no local deployment option; Qwen3.6-27B is free to self-host with full weights under Apache 2.0.
Is Qwen3.6-27B really better than the 397B model?
On the benchmarks Alibaba reports, yes: Qwen3.6-27B scores 77.2% on SWE-bench Verified versus Qwen3.5-397B-A17B's 76.2%, 53.5% on SWE-bench Pro versus 50.9%, and 59.3% on Terminal-Bench 2.0 versus 52.5%. The key caveat: these benchmarks use Qwen's own internal agent scaffold. Independent third-party verification on production coding tasks is still limited as of April 23, 2026. The architectural explanation for the result is that Qwen3.6-27B's dense architecture and newer training improvements can outperform older, larger MoE models on specific task types.
How much VRAM does Qwen3.6-27B need?
The recommended Q4_K_M or UD-Q4_K_XL GGUF quantization runs on approximately 18GB of total memory (RAM + VRAM combined). A single NVIDIA RTX 4090 (24GB VRAM) is comfortable. A 24GB unified memory Mac runs it well. Systems with 18–24GB can run the Q4 variants; systems with 12–16GB can use Q2 or Q3 variants with some quality degradation. The full BF16 model requires 60GB+.
What is Thinking Preservation in Qwen3.6?
Thinking Preservation is a new feature in the Qwen3.6 family that allows the model to retain its chain-of-thought reasoning traces across multi-turn conversations, rather than discarding them after each response. In standard reasoning models, each new message starts fresh reasoning. With Thinking Preservation enabled via preserve_thinking: True in the API, the model can reference and build on earlier reasoning blocks, reducing redundant token generation and improving KV cache efficiency in long agentic workflows.
Is Qwen3.6-27B free to use commercially?
Yes. Qwen3.6-27B is released under the Apache 2.0 license, which permits free commercial use, modification, and distribution with minimal restrictions. You can integrate it into commercial products, fine-tune it, and deploy it on your own infrastructure without paying Alibaba. No royalties, no commercial license fees.
How to run Qwen3.6-27B locally?
Use llama.cpp or Unsloth Studio — Ollama currently does not support Qwen3.6 GGUFs due to separate mmproj vision files. Download the UD-Q4_K_XL GGUF from Hugging Face at unsloth/Qwen3.6-27B-GGUF. Run llama-server with --jinja flag enabled for tool calling and --chat-template-kwargs '{"preserve_thinking": true}' to enable Thinking Preservation. The server exposes a local OpenAI-compatible API at localhost:8080. Do NOT use CUDA 13.2 — a known bug produces gibberish outputs on this driver version.
What is the difference between dense and MoE AI models?
Dense models activate all their parameters for every inference pass. MoE (Mixture-of-Experts) models divide parameters into specialist groups called experts and activate only a fraction (typically 5–20%) per token. MoE is more parameter-efficient at scale — the Qwen3.5-397B-A17B only activates 17B parameters per token despite 397B total. Dense models like Qwen3.6-27B are simpler to deploy, quantize more predictably, and avoid routing overhead, but use more compute per parameter at equivalent total size.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Recommended Blogs
If you found this review useful, these posts cover related topics across the open-source and Qwen3.6 ecosystem:

