





Qwen3.6-Max-Preview: Benchmarks, API & Full Review (2026)
Alibaba dropped Qwen3.6-Max-Preview this morning, April 20, 2026 — and it immediately claimed the top score on six of the most demanding coding benchmarks in existence. Not just one. Six. SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, and SciCode. If you build AI-powered coding tools, agents, or developer workflows, this is the release you've been waiting for.
What Is Qwen3.6-Max-Preview?
Qwen3.6-Max-Preview is Alibaba's most capable language model to date — a proprietary, hosted flagship model available via Alibaba Cloud Model Studio and Qwen Studio, released on April 20, 2026. It is the top-tier model in the Qwen3.6 family, sitting above the Qwen3.6-Plus that launched three weeks earlier.
The 'Preview' label is deliberate. Alibaba is still actively developing the model, gathering community feedback, and expects further improvements in subsequent versions. That said, even as a preview, the benchmark numbers are not incremental — they're generation-defining for coding.
The model supports a 260,000 token context window, is compatible with both OpenAI and Anthropic API specifications via Alibaba Cloud's compatible-mode endpoint, and introduces the preserve_thinking feature designed specifically for multi-turn agentic workflows. You can interact with it on Qwen Studio today. The API access via the model string qwen3.6-max-preview is coming soon to Alibaba Cloud Model Studio.
This is the third major Qwen release in April 2026 alone. If you want context on how the full Qwen3.6 family fits together — including the open-source 35B-A3B model — our Qwen3.6-35B-A3B deep-dive review covers the open-weight side of this family in detail.
What Changed Over Qwen3.6-Plus?
Qwen3.6-Max-Preview is not a minor patch. Compared to Qwen3.6-Plus (launched March 30, 2026), it delivers meaningful gains across three specific dimensions: agentic coding, world knowledge, and instruction following.
On agentic coding, the benchmark improvements are significant. SkillsBench jumped by 9.9 points. SciCode improved by 10.8 points. NL2Repo — which tests the ability to navigate and contribute to real codebases — improved by 5.0 points. Terminal-Bench 2.0, which simulates actual terminal-based engineering tasks under real hardware constraints (32 CPU, 48 GB RAM, 3-hour timeout), improved by 3.8 points.
On world knowledge, SuperGPQA improved by 2.3 points and QwenChineseBench by 5.3 points. On instruction following, ToolcallFormatIFBench — a benchmark for tool-calling format compliance in agentic settings — improved by 2.8 points. These aren't cosmetic gains. Tool-call format reliability directly affects whether your agents succeed or fail in production.
My hot take: the 10.8-point gain on SciCode is the number that matters most here. SciCode tests the ability to write working code that solves real scientific and engineering problems — not autocomplete suggestions, not documentation summaries. That kind of improvement signals that the model genuinely understands complex domains, not just pattern-matches on training data.
Benchmark Breakdown: Where It Wins (and Where It Doesn't)
Qwen3.6-Max-Preview claims the top position on six major coding benchmarks as of its April 20, 2026 release. Here's the full picture compared to its closest competitors:
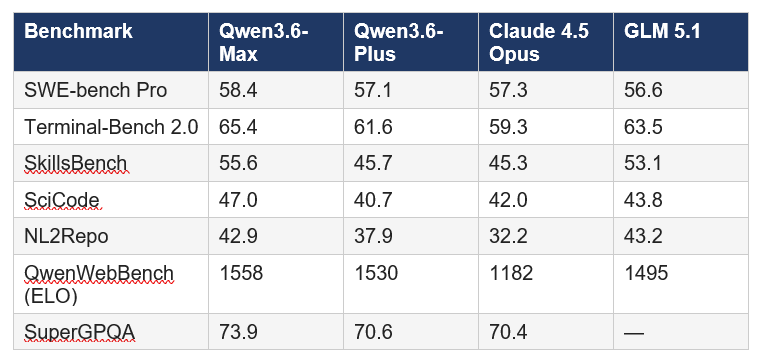
Note: Claude scores in Alibaba's comparison appear to use Claude Opus 4.5 as the baseline for most benchmarks. For Terminal-Bench 2.0 specifically, Anthropic's own Claude Opus 4.6 submission scores 65.4% — which matches Qwen3.6-Max-Preview's result, making it a true tie rather than a Qwen win. The benchmarks are real, but always check which model version was used in the comparison.
Where Qwen3.6-Max-Preview dominates most convincingly is QwenWebBench (ELO 1558 vs 1182 for Claude Opus 4.5). This is an internal front-end code generation benchmark covering web design, web apps, games, SVG, and data visualization across both English and Chinese. For teams building UI-heavy products, this gap is the most actionable number in the entire release.
If you're deciding where Max-Preview fits in the broader model landscape right now, our ranked comparison of the best AI models in April 2026 gives you the full leaderboard context across 20+ models.
How to Access the API: Step-by-Step
Qwen3.6-Max-Preview is available via the Alibaba Cloud Model Studio API as the model string qwen3.6-max-preview. The API uses an OpenAI-compatible endpoint, so if you've already integrated Qwen3.6-Plus or any other OpenAI-compatible model, switching is a one-line change.
Step 1: Get your API key from the Alibaba Cloud Model Studio console at modelstudio.console.alibabacloud.com. Set it as the environment variable DASHSCOPE_API_KEY.
Step 2: Install the OpenAI Python SDK if you haven't already: pip install openai
Step 3: Point your client at the Alibaba Cloud compatible-mode endpoint and use the new model string. Here is the minimal working example:
from openai import OpenAI import os client = OpenAI( api_key=os.environ["DASHSCOPE_API_KEY"],
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1", ) completion = client.chat.completions.create(
model="qwen3.6-max-preview",
messages=[{"role": "user", "content": "Review this Python function for bugs."}],
extra_body={"enable_thinking": True, "preserve_thinking": True}, stream=True )The model is currently in preview and available for free during this period. Once the full API goes live, Alibaba will publish pricing. Based on patterns from Qwen3.6-Plus, expect competitive positioning well below Claude Opus 4.6's $5/$25 per million tokens.
If you want a practical example of what you can build before the full API goes live, the Qwen + Cerebras AI game generator cookbook shows you how to wire up a Qwen model in a Streamlit app — swap in qwen3.6-max-preview when the API drops and it will work without any other changes.
The preserve_thinking Feature Explained
The preserve_thinking feature is one of the most underrated capabilities in this release, and it's the reason Qwen3.6-Max-Preview is specifically positioned for agentic tasks.
By default, language models discard their internal reasoning between turns. Each new message is a blank slate — the model recomputes everything from scratch. For simple chat interactions, that's fine. For agentic coding workflows where the model needs to maintain coherent intent across dozens of tool calls, file reads, and code generations, it's a serious reliability problem.
When preserve_thinking is enabled (pass preserve_thinking: True in the extra_body of your API request), the model retains the chain-of-thought from previous turns in the conversation history. This means it can refer back to earlier reasoning steps, avoid contradicting itself across tool calls, and maintain a consistent mental model of the codebase it's working in. Alibaba recommends enabling this feature for all agentic tasks.
The practical result: fewer retries, more consistent tool-calling behavior, and better task completion rates on long-horizon engineering tasks. If you've been frustrated by agents that seem to 'forget' the constraints you set three steps ago, this feature directly addresses that failure mode.
For teams already using the Qwen Agent framework for multi-step workflows, the Qwen3.6-Plus full review covers the architecture changes in Qwen3.6 that make preserve_thinking possible — including the hybrid attention mechanism that retains context more efficiently than standard attention.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Qwen3.6-Max-Preview vs Claude Opus 4.6 vs GPT-5.4
This is the comparison developers actually want. Here's where each model genuinely leads in April 2026:
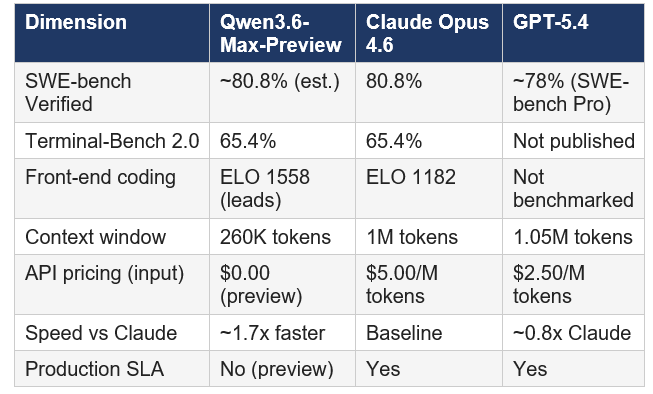
My honest assessment: on raw coding capability at the end of April 2026, this is the tightest three-way race in the history of AI benchmarking. Claude Opus 4.6 retains an edge on SWE-bench Verified for production software engineering. Qwen3.6-Max-Preview leads convincingly on front-end code generation and matches Claude on Terminal-Bench 2.0. GPT-5.4 leads on GUI automation and OSWorld tasks that the other two don't even compete on.
The honest contrarian point: benchmarks are not production. Alibaba's comparisons against Claude use Opus 4.5, not 4.6, for most metrics. Independent testers have flagged fabrication rates on API behavior claims when using Qwen models without careful prompting. And Qwen3.6-Max-Preview has no production SLA as of this writing. Use it for development, prototyping, and non-sensitive workflows. For production deployments at scale, Claude Opus 4.6 or GPT-5.4 are still the safer calls.
For a head-to-head on the Chinese AI lab competition specifically, the Qwen3.6-Plus vs GLM-5.1 vs Kimi 2.5 coding comparison breaks down how Max-Preview's predecessor positioned itself, and how Max-Preview changes those rankings.
Open Source vs Proprietary: Which Qwen3.6 Should You Use?
This is the most practical question for most developers. Qwen3.6-Max-Preview is the proprietary hosted flagship. Qwen3.6-35B-A3B is the open-source Apache 2.0 release from four days ago. They serve different use cases.
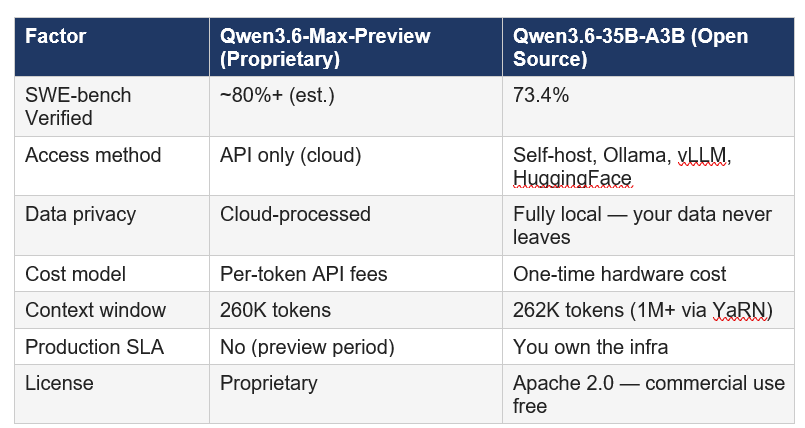
For teams handling sensitive code (fintech, healthcare, legal), Qwen3.6-35B-A3B is the correct default. Your proprietary code never leaves your infrastructure. The 73.4% SWE-bench Verified score is exceptional for an open-weight model — the gap versus Max-Preview is real but not disqualifying for most real-world tasks. For the highest benchmark performance without infrastructure overhead, Max-Preview is the call — as long as you're comfortable with API data terms and the preview-stage reliability profile.
If front-end and UI generation is your primary use case, check out our analysis of the best AI models for frontend and UI development in 2026 — Qwen3.6-Max-Preview's QwenWebBench ELO of 1558 changes several of those rankings.
Interested in self-hosting Qwen3.6-35B-A3B for local agentic code review? The gen-ai-experiments repository has production-ready notebooks covering quantization, vLLM serving, and CI integration that you can adapt for either Qwen3.6 variant.
Frequently Asked Questions
What is Qwen3.6-Max-Preview?
Qwen3.6-Max-Preview is Alibaba's most capable language model, released April 20, 2026. It is a proprietary hosted model available via Qwen Studio and Alibaba Cloud Model Studio, positioned as the flagship tier of the Qwen3.6 family. It achieves top scores on six major coding benchmarks including SWE-bench Pro, SkillsBench, and SciCode, with a 260K token context window and the preserve_thinking feature for agentic workflows.
Is Qwen3.6-Max-Preview better than Claude Opus 4.6 for coding?
On front-end code generation (QwenWebBench ELO 1558 vs 1182) and SkillsBench (+10.3 points), Qwen3.6-Max-Preview leads as of April 2026. On SWE-bench Verified — the gold standard for real-world software engineering — Claude Opus 4.6 holds its position at 80.8%. On Terminal-Bench 2.0, both models are tied at 65.4%. The honest answer: they're different strengths, and no single model leads on every coding task.
How do I access Qwen3.6-Max-Preview via API?
Use the model string qwen3.6-max-preview with an OpenAI-compatible client pointed at the Alibaba Cloud Model Studio endpoint (dashscope-intl.aliyuncs.com/compatible-mode/v1). You will need a DASHSCOPE_API_KEY from the Alibaba Cloud console. Full API availability is coming soon — you can already interact with the model on Qwen Studio at chat.qwen.ai.
What is the difference between Qwen3.6-Max-Preview and Qwen3.6-Plus?
Qwen3.6-Max-Preview is the higher-tier proprietary model. Compared to Qwen3.6-Plus, it delivers +9.9 points on SkillsBench, +10.8 on SciCode, +5.0 on NL2Repo, +3.8 on Terminal-Bench 2.0, +2.3 on SuperGPQA, +5.3 on QwenChineseBench, and +2.8 on ToolcallFormatIFBench. Both models are available via the Alibaba Cloud API. Qwen3.6-Plus has been available for three weeks; Max-Preview launched today.
Is Qwen3.6-Max-Preview free to use?
Currently, yes — it is in a free preview period. You can interact with it directly on Qwen Studio at no cost. The full commercial API (qwen3.6-max-preview on Alibaba Cloud) is coming soon and pricing has not yet been announced. Note that during the preview period, prompts and completions may be used for model improvement. Avoid sensitive or proprietary inputs during this period.
What is the preserve_thinking feature and why does it matter?
preserve_thinking is an API parameter (enable via preserve_thinking: True in extra_body) that retains the model's chain-of-thought reasoning across conversation turns. Standard models discard internal reasoning after each response. With preserve_thinking enabled, the model maintains its reasoning context across a full multi-turn agentic session — reducing errors, preventing contradictions across tool calls, and improving task completion rates on long-horizon coding tasks.
Is Qwen3.6-Max-Preview open source?
No. Qwen3.6-Max-Preview is a proprietary model. The model weights are not publicly available. If you need an open-source Qwen3.6 option, Qwen3.6-35B-A3B was released under Apache 2.0 on April 16, 2026, scores 73.4% on SWE-bench Verified, and is available via HuggingFace, Ollama, and vLLM.
How does Qwen3.6-Max-Preview compare to GLM-5.1 and Kimi 2.5?
On SWE-bench Pro, Qwen3.6-Max-Preview leads GLM-5.1 at 58.4% vs 56.6%. On Terminal-Bench 2.0, GLM-5.1 (63.5%) trails Max-Preview (65.4%). Kimi 2.5 remains the leader on LiveCodeBench for competitive programming. Each model has a specific strength: Qwen leads on front-end coding, GLM on long-horizon autonomous tasks, and Kimi on competitive algorithm challenges.
Recommended Blogs
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
References
Qwen Team. Qwen3.6-Max-Preview: Smarter, Sharper, Still Evolving (April 18, 2026).
Serenities AI. Qwen 3.6 Plus vs Claude Opus 4.6 vs GPT-5.4: Complete Comparison (April 2026).
Build Fast with AI. Qwen3.6-35B-A3B: 73.4% SWE-Bench, Runs Locally (April 2026).
Build Fast with AI. Qwen 3.6 Plus Preview: 1M Context, Speed & Benchmarks 2026.

