





Qwen3.6-35B-A3B: 73.4% on SWE-Bench With 3B Active Params — and It Runs on Your Laptop
I woke up on April 16 to developers sharing screenshots of an open-source model beating Claude Opus 4.7 on a local MacBook. Not a typo. Alibaba's Qwen team just dropped Qwen3.6-35B-A3B — a sparse Mixture of Experts model that scores 73.4% on SWE-bench Verified while activating only 3 billion of its 35 billion parameters per token. For context: Gemma 4-31B, a dense model that activates all 31 billion of its parameters every single inference step, scores 52.0% on the same benchmark. The efficient model won. By a lot.
This is the kind of release that changes how you think about local AI. And it launched under the Apache 2.0 license, meaning you can use it commercially, modify it, and build products on top of it with zero licensing fees. Here is everything you need to know before you decide whether to run it.
1. What Is Qwen3.6-35B-A3B? (And What Does "A3B" Mean?)
Qwen3.6-35B-A3B is a sparse Mixture of Experts (MoE) multimodal language model developed by Alibaba's Qwen team, released on April 16, 2026 under the Apache 2.0 open-source license. It is the latest entry in the Qwen3.6 family — the higher-end complement to the Qwen 3.5 Small series (0.8B–9B) that Alibaba released earlier in 2026.
The "A3B" in the name is the key thing to understand. It means approximately 3 billion active parameters per token. The model has 35 billion total parameters sitting in its weights, but the MoE router only activates a fraction of them for each forward pass. In practice, this means you get the representational capacity of a 35B model at the compute cost of a 3B model. That math is what explains every surprising benchmark result you're about to read.
I've been following MoE architectures since DeepSeek V2 made it mainstream in 2024, and Qwen3.6's sparsity ratio is among the most aggressive in any publicly released model — 3B active out of 35B total is roughly a 12:1 ratio. For comparison, if you want to understand the MoE architecture pattern more deeply, check out this breakdown on
For comparison, the Qwen family started making noise when the DeepSeek efficiency story broke — our earlier analysis on how DeepSeek changed the open-source AI cost equation is still relevant context here.
Two additional architectural points worth noting: the model supports both "thinking" and "non-thinking" modes (you toggle between deliberate chain-of-thought reasoning and fast direct responses), and the native context window is 262,144 tokens — extensible to over 1 million via YaRN scaling.
Quotable: "Qwen3.6-35B-A3B delivers the economics of a 3B model and the learned capacity of a 35B model — a 12:1 compute sparsity ratio that explains every benchmark result."
2. The Full Benchmark Breakdown
Qwen3.6-35B-A3B scores 73.4% on SWE-bench Verified — the industry's most credible real-world software engineering benchmark. For reference, the previous state-of-the-art among open models with similar active-parameter budgets was well under 60%. This number matters more than any other in this release.
Here is the complete benchmark picture across coding, reasoning, multimodal, and agentic tasks:
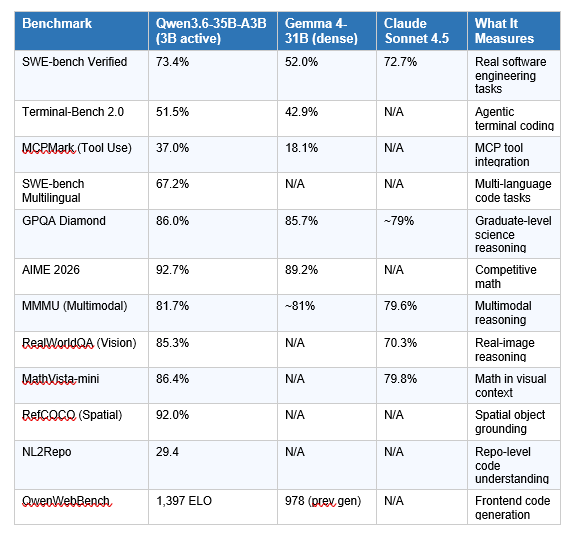
A few important nuances I want to flag before you get too excited. First, all vision benchmark comparisons against Claude Sonnet 4.5 are self-reported by Alibaba. The RealWorldQA gap (85.3% vs 70.3%) is suspiciously wide, and independent third-party evals have not yet replicated these numbers. Take the vision claims with appropriate skepticism.
Second, the SWE-bench Verified number (73.4%) is impressive, but it was measured using Alibaba's internal agent scaffold — not the standard public harness. That makes direct comparisons to other labs' published SWE-bench numbers tricky. When third-party evaluators run standardized scaffolds, numbers often shift 3-8 points in either direction.
What is objectively verifiable from community testing: the model runs at 120+ tokens per second on an RTX 4090, developers on Hacker News gave it 125+ points within hours of release, and Simon Willison at simonwillison.net declared it beat Claude Opus 4.7 on SVG generation tasks when running locally on an M5 MacBook Pro.
To see where Qwen3.6 fits against every major model released this month, check our ranked comparison of the best AI models in April 2026.
3. Qwen3.6 vs Gemma 4-31B vs Claude Sonnet 4.5: Side-by-Side
The most useful comparison is Qwen3.6-35B-A3B against Gemma 4-31B, because they are the two dominant open-source options in the sub-40B class right now. The table above tells most of the story. On every coding metric where both models have published numbers, Qwen3.6 wins — and sometimes it isn't close. MCPMark (tool use) is the starkest example: 37.0% vs Gemma 4's 18.1% means Qwen is more than twice as capable at integrating with MCP tools and function calls in agentic loops.
Where does Gemma 4-31B hold its own? Competitive coding (LiveCodeBench) and multilingual tasks where its multilingual training shows. If you're building a coding assistant for a global team where TypeScript and Python are equally important alongside Korean or Arabic input, Gemma 4's architecture choices may still warrant a serious A/B test.
Against Claude Sonnet 4.5, the comparison is messier. Claude Sonnet 4.5 is a closed proprietary model with unknown parameter count, trained with Anthropic's full RLHF pipeline and safety tuning. Qwen3.6 trails on assistant-style preference tasks and general chat. But on pure coding benchmarks at the specific task of "fix this real GitHub issue," the gap has narrowed to near parity. That's remarkable for a local, open-weight, Apache 2.0 model.
We covered Gemma 4's release in detail last month — our Google Gemma 4 review and benchmark analysis explains why the Apache 2.0 license shift was the bigger story than the benchmarks.
My honest take on the comparison: I would use Qwen3.6-35B-A3B as my default local coding model today. The MCPMark and Terminal-Bench numbers are the ones that matter for agent loops — and Qwen wins those by a wide margin. If I need production-grade reliability with Anthropic's safety guarantees, I'm still paying for Claude Sonnet 4.6. But for local development, prototyping, and internal tools? Qwen3.6 just became my first call.
4. Thinking Preservation: The Feature Developers Actually Care About
Thinking Preservation is Qwen3.6's most underreported feature, and it's the one that will matter most for anyone building multi-step coding agents. Standard reasoning models discard their chain-of-thought traces after each turn — every new message starts with a blank reasoning slate. This is fine for one-shot questions. It's frustrating for iterative agent loops.
With Thinking Preservation enabled, the model retains its reasoning context from previous turns. In practice, this means an agent loop doing something like "analyze this repo, then write a test suite, then fix the failing tests" can maintain coherent context about its earlier decisions without you needing to re-inject the full reasoning history manually. The model remembers what it was thinking.
This is a genuine architectural differentiator. Most open models don't have this at all. Proprietary services like Claude with extended thinking technically solve this through long context windows, but that costs tokens — and money. Qwen3.6's Thinking Preservation is implemented at the model level, not through brute-force context stuffing.
If you want to build agent loops that actually use this feature, the Build Fast with AI generative AI experiments repository has multi-agent orchestration cookbooks covering agentic patterns you can adapt for Qwen3.6 with minimal modification.
One flag: Thinking Preservation adds overhead. Retaining reasoning context means your effective context window fills faster, and there is computational cost to carrying those traces. For simple one-turn tasks, disable it. For iterative dev agents? Enable it and watch your agents stop forgetting what they were doing.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. How to Run Qwen3.6-35B-A3B Locally
Running Qwen3.6-35B-A3B locally is straightforward, and the community already has multiple paths ready within 14 hours of release. Here are the three main options ranked by ease of setup.
Option 1: Ollama (Easiest — One Command)
Ollama shipped native Qwen3.6 support at launch. Pull and run the model in a single command:
ollama run qwen3.6 (one-line install)
This is the fastest way to try the model. Ollama handles quantization automatically and exposes an OpenAI-compatible API at localhost:11434. The tradeoff: you get less control over quantization settings and inference parameters compared to vLLM.
Option 2: vLLM (Production / High Throughput)
For teams serving the model to multiple users or building production API endpoints, vLLM is the right tool. The command is:
vllm serve Qwen/Qwen3.6-35B-A3B --port 8000 --tensor-parallel-size 1 --max-model-len 262144 --trust-remote-code --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder
Add --tensor-parallel-size 2 if you have two GPUs to split the model across. For tool use (which you almost certainly want for coding agents), the --enable-auto-tool-choice and --tool-call-parser qwen3_coder flags are required.
Option 3: Unsloth GGUF + llama.cpp (Best for Apple Silicon and Single GPUs)
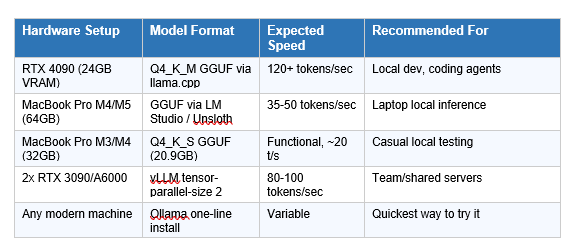
UnslothAI released Dynamic 2.0 GGUF quantizations within hours of the model's launch. The Q4_K_M variant runs at 120+ tokens/second on an RTX 4090 and functionally on a 64GB MacBook Pro M4/M5. Download via:
huggingface-cli download unsloth/Qwen3.6-35B-A3B-GGUF --include "Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf" --local-dir ./
Then serve with llama-server or load directly in LM Studio for a GUI experience.
Hardware Requirements
For a deeper walkthrough on setting up local inference environments for models like this, our AI models from March 2026 breakdown covers the local inference ecosystem in detail, including MoE-specific setup considerations.
6. Deployment Options: API, Cloud, and Self-Hosted
Qwen3.6-35B-A3B is available across several access points right now, with more coming.
- Hugging Face: Model weights available at Qwen/Qwen3.6-35B-A3B. Download and self-host with no restrictions under Apache 2.0.
- ModelScope: Mirror for users in China or those who prefer the Alibaba-native platform.
- Alibaba Cloud Bailian (coming): API access compatible with OpenAI and Anthropic protocols. Pricing expected around $0.29/M input tokens and $1.65/M output tokens — roughly 12x cheaper than Claude Opus 4.6 for equivalent tasks.
- OpenRouter: Qwen3.6-35B-A3B may appear as a hosted option as the ecosystem integrates it. Check OpenRouter for current availability.
- Integration: Works natively with Claude Code (via Ollama backend), Qwen Code, CLINE, and any OpenAI-compatible client.
A note on the API compatibility point: Qwen3.6-35B-A3B's API will support Anthropic protocol in addition to OpenAI-compatible endpoints. That means you can drop it into existing Claude API integrations with minimal code changes. For teams evaluating cost reduction on internal tools, that compatibility matters a lot.
We analyzed the Qwen 3.6 Plus cloud model (the proprietary 1M-context sibling) separately. If you're evaluating the full Qwen 3.6 family, read our Qwen 3.6 Plus Preview review alongside this post.
7. Who Should Actually Use Qwen3.6-35B-A3B?
Qwen3.6-35B-A3B is the right model for you if at least two of the following apply:
- You are building or running a local AI coding agent and need the best open-weight model available for agentic tasks right now.
- You are self-hosting for privacy, data sovereignty, or compliance reasons and cannot use cloud APIs for code.
- You are a developer or startup with a tight compute budget who wants frontier-adjacent coding capability without a monthly API bill.
- You are building on top of Claude Code or Qwen Code and want a powerful local backend model that integrates without configuration overhead.
- You have an RTX 4090, high-RAM Mac, or dual-GPU setup collecting dust between training runs.
It is probably not the right model if you need verified production stability (this was released 14 hours ago at the time I'm writing this), if your primary use case is multimodal video or audio (use Qwen3.5 Omni instead), or if you need Anthropic-grade safety and content policy reliability for customer-facing products.
8. My Honest Take: What Impresses Me — and What Does Not
I am genuinely impressed by three things about this release. First, the MCPMark score. MCP tool integration is where most open models fall apart in real agentic workflows — Qwen3.6 scoring 37.0% vs Gemma 4's 18.1% suggests this model was explicitly trained on tool-use patterns, not just code generation. That distinction matters enormously for anyone building actual agents rather than code autocomplete.
Second, the QwenWebBench jump from 978 to 1,397 ELO is a 43% improvement in frontend code generation over the previous generation. Frontend is where coding models typically underperform — too much variation in frameworks, CSS edge cases, and component integration logic. If this number holds in independent testing, Qwen3.6-35B-A3B becomes a genuinely viable backend for tools like Cursor or Windsurf running locally.
Third, the community response was immediate in a way that matters. Unsloth had GGUFs ready within hours. Ollama shipped native support at launch. Bartowski had additional GGUF variants on Hugging Face within three hours. That ecosystem velocity is what separates models people actually use from models that look good on benchmarks and then disappear.
What does not impress me: the self-reported benchmark comparisons against Claude Sonnet 4.5 on vision tasks need third-party validation before I trust them. A 15-point gap on RealWorldQA (85.3% vs 70.3%) is too large to accept without independent confirmation — model cards have strong incentives to cherry-pick favorable comparisons. I'd wait two weeks for community evaluations before citing those vision numbers in any serious technical decision.
My contrarian take: the bigger story here is not the model itself — it's what Alibaba released this model two weeks after their longtime Qwen lead Junyang Lin stepped down, and it's arguably the best open-source model release of the year so far. That says something interesting about organizational momentum. The question worth watching is whether this pace continues, or whether the leadership transition eventually shows in release quality.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. Frequently Asked Questions
What is Qwen3.6-35B-A3B?
Qwen3.6-35B-A3B is an open-source sparse Mixture of Experts (MoE) multimodal language model released by Alibaba's Qwen team on April 16, 2026. It has 35 billion total parameters but activates only 3 billion per token during inference, making it highly compute-efficient. It is released under the Apache 2.0 license, enabling free commercial use.
What does A3B mean in a model name?
"A3B" stands for approximately 3 billion active parameters. In a Mixture of Experts architecture, the model has a larger pool of parameters (35B in this case) but a router network activates only a subset (3B) for each token processed. This gives the model the learned capacity of a 35B model at the inference cost of a 3B model.
How does Qwen3.6-35B-A3B compare to Gemma 4-31B on coding benchmarks?
Qwen3.6-35B-A3B significantly outperforms Gemma 4-31B on real-world coding tasks. On SWE-bench Verified, Qwen3.6 scores 73.4% vs Gemma 4-31B's 52.0%. On Terminal-Bench 2.0, it scores 51.5% vs 42.9%. On MCPMark (tool use), it more than doubles Gemma's score at 37.0% vs 18.1%. Gemma 4-31B retains advantages on LiveCodeBench competitive programming and multilingual tasks.
What is Thinking Preservation in Qwen3.6?
Thinking Preservation is a new feature in Qwen3.6 that allows the model to retain its reasoning traces from earlier turns in a conversation, rather than discarding them after each message. This is particularly useful in multi-step agent loops where the model needs to maintain coherent context about earlier decisions — such as when debugging code across multiple files in a repository.
What hardware do I need to run Qwen3.6-35B-A3B locally?
The minimum practical setup is a 64GB unified memory Mac (M3/M4/M5 Pro or Max) or a system with an RTX 4090 (24GB VRAM) plus at least 32GB of system RAM. The Unsloth Q4_K_S GGUF quantization weighs approximately 20.9GB and runs at 35-50 tokens per second on Apple Silicon. On an RTX 4090 with llama.cpp or vLLM, expect 120+ tokens per second.
How do I run Qwen3.6-35B-A3B with Ollama?
With Ollama installed, run the command: ollama run qwen3.6. Ollama shipped native support for Qwen3.6 at launch on April 16, 2026. This downloads the model automatically, handles quantization, and exposes an OpenAI-compatible API at http://localhost:11434. No additional configuration is needed for basic inference.
Is Qwen3.6-35B-A3B production-ready?
As of April 17, 2026 — the model was released 24 hours ago — it is not yet verified for production deployment. Community benchmarks are still emerging, third-party vision comparisons have not been independently validated, and there is no long-term stability track record. For development, prototyping, and internal tooling, it is an excellent choice. For customer-facing production applications, allow two to four weeks for the community evaluation ecosystem to mature.
How does Qwen3.6-35B-A3B compare to the Qwen 3.6 Plus cloud model?
Qwen 3.6 Plus (released March 31, 2026) is a proprietary cloud model with a 1 million token context window and 78.8% on SWE-bench Verified. Qwen3.6-35B-A3B (released April 16, 2026) is the open-weight, locally runnable companion model with a 262K context window and 73.4% on SWE-bench Verified. The Plus model has higher benchmark scores; the 35B-A3B variant has open weights and can run entirely offline.
Recommended Blogs
These are real posts that exist on buildfastwithai.com right now — all directly related to the Qwen3.6 story:
- Qwen 3.6 Plus Preview: 1M Context, Speed & Benchmarks 2026
- Best AI Models April 2026: Ranked by Benchmarks
- Google Gemma 4: Best Open AI Model in 2026?
- 12+ AI Models in March 2026: The Week That Changed AI
- DeepSeek vs ChatGPT vs Anthropic: The MoE Efficiency Breakdow
References
- Qwen3.6-35B-A3B Official Model Card — Hugging Face
- Qwen3.6-35B-A3B: Agentic Coding Power, Now Open to All — Qwen Official Blog
- Alibaba Announces Qwen3.6-35B-A3B, Beats Gemma 4-31B On Many Benchmarks — OfficeChai
- unsloth/Qwen3.6-35B-A3B-GGUF — Hugging Face
- Simon Willison: Qwen3.6-35B-A3B Outdraws Claude Opus 4.7 Locally
- Qwen 3.6 vs Gemma 4 vs Llama 4 vs GLM-5 Comparison — Lushbinary
- Build Fast with AI — Gen AI Experiments Repository (Cookbooks)
- Qwen 3.6 Developer Guide: Benchmarks, Architecture & Self-Hosting — Lushbinary