





I've been covering AI releases for a while now, and even I had to double-check the calendar. OpenAI dropped GPT-5.4 with a 1-million-token context window. Alibaba's Qwen 3.5 9B outperformed a model 13 times its size on graduate-level reasoning. Lightricks shipped LTX 2.3, generating native 4K video with synchronized audio in a single open-source pass. ByteDance, Peking University, and Canva combined to release Helios, a model that creates full 60-second videos at real-time speed on a single GPU. And NVIDIA quietly dropped Nemotron 3 Super at GTC, an 120B-parameter enterprise coding model that scored 60.47% on SWE-Bench Verified.
This is not a normal week in AI. This is a realignment.
I'm going to break down every model that matters, what the benchmarks actually say, and what developers and builders should do about it. Skip the hype. Here's what's real.
1. What Just Happened: The March 2026 AI Avalanche
The first week of March 2026 produced more significant AI releases than most entire quarters in 2024. Over seven days, organizations across the US, China, and Europe announced at least 12 major models and tools spanning language, video generation, 3D spatial reasoning, GPU kernel automation, and diffusion acceleration.
The release list, catalogued by AI Search (@aisearchio) on March 8, included: GPT-5.4, LTX 2.3, FireRed Edit 1.1, Kiwi Edit, HY WU, Qwen 3.5 Small Series, CUDA Agent, CubeComposer, Helios, Spatial T2I, Spectrum, Utonia, and more. NVIDIA added Nemotron 3 Super at GTC on March 11, making the full count across the first two weeks even higher.
What makes this week different is not just the quantity. The quality gap between open-source and proprietary closed rapidly. Alibaba's 9B open model matched OpenAI's 120B parameter model on GPQA Diamond. Lightricks shipped a 4K video generator that was unthinkable six months ago. ByteDance and Peking University built real-time minute-long video generation without KV-cache, quantization, or sparse attention tricks.
The frontier is no longer the exclusive domain of trillion-dollar companies. That's the real story here.

2. GPT-5.4: OpenAI's Million-Token Frontier Model
GPT-5.4 is OpenAI's most capable and efficient model released to date, launched on March 5, 2026. It comes in three variants: GPT-5.4 Standard, GPT-5.4 Thinking (reasoning-first), and GPT-5.4 Pro (maximum capability). The API supports context windows up to 1.05 million tokens, the largest OpenAI has ever offered commercially.
On factual accuracy, GPT-5.4 reduces individual claim errors by 33% and full-response errors by 18% compared to GPT-5.2. It scored 83% on OpenAI's GDPval benchmark for knowledge work. For coding specifically, it hits 57.7% on SWE-Bench Pro, just above GPT-5.3-Codex's 56.8%, with lower latency.
The new Tool Search feature is genuinely clever. Instead of loading all tool definitions into the prompt (which gets expensive fast when you have 50+ tools), the model dynamically looks up relevant tool definitions as needed. For developers building complex agentic systems, that's a real cost and latency reduction, not a marketing feature.
Pricing: $2.50 per 1M input tokens and $15.00 per 1M output tokens for standard context. There's a 2x surcharge beyond 272K tokens. That surcharge is going to matter for anyone running large-document workflows.
My honest take: GPT-5.4 is incrementally better than GPT-5.2/5.3, not a generational leap. The Tool Search architecture is the most interesting genuine innovation here. The Thinking variant competes directly with Grok 4.20's reasoning mode. If you're already in the OpenAI ecosystem, this is a solid upgrade. If you're choosing a model fresh, the comparison table in section 6 tells a more complete story.
3. Qwen 3.5 Small: The 9B Model That Shocked Everyone
Qwen 3.5 Small is Alibaba's latest open-source family, released March 1, 2026, delivering four dense models at 0.8B, 2B, 4B, and 9B parameters. Every model is natively multimodal, supporting text, images, and video through the same set of weights without a separate vision adapter. All four are licensed under Apache 2.0.
The 9B is the headline. On GPQA Diamond (graduate-level reasoning in biology, physics, and chemistry), it scores 81.7 versus GPT-OSS-120B's 71.5. On HMMT Feb 2025 (a Harvard-MIT math competition benchmark), it hits 83.2 versus GPT-OSS-120B's 76.7. On MMLU-Pro, it reaches 82.5 versus 80.8. On video understanding (Video-MME with subtitles), the 9B scores 84.5, significantly ahead of Gemini 2.5 Flash-Lite at 74.6.
The architecture is the real story. Alibaba moved to a Gated DeltaNet hybrid architecture, combining linear attention (Gated Delta Networks) with sparse Mixture-of-Experts. Linear attention maintains constant memory complexity, which is why a 9B model can support a 262K native context window (extensible to 1M via YaRN) without blowing up on RAM. The 2B model runs on an iPhone in airplane mode, processing text and images on just 4 GB of RAM.
The cost comparison is staggering. Qwen 3.5 via API costs approximately $0.10 per 1M input tokens, versus Claude Opus 4.6 at roughly 13x that price. For startups running high-volume inference, that's the difference between a product being viable and not.
I'll say the contrarian thing here: the benchmark results are real, but benchmarks like GPQA Diamond test academic multiple-choice questions. They do not test what happens when you ask the model to debug a multi-service production outage at 2am with partial logs and five misleading stack traces. That's where the frontier closed models still have an edge. Use the benchmarks as a starting point, not a verdict.
4. LTX 2.3 and Helios: Open-Source Video's Big Moment
Two open-source video models released this week fundamentally change what independent creators and small studios can build without enterprise licensing.
LTX 2.3 (Lightricks)
LTX 2.3 is a 22-billion-parameter Diffusion Transformer model released by Lightricks in the first week of March 2026. It generates synchronized video and audio in a single forward pass, supports resolutions up to 4K at 50 FPS, and runs up to 20 seconds of video. Portrait-mode generation at 1080x1920 is native, not a post-processing crop.
Four checkpoint variants ship: dev, distilled, fast, and pro. The distilled variant runs in just 8 denoising steps. A rebuilt VAE delivers sharper textures and edge detail compared to LTX 2. A new gated attention text connector improves prompt adherence significantly. Audio is cleaner via filtered training data and a new vocoder.
Six months ago, synchronized audio-video generation at 4K in an open-source package was science fiction. Today it costs zero in licensing fees.
Helios (Peking University, ByteDance, Canva)
Helios is a 14-billion-parameter autoregressive diffusion model generating videos up to 1,440 frames (approximately 60 seconds at 24 FPS) at 19.5 FPS on a single NVIDIA H100 GPU. Released under Apache 2.0.
What makes Helios architecturally interesting is what it does NOT use. No KV-cache. No quantization. No sparse attention. No anti-drifting heuristics. The team introduced Deep Compression Flow and Easy Anti-Drifting strategies during training to handle long-horizon video generation natively. The model supports text-to-video, image-to-video, and video-to-video through a unified input representation.
Real-time speed on a single H100 for 60-second videos is the number that matters here. That enables workflows that were previously only possible with multi-GPU clusters and enterprise contracts. Keep your eye on this one.
5. NVIDIA Nemotron 3 Super: The Enterprise Dark Horse
NVIDIA announced Nemotron 3 Super at GTC on March 11, 2026. It is a 120-billion-total-parameter hybrid Mixture-of-Experts model with only 12 billion active parameters per forward pass, designed for complex multi-agent applications including software development, cybersecurity triaging, and agentic workflows.
The benchmark numbers are serious. Nemotron 3 Super scores 60.47% on SWE-Bench Verified (OpenHands scaffold), versus GPT-OSS's 41.90%. On RULER at 1M tokens, it scores 91.75% versus GPT-OSS's 22.30%. It delivers 2.2x higher throughput than GPT-OSS-120B and 7.5x higher throughput than Qwen3.5-122B. That 5x throughput improvement versus the previous Nemotron Super generation is significant for production deployments.
Three genuine architectural innovations ship here. LatentMoE introduces a new expert routing mechanism. Native NVFP4 pretraining means the model was trained in 4-bit precision from the first gradient update, not post-hoc quantized. Multi-Token Prediction is built in for speculative decoding gains.
Already deployed by Perplexity (as one of 20 orchestrated models in their Computer platform), CodeRabbit, Factory, Greptile, Palantir, Cadence, Dassault Systemes, and Siemens.
I think Nemotron 3 Super is being underreported. The SWE-Bench score of 60.47% is higher than anything else in the open-weight category right now. For enterprise teams building coding agents and needing to run models on-prem (regulated industries, defense, healthcare), this is the most important model of the week. It ships with open weights and the full training recipe under the NVIDIA Nemotron Open Model License.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
6. Benchmark Breakdown: How These Models Actually Compare
Here is how the major March 2026 models stack up across the benchmarks that matter most. All data is from independent measurement or official lab disclosures.
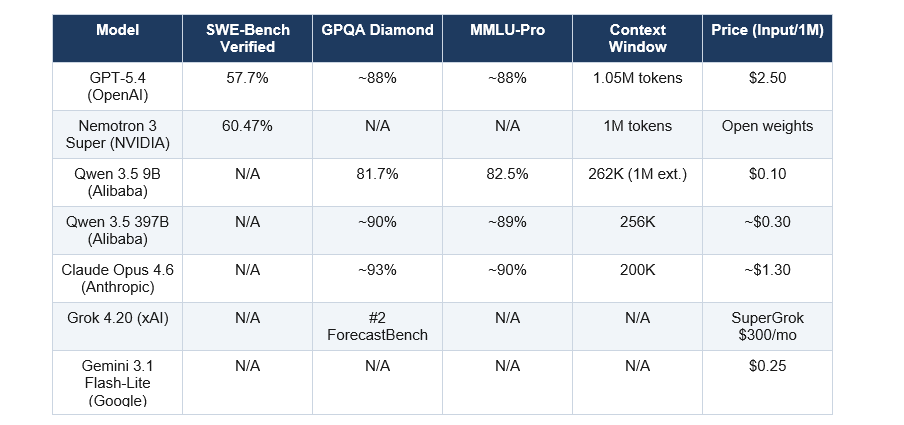
A few things jump out at me from this table. First, Nemotron 3 Super's 60.47% on SWE-Bench Verified is the highest open-weight score I've seen, period. Second, the Qwen 3.5 9B's GPQA score of 81.7% being competitive with models many times its size confirms the efficiency gains are real, not marketing. Third, GPT-5.4's 33% reduction in factual errors is the reliability improvement that matters most for production enterprise use cases.
Grok 4.20's ranking second on ForecastBench (ahead of GPT-5, Gemini 3 Pro, and Claude Opus 4.6) is the result I'd want to verify independently before building anything on top of it. Real-time reasoning on probabilistic forecasting is a genuinely hard task, and if Grok 4.20 delivers there consistently, that's a meaningful differentiator.
7. What This Means for Developers and Builders in 2026
The practical implications of this week's releases are significant. Here's what I think actually matters for people building products right now.
The on-device opportunity just got real. Qwen 3.5's 2B model runs on an iPhone with 4 GB of RAM, offline, processing text and images natively. The 4B model handles lightweight agentic tasks on consumer GPUs. The 9B matches cloud models from last year. If you're building an app and avoided local inference because the models were too weak, that excuse is gone.
Open-source video is production-ready. LTX 2.3 at 4K with synchronized audio is not a toy. Helios generating 60-second videos in real time on one H100 is not a toy. If you're paying enterprise licensing for AI video tools, the math just changed.
The coding agent race is NVIDIA's to lose. Nemotron 3 Super at 60.47% on SWE-Bench Verified, open-weight, running at 2.2x the throughput of GPT-OSS, with full training recipe transparency, is the most compelling foundation for enterprise coding agents I've seen. Teams at regulated companies that can't use cloud APIs should be benchmarking this now.
Tool calling architecture matters more than raw capability. GPT-5.4's Tool Search, which dynamically loads tool definitions rather than stuffing them all into the prompt, is the kind of infrastructure improvement that compounds. If you're building a system with many tools, the cost and latency savings are real.
The wider trend I see: the gap between proprietary frontier models and open-weight models is narrowing from years to months. The winners in 2026 are not the companies with the biggest models. They're the companies that build the best products on top of these efficient, open, edge-deployable foundations.
Frequently Asked Questions
What is the best AI model released in March 2026?
For enterprise coding tasks, NVIDIA Nemotron 3 Super scores 60.47% on SWE-Bench Verified, the highest open-weight score currently available. For general-purpose frontier performance, GPT-5.4 scores 83% on GDPval and reduces factual errors by 33% versus GPT-5.2. For on-device or budget-constrained deployment, Qwen 3.5 9B at $0.10 per 1M tokens matches models 13x its size on GPQA Diamond.
What is GPT-5.4 and when did it release?
GPT-5.4 is OpenAI's latest frontier language model, released on March 5, 2026. It offers a 1.05 million-token context window, three variants (Standard, Thinking, and Pro), 33% fewer individual factual errors than GPT-5.2, and a new Tool Search architecture for dynamic tool calling. API pricing starts at $2.50 per 1 million input tokens.
How does Qwen 3.5 9B beat a 120B model?
Qwen 3.5 9B uses a Gated DeltaNet hybrid architecture combining linear attention with sparse Mixture-of-Experts. Linear attention maintains constant memory complexity rather than quadratic scaling, enabling the model to allocate more of its parameters toward task-specific reasoning rather than memory management. On GPQA Diamond (81.7 vs 71.5) and HMMU Feb 2025 (83.2 vs 76.7), the architecture advantage is visible in the benchmark scores.
What is LTX 2.3 and is it free to use?
LTX 2.3 is a 22-billion-parameter open-source video generation model from Lightricks, released in the first week of March 2026. It generates 4K video at 50 FPS with synchronized audio in a single pass, supports portrait mode at 1080x1920, and runs in 8 denoising steps on the distilled variant. The model ships with open weights and is free to use for commercial purposes.
What is NVIDIA Nemotron 3 Super?
Nemotron 3 Super is a 120B-total-parameter, 12B-active-parameter hybrid MoE model from NVIDIA, announced at GTC on March 11, 2026. It scores 60.47% on SWE-Bench Verified, delivers 2.2x higher throughput than GPT-OSS-120B, and supports a 1M-token context window. It ships with open weights, datasets, and the full training recipe under the NVIDIA Nemotron Open Model License.
What is Helios and who made it?
Helios is a 14-billion-parameter autoregressive diffusion model built jointly by Peking University, ByteDance, and Canva. Released under Apache 2.0 in March 2026, it generates videos up to 1,440 frames (approximately 60 seconds at 24 FPS) at 19.5 frames per second on a single NVIDIA H100 GPU, supporting text-to-video, image-to-video, and video-to-video tasks through a unified architecture.
How does March 2026 AI compare to earlier generations?
March 2026 marks the point where open-source models became genuinely competitive with proprietary frontier models on specific critical benchmarks. A 9B open-weight model now matches a 120B closed model on graduate reasoning. A free video model generates 4K output. The efficiency frontier collapsed in one week: models are achieving more capability with less compute than at any previous point in the field's history.
Which AI model is best for coding in 2026?
NVIDIA Nemotron 3 Super leads on SWE-Bench Verified at 60.47%, making it the top open-weight model for real coding tasks. GPT-5.4 scores 57.7% on SWE-Bench Pro with integrated Codex capabilities and lower latency than previous coding-specialized variants. For teams needing local deployment with no API costs, Nemotron 3 Super's open weights and full training transparency make it the strongest enterprise option.
Recommended Blogs
These posts are live on buildfastwithai.com and directly related to what we covered above:
- GPT-5.4 vs Gemini 3.1 Pro (2026): Which AI Wins?
- GPT-5.4 Review: Features, Benchmarks & Access (2026)
- Gemini 3.1 Flash Lite vs 2.5 Flash: Speed, Cost & Benchmarks (2026)
- 6 Biggest AI Releases This Week: Feb 2026 Roundup
- Sarvam-105B: India's Open-Source LLM for 22 Indian Languages (2026)
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
References
- 1. OpenAI GPT-5.4 Release | sci-tech-today.com/news/march-2026-ai-models-avalanche
- 2. Alibaba Qwen 3.5 Small Series
- 3. Qwen 3.5 9B Benchmarks
- 4. NVIDIA Nemotron 3 Super SWE-Bench
- 5. Qwen3.5 Complete Guide |
- 6. xda-developers.com/qwen-3-5-9b-tops-ai-benchmarks-not-how-pick-model |
- 7. AI Search (@aisearchio) March 8 Recap |

