




Qwen 3.6 Plus Preview: The 1M-Token Free Model That's Shaking Up the AI Rankings
I woke up on March 31 to a very specific kind of chaos in my feed. Developers were sharing benchmarks, OpenRouter numbers were going wild, and one post kept appearing: Alibaba just dropped a 1-million-token model and made it completely free. That's not a typo.
Qwen 3.6 Plus Preview landed on OpenRouter on March 31, 2026, and the numbers are hard to ignore. Free access. 1M token context. Up to 65,536 output tokens. Built on a next-generation hybrid architecture that community users are clocking at roughly 3x the speed of Claude Opus 4.6 in early tests.
I've been following the Qwen series since Qwen 2.5, and each release has been faster, cheaper, and more capable than the last. But this one feels different. Not just because of the context window. Because of what it signals about where Alibaba is positioning itself against the US AI giants in 2026.
Here's my full breakdown of what Qwen 3.6 Plus Preview actually is, how it stacks up against Qwen 3.5 Omni and other major models, and whether you should build with it right now.
What Is Qwen 3.6 Plus Preview?
Qwen 3.6 Plus Preview is Alibaba's next-generation flagship language model, released on March 30-31, 2026, currently available for free via OpenRouter. It succeeds the Qwen 3.5 Plus series and is built on a new hybrid architecture designed for improved efficiency, stronger reasoning, and more reliable agentic behavior.
The "Preview" label means this is an early-access version. Alibaba is collecting prompt and completion data to improve the model. So skip sensitive or confidential information while testing — but for development, benchmarking, or learning what this thing can do, the free access is genuinely useful.
The headline feature is the 1-million-token context window. To put that in concrete terms: 1M tokens handles approximately 2,000 pages of text in a single request. Entire codebases. Long legal documents. Hours of transcribed meeting notes. All processed in one pass, with no need for chunking, retrieval, or workarounds.
I'll be honest: a year ago, I would have assumed a model with these specs would cost $15+ per million tokens. Instead it's free at the door. That changes a lot of calculations for indie developers and startups running on tight compute budgets.
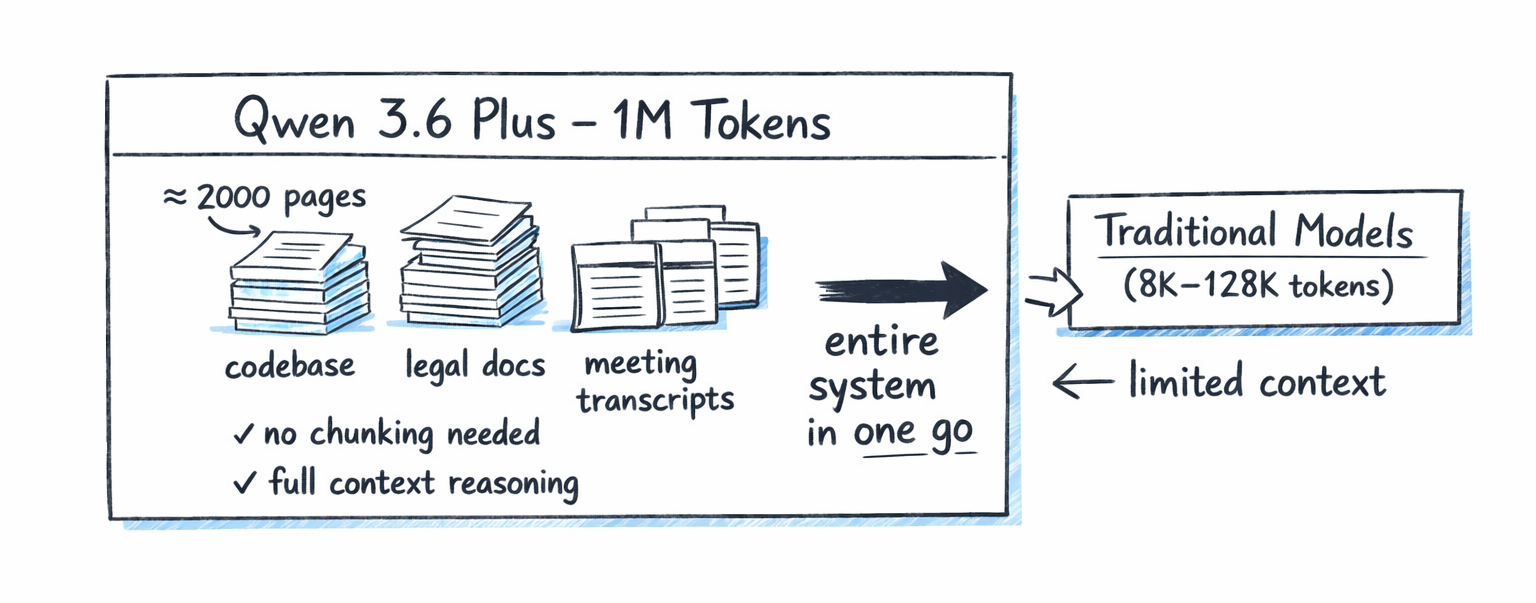
Key Specs and Architecture
Here's what we know about Qwen 3.6 Plus Preview from official sources and early testing:
- Context Window: 1,000,000 tokens (1M)
- Max Output Length: 65,536 tokens per response
- Architecture: Advanced hybrid (next-generation, not a standard MoE)
- Reasoning: Built-in chain-of-thought, always active (no thinking mode toggle)
- Tool Use: Native function calling supported
- Modality: Text only (not multimodal in this release)
- Model Size: Not publicly disclosed
- License: Closed source (not open weights)
- Availability: Free via OpenRouter (qwen/qwen3.6-plus-preview:free)
- Release Date: March 30-31, 2026
The architecture upgrade from 3.5 is described as efficiency-focused. Inference energy consumption is lower, and the model reaches conclusions faster while maintaining stability. One of the most common complaints about Qwen 3.5 was overthinking on simple tasks. Qwen 3.6 Plus appears to fix that: it's more decisive, uses fewer tokens to reach answers, and shows better agent reliability in multi-step workflows.
The always-on chain-of-thought is an interesting design choice. No toggle. No thinking vs non-thinking mode. The model reasons through every prompt by default. I think this is actually the right call for an agentic coding model where you want consistent, auditable decision-making. For simple conversational tasks, you might pay a small latency premium. For complex multi-step tasks, you get more reliable outputs.
Qwen 3.6 Plus Preview vs Qwen 3.5 Omni: Head-to-Head
This is the comparison most people in my feed are asking about. Both dropped within 24 hours of each other on March 30-31, 2026. But they are very different models targeting different use cases.
Qwen 3.6 Plus Preview vs Qwen 3.5 Omni Comparison
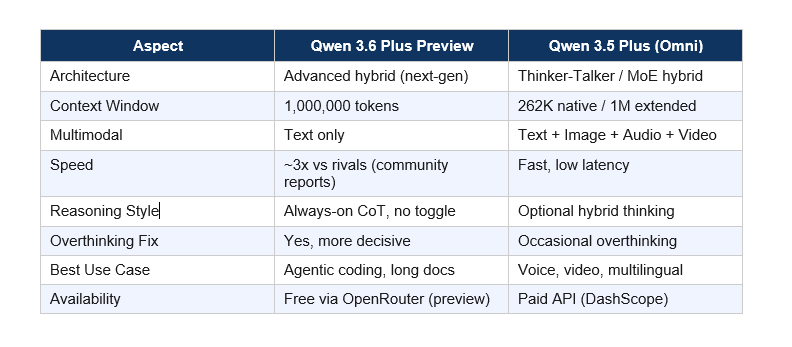
My take: These are not competing releases. They serve different builders. Qwen 3.5 Omni is a multimodal powerhouse built for voice applications, audio-video analysis, and multilingual markets. If you're building a voice agent or processing video content, Qwen 3.5 Omni (read my full review at Qwen3.5-Omni Review: Does It Beat Gemini in 2026?) is the better pick.
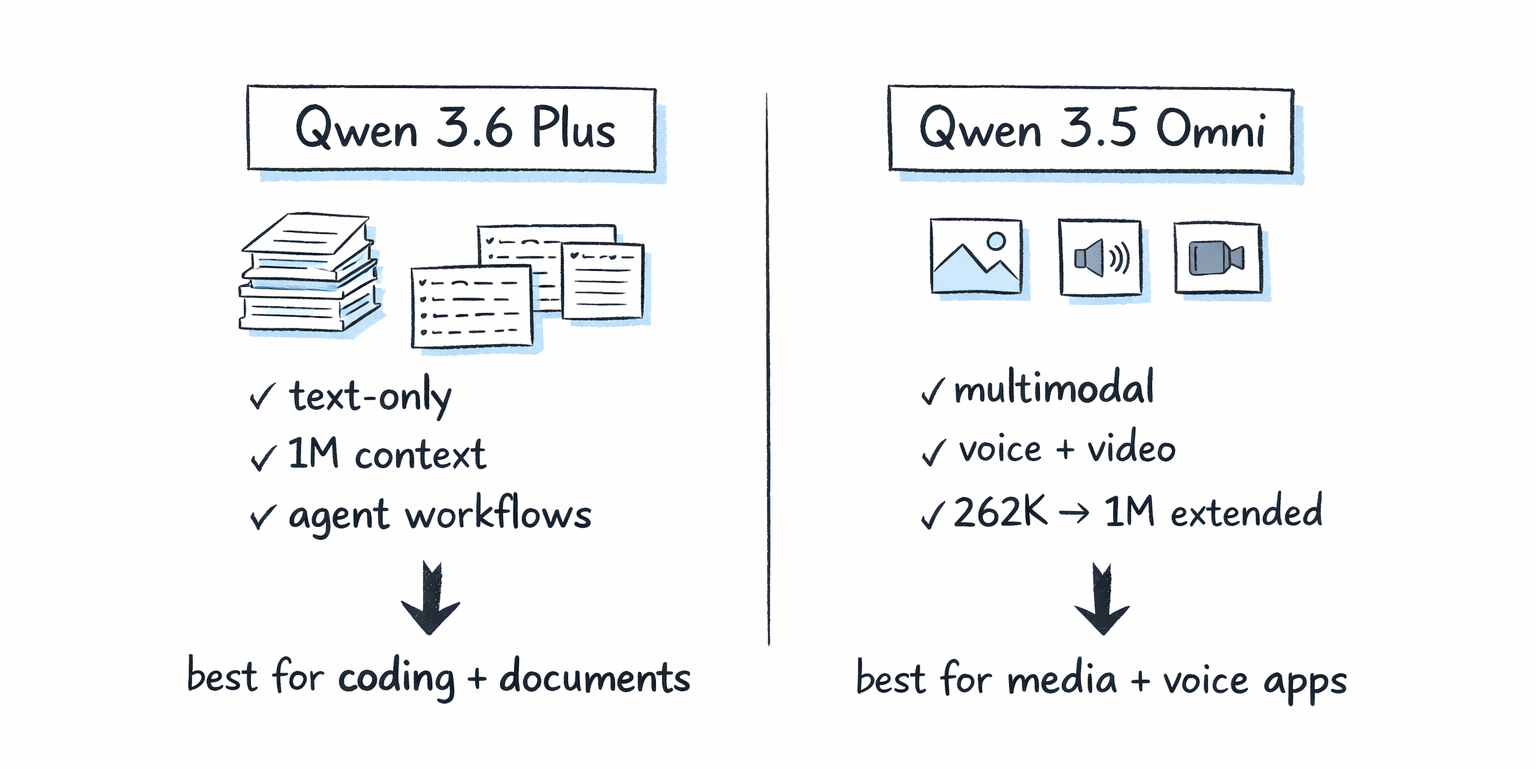
Qwen 3.6 Plus Preview is for text-heavy workloads: large codebase analysis, long-document reasoning, and complex multi-step agents that need to reason carefully and consistently. The 1M context window combined with always-on CoT makes it the better fit for those scenarios.
Full Model Comparison: Qwen 3.6 Plus vs Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro
Let me put the numbers side by side. This is what I use to evaluate whether a model is worth building on:
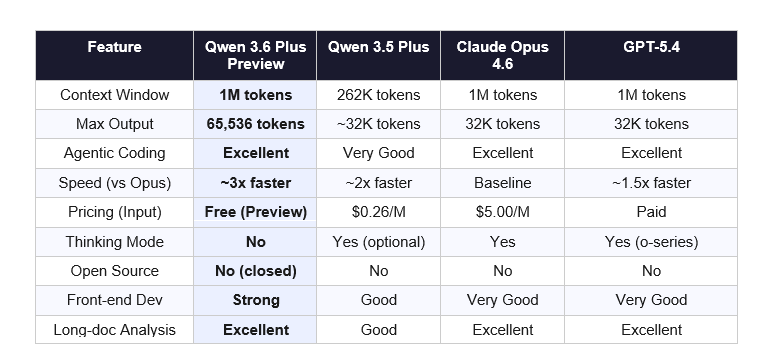
On pricing alone, Qwen 3.6 Plus Preview wins by a country mile. Claude Opus 4.6 charges $5.00 per million input tokens and $25.00 per million output tokens. GPT-5.4 is paid. Qwen 3.6 Plus Preview is free during preview. That's not a small gap. That's a fundamentally different cost structure for developers who want to experiment or build MVPs.
Where does Claude Opus 4.6 still win? Production reliability, safety controls, and the depth of its enterprise integrations. If you're shipping to clients who care about compliance and output consistency at scale, Opus 4.6's track record matters. Qwen 3.6 Plus Preview is a week old. The production trust has to be earned over time.
Gemini 3.1 Pro is the benchmark leader right now, scoring 77.1% on ARC-AGI-2 and 94.3% on GPQA Diamond. For pure reasoning and scientific knowledge tasks, it's the strongest general-purpose model available. But it's not free, and the context window math differs by workload.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
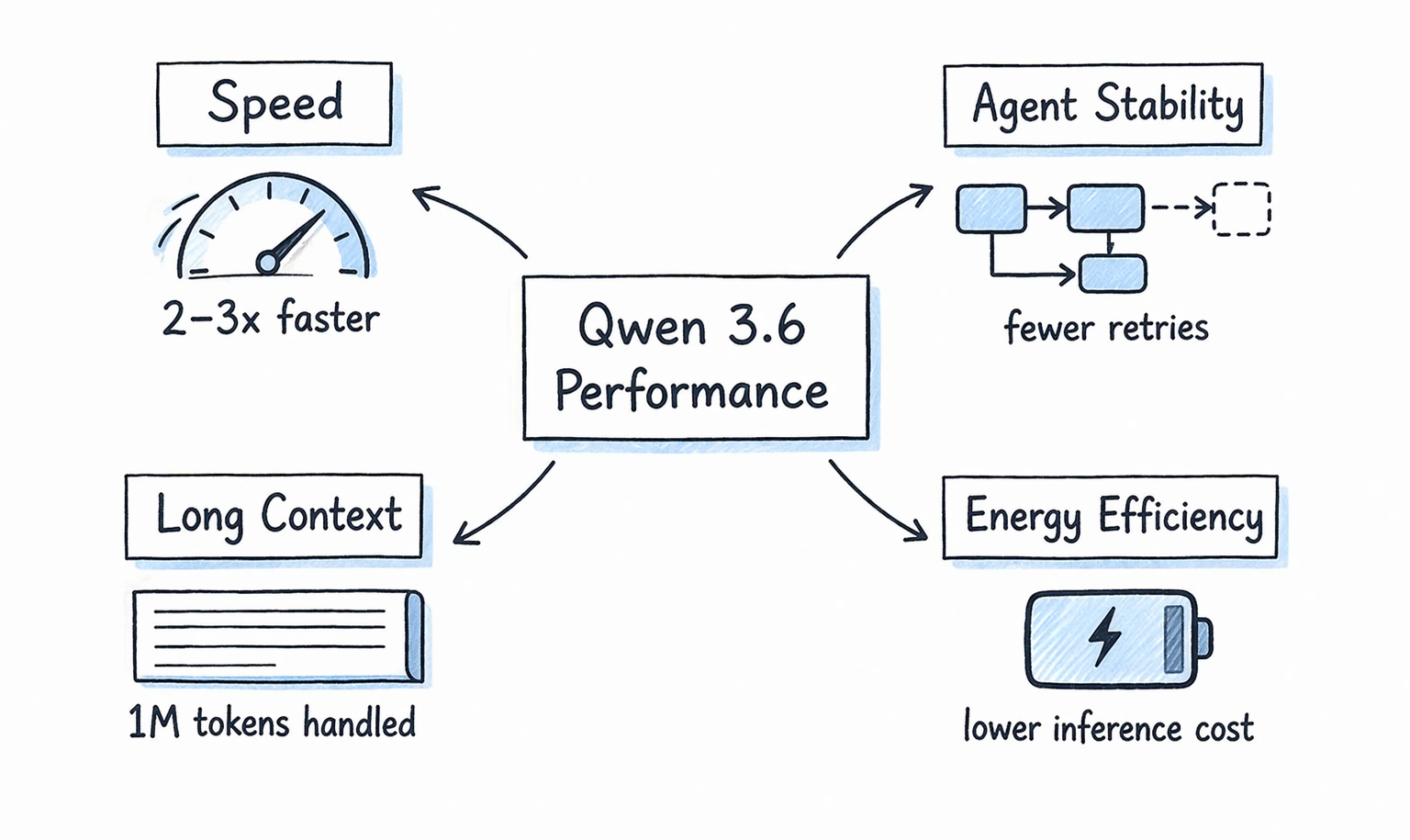
Speed and Performance: What Early Users Are Saying
Official benchmark numbers for Qwen 3.6 Plus Preview aren't fully public yet at the time of writing. But early community testing on OpenRouter is telling a clear story.
- Speed: Users are reporting Qwen 3.6 Plus Preview running at up to 3x the output speed of Claude Opus 4.6 in token-per-second tests. This tracks with Alibaba's claim of significantly reduced inference energy consumption in the new hybrid architecture.
- Agent Stability: Developers building multi-step agents are reporting fewer retries and more consistent tool-call behavior compared to Qwen 3.5. This is a big deal for production agent pipelines where flaky behavior costs real money.
- Long-Context Performance: 1M context handling in benchmarks shows solid performance. Community tests processing large codebases are reporting accurate retrieval and reasoning across the full window.
- Vision Tasks: Mixed feedback. This is a text-only model, so any vision comparisons are irrelevant. For multimodal tasks, look at Qwen 3.5 Omni instead.
- Data Privacy Note: Prompts are collected during the free preview period for model training. Do not send confidential, proprietary, or client data through the free endpoint.
I want to be specific about what we don't know yet. Public benchmark scores on SWE-Bench Verified, HumanEval, and MMLU haven't been published by Alibaba for this specific preview release. The community speed reports are real but informal. Give it 2-3 weeks for third-party evaluators to run proper comparisons. The early signals are very good. But "very good early signals" is not the same as verified SOTA performance.
Who Should Use Qwen 3.6 Plus Preview Right Now?
Build with it if you are:
- A developer building AI coding agents or code review tools who wants 1M context at zero API cost for testing and development
- Building long-document workflows: legal contract analysis, financial report summarization, repository-scale code understanding
- Running multi-step agentic tasks where the new stability improvements in 3.6 Plus matter more than raw benchmark scores
- A startup or indie developer who cannot afford $5-25 per million tokens for a production-grade frontier model during early validation
- Testing front-end component generation at scale, where the model's strength in agentic front-end development is directly useful
Wait or look elsewhere if you need:
- Multimodal inputs (audio, video, images): use Qwen 3.5 Omni instead
- Verified production stability: this is a preview model collecting training data; production deployments need more track record
- Open-source weights: Qwen 3.6 Plus Preview is closed source; if on-device or private deployment matters, Qwen 3.5 variants on Hugging Face are a better option
- The absolute highest reasoning benchmark scores: Gemini 3.1 Pro leads the field on ARC-AGI-2 and GPQA Diamond right now
The use case I'm most excited about personally: using the 1M context window to give an agent an entire codebase and ask it to audit every API endpoint for security issues in one pass. No chunking, no retrieval, no missed context. That workflow alone justifies testing this model seriously.
How to Access Qwen 3.6 Plus Preview for Free
Via OpenRouter (easiest): The model ID is qwen/qwen3.6-plus-preview:free. You need an OpenRouter API key. Free tier access is available during the preview period.
Via Puter.js (no API key needed): Puter.js supports the model with zero setup. Use the model string 'qwen/qwen3.6-plus-preview:free' in your puter.ai.chat() call. Useful for quick prototyping without any authentication setup.
Via OpenAI-compatible clients: Set the base URL to OpenRouter's endpoint and use the model string above. Works with any Python, JavaScript, or cURL setup that supports the OpenAI API format.
One practical note: during the free preview, Alibaba collects prompt and completion data. If you're working with client information, proprietary code, or anything sensitive, use a private instance or wait for the paid API. For benchmarking and personal development work, it's fine.
My Honest Take: What's Great and What's Missing
What's actually impressive:
- The 1M context window at zero cost is a genuine unlock for developers who couldn't afford frontier-model API pricing at scale
- The overthinking fix from 3.5 is real and meaningful. Faster, more decisive responses in agent workflows matters in production
- Speed advantage over Opus 4.6 is significant if the community reports hold up under more systematic testing
- Always-on chain-of-thought is the right default for agentic coding tasks
What I'm skeptical about:
- No public benchmark scores yet. "Performs at or above leading SOTA models" is a marketing claim, not a benchmark result. I need to see HumanEval, SWE-Bench, and MMLU numbers before I'd call this definitively better than GPT-5.4 or Gemini 3.1 Pro on reasoning
- Closed source and data collection during free preview creates legitimate privacy concerns for anyone with real production data
- No multimodal capability. If Qwen 3.5 Omni taught us anything, it's that the future of these models is full modality. A text-only 3.6 Plus feels like one piece of a larger release strategy, not the whole picture
- Preview status means this could change, improve, or get restricted at any time. Don't build a critical production system on a free preview model
The contrarian view worth considering: Alibaba releasing this for free isn't purely altruistic. They're training on your prompts. The cost structure only makes sense if the data you generate improves the model enough to justify the inference costs they're absorbing. That's not a reason to avoid it entirely, but it is a reason to be intentional about what you send through it.
Overall verdict: Qwen 3.6 Plus Preview is worth testing immediately if you're a developer building text-heavy agentic workflows. The cost-to-capability ratio during the free preview period is hard to argue with. Just don't confuse "free and fast" with "fully production-ready." Those are different things. Now go build something and see what it actually does.
Frequently Asked Questions
What is Qwen 3.6 Plus Preview?
Qwen 3.6 Plus Preview is Alibaba's next-generation large language model, released on March 30-31, 2026, on OpenRouter. It features a 1-million-token context window, up to 65,536 output tokens, always-on chain-of-thought reasoning, and native function calling. It is currently available free of charge during the preview period.
How does Qwen 3.6 Plus Preview compare to Qwen 3.5 Omni?
Qwen 3.6 Plus Preview is a text-only model focused on agentic coding, long-document reasoning, and multi-step agents. Qwen 3.5 Omni is a fully multimodal model supporting text, image, audio, and video. The 3.6 Plus has a larger 1M native context versus 3.5 Omni's 262K native (extendable to 1M), and addresses the overthinking issues present in the 3.5 series.
Is Qwen 3.6 Plus Preview free to use?
Yes. As of April 2026, Qwen 3.6 Plus Preview is available for free via OpenRouter using the model string qwen/qwen3.6-plus-preview:free. The model collects prompt and completion data during the preview period for model improvement. The paid pricing for the full release has not been announced.
What is the context window of Qwen 3.6 Plus Preview?
Qwen 3.6 Plus Preview supports a 1,000,000-token (1M) context window, equivalent to approximately 2,000 pages of text. This makes it suitable for repository-level code analysis, multi-hour document processing, and complex multi-turn agent workflows without chunking or retrieval.
How fast is Qwen 3.6 Plus Preview vs Claude Opus 4.6?
Early community testing on OpenRouter reports Qwen 3.6 Plus Preview running at approximately 2-3x the output speed of Claude Opus 4.6 in tokens-per-second comparisons. This aligns with Alibaba's claim of significantly reduced inference energy consumption through the new hybrid architecture. Official speed benchmarks have not been published.
Is Qwen 3.6 Plus Preview open source?
No. Qwen 3.6 Plus Preview is a closed-source model. The weights are not publicly available. Access is through the OpenRouter API only. For open-weight Qwen models, the Qwen 3.5 series (including the 9B and 27B variants) remains available on Hugging Face.
What is the difference between Qwen 3.5 Plus and Qwen 3.6 Plus Preview?
Qwen 3.6 Plus Preview upgrades the architecture with a more advanced hybrid design, expands the context window from 262K to 1M tokens, improves agent behavior reliability and reduces overthinking on simple tasks, and generates up to 65,536 output tokens per response. It does not add multimodal capabilities. Chain-of-thought reasoning is always active in 3.6 Plus, compared to optional thinking mode in 3.5.
Should I use Qwen 3.6 Plus Preview for production applications?
Not yet. This is a preview model that collects training data from prompts and completions. It has limited third-party benchmark verification and no long-term production track record. For development, testing, and building prototypes, it is excellent. For production applications handling sensitive data, use Claude Opus 4.6, GPT-5.4, or Gemini 3.1 Pro until Qwen 3.6 Plus reaches general availability with a paid API.
Recommended Blogs
If this breakdown was useful, these posts from Build Fast with AI go deeper on related topics:
Kimi 2.5 Review: Is It Better Than Claude for Coding? (2026)
LLM Scaling Laws Explained: Will Bigger AI Models Always Win? (2026)
Want to stay ahead of every major AI release? Subscribe to Build Fast with AI for weekly breakdowns, model comparisons, and hands-on tutorials that actually help you ship.
Related Cookbooks
References
- Qwen 3.6 Plus Preview on OpenRouter - OpenRouter model page with specs and pricing
- Qwen 3.6 Plus Preview Specs - Puter Developer - Technical specs and API integration guide
- Qwen 3.6 Plus Preview on OpenRouter - AIBase - Architecture upgrade details and free access announcement
- Qwen 3.6 Plus Early Benchmarks - Qubrid - Community benchmark comparisons vs Qwen 3.5 Plus and GLM 5 Turbo
- Qwen3.5-Omni Review: Does It Beat Gemini in 2026? - Build Fast with AI, March 31, 2026

