




Qwen3.5-Omni Review: Alibaba Just Beat Gemini on Audio in 2026
Alibaba dropped Qwen3.5-Omni on March 30, 2026. And if you blinked, you missed something significant.
The Plus variant hit 215 SOTA results across audio, audio-video understanding, reasoning, and interaction benchmarks. It outperformed Google's Gemini-3.1 Pro on general audio understanding, reasoning, and translation tasks. A voice-first, fully multimodal open model from a Chinese lab just outperformed Google at Google's own game.
I've been tracking the Qwen family since Qwen2.5-Omni, and the pace of improvement here is genuinely hard to wrap your head around. The previous generation supported 19 languages for speech recognition. This one handles 113 languages and dialects. That's not iteration. That's a different category of model.
So let me break down what Qwen3.5-Omni actually does, how it compares against GPT-4o, Gemini, and ElevenLabs, and whether you should actually build with it.
What Is Qwen3.5-Omni?
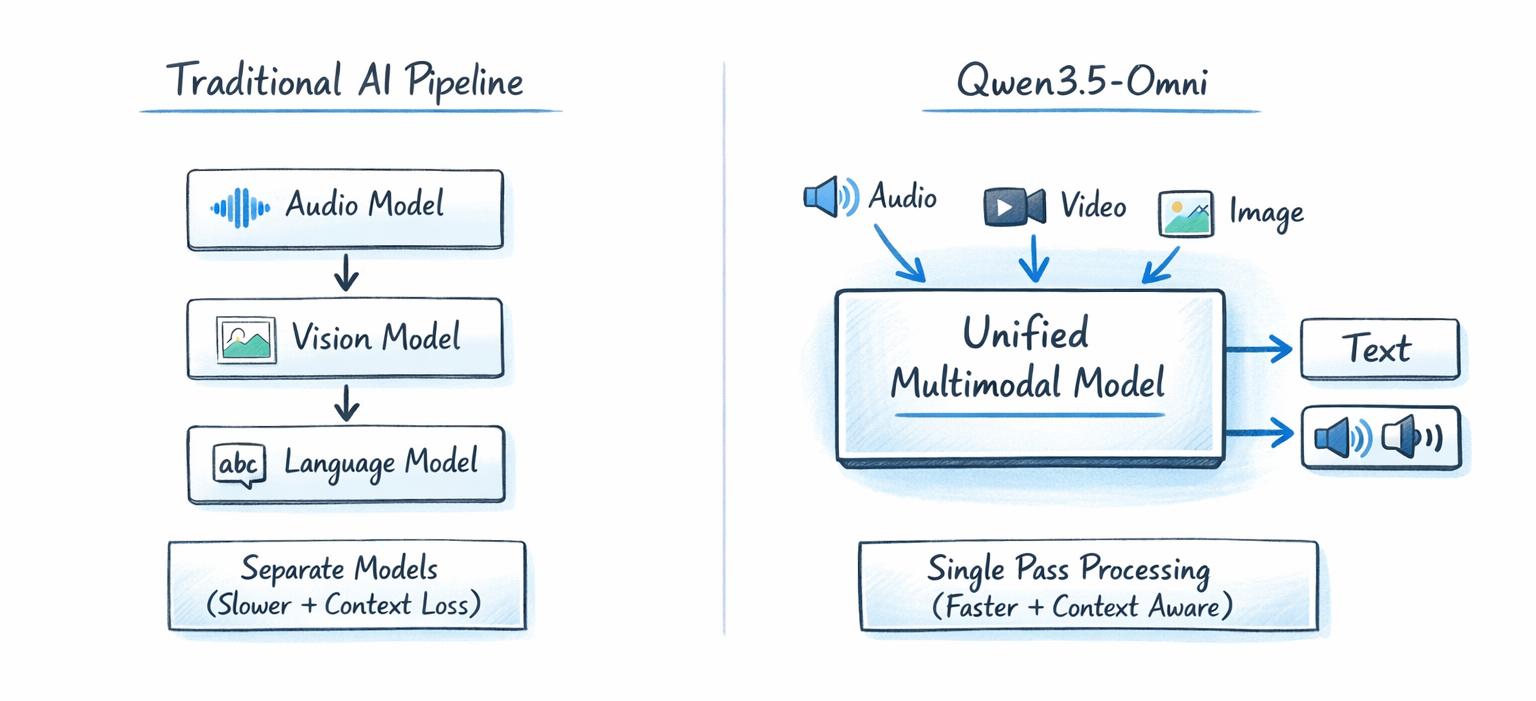
Qwen3.5-Omni is Alibaba's latest generation full-modal AI model, released on March 30, 2026. It processes text, images, audio, and video natively in a single model pass, and generates both text and streaming speech output in real time.
The key word there is "natively." Most multimodal systems stitch separate models together. GPT-4o uses Whisper for audio transcription, a vision model for image processing, and its language model for reasoning. Three separate pipelines, stitched into one UX. Qwen3.5-Omni doesn't do that. Every modality goes through a single unified model.
The practical difference is speed and contextual coherence. When a model processes video and audio in a single pass, it can reason about what a speaker is saying in the context of what they're showing on screen simultaneously. That capability is genuinely hard to replicate with a pipeline approach.
This is Alibaba's second major AI release in under six weeks. In February 2026, they launched Qwen3.5, which matched frontier models on reasoning and coding. Qwen3.5-Omni extends that into full multimodal territory.
Qwen3.5-Omni Models: Plus, Flash, and Light Compared
The Qwen3.5-Omni family ships in three size tiers, each targeting a different deployment context.
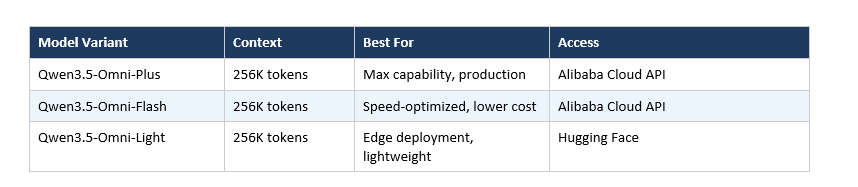
All three variants share the same 256K token context window. To put that in concrete terms: 256K tokens handles over 10 hours of continuous audio or 400 seconds of 720p video with audio. For enterprise use cases like meeting transcription, long-form content moderation, or multi-hour podcast analysis, that context length is a practical requirement, not a luxury.
The Plus variant is the one hitting those 215 SOTA results and outperforming Gemini-3.1 Pro on audio benchmarks. Flash trades some of that capability for lower latency and cost. Light is for when you need on-device or edge deployment.
My take: the Flash variant is probably the most interesting one for most developers. Most real-world applications don't need max-capability Plus but absolutely need something faster and cheaper. I'll be watching to see what the latency numbers look like in production.
How the Thinker-Talker Architecture Works
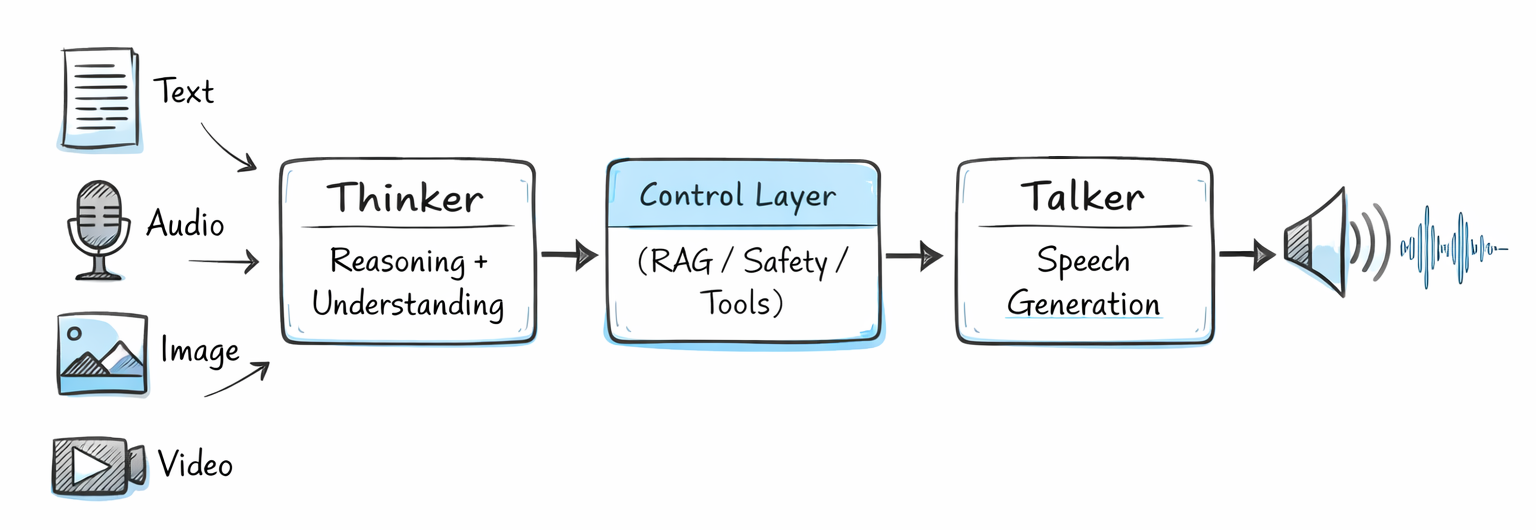
Qwen3.5-Omni uses a split architecture called Thinker-Talker, first introduced in Qwen2.5-Omni and significantly upgraded here.
The Thinker handles all reasoning and text generation. It processes every input modality including text, images, audio, and video, then generates the internal reasoning representation.
The Talker converts those representations into streaming speech tokens. It runs autoregressively, predicting multi-codebook sequences and synthesizing audio frame-by-frame via the Code2Wav renderer.
The upgrade in version 3.5 is that both Thinker and Talker now use a Hybrid-Attention Mixture-of-Experts (MoE) architecture. This matches the broader Qwen3.5 family's move toward sparse models, meaning the model routes each input token to the most relevant subset of experts rather than activating everything on every pass. The result is lower compute cost at a given capability level.
Pre-training used more than 100 million hours of native multimodal audio-video data. The audio encoder was trained from scratch on 20 million hours of audio data. The vision encoder comes from Qwen3-VL, initialized from SigLIP2-So400m with roughly 543 million parameters.
One architectural detail I find genuinely smart: the Thinker-Talker split allows external systems like RAG pipelines, safety filters, and function calls to intervene between reasoning and speech synthesis. That's important for enterprise deployment, where you often need a layer between the model's raw output and what actually gets spoken to an end user.
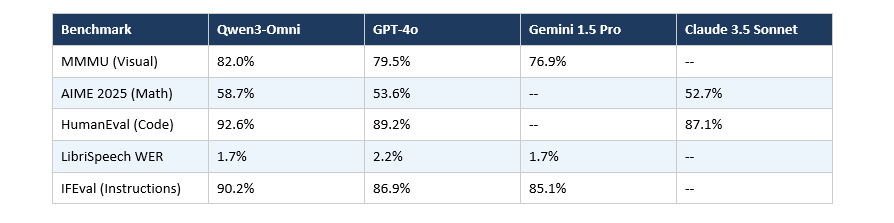
Benchmark Comparison: Qwen3.5-Omni vs Gemini vs GPT-4o
Here's where things get interesting. These are benchmark results verified across the Qwen3 and Qwen3.5-Omni family:
On the Qwen3.5-Omni-Plus specifically, the headline results against Gemini-3.1 Pro:
- General audio understanding, reasoning, recognition, and translation: Qwen3.5-Omni-Plus wins outright
- Audio-video comprehension: Matches Gemini-3.1 Pro overall
- Multilingual voice stability across 20 languages: Beats ElevenLabs, GPT-Audio, and Minimax
For document recognition, the broader Qwen3.5 family scores 90.8 on OmniDocBench v1.5, outperforming GPT-5.2 (85.7), Claude Opus 4.5 (87.7), and Gemini-3.1 Pro (88.5).
I want to be honest about one thing: the "215 SOTA results" number is a marketing claim, not a single unified benchmark. It's an aggregate across many audio, audio-video, and interaction-specific evals. What actually matters is performance on the specific benchmarks relevant to your use case. The audio numbers look strong. The broader model-level comparisons against GPT-5.2 and Claude Opus 4.5 are based on the Qwen3.5 base family, not specifically the Omni variant.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
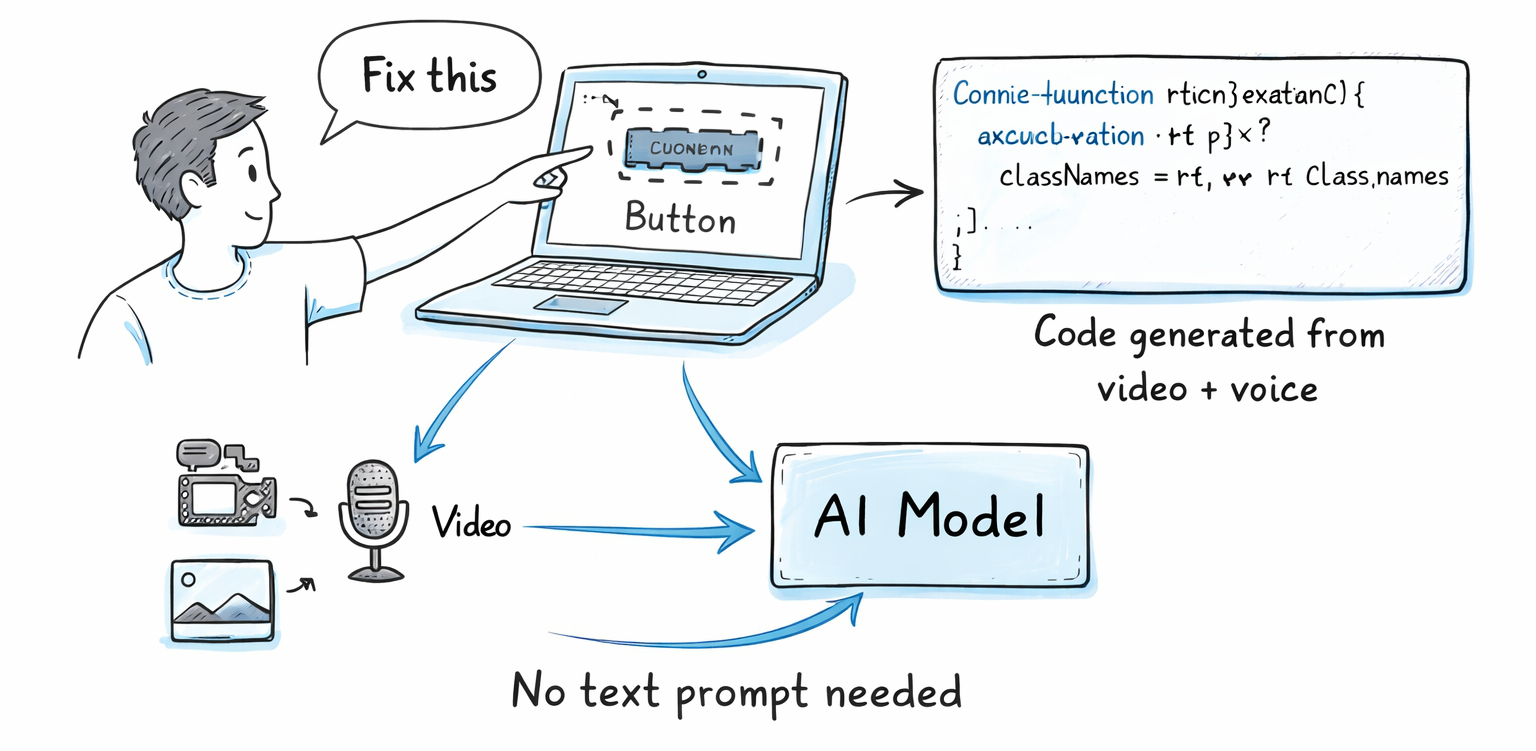
Audio-Visual Vibe Coding: What It Actually Does
Audio-Visual Vibe Coding is Qwen3.5-Omni's most distinctive new feature. The concept: you show the model a screen recording or video of a coding task, speak your intent out loud, and the model writes functional code based on what it sees and hears combined, with no text prompt required.
The idea is actually fairly profound. Instead of describing what you want in a text prompt, you demonstrate it. Point your camera at a UI bug, say "fix this," and the model processes both the visual evidence and your voice simultaneously.
In practice, this works because Qwen3.5-Omni processes audio and video in a single pass rather than transcribing speech first and then separately analyzing the video. The contextual link between what you're saying and what you're pointing at is maintained throughout the inference.
Whether this becomes a practical developer workflow or stays a cool demo depends on latency. The previous generation Qwen3-Omni Flash achieved voice response latency as low as 234 milliseconds, which is genuinely conversation-speed.
Other real-time interaction features added in this release:
- Semantic interruption: The model distinguishes between "uh-huh" mid-conversation and an actual intent to cut in, so it doesn't stop mid-thought every time there's background noise.
- Voice cloning: Generate custom voices from short reference clips.
- Real-time web search: The model can answer questions about breaking news or live data without pretending it already knows.
That last one matters more than people are giving it credit for. Most omni models are static inference engines. Baking real-time web search into the omni model means voice-first applications can actually answer current questions without a separate RAG pipeline.
Who Should Use Qwen3.5-Omni?
Qwen3.5-Omni is worth serious evaluation if you're building in one of these areas.
Voice-first applications: 113 language support plus native voice cloning and semantic interruption makes this one of the strongest open-source foundations for multilingual voice agents. DeepSeek, Mistral, and Meta's Llama don't have comparable voice-native capabilities right now.
Meeting and audio intelligence: The 10-hour context window combined with strong multilingual speech recognition (1.7% WER on LibriSpeech, matching Gemini 2.5 Pro) makes it a serious option for long-form transcription and analysis.
Video understanding: 400 seconds of 720p video at 1 FPS in a single context pass. For content moderation, video summarization, or educational content processing, that's a meaningful capability.
Multilingual markets: 113 recognition languages is unusually broad coverage. If you're building for markets where major US models have weak language support, this is a realistic alternative.
Where I'd be more cautious: complex software engineering tasks. Claude Opus 4.5 maintains an edge on SWE-bench at 80%+ compared to the Qwen3.5 family. For pure coding agent workflows, the Qwen models are strong but not definitively ahead on the hardest engineering benchmarks.
How to Access Qwen3.5-Omni Today
Demos are available now on Hugging Face and through Alibaba Cloud. Community fine-tunes have already appeared on Hugging Face following the March 30 release.
For API access, Qwen3.5-Omni-Plus and Flash are available via Alibaba Cloud's DashScope API. The Light variant can be run locally via Hugging Face.
If you're a developer who has already worked with Qwen via the OpenAI-compatible API interface, integration should be familiar. The model supports function calling and native web search baked in, which changes what's possible without external orchestration.
My Honest Take: What's Missing
I think Qwen3.5-Omni is a genuinely impressive release and the audio benchmark numbers look real. But there are things worth being skeptical about.
The "215 SOTA results" headline is a number I'd take with some skepticism. Benchmarks self-selected by the releasing lab tend to favor the releasing lab. More neutral third-party evaluations will tell a clearer story over the next few weeks.
Also, the speech recognition language count. Alibaba lists 113 languages and dialects. That last word matters. Regional dialect variants often get counted separately, which makes the number look bigger than the practical coverage. I'd want to see independent evaluations on lower-resource languages before claiming Qwen3.5-Omni as the definitive multilingual voice option.
That said, for open-source omni models specifically, the competitive gap is real. DeepSeek doesn't have this. Mistral doesn't have this. Meta doesn't have this. If you need a voice-native open model and you don't want to be locked into Google or OpenAI's API, Qwen3.5-Omni is your most serious option right now.
Want to learn how to build AI agents and apps using models like Qwen3.5-Omni?
Join Build Fast with AI's Gen AI Launchpad, an 8-week structured program to go from 0 to 1 in Generative AI.
Register here: buildfastwithai.com/genai-course
Frequently Asked Questions
What is Qwen3.5-Omni?
Qwen3.5-Omni is Alibaba's latest omnimodal AI model, released on March 30, 2026. It processes text, images, audio, and video natively in a single model pass and generates streaming speech output in real time. The Plus variant achieved 215 SOTA benchmark results across audio and audio-video tasks.
How does Qwen3.5-Omni compare to Gemini?
Qwen3.5-Omni-Plus outperforms Google's Gemini-3.1 Pro on general audio understanding, reasoning, recognition, and translation tasks, and matches Gemini-3.1 Pro on audio-video comprehension overall. On multilingual voice stability across 20 languages, it also beats ElevenLabs, GPT-Audio, and Minimax.
What languages does Qwen3.5-Omni support?
Qwen3.5-Omni supports speech recognition for 113 languages and dialects, up from 19 in the previous Qwen3-Omni generation. Speech generation covers 36 languages. The previous Flash variant achieved voice response latency as low as 234 milliseconds.
What is Audio-Visual Vibe Coding in Qwen3.5-Omni?
Audio-Visual Vibe Coding allows the model to watch a screen recording or video of a coding task and generate functional code based on both the visual content and spoken instructions simultaneously, without a text prompt. It works because Qwen3.5-Omni processes audio and video in a single model pass rather than through separate pipelines.
How long can Qwen3.5-Omni process audio or video?
All three Qwen3.5-Omni variants (Plus, Flash, Light) support a 256K token context window. In practical terms, this handles over 10 hours of continuous audio input or up to 400 seconds of 720p video at 1 frame per second with audio.
Is Qwen3.5-Omni open source?
The Light variant is available as open weights on Hugging Face. The Plus and Flash variants are accessible via Alibaba Cloud's DashScope API. The model was pre-trained on over 100 million hours of native multimodal audio-video data using the Thinker-Talker architecture with Hybrid-Attention MoE design.
What is the Thinker-Talker architecture?
Thinker-Talker is Qwen's split model architecture where the Thinker component handles multimodal reasoning and text generation, and the Talker converts those representations into streaming speech. The split allows external systems like RAG pipelines or safety filters to intervene between reasoning and speech output before it reaches the end user.
How does Qwen3.5-Omni compare to GPT-4o?
On Qwen3-Omni generation benchmarks, the model scores 82.0% on MMMU vs GPT-4o's 79.5%, 92.6% on HumanEval vs GPT-4o's 89.2%, and 1.7% word error rate on LibriSpeech vs GPT-4o's 2.2%. The Qwen3.5-Omni-Plus additionally beats GPT-Audio on multilingual voice stability across 20 languages.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
LLM Scaling Laws Explained: Will Bigger AI Models Always Win? (2026)
Kimi 2.5 Review: Is It Better Than Claude for Coding? (2026)
References
Qwen3.5-Omni Official Announcement - Alibaba Qwen, March 30 2026
Qwen3-Omni Technical Report - arXiv
Qwen3.5-Omni: Alibaba's AI Model Can Now Hear, Watch, and Clone Your Voice - Decrypt
Qwen3-Omni Review: Multimodal Powerhouse or Overhyped Promise? - Analytics Vidhya
Qwen3.5 Features, Access, and Benchmarks - DataCamp
Qwen3.5 Model Card and Deployment Guide - Hugging Face
Qwen3.5-Omni Launch Coverage - Aihola

