




In 2023, open-source AI was two years behind the frontier. In 2024, one year. In 2025, six months. In April 2026, a Chinese open-source model claimed the top score on SWE-Bench Pro, beating GPT-5.4 and Claude Opus 4.6 on the hardest software engineering benchmark in AI. That model is GLM-5.1. And it did not arrive alone.
Within 75 days, three Chinese labs shipped flagship coding models. Qwen 3.6 Plus landed on OpenRouter on March 30 -- free, 1 million token context, no API key friction. Kimi 2.5 came from Moonshot AI in January 2026 -- 100 parallel AI agents, $0.60 per million tokens, and the highest LiveCodeBench score of any model tested. GLM-5.1 dropped on April 7, MIT-licensed, running on zero Nvidia hardware, capable of working autonomously for 8 continuous hours.
I ran all three through real coding tasks and benchmarks. If you are deciding which Chinese AI model belongs in your stack right now, this is the breakdown.
1. Why These Three Models Matter Right Now
Three Chinese AI labs released flagship coding models within 75 days of each other. That cadence is not accidental. Alibaba, Z.ai, and Moonshot AI are all racing to capture Western developer adoption before the next wave of proprietary releases from OpenAI, Anthropic, and Google.
What makes this race worth your attention as a developer: all three models are either free, open-source, or dramatically cheaper than the US frontier labs. All three score within a narrow band of Claude Opus 4.6 on real-world coding benchmarks. And all three are being actively adopted by engineering teams tired of $5 to $15 per million token invoices.
For context on where these models sit in the broader April 2026 landscape, our roundup of best AI models April 2026 covers the full competitive picture across both Chinese and Western labs.
The honest take: None of these models replaces Claude Opus 4.6 or GPT-5.4 for every single use case. But for specific workflows -- agentic coding, frontend generation, long-context document reasoning -- one of these three is almost certainly the right tool at a fraction of the cost. The job is figuring out which one matches your actual workflow.
2. Full Specs: Side-by-Side Comparison
Here is every specification that matters for a developer evaluation, in one place.
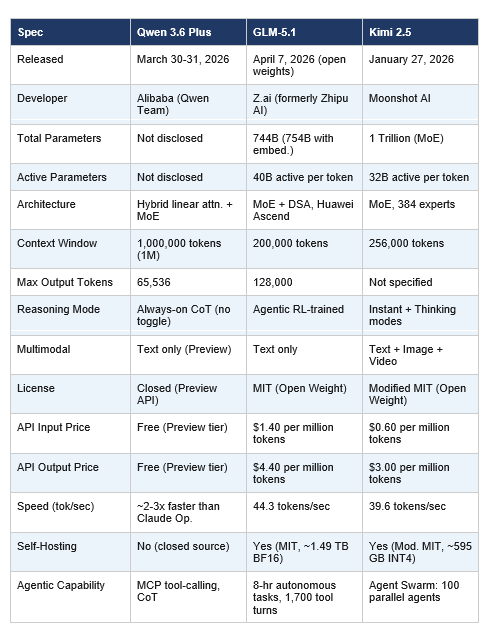
3. Coding Benchmarks: The Real Numbers
Benchmarks are imperfect, but they are the most consistent starting point for model evaluation. Here is every major coding and reasoning benchmark with scores for all three models, plus Claude Opus 4.6 as the reference point.
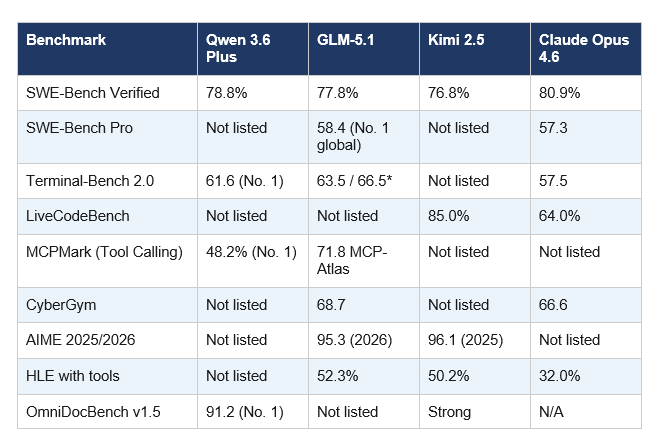
*GLM-5.1 Terminal-Bench: 63.5 with Terminus-2 framework; 66.5 when scaffolded with Claude Code harness.
What the numbers actually say: All three cluster within 2 percentage points on SWE-Bench Verified (76.8 to 78.8%). All three trail Claude Opus 4.6 by 2 to 4 points on that specific benchmark. But GLM-5.1 beats Claude on SWE-Bench Pro, the harder, more practical evaluation. Kimi 2.5 beats Claude by 21 points on LiveCodeBench. Qwen 3.6 Plus leads every model on MCPMark for tool-calling reliability. No single model wins everywhere. That is the real story, and it is why model routing beats model loyalty in 2026.
4. Qwen 3.6 Plus: The Free 1M-Context Agentic Coder
Qwen 3.6 Plus Preview is available free on OpenRouter right now, and that single fact reshapes the evaluation. When cost is zero, the question shifts from 'is it worth paying for?' to 'is it good enough to use?' The answer is yes -- for specific workflows.
The 1-million-token context window is the genuine differentiator. In practical terms: 1M tokens holds an entire medium-sized codebase, its documentation, its test suite, and your full conversation history in one prompt. No chunking. No retrieval workarounds. No 'how do I split this up' engineering overhead. For large-codebase analysis and multi-file refactoring agents, this removes an entire category of architecture complexity.
The always-on chain-of-thought is a deliberate design choice. No thinking mode toggle. Claude 3.5's biggest production complaint was overthinking on simple tasks. Qwen 3.6 Plus fixes that with a new hybrid architecture that is more decisive, reaches conclusions faster, and maintains higher output stability across long agent sessions. On Terminal-Bench 2.0, Qwen 3.6 Plus scores 61.6 versus Claude Opus 4.6 at 57.5 -- currently the top score on that benchmark. On MCPMark for tool-calling reliability, it leads all models at 48.2%.
For a full technical breakdown of architecture, context window handling, and benchmark methodology, see the dedicated Qwen 3.6 Plus full review.
The catch: This is a preview. Alibaba collects your prompt and completion data during the free period. No production SLA. Time-to-first-token averages 11.5 seconds on the free tier, which is painful for interactive workflows. Full paid pricing is not yet announced. Use it aggressively for development, testing, and prototyping. Do not route production traffic with sensitive data through the free preview endpoint.
5. GLM-5.1: The Open-Source Model That Beat Claude on SWE-Bench Pro
On April 7, 2026, Z.ai released GLM-5.1 open weights under the MIT license and posted a 58.4 on SWE-Bench Pro -- the world's top score. That cleared GPT-5.4 at 57.7 and Claude Opus 4.6 at 57.3. First time an open-source model has claimed the top position on a major real-world software engineering benchmark.
GLM-5.1 is a post-training refinement of GLM-5, not a new architecture. Same 744-billion-parameter Mixture-of-Experts base. Same 40 billion active parameters per token. Same 200K context window and DeepSeek Sparse Attention. What Z.ai changed is the RL pipeline: they retargeted post-training at coding task distributions specifically, running multi-task supervised fine-tuning followed by reasoning RL, agentic RL, and general RL with cross-stage distillation. The result was a 28 percent improvement on Z.ai's internal coding eval in a single point release.
The long-horizon capability is where GLM-5.1 separates itself most clearly. Z.ai's documentation shows the model can work autonomously for up to 8 hours on a single task -- planning, executing, testing, and iterating across up to 1,700 tool-use turns without human intervention. In a documented test, GLM-5.1 built a complete Linux desktop environment from scratch in 8 hours. That is not a chatbot behaviour. That is a software engineer running overnight.
CyberGym at 68.7 is the benchmark that deserves more attention. It tests 1,507 real-world tasks under adversarial conditions. GLM-5.1 scores nearly 20 points above GLM-5 there -- and edges past Claude Opus 4.6 at 66.6. For teams building security tooling, that number matters.
For a full head-to-head benchmark analysis of GLM-5.1 against Claude Opus 4.6 on coding tasks, the GLM-5.1 vs Claude Opus 4.6 review is the most detailed breakdown on the site.
Critical caveat: The SWE-Bench Pro numbers are self-reported by Z.ai as of April 2026. No independent third-party lab has published corroborating results yet. GLM-5's SWE-Bench Verified scores held under independent testing, so Z.ai has a solid track record. But treat these as strong preliminary claims, not verified facts. Also -- GLM-5.1 is text-only. No image, audio, or video. If your workflow involves visual coding or screenshot-to-code generation, you need a different model.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
6. Kimi 2.5: Agent Swarm, Visual Coding and 8x Cheaper Than Claude
Moonshot AI released Kimi 2.5 on January 27, 2026. The headline numbers were immediately hard to ignore: 76.8% on SWE-Bench Verified, 96.1% on AIME 2025, and 50.2% on Humanity's Last Exam with tools. That HLE score beats Claude Opus 4.5 at 32.0% and GPT-5.2 High at 41.7%. The price: $0.60 per million input tokens -- 8x cheaper than Claude Opus 4.6.
Agent Swarm is the standout feature with no equivalent in any other model on this list. Standard AI processes tasks sequentially. Kimi 2.5's Agent Swarm deploys an orchestrator that decomposes a complex task into parallelizable subtasks, spins up to 100 specialized sub-agents simultaneously, and runs them in parallel. Moonshot AI's internal January 2026 data shows 4.5x faster completion on wide-search tasks and an 80 percent reduction in end-to-end runtime compared to sequential single-agent approaches.
The visual-to-code capability is genuinely useful, not a demo feature. Kimi 2.5 takes a UI screenshot and generates working React or Vue code from it. It reasons over video to track changes across frames. On LiveCodeBench it leads the entire field at 85.0% versus Claude Opus 4.6 at 64.0%. That 21-point gap on competitive programming is the largest performance difference between any two models in this comparison.
For teams with Chinese-English bilingual workflows, Kimi carries a real edge. It produces natural-sounding Chinese without the over-formality that shows up in Claude's and GPT's Chinese output. In short snippets the difference is subtle. At scale across a bilingual content pipeline, it is meaningful.
For a three-week hands-on testing report covering Kimi 2.5 on real coding workflows including frontend generation, Agent Swarm, and API cost analysis, the Kimi K2.5 vs Claude for coding review at is the most thorough independent evaluation available.
The real downsides: At 39.6 tokens per second, Kimi 2.5 is the slowest of the three models. It is also verbose -- community testing showed usage surging past 50 billion tokens per day during Kilo Code's free trial week, with verbosity diluting the pricing advantage from input caching. And for complex backend architecture where you need SWE-Bench Verified reliability above 80%, Claude Opus 4.6 still leads. Kimi's sweet spot is frontend work, visual coding, batch operations, research tasks, and any workflow where Agent Swarm's parallelism changes the math.
7. Which Model Should You Actually Use?
The right answer is not a single winner. It is a routing strategy. Each of these three models is genuinely the best choice for specific workflows.
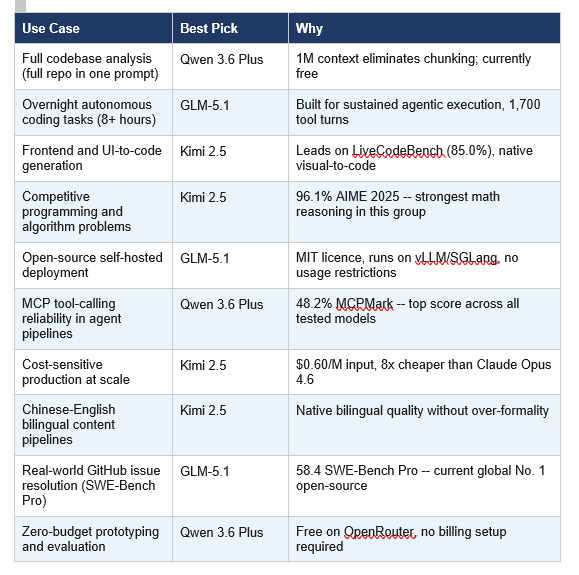
My personal workflow in April 2026: Qwen 3.6 Plus for any task where I need to load an entire codebase into context. GLM-5.1 API for overnight autonomous engineering tasks. Kimi 2.5 for frontend work and anything that starts from a screenshot or a design file. Claude Opus 4.6 for production code reviews and anything where I genuinely cannot afford a hallucination.
If you want a broader decision framework for matching AI models to specific task types across the full 2026 model landscape, the best AI model per task 2026 guide covers the full routing logic.
Four models. Each doing the job it is actually best at. Model routing is the winning strategy in 2026, not model loyalty.
Frequently Asked Questions
Which Chinese AI model is best for coding in 2026?
It depends on the task. GLM-5.1 leads on SWE-Bench Pro (58.4 vs Claude Opus 4.6's 57.3) and long-horizon autonomous tasks up to 8 hours. Kimi 2.5 leads on LiveCodeBench (85.0%) and frontend and visual coding tasks. Qwen 3.6 Plus leads on context window (1M tokens) and MCP tool-calling reliability (48.2% MCPMark). A routing strategy using all three outperforms committing to a single model for most engineering teams.
Is GLM-5.1 open source?
Yes. GLM-5.1 was released on April 7, 2026 under the MIT licence with weights on HuggingFace at huggingface.co/zai-org/GLM-5.1. MIT is one of the most permissive open-source licences available -- no commercial restrictions, full right to inspect, modify, and redistribute. Self-hosting requires significant GPU infrastructure: approximately 1.49TB for the BF16 version, or around 595GB using INT4 quantization. Supported runtimes include SGLang, vLLM, xLLM, and KTransformers.
Is Qwen 3.6 Plus free to use?
As of April 2026, Qwen 3.6 Plus Preview is free via OpenRouter using the model string qwen/qwen3.6-plus-preview:free. The preview tier collects prompt and completion data for model improvement -- avoid sending sensitive or proprietary content. The paid general-availability pricing has not been announced. Alibaba's DashScope API offers paid access to the full production model.
How does Kimi 2.5 compare to GLM-5.1 for coding?
Kimi 2.5 scores 76.8% on SWE-Bench Verified versus GLM-5.1's 77.8% -- a narrow 1-point gap. Kimi leads on LiveCodeBench (85.0% vs not tested for GLM-5.1) and visual-to-code generation. GLM-5.1 leads on SWE-Bench Pro (58.4), long-horizon autonomous execution, and CyberGym adversarial tasks (68.7 vs Kimi's score not listed). Kimi is significantly cheaper at $0.60/M input versus GLM-5.1's $1.40/M, and supports multimodal input. GLM-5.1 is text only.
What is Kimi 2.5 Agent Swarm?
Agent Swarm is Kimi 2.5's capability to coordinate up to 100 specialized AI sub-agents running in parallel on a single complex task. An orchestrator decomposes the task into parallelizable subtasks and delegates them to domain-specific agents simultaneously. Moonshot AI's January 2026 testing reported 4.5x faster task completion and 80% reduction in end-to-end runtime compared to sequential single-agent approaches. Agent Swarm is currently in research preview with free credits for high-tier paid users on kimi.com.
What is the context window of Qwen 3.6 Plus?
Qwen 3.6 Plus Preview supports a 1,000,000-token (1M) context window -- equivalent to approximately 2,000 pages of text. Maximum output length per response is 65,536 tokens. This is the largest context window among all three models in this comparison, enabling full codebase ingestion in a single prompt without chunking or retrieval architecture.
How much does GLM-5.1 cost via API?
GLM-5.1 API pricing as of April 2026 is $1.40 per million input tokens and $4.40 per million output tokens. Cached input tokens cost $0.26 per million. During peak hours (14:00 to 18:00 Beijing Time daily), usage is billed at three times the standard rate, though a promotional standard 1x billing applies for off-peak usage through April 2026. GLM Coding Plan subscriptions start at $3/month (promotional rate).
Can any of these models be run locally?
GLM-5.1 and Kimi 2.5 are both open-weight models that support local deployment. GLM-5.1 requires approximately 1.49TB for the BF16 version (about 595GB FP8 quantized) and a minimum of 8x H100 GPUs for practical inference -- it supports SGLang, vLLM, and KTransformers. Kimi 2.5 ships in native INT4 precision at approximately 595GB, runnable on a single 24GB GPU with RAM offloading at around 10 tokens per second using Unsloth's dynamic 1.8-bit quant. Qwen 3.6 Plus is a closed-source API model with no local deployment option.
Recommended Reading
Related Cookbooks
References
Qwen Team (Alibaba) -- Qwen 3.6 Plus Preview on OpenRouter (March 2026):
Z.ai Developer Documentation -- GLM-5.1 Overview (April 2026):
Moonshot AI -- Kimi K2.5 Technical Blog (January 2026):
HuggingFace -- GLM-5.1 Model Card, MIT Licence:
HuggingFace -- Kimi K2.5 Model Card, Modified MIT:
Artificial Analysis -- Kimi K2.5 Intelligence and Performance Index:
Puter Developer -- Qwen 3.6 Plus Benchmark Data:
VentureBeat -- GLM-5.1 Tops SWE-Bench Pro (April 2026):
OfficeChai -- China Z.ai GLM-5.1 Beats US Models on SWE-Bench Pro:
Renovate QR Research -- Qwen 3.6 Plus Full Review and Benchmarks (April 2026):

