





Four AI agents - Grok, Harper, Benjamin, and Lucas - now argue with each other inside every query you send. They cross-check, debate, fact-check, and refuse to hand you a final answer until they've reached internal consensus. One of them, Lucas, exists purely to disagree with the others.
That's Grok 4.20 Beta. And I've been testing all three variants - Non-Reasoning, Reasoning Preview, and Multi-Agent Beta - since launch. Here's what actually matters and what the hype is missing.
1. What Is Grok 4.20 Beta? (And Why the Name Matters)
Grok 4.20 Beta is xAI's latest AI model, publicly launched on February 17, 2026, across grok.com, iOS, and Android simultaneously - no staged rollouts, no waitlists. It's the fastest iteration xAI has shipped, arriving just three months after Grok 4.1's November 2025 release.
The version number, 4.20, is classic Elon Musk. It's a deliberate internet culture wink. But the engineering underneath it is dead serious.
The headline changes from Grok 4.1 are two-fold:
- Rapid Learning Architecture - Unlike every previous Grok version, 4.20 updates its own capabilities weekly based on real-world usage. You don't download an update. The model you use today will be meaningfully different from the one you used a month ago. Automatically.
- Native Multi-Agent Collaboration - This is the architecture shift. Instead of a single model chain-of-thought, four specialized AI agents work in parallel, debate each other's outputs, and only synthesize a final answer after internal peer review.
Three API variants shipped with it: Non-Reasoning, Reasoning Preview, and Multi-Agent Beta. The distinctions between them are not cosmetic - they serve entirely different use cases and come with meaningfully different performance profiles.
My honest take: the Rapid Learning Architecture is the underrated feature. A model that compounds improvements weekly in production is a fundamentally different product than a static one. Everyone's talking about the agents. I'd watch the learning loop.
2. The Three Grok 4.20 Variants Explained
Grok 4.20 isn't a single model. It's a family of three variants, each designed for a different kind of task. Here's the clean breakdown:
Grok 4.20 Beta Non-Reasoning
Released as a stable beta on March 9, 2026 (build 0309), this is the speed-first variant. It gives you direct answers without chain-of-thought reasoning tokens - no internal "thinking" step before the response.
What that means in practice: fast outputs, lower cost per call, and still capable of handling most tasks you'd throw at a frontier model. It scores 30 on the Artificial Analysis Intelligence Index - above average for non-reasoning models in its price tier (the median is 21). It generates output at 232.5 tokens per second, compared to the category median of 54.8 t/s. Time-to-first-token is 0.54 seconds (category median: 1.49 seconds).
One honest warning: this variant is verbose. When evaluated on the Intelligence Index, it generated 30 million output tokens against a category median of 4 million. If you're paying per output token, that verbosity adds up fast.
Grok 4.20 Beta Reasoning Preview
This is the deep-thinker variant. With reasoning enabled, Grok 4.20 scores 48 on the Artificial Analysis Intelligence Index - a meaningful 6-point jump over Grok 4. It's not at the top of the leaderboard (Gemini 3.1 Pro Preview and GPT-5.4 both score 57), but the gap is narrowing.
The reasoning mode processes extended chain-of-thought before responding. That means slower outputs but notably stronger performance on complex logic, multi-step math, scientific reasoning, and anything where getting the first answer wrong is expensive. One important xAI note: there is no non-reasoning fallback when Reasoning mode is active - it's always on for this variant.
Grok 4.20 Multi-Agent Beta
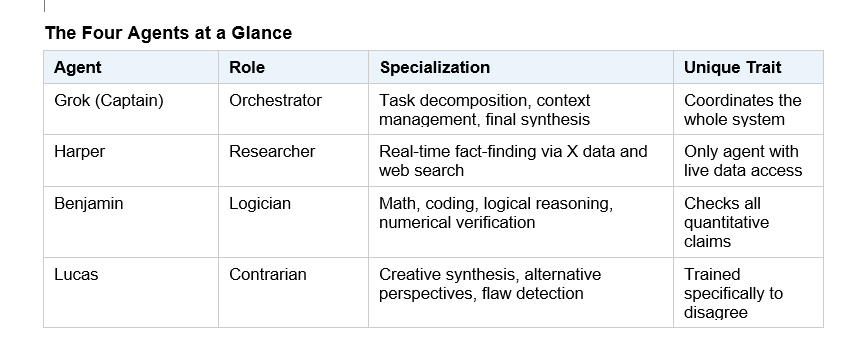
This is the architectural flagship. Four specialized agents - Grok (Captain/coordinator), Harper (research and fact-checking via real-time X data), Benjamin (logic, math, and coding), and Lucas (creative synthesis and built-in contrarianism) - run in parallel on every query.
The workflow has four phases: task decomposition by Grok, parallel analysis by all four agents, internal debate and peer review, and finally aggregated output. The internal debate phase is where the hallucination reduction happens. Cross-agent verification drops the hallucination rate from approximately 12% down to roughly 4.2% - a 65% improvement over single-model baselines.
For tougher tasks, a "Heavy" mode scales this to 16 agents. Elon Musk confirmed on March 12, 2026 that Grok 4.20 Heavy (Beta 2) is "extremely fast for deep analysis" - the first direct performance characterization from xAI's CEO since launch.
The comparison that helps most: Non-Reasoning is your fast, cost-efficient everyday driver. Reasoning Preview is for problems where depth matters more than speed. Multi-Agent Beta is for complex multi-perspective work - research, strategy, scientific writing - where a single model's blind spots are a liability.
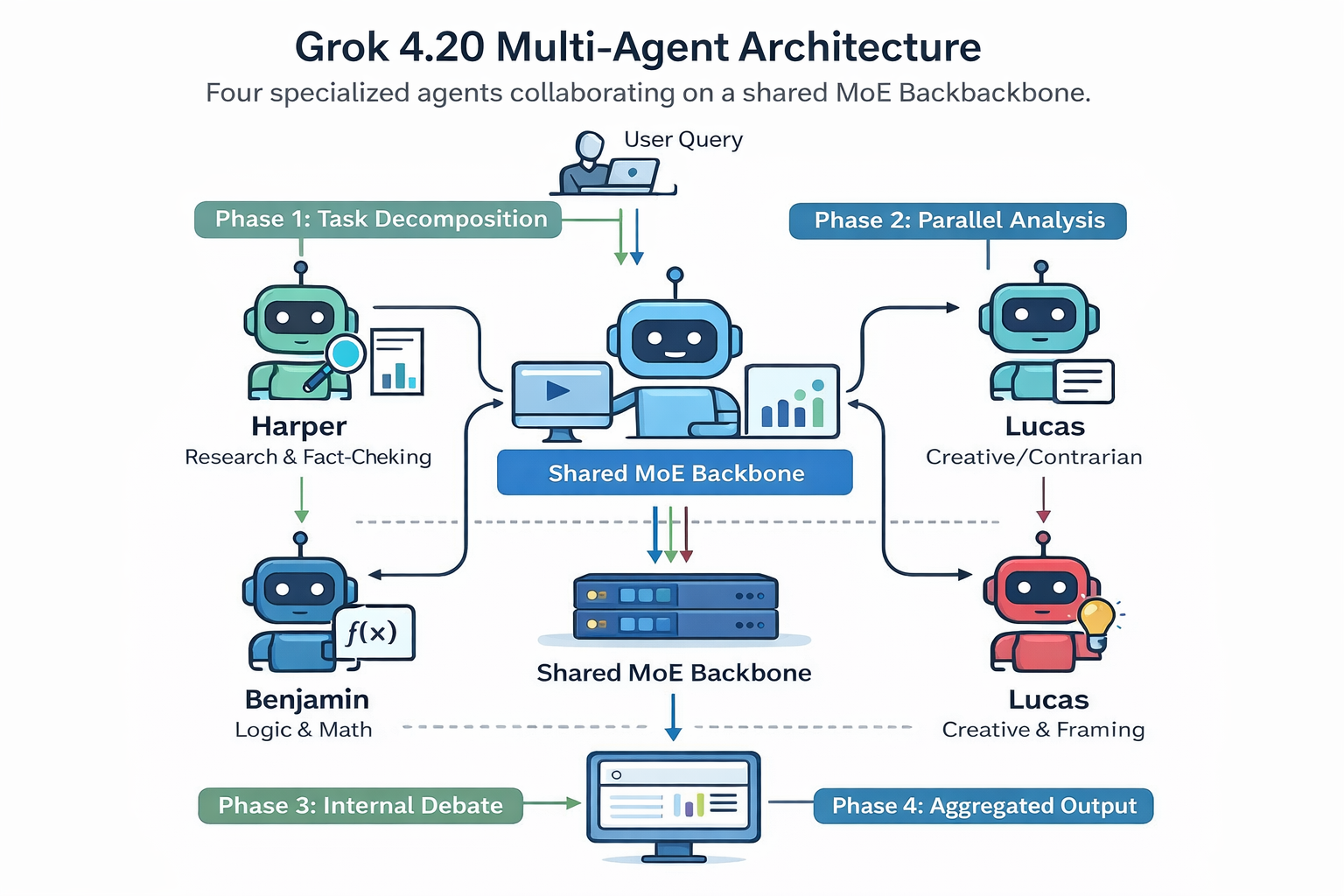
3. How the 4-Agent Multi-Agent System Actually Works
The four-agent architecture isn't a marketing frame on top of a single model. The agents are distinct specialized sub-models running on a shared Mixture-of-Experts (MoE) backbone. Here's the actual workflow:
Phase 1: Task Decomposition
When your query arrives, Grok the Captain analyzes its structure and breaks it into parallel sub-tasks. Research questions go to Harper. Logic and calculation goes to Benjamin. Creative framing and contrarian pressure goes to Lucas.
Phase 2: Parallel Analysis
All four agents work simultaneously. Harper pulls real-time data from X (formerly Twitter) and the web. Benjamin constructs and verifies logical chains. Lucas actively looks for flaws in the other agents' emerging conclusions. Grok maintains overall context.
Phase 3: Internal Debate and Peer Review
This is the key innovation. If Benjamin's mathematical conclusion contradicts a fact Harper found, they surface the conflict explicitly. The agents iterate, challenge, and correct each other before anything reaches you. Lucas's contrarian role means there's always at least one agent whose job is to poke holes in the consensus - which is how the hallucination rate gets forced down.
Phase 4: Aggregated Output
Grok synthesizes a final response only after internal consensus is reached. The output is typically more structured and better-reasoned than what a single model would produce on the same query.
A real example of what this enables: a user on X tasked 16 Grok 4.20 Heavy agents with building a complete, library-free HTML page featuring a full-screen WebGL GLSL shader. The result worked on the first try. Single-model systems typically require multiple iterations to get to the same place.
The numbers that back this up: the AA Omniscience test measures factual accuracy under uncertainty - specifically, how often a model admits it doesn't know versus hallucinating an answer. Grok 4.20 hit a 78% non-hallucination rate on this benchmark. That's a record, according to Artificial Analysis. No other model tested has hit it. It's the clearest quantitative signal that the multi-agent peer-review approach is working.
The Four Agents at a Glance
4. Grok 4.20 Beta Benchmarks vs GPT-5, Claude Opus 4.6, and Gemini 3.1 Pro
The benchmark picture for Grok 4.20 is nuanced, and I'd be misleading you if I pretended it was simpler than it is. Here's the honest summary:
On overall intelligence scores, Grok 4.20 is competitive but not leading. With reasoning enabled, it scores 48 on the Artificial Analysis Intelligence Index. Gemini 3.1 Pro Preview and GPT-5.4 both score 57. That's a real gap. On raw benchmark performance across most test suites, Grok 4.20 is third or fourth in the current frontier tier.
On factual reliability, Grok 4.20 is currently best in class. The 78% AA Omniscience non-hallucination rate is a record. This is the benchmark that matters most for real-world production use - a model that's slightly less "intelligent" but significantly less likely to confidently fabricate an answer is often more useful.
For context, here's how the major current models compare on the benchmarks that matter for most developers and researchers:
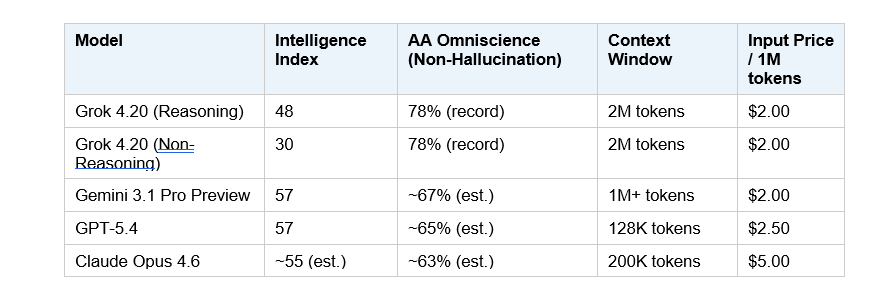
Note: Intelligence Index scores from Artificial Analysis (March 2026). Omniscience estimates for competitors based on published partial data. Prices reflect median API provider rates.
On coding specifically - SWE-bench Verified is the benchmark most developers care about - Grok 4 (the base model underlying 4.20) scored 75%, GPT-5 hit 74.9%, Claude Opus 4.6 reached 72.5% on SWE-bench tasks. Gemini 3.1 Pro trails at 67.2%. For coding workflows, the gap between the top three (Grok, GPT-5, Claude) is small enough that API pricing and integration convenience often make a bigger practical difference than raw score differences.
My read: Grok 4.20 is not the most intelligent model on the market right now. But it might be the most reliable one. In a world where AI gets embedded into production systems - where a wrong answer doesn't just look bad but causes real downstream damage - hallucination rate is the benchmark that actually matters. Grok 4.20 has a real, measurable advantage there.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
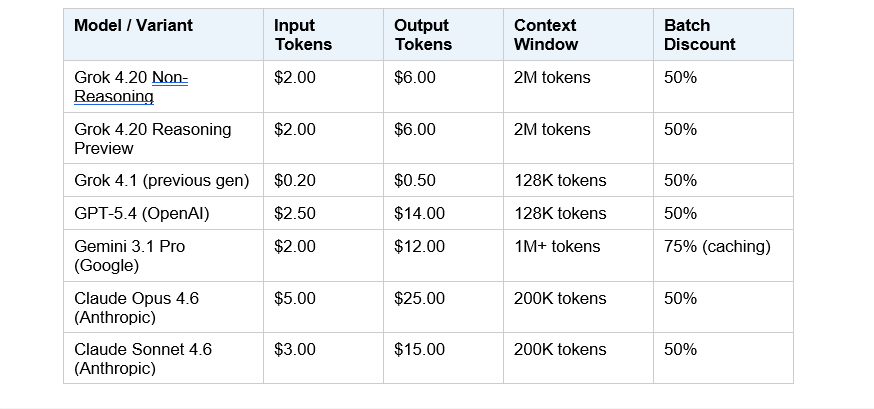
5. Grok 4.20 API Pricing Breakdown (2026)
Grok 4.20 is the cheapest Western frontier model by input token cost right now. Here's the full picture:
API Pricing (Per 1 Million Tokens)
Consumer Subscription Plans
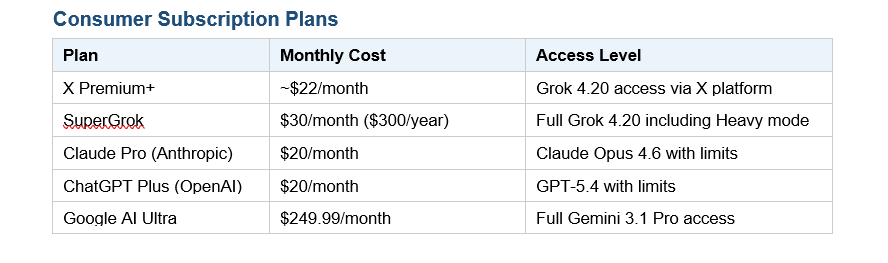
At $2.00 per million input tokens, Grok 4.20 is priced identically to Gemini 3.1 Pro on inputs but significantly cheaper on outputs ($6.00 vs $12.00 per million). Claude Opus 4.6 at $5.00/$25.00 is the premium option - you're paying for coding depth and reliability, not raw speed.
One important caveat: API access for Grok 4.20 Multi-Agent Beta is still listed as "coming soon" as of March 2026. The agent architecture is currently consumer-facing only. Developers building on the API are working with the Non-Reasoning and Reasoning variants for now.
Bottom line on pricing: if you're cost-sensitive and running high volumes, Grok 4.20 Non-Reasoning at $2/$6 is the best bang-per-token among frontier Western models right now. If you need the highest reliability for production, the 78% Omniscience score makes the $2 input price look very reasonable.
6. Grok 4.20 vs Claude Opus 4.6 vs GPT-5.4 vs Gemini 3.1 Pro - Full Comparison
No single model dominates across all tasks in 2026. The current frontier is genuinely competitive, and the right choice depends entirely on what you're actually building. Here's where each model actually wins:
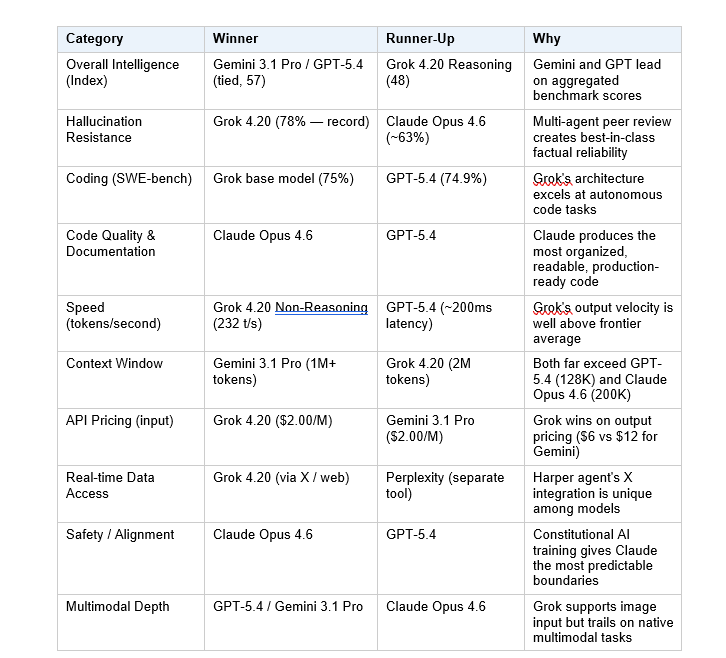
The developer community's own verdict is interesting. Reddit threads from early 2026 consistently show Claude (particularly Opus 4.6 and Claude Code) as the leading choice for software engineering, specifically for production-grade Next.js applications, full-stack workflows, and anything requiring well-organized, maintainable code. Grok 4.20 is getting cited as the daily driver for research and analysis tasks, where its lower hallucination rate and real-time X data access create a real edge. GPT-5.4 holds its position as the most versatile generalist.
The honest take nobody says out loud: Claude is 2–3x more expensive than Grok per token. For coding workflows where the quality difference is real but marginal, the economics will push more developers toward Grok over time - especially once Multi-Agent API access opens up.
7. Who Should Use Which Grok 4.20 Variant?
The variant you choose should match the nature of the task, not just your preference. Here's how I'd route different use cases:
Use Grok 4.20 Non-Reasoning When:
- You need fast responses at scale (232+ tokens/second output)
- The task is straightforward: summarization, classification, content generation, basic Q&A
- Cost per call matters - $2/$6 per million tokens is one of the best rates at frontier quality
- You're building a high-volume API integration and latency is a constraint (0.54s TTFT)
- You want to prototype quickly before committing to a heavier reasoning pipeline
Use Grok 4.20 Reasoning Preview When:
- The problem involves multi-step logic, complex math, or scientific reasoning
- Getting the first answer right matters more than getting it fast
- You're working on tasks that require extended chain-of-thought - competitive math, advanced coding problems, strategic planning
- You need the hallucination resistance of 4.20 with deeper analytical depth
Use Grok 4.20 Multi-Agent Beta When:
- The task has multiple dimensions that benefit from parallel expert analysis - research reports, comprehensive market analysis, technical white papers
- You need built-in fact-checking and peer review as part of the output process
- Real-time X / web data matters for accuracy (Harper's specialization)
- You're building or generating outputs where one model's blind spots could cause downstream problems
- You have a SuperGrok or X Premium+ subscription and want to push what's possible today
And if you're not sure which to use: start with Non-Reasoning for any task under 5 minutes of human effort. If the output quality isn't meeting your standard, step up to Reasoning. Reserve Multi-Agent for the 20% of tasks where comprehensive accuracy actually justifies the extra processing time.
8. What's Coming Next: Grok 4.20 Beta 3 and Beyond
xAI is moving fast. As of March 12, 2026, Elon Musk confirmed that Beta 3 is already in active development, with "many fixes and functionality gains" promised. No specific timeline was given, but the Beta 1 to Beta 2 gap was 14 days (Feb 17 to Mar 3). Expect Beta 3 within similar range.
Beta 2 (March 3, 2026) already addressed five specific reliability issues from the initial launch:
- Improved instruction following on multi-step prompts
- Reduced capability hallucination (where the model claims it can do something it can't)
- Better LaTeX and scientific text rendering
- More reliable image search integration
- Improved multi-image display handling
The outstanding bottleneck is API access for the Multi-Agent Beta. As of mid-March 2026, the 4-agent system is consumer-facing only. xAI hasn't published a timeline for developer API access, but it's the feature the developer community is most waiting for. When that gate opens, expect a fast-moving wave of third-party integrations.
There's also the Grok 5 question. Reports from early 2026 have speculated about a model with up to 6 trillion parameters - though xAI hasn't confirmed timelines or architecture. The Rapid Learning Architecture of 4.20 suggests that whatever "Grok 5" becomes, the iteration approach is changing. xAI is building a model that improves in production, not just in training runs.
What I'm watching: The Rapid Learning Architecture is the real long-term play here. Every week of real-world usage compounds into a better model without a version update. Six months from now, the Grok 4.20 you're using will be meaningfully smarter than the one that launched in February - and that's a fundamentally different product philosophy than any of its competitors are running.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. FAQ: Everything People Are Asking About Grok 4.20
What is Grok 4.20 Beta?
Grok 4.20 Beta is xAI's latest AI model family, launched in public beta on February 17, 2026. It introduces a native 4-agent multi-agent architecture where specialized AI agents named Grok, Harper, Benjamin, and Lucas work simultaneously on complex queries. It also introduces a Rapid Learning Architecture that updates the model's capabilities weekly based on real-world usage, without requiring a manual version update.
What is the difference between Grok 4.20 Non-Reasoning and Reasoning?
Non-Reasoning gives direct, fast answers without chain-of-thought processing -output speed is 232 tokens/second with 0.54-second time-to-first-token. Reasoning Preview adds an extended internal thinking phase before responding, producing more accurate answers on complex logic, math, and multi-step problems. Non-Reasoning scores 30 on the Artificial Analysis Intelligence Index; Reasoning scores 48. Non-Reasoning is cheaper per call due to fewer tokens generated on the reasoning step.
How does Grok 4.20's Multi-Agent Beta work?
Grok 4.20 Multi-Agent Beta uses four specialized AI agents running in parallel on a shared MoE backbone. Grok the Captain decomposes the query, Harper researches with real-time X and web data, Benjamin handles logic and math, and Lucas provides contrarian analysis to catch errors. They debate internally before synthesizing a final answer. This peer-review mechanism reduces hallucinations from approximately 12% to roughly 4.2%, according to benchmark data.
What is Grok 4.20 Heavy mode?
Grok 4.20 Heavy mode scales the multi-agent system from 4 agents to 16 agents for more demanding tasks. Available to SuperGrok and Heavy subscribers, it applies the same parallel processing and peer-review workflow at greater depth and breadth. Elon Musk described Grok 4.20 Heavy (Beta 2) as "extremely fast for deep analysis" on March 12, 2026.
How does Grok 4.20 compare to Claude Opus 4.6?
Grok 4.20 Reasoning scores 48 on the Artificial Analysis Intelligence Index vs Claude Opus 4.6's estimated 55. Claude leads on coding quality, documentation, and production-ready software engineering tasks. Grok 4.20 leads on hallucination resistance (78% vs ~63% Omniscience score) and is significantly cheaper - $2/$6 per million tokens vs $5/$25 for Claude Opus 4.6. For high-volume use cases where reliability matters, Grok's price-to-reliability ratio is currently the strongest in the frontier tier.
How does Grok 4.20 compare to GPT-5.4?
GPT-5.4 and Gemini 3.1 Pro Preview both outscore Grok 4.20 Reasoning on the Intelligence Index (57 vs 48). However, Grok 4.20 leads on hallucination resistance, is cheaper on input tokens ($2 vs $2.50) and significantly cheaper on output tokens ($6 vs $14 per million). GPT-5.4 has a much smaller context window (128K vs Grok 4.20's 2M tokens). For real-time data needs, Grok's X integration is a capability GPT-5.4 doesn't match natively.
What is the Grok 4.20 API price?
Grok 4.20 Beta Non-Reasoning and Reasoning Preview are both priced at $2.00 per million input tokens and $6.00 per million output tokens, based on median rates across API providers as of March 2026. A 50% batch API discount is available. API access for the Multi-Agent Beta variant is still listed as "coming soon." Consumer access requires SuperGrok ($30/month or $300/year) or X Premium+ subscription.
Is Grok 4.20 available for free?
Grok 4.20 Beta requires either a SuperGrok subscription ($30/month) or X Premium+ membership for consumer access. There is no confirmed free tier for Grok 4.20 at this time. API access is billed per token. Previous Grok models had limited free usage through X - xAI has not confirmed whether that will extend to 4.20 beyond the beta period.
What is the Grok 4.20 context window?
Grok 4.20 maintains the same 2-million token context window as Grok 4.1. This is the largest context window among Western frontier AI models, exceeding Gemini 3.1 Pro (1M+ tokens), Claude Opus 4.6 (200K tokens), and GPT-5.4 (128K tokens). In Multi-Agent mode, the 2M token limit is shared across all four agents.
When will Grok 4.20 API access for Multi-Agent Beta open?
As of March 14, 2026, xAI has not published a specific timeline for Multi-Agent Beta API access. The current developer API offers Non-Reasoning and Reasoning Preview variants. Grok 4.20 Beta 3 is confirmed to be in development, with Elon Musk citing it on March 12, 2026 - API access may arrive alongside or shortly after that release.
Does Grok 4.20 support image input?
Yes. Grok 4.20 Beta 0309 (Non-Reasoning) supports both text and image input, with text output. Accepted image formats are JPG/JPEG and PNG. The model can analyze, describe, and answer questions about images. Multi-image display was specifically improved in Beta 2 (March 3, 2026), addressing stability issues from the initial launch.
Recommended Blogs:
- GPT-5.4 vs Gemini 3.1 Pro
- GPT-5.4 Review 2026
- GPT-5.3-Codex vs Claude vs Kimi
- Cheap Claude Alternative for AI Agents
- 6 AI Launches Feb 2026
6. Grok AI Image Safety Crisis Jan 2026
References & Sources:

