





Five days. Four frontier-class releases. The leaderboard you bookmarked three weeks ago is already wrong.
Between April 20 and April 24, 2026, the AI model landscape changed faster than it has at any point this year. Kimi K2.6 dropped on April 20 and immediately beat GPT-5.4 on SWE-Bench Pro at $0.60 per million tokens — a price point that should not support that level of performance. GPT-5.5 landed April 23 at 88.7% SWE-bench Verified, claiming the coding crown. DeepSeek V4 reset the price floor to $0.14 per million tokens on April 24. And Grok 4.3 quietly went live on April 17 behind a $300/month paywall. I covered the April 5 roundup three weeks ago. That post is now three generations stale. This is the update.
1. Why the April 20–26 Wave Changes Everything
The April 20–26 release window is the single densest five-day stretch of frontier model launches in 2026. Not the most hyped — the most impactful. Three separate models claimed the #1 spot on different benchmarks within 120 hours of each other. The price floor for frontier-adjacent API performance dropped by a factor of four overnight. And for the first time, an open-weight model from a Chinese lab legitimately belongs in the same sentence as Claude and GPT on hard coding benchmarks.
Here is the precise timeline that matters for developers:
• April 16 — Claude Opus 4.7 launches at 87.6% SWE-bench Verified with 1M context window, becoming the coding leader
• April 17 — Grok 4.3 Beta goes live quietly for SuperGrok Heavy ($300/month) with native PDF, slides, and video input
• April 20 — Kimi K2.6 drops on Hugging Face; overnight benchmarks show $0.60/M token open-weight model beating GPT-5.4 on SWE-Bench Pro
• April 23 — GPT-5.5 launches at 88.7% SWE-bench Verified, surpassing Opus 4.7 by 1.1 points on this benchmark while generating 72% fewer tokens
• April 24 — DeepSeek V4 Pro and V4 Flash launch; Flash prices at $0.14/$0.28 per million tokens — cheaper than every Western model at every tier
The old framing — "choose between OpenAI, Anthropic, and Google" — is finished. For a full breakdown of what the April 1–19 releases brought before this wave, see the April 12 model roundup covering Gemma 4, Claude Mythos, and Meta Muse Spark. This post focuses specifically on the April 20–26 models and how they change the overall ranking.
2. The Master Benchmark Table (12 Models, April 27, 2026)
Every model listed below is actively available via API or open weights as of April 27, 2026. Benchmark scores are from official vendor reports or third-party evaluations (Artificial Analysis, BenchLM.ai, vals.ai). Stars (*) indicate vendor-reported figures without independent third-party verification — treat with appropriate skepticism.
Table 1: Full model comparison — April 27, 2026 (SWE-V = SWE-bench Verified, SWE-Pro = SWE-bench Pro, AA Index = Artificial Analysis Intelligence Index)
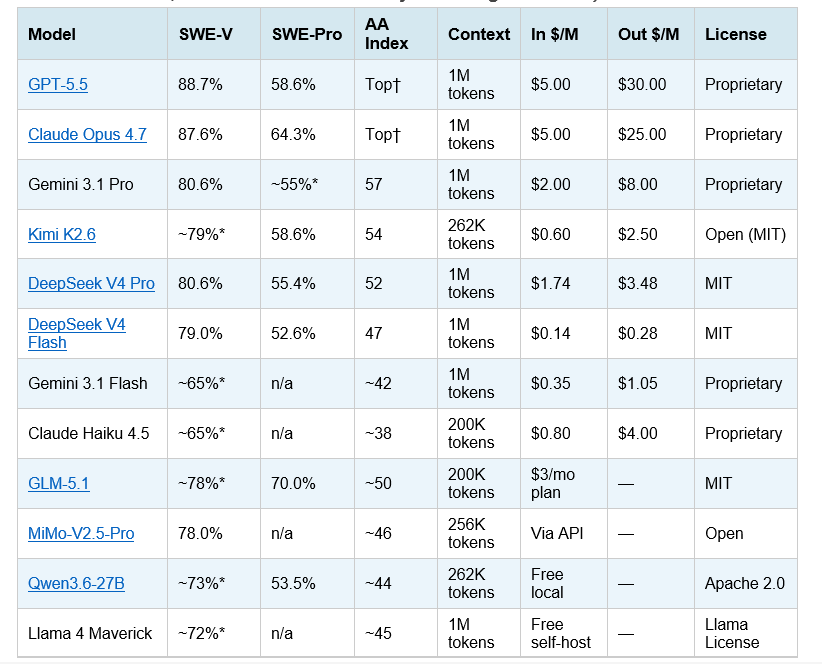
† GPT-5.5 and Claude Opus 4.7 are tied at the top of the AA Intelligence Index in the latest update. Claude Opus 4.7 leads SWE-bench Pro (64.3% vs GPT-5.5's 58.6%). GPT-5.5 leads SWE-bench Verified (88.7% vs Opus 4.7's 87.6%). * = vendor-reported, no independent third-party confirmation. Kimi K2.6 SWE-bench Verified score is vendor-reported; SWE-Pro 58.6% is independently confirmed. Pricing as of April 27, 2026. Subject to change.
3. Tier Breakdown: What Each Tier Is Actually For
Tier 1 — Frontier Closed: GPT-5.5 and Claude Opus 4.7
These are the two models you choose when you cannot afford to be wrong. GPT-5.5 leads SWE-bench Verified at 88.7%, generates 72% fewer output tokens than GPT-5.4 (making its effective cost-per-task far lower than list price suggests), and runs well on Terminal-Bench 2.0 agentic tasks at 82.7%. Claude Opus 4.7 leads SWE-bench Pro at 64.3% — the harder, less contaminated coding benchmark — and tops LM Arena human preference at 1504 Elo. Both have 1M context windows. Both are text-plus-multimodal.
My honest take: for most teams, neither model is the right default. They are the right escalation target. Use them for the 15–20% of tasks where the gap to the next tier is measurable in your specific workload. Default to Tier 2 for everything else.
For the full GPT-5.5 vs Claude Opus 4.7 head-to-head — including the 72% output token efficiency difference and what that means for real per-task costs — see the complete GPT-5.5 review and benchmark analysis.
Tier 2 — Frontier Value: Kimi K2.6 and DeepSeek V4 Pro
This tier is the most important development in the April wave. Kimi K2.6 from Moonshot AI scores 58.6% on SWE-bench Pro — matching GPT-5.4 on the harder benchmark — at $0.60 per million output tokens. That is 42× cheaper than Claude Opus 4.7 on output while sitting 5.7 points behind on SWE-Pro. DeepSeek V4 Pro hits 80.6% SWE-bench Verified and 55.4% SWE-Pro at $3.48/M output — roughly 7× cheaper than Opus 4.7.
For teams with cost-sensitive production workloads that still require near-frontier coding quality: Kimi K2.6 is the right default for complex tasks. V4 Pro is the right choice for long-context (1M token) workflows where K2.6's 262K limit is insufficient.
The Kimi K2.6 benchmarks genuinely surprised me when I reviewed the numbers. The full breakdown — including its MoE architecture, SwiGLU activation, and how it compares to GPT-5.4 and Claude Opus 4.6 — is in the Kimi K2.6 vs GPT-5.4 vs Claude Opus benchmark comparison.
Tier 3 — Budget API: DeepSeek V4 Flash and Gemini 3.1 Flash
Flash is the tier that rewrites production economics. DeepSeek V4 Flash scores 79.0% on SWE-bench Verified — essentially matching GPT-5.4 from three weeks ago — at $0.28/M output. Gemini 3.1 Flash provides multimodal support at $1.05/M output with sub-50ms first-token latency. For high-volume workloads: chatbots, RAG pipelines, summarization, classification, and code autocomplete, these are your defaults. Only escalate when Flash provably underperforms on your specific tasks.
For the complete Flash vs Pro decision guide — including the migration deadline from deepseek-chat (July 24, 2026) and Python quickstart code — see the DeepSeek V4 Flash review and pricing breakdown.
Tier 4 — Open-Weight Local: GLM-5.1, MiMo-V2.5-Pro, Qwen3.6-27B, Llama 4 Maverick
The open-weight tier has never been stronger. GLM-5.1 from Z.ai leads SWE-bench Pro among open models at 70% — above DeepSeek V4 Pro's 55.4% on the same benchmark. MiMo-V2.5-Pro from Xiaomi (formerly "Hunter Alpha") hit 78.0% SWE-bench Verified and topped OpenRouter traffic charts before its identity was revealed. Qwen3.6-27B runs on a 12:1 compute sparsity ratio — 3B active out of 27B total — making it feasible on consumer hardware. Llama 4 Maverick from Meta gives you Apache-2.0 weights at 400B total / 17B active with a 1M token context window.
For a hands-on guide to running Qwen3.6 locally — including hardware requirements, quantization setup, and benchmark comparison with Gemma 4 — see the Qwen3.6-27B full review and local deployment guide.
4. Per-Task Recommendations: Who Should Use What
The single most useful table in this post. Pick your task. Use the model. Do not let a marketing blog convince you that a single model wins everything — that has not been true since March 2025.
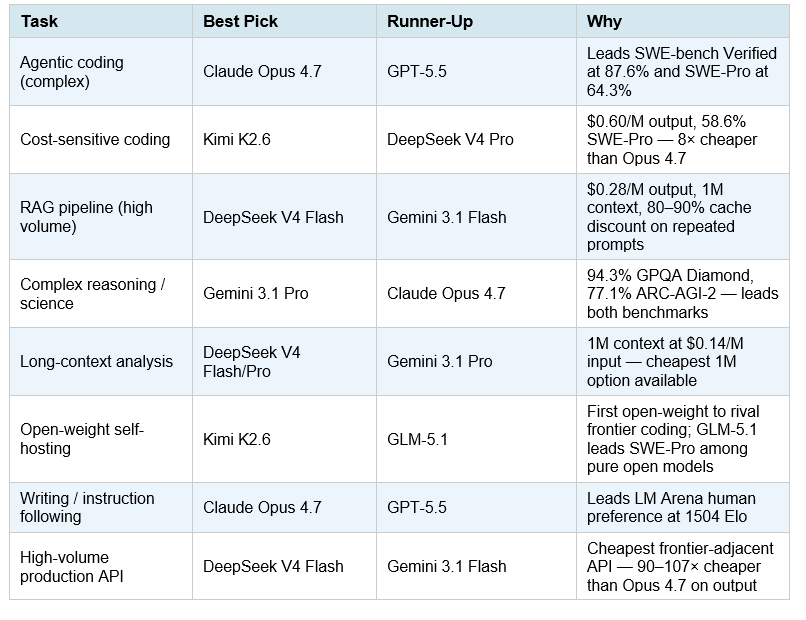
Table 2: Per-task model recommendations — April 27, 2026
A critical nuance that most model comparison articles skip: "best for coding" is not one category. SWE-bench Verified measures whether a model can resolve real GitHub issues end-to-end. SWE-bench Pro measures the same thing on harder, less contaminated tasks. Terminal-Bench 2.0 measures autonomous command-line execution. A model that scores 87.6% on Verified but 56.9% on Terminal-Bench (DeepSeek V4 Flash) is a very different product from one that scores 64.3% on SWE-Pro (Claude Opus 4.7). Match the benchmark to the actual task you are building.
For a broader per-task decision framework covering 20+ use cases — writing, customer support, research, data extraction, and more — see the every AI model compared guide updated for 2026.
5. Cost at Scale: 100M Token Math Across All Tiers
The price gap between tiers is wider than any other period in AI history. At 100 million output tokens per month — a mid-sized production workload — the difference between the cheapest and most expensive frontier option is more than 100×.
Table 3: Monthly API cost at 100M output tokens by tier (standard rates, cache-miss baseline)
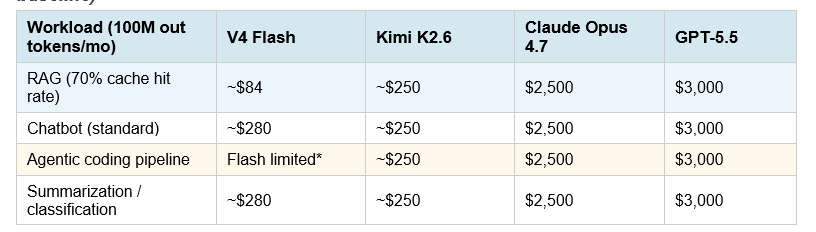
*V4 Flash scores 79.0% SWE-bench Verified — competitive for most coding tasks. Flash underperforms on complex multi-step agent tasks (Terminal-Bench 2.0: 56.9%). For those, route to V4 Pro or higher. RAG cache hit savings assume 70% hit rate at 10% of standard input price. Source: DeepSeek API docs, Anthropic API pricing, OpenAI pricing, Moonshot AI docs (April 2026).
The cache math is the most underreported factor in API cost comparisons. RAG pipelines, legal document agents, and customer support bots reuse system prompts and tool schemas on almost every call. At 65–70% cache-hit rates, DeepSeek V4 Flash's effective input cost drops to roughly $0.014 per million tokens. The cost gap between Flash and Western frontier models in those workflows is closer to 50× than the 7× headline figure. If your team is spending more than $500/month on API costs for summarization, classification, or standard coding tasks, you owe it to your budget to run Flash against your actual workload for one week.
Want to run your own cost-performance comparison across models on real prompts? The Gen AI Experiments multi-model benchmarking cookbook shows how to route calls to multiple providers and log cost per output for direct A/B comparison — the fastest way to find your actual production crossover point.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
6. The Fractured Leaderboard: No Single Winner in 2026
The most important thing I can tell you about the April 2026 AI model landscape: there is no single best model, and anyone who claims otherwise is either selling something or has not looked at the data carefully.
On Artificial Analysis Intelligence Index: GPT-5.5 and Claude Opus 4.7 share the top position in the latest update. On SWE-bench Verified (coding): GPT-5.5 leads at 88.7%. On SWE-bench Pro (harder coding): Claude Opus 4.7 leads at 64.3%. On GPQA Diamond (science reasoning): Gemini 3.1 Pro leads at 94.3%. On LM Arena (human preference): Claude Opus 4.7 leads at 1504 Elo. On cost-per-successful-fix: Kimi K2.6 and DeepSeek V4 are 7× cheaper than Opus 4.7 while only 10–12 points behind on coding benchmarks.
The implication for your stack: single-model routing is leaving money on the table. The mature architecture in 2026 is multi-tier: a cheap, fast default model for 70–80% of requests, and targeted escalation to frontier models for tasks that demonstrably need it. DeepSeek V4 Flash → Kimi K2.6 → Claude Opus 4.7 is one such stack. Gemini 3.1 Flash → Gemini 3.1 Pro for Google Workspace-native teams is another.
Quotable: "Pick the right model for the job, not the highest benchmark score. The gap between Tier 1 and Tier 2 is real on hard tasks; on typical production workloads, it is often within noise." This is the same conclusion reached in the Best AI Models April 2026 original roundup — and it has only become more true since Kimi K2.6 and DeepSeek V4 shifted the price-performance frontier downward.
7. The Benchmarks That Actually Matter
Before you trust any benchmark score in this post — or any other post — you need to understand what each benchmark actually measures. Labs cherry-pick the metrics where they look best. Here is the quick reference.
SWE-bench Verified
Real GitHub issues from popular Python repositories. The model must resolve them end-to-end in a sandboxed environment. As of April 2026, this is the most cited coding benchmark — but it has contamination concerns because many training datasets include GitHub content. Third-party site vals.ai provides independent verification. Treat vendor-reported scores as directional, not definitive.
SWE-bench Pro
The harder, less contaminated successor. 1,865 tasks across 41 actively maintained repositories in Python, Go, TypeScript, and JavaScript. Commissioned by Scale AI. Models that lead on SWE-bench Verified but trail on Pro (a 20-30 point drop is normal) are showing benchmark-specific performance rather than general coding ability. Claude Opus 4.7 leads at 64.3% on Pro — and its Verified score is also among the highest, suggesting genuine generalization.
Artificial Analysis Intelligence Index
A composite of 10+ standardized benchmarks including GPQA Diamond, AIME, LiveCodeBench, MMLU-Pro, and τ²-Bench. Scores are 0-100. The current top tier clusters around 52-58. A three-point gap on this index is meaningful; a one-point gap is within noise. Use this for "which model is generally smarter" comparisons, not task-specific decisions.
HLE (Humanity's Last Exam)
PhD-level expert questions across 100+ domains without tool assistance. Kimi K2.6 scored 54.0% on the with-tools variant — a remarkable result for an open-weight model. Claude Mythos Preview reportedly leads the field but is not publicly released. Most frontier models score 35–50% on this benchmark; any model above 50% is doing something technically impressive.
8. What Is Coming Next: Q2 2026 Pipeline
The April 20–26 wave is not the end of the Q2 release cycle. Here is what is confirmed or highly probable before the end of June 2026:
Table 4: Upcoming model releases — Q2 2026
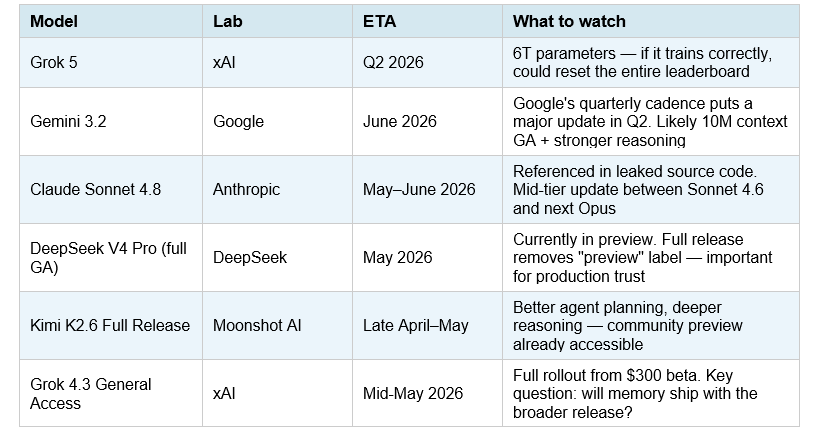
My honest prediction: Grok 5 is the release to watch. Six trillion parameters is an architectural bet that scale still matters at the frontier — the opposite of DeepSeek's MoE efficiency thesis. If Grok 5 delivers, it could restore a capability gap that the Tier 2 models have nearly closed. If it does not deliver proportional gains, it validates the efficiency-first approach that DeepSeek, Kimi, and GLM are all pursuing.
For context on the Grok 4.3 beta — the immediate predecessor to Grok 5 — including the $300/month paywall, PDF and slides output, and the Grok Computer integration, see the Grok 4.3 beta full feature breakdown and honest review.
Frequently Asked Questions
What is the best AI model in April 2026?
There is no single best model — the leaderboard has fractured by task. For agentic coding: Claude Opus 4.7 (87.6% SWE-bench Verified, 64.3% SWE-Pro). For cost-efficient coding: Kimi K2.6 (58.6% SWE-Pro at $0.60/M output). For complex reasoning: Gemini 3.1 Pro (94.3% GPQA Diamond). For budget API: DeepSeek V4 Flash ($0.28/M output, 79.0% SWE-bench Verified). Pick by task and budget, not by headline ranking.
What AI models were released in the April 20–26, 2026 wave?
The major releases in this window: Kimi K2.6 (Moonshot AI, April 20), GPT-5.5 (OpenAI, April 23), DeepSeek V4 Pro and V4 Flash (DeepSeek, April 24). Grok 4.3 Beta launched April 17, just before this window. Claude Opus 4.7 launched April 16. Combined, these five models created the most competitive benchmark environment of 2026 — three separate models claimed a #1 position on different benchmarks within one week.
Is GPT-5.5 better than Claude Opus 4.7?
Depends on the benchmark. GPT-5.5 leads SWE-bench Verified at 88.7% vs Opus 4.7's 87.6%. Claude Opus 4.7 leads SWE-bench Pro at 64.3% vs GPT-5.5's 58.6% — the more important benchmark for general coding capability. Opus 4.7 also leads LM Arena human preference at 1504 Elo. On the Artificial Analysis Intelligence Index they are tied. For most coding workloads: route to whichever your scaffold/tooling is already built for. The benchmark gap is too small to justify a platform switch.
What is SWE-bench Pro and how is it different from Verified?
SWE-bench Verified uses 500 Python-only GitHub issues and is the most commonly cited benchmark. SWE-bench Pro uses 1,865 tasks across 41 repositories in multiple programming languages (Python, Go, TypeScript, JavaScript) — less contaminated and harder. A model that scores 80% on Verified but 50% on Pro is benchmark-overfit. Claude Opus 4.7 leads both (87.6% Verified, 64.3% Pro), which is the strongest available signal that its coding performance generalizes to real-world tasks.
Which is the cheapest frontier-adjacent AI model in 2026?
DeepSeek V4 Flash at $0.14/M input and $0.28/M output — released April 24, 2026. It scores 79.0% on SWE-bench Verified (matching GPT-5.4 from three weeks ago) and runs at 83.6 tokens per second on DeepSeek's hosted API. With automatic context caching, effective input cost drops to ~$0.014/M on repeated system prompts. It is the cheapest model in its performance tier — cheaper than GPT-5.4 Nano, Gemini 3.1 Flash, and Claude Haiku 4.5.
Is Kimi K2.6 truly open source?
Yes — released under the MIT license on April 20, 2026, with full weights available on Hugging Face. The model is a 1-trillion-parameter Mixture-of-Experts architecture with 32B active parameters per forward pass. Self-hosting requires significant infrastructure (cluster-grade hardware for the full model) but quantized versions are expected from the community within weeks of launch. Kimi K2.6 API access is available at $0.60/M input and $2.50/M output through Moonshot AI's API.
What is Grok 4.3 and who should use it?
Grok 4.3 Beta launched April 17, 2026, exclusively for SuperGrok Heavy subscribers at $300/month. New capabilities include native PDF, PowerPoint, and spreadsheet generation directly from conversation; native video input; and tighter integration with Grok Computer (xAI's autonomous desktop agent). The $300/month tier is hard to justify for most teams — the core SuperGrok tier at $30/month gives meaningful Grok 4.3 access. Grok's key differentiator remains real-time X/Twitter data integration, which no other model can match.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Recommended Blogs
- Best AI Models April 2026 — Original Benchmark Roundup (April 5)
- GPT-5.5 Full Review: Benchmarks, Pricing & Vs Claude (2026)
- DeepSeek V4-Pro Review: Architecture, Benchmarks & Pricing
- DeepSeek V4 Flash: Review, Pricing & When to Use It (2026)
- Kimi K2.6 vs GPT-5.4 vs Claude Opus: Full Benchmark Breakdown
- Grok 4.3 Beta: Full Feature Review & $300 Paywall Analysis
- GLM-5.1: #1 Open Source AI Model? Full Review (2026)
References
- Artificial Analysis. (2026, April). LLM Leaderboard — Comparison of over 100 AI models.
- BenchLM.ai. (2026, April 22). SWE-bench Verified Benchmark 2026: 35 LLM scores.
- BenchLM.ai. (2026, April 24). SWE-bench Pro Benchmark 2026: 28 LLM scores.
- Marc0.dev. (2026, April). SWE-Bench Leaderboard April 2026 — Claude Opus 4.7 Leads.
- TokenMix Blog. (2026, April 24). SWE-Bench 2026: Claude Opus 4.7 Wins 87.6% vs GPT-5.3 85.0%.
- DeepSeek AI. (2026, April 24). DeepSeek V4 Preview Release. DeepSeek API Docs.
- TechSifted. (2026, April 17). Grok 4.3 Beta Review: What's New in xAI's Latest Model.
- Artificial Analysis. (2026, April 24). DeepSeek is back among the leading open weights models with V4 Pro and V4 Flash.
- Ofox AI. (2026, April). LLM Leaderboard: Best AI Models Ranked (April 2026).
- DataLearner. (2026, April). AI Model Leaderboard [2026-04] — Live Rankings.

