





DeepSeek V4-Pro Review: Benchmarks, Pricing & Architecture (2026)
January 2025: DeepSeek R1 matched OpenAI's o1 at a fraction of the cost and briefly crashed NVIDIA's stock. April 24, 2026: DeepSeek is back — with something bigger.
DeepSeek dropped the V4-Pro and V4-Flash preview models on Hugging Face today, after three delays spanning nearly four months. The result is a 1.6 trillion parameter open-source model that scores 80.6% on SWE-bench Verified — within 0.2 points of Claude Opus 4.6 — and costs $3.48 per million output tokens versus Claude's $25. That is a 7x price gap at near-identical coding benchmark performance.
I've been tracking the V4 release cycle since January 2026, watching every Reuters leak, every false OpenRouter attribution, every delayed launch window. Now that it's actually here, let me cut through the noise and give you the real breakdown: what the benchmarks actually say, what the architecture innovations mean in practice, how the pricing math works, and who should use which model.
DeepSeek V4-Pro vs V4-Flash: The Two-Model Family Explained
DeepSeek V4 is a two-model family, both using Mixture-of-Experts (MoE) architecture and released simultaneously under the MIT License on April 24, 2026. The distinction is not just scale — it is a fundamental product segmentation between depth and speed.
DeepSeek-V4-Pro is the flagship: 1.6 trillion total parameters, 49 billion active per token, pre-trained on 33 trillion tokens. This is the model DeepSeek calls 'the best open-source model available today.' It's accessible as 'Expert Mode' on chat.deepseek.com and through the API.
DeepSeek-V4-Flash is the efficiency play: 284 billion total parameters, 13 billion active per token, trained on 32 trillion tokens. The 13B active parameter count is in the same ballpark as many mid-range models — but Flash has access to 284B worth of specialized expert knowledge. DeepSeek calls this 'Instant Mode' on their chat interface.
Both models share an identical feature set: 1 million token context window, 384K maximum output, three reasoning effort modes (standard, think, think-max), JSON output, tool calls, FIM completion in non-think mode, and Chat Prefix Completion. The differentiation is purely in reasoning depth, factual recall on complex tasks, and price.
One critical note from the official model cards: this release does NOT include a Jinja-format chat template. DeepSeek provides Python encoding scripts in the model repository for prompt construction. Plan for this in your integration.
To put these models in context against the full April 2026 leaderboard, our April 2026 AI model benchmark rankings covers where V4 slots in across all major models now that the weights are live.
Three Architecture Innovations That Make 1M Context Viable
Most models claim million-token context windows as a marketing number. The economics of inference at 1M tokens are usually brutal — quadratic attention scaling means exponentially more compute and memory per token. DeepSeek V4 solves this with three specific architectural innovations, all published in peer-reviewed papers before today's release.
1. Hybrid Attention Architecture (CSA + HCA)
The most consequential change. DeepSeek V4 replaces standard full attention with a hybrid of Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). The practical result is striking: in the 1M-token context setting, DeepSeek-V4-Pro requires only 27% of the single-token inference FLOPs and 10% of the KV cache compared with DeepSeek-V3.2. That is not an incremental improvement. At 10% of the KV cache, you can fit a context that would otherwise require 10x the GPU memory. This is what makes 1M-context inference economically viable to deploy as a standard offering rather than a premium add-on.
2. Manifold-Constrained Hyper-Connections (mHC)
Standard residual connections in transformers pass a single vector forward through the network. Hyper-Connections widen this into multiple parallel streams — theoretically improving expressivity. The problem: unconstrained Hyper-Connections caused catastrophic training divergence in DeepSeek's own 27B experiments, with signal amplification exceeding 3,000x. The mHC framework solves this by constraining the residual connection mixing matrices to the Birkhoff Polytope using the Sinkhorn-Knopp algorithm. The mathematical result: signal amplification drops to 1.6x, enabling stable training at 1.6 trillion parameters. The paper was published December 31, 2025, co-authored by CEO Liang Wenfeng — a clear signal this was V4's core training innovation.
3. Muon Optimizer
DeepSeek employs the Muon optimizer for pre-training — chosen for faster convergence and greater stability compared to standard AdamW. At 1.6 trillion parameter scale, training instability compounds quickly. Muon, combined with mHC's stability guarantees, is what allowed DeepSeek to push training to 33 trillion tokens without the gradient collapse that typically plagues models at this scale.
Taken together, these three innovations explain something specific: how a Chinese AI lab that reportedly cannot access NVIDIA's latest chips at training scale produced a model that benchmarks within a fraction of GPT-5.4 on coding tasks. The efficiency gains are architectural, not compute-brute-force.
Full Benchmark Breakdown: Where V4-Pro Wins, Where It Trails
DeepSeek published detailed head-to-head comparisons against Claude Opus 4.6, GPT-5.4, and Gemini-3.1-Pro. The results are strong with genuine nuance — and DeepSeek is notably honest about where V4-Pro trails. Here is the full picture:
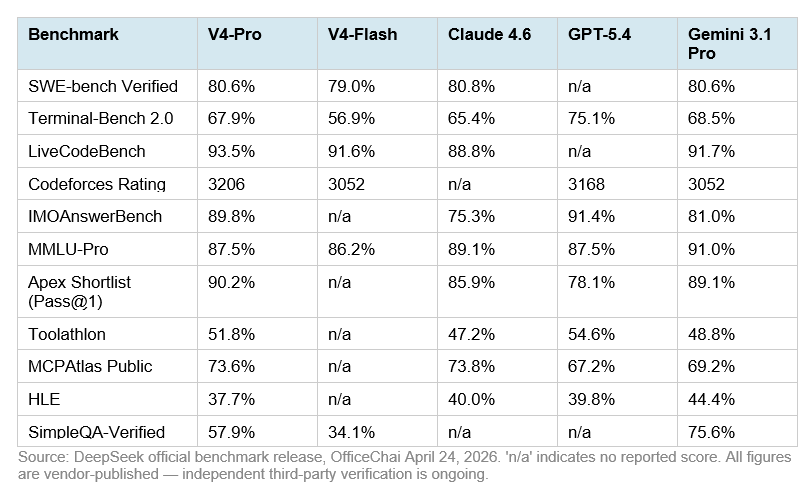
Where V4-Pro Wins Clearly
LiveCodeBench at 93.5% is V4-Pro's strongest competitive position — ahead of Gemini (91.7%) and significantly ahead of Claude (88.8%). For pure code generation quality across diverse programming tasks, this is the best open-source result on this benchmark.
Codeforces rating at 3206 puts V4-Pro at the top of competitive programming rankings, ahead of GPT-5.4 (3168) and Gemini (3052). No Claude score is reported for this benchmark.
Terminal-Bench 2.0 at 67.9% beats Claude Opus 4.6 (65.4%) by 2.5 points — this benchmark involves real autonomous terminal execution with a 3-hour timeout. That gap matters for agentic workflows more than a single-turn coding benchmark would.
Where V4-Pro Trails
HLE (Humanity's Last Exam) at 37.7% puts V4-Pro below Claude (40.0%), GPT-5.4 (39.8%), and well below Gemini-3.1-Pro (44.4%). HLE tests expert-level cross-domain reasoning. DeepSeek acknowledges this gap directly.
SimpleQA-Verified at 57.9% versus Gemini's 75.6% reveals a meaningful factual knowledge retrieval gap. If your use case requires accurate real-world knowledge recall — not just code generation — Gemini holds a clear edge.
HMMT 2026 math competition: Claude (96.2%) and GPT-5.4 (97.7%) pull decisively ahead of V4-Pro (95.2%). For the most complex mathematical reasoning tasks specifically, V4-Pro trails on this metric.
V4-Flash's Benchmark Position
V4-Flash is a genuinely serious model, not a stripped-down fallback. On SWE-bench Verified it scores 79.0% versus V4-Pro's 80.6% — a 1.6-point gap. On LiveCodeBench it hits 91.6% versus 93.5%. For most developer coding tasks, these are functionally equivalent results. The meaningful gaps emerge on Terminal-Bench 2.0 (56.9% vs 67.9%) and SimpleQA-Verified (34.1% vs 57.9%) — complex multi-step tool use and factual recall tasks favor V4-Pro significantly.
For deeper context on how these benchmarks compare against the full open-source landscape including GLM-5.1 and Qwen3.6, our GLM-5.1 full review and benchmark analysis covers the competing Chinese open-source leader's performance on the same metrics.
Pricing Deep Dive: The 7x Claude Cost Advantage
DeepSeek's pricing for V4 follows the exact same pattern as V3 — strong capabilities at a fraction of Western model prices. Here is the complete pricing table alongside all major frontier models:
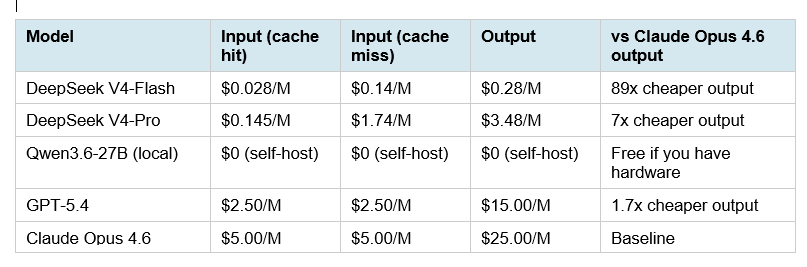
The V4-Flash output price of $0.28 per million tokens is remarkable. Running 10 million output tokens through V4-Flash costs $2.80. The same workload on Claude Opus 4.6 costs $250. That is an 89x difference — not 7x. The 7x gap applies to V4-Pro.
To make the V4-Pro math concrete: a production agentic coding pipeline processing 50 million output tokens per month costs $174 on V4-Pro versus $1,250 on Claude Opus 4.6. At 100 million output tokens — a reasonable number for an active SWE agent — that gap becomes $348 versus $2,500 monthly. The cache-hit input pricing ($0.145/M for V4-Pro) makes systems with repetitive system prompts even cheaper in practice.
The contrarian point worth making: pricing is not the whole story, and I would push back on anyone treating V4-Pro as a direct Claude drop-in. Claude Opus 4.6 leads on SWE-bench Verified by 0.2 points, leads decisively on HLE, SimpleQA, and HMMT, and has a mature safety and reliability profile from years of production deployment. For cost-sensitive agentic coding at scale — V4-Pro is genuinely compelling. For nuanced reasoning, factual recall, or enterprise reliability requirements — the price gap alone should not close the deal.
For a practical comparison of how DeepSeek pricing has evolved from the R1 era, our guide to installing and running DeepSeek-R1 locally covers the cost math that originally made DeepSeek's pricing disruptive in 2025.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
How to Access DeepSeek V4 Right Now
DeepSeek V4-Pro and V4-Flash are available through three access routes as of April 24, 2026:
Route 1: chat.deepseek.com (Immediate, No Setup)
V4-Pro is available as 'Expert Mode' and V4-Flash as 'Instant Mode' at chat.deepseek.com. This is the fastest way to test both models. No API key required for the chat interface.
Route 2: DeepSeek API (Production)
The API is live immediately at api.deepseek.com. DeepSeek uses an OpenAI-compatible format — integrate using the OpenAI SDK with a base URL swap to api.deepseek.com and the model set to deepseek-v4-pro or deepseek-v4-flash. The API also supports Anthropic API format, making migration from Claude straightforward. Recommended sampling parameters: temperature = 1.0, top_p = 1.0. For Think Max reasoning mode, set context window to at least 384K tokens.
Note: The V4 models do NOT include a Jinja-format chat template. Use the Python encoding scripts in the DeepSeek-V4-Pro Hugging Face repository (encoding_dsv4.py) to construct prompts correctly.
Route 3: Open Weights (Self-Hosting)
Full model weights are available at the DeepSeek V4 collection on Hugging Face under the MIT License. V4-Pro at FP4+FP8 mixed precision requires significant GPU infrastructure — the 1.6T parameter model needs multiple H100 or equivalent nodes for inference. DeepSeek provides inference setup instructions in the inference folder of the Hugging Face repository, including weight conversion guides and interactive chat demos. Expect GGUF quantizations to appear from the community within days of this writing.
Integration compatibility: DeepSeek confirms V4-Pro works with Claude Code, OpenClaw, and OpenCode — a strong signal the company is targeting the agentic coding developer ecosystem directly.
For a hands-on implementation pattern using an OpenAI-compatible open-source endpoint, the Netflix Void Model cookbook demonstrates the exact base URL + model swap integration pattern that applies to DeepSeek V4's API.
Who Should Use V4-Pro vs V4-Flash vs Stick With Claude
Use DeepSeek V4-Pro if:
• You run high-volume agentic coding workflows where $3.48/M output versus $25/M is a meaningful budget lever
• Your primary use cases are software engineering, competitive programming, or terminal-based autonomous agent tasks — V4-Pro leads Claude on LiveCodeBench (93.5% vs 88.8%) and Terminal-Bench (67.9% vs 65.4%)
• You are building on OpenCode, Claude Code (via API routing), or OpenClaw and want to cut infrastructure cost without sacrificing coding benchmark performance
• You need MIT-licensed open weights for compliance, on-premises deployment, or fine-tuning — and have the GPU infrastructure to run a 1.6T MoE model
Use DeepSeek V4-Flash if:
• Speed and cost are your primary requirements — $0.28/M output (89x cheaper than Claude Opus 4.6) with 79% SWE-bench Verified performance
• Your workflow involves high-frequency, lower-complexity coding tasks where 1-2 benchmark point gaps do not matter in practice
• You want to build a tiered routing system: Flash for initial drafts and straightforward tasks, Pro for complex repository-level reasoning or multi-step agentic sequences
Stick with Claude Opus 4.6 or Claude Sonnet 4.6 if:
•Factual accuracy and world knowledge are critical — Gemini-3.1-Pro leads on SimpleQA-Verified (75.6% vs V4-Pro's 57.9%), and Claude holds a meaningful HLE gap
• You operate in regulated industries (healthcare, finance, legal) where Chinese-origin model data routing is a compliance consideration
•Your agentic tooling is built around Claude's native tool-use capabilities and you need battle-tested production reliability
• You need AWS Bedrock or Azure OpenAI deployment — DeepSeek V4 is not yet available on major cloud platforms beyond DeepSeek's own API
For developers evaluating the broader Chinese open-source landscape alongside V4, our comparison of Qwen 3.6 Plus, GLM-5.1, and Kimi 2.5 for coding covers the three-way test with real cost math and benchmark tables.
The Huawei Chip Story: Why It Matters
Reuters confirmed on April 4, 2026 that DeepSeek V4 was trained on Huawei's Ascend 950PR chips — not NVIDIA hardware. DeepSeek deliberately denied NVIDIA and AMD early optimization access while giving that window exclusively to Chinese chipmakers. NVIDIA CEO Jensen Huang called this outcome 'horrible for the United States' on the Dwarkesh Podcast. He is not wrong about the strategic implication.
The practical consequence: inference weights are available in FP4 + FP8 mixed precision and run on NVIDIA H100/H200 hardware. Local deployment for most developers is unaffected. But the training-side shift to Huawei silicon is significant — it establishes that frontier-class models can now be trained on non-NVIDIA hardware at scale. That changes the geopolitical calculus around US chip export controls.
For developers outside China using the DeepSeek API: the server infrastructure is DeepSeek-operated and based in China. This creates the same data sovereignty considerations that applied to V3.2 — not a security risk per se, but a compliance consideration for teams handling sensitive code, proprietary IP, or regulated data. Self-hosting via open weights is the mitigation path for teams where this matters.
For historical context on DeepSeek's open-source release pattern and how the R1 launch established its cost-efficiency reputation, our DeepSeek R1 local deployment guide covers the technical and economic story that set up today's V4 launch.
Frequently Asked Questions
What is DeepSeek V4-Pro?
DeepSeek V4-Pro is a 1.6 trillion parameter Mixture-of-Experts language model released on April 24, 2026 by DeepSeek under the MIT License. It activates 49 billion parameters per token, supports a 1 million token context window, and achieves 80.6% on SWE-bench Verified — within 0.2 points of Claude Opus 4.6. It is available via the DeepSeek API, at chat.deepseek.com as 'Expert Mode,' and as open weights on Hugging Face.
Is DeepSeek V4-Pro better than Claude Opus 4.6?
On coding benchmarks, DeepSeek V4-Pro leads Claude on Terminal-Bench 2.0 (67.9% vs 65.4%), LiveCodeBench (93.5% vs 88.8%), and Codeforces rating (3206 vs no reported score). Claude Opus 4.6 holds a marginal lead on SWE-bench Verified (80.8% vs 80.6%), and a meaningful lead on HLE (40.0% vs 37.7%) and HMMT 2026 math (96.2% vs 95.2%). V4-Pro costs 7x less per million output tokens. For high-volume coding agent workloads, the price-performance math favors V4-Pro. For nuanced reasoning and factual accuracy, Claude Opus 4.6 still holds an edge.
What is the difference between DeepSeek V4-Pro and V4-Flash?
V4-Pro has 1.6 trillion total parameters (49B active) and costs $3.48/M output tokens. V4-Flash has 284 billion total parameters (13B active) and costs $0.28/M output tokens — 12.4x cheaper than Pro. On SWE-bench Verified, Flash scores 79.0% versus Pro's 80.6%. The main practical gaps appear on Terminal-Bench 2.0 (56.9% vs 67.9%) and SimpleQA-Verified (34.1% vs 57.9%), suggesting Flash struggles more on complex multi-step tool use and factual recall tasks. For most coding use cases, Flash delivers acceptable quality at dramatically lower cost.
What is the Hybrid Attention Architecture in DeepSeek V4?
DeepSeek V4's Hybrid Attention Architecture combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to reduce the computational cost of long-context inference. In the 1M-token context setting, V4-Pro requires only 27% of the single-token inference FLOPs and 10% of the KV cache compared to DeepSeek-V3.2. This makes million-token context inference economically viable as a standard API offering rather than a premium feature.
What are Manifold-Constrained Hyper-Connections (mHC)?
mHC is a training innovation that extends standard transformer residual connections into multiple parallel information streams, while constraining their interaction matrices to the Birkhoff Polytope via the Sinkhorn-Knopp algorithm. Unconstrained Hyper-Connections caused signal amplification of 3,000x in DeepSeek's own 27B experiments, crashing training. mHC drops that amplification to 1.6x, enabling stable training at 1.6 trillion parameters. The paper was published December 31, 2025, co-authored by DeepSeek CEO Liang Wenfeng.
How much does DeepSeek V4-Pro cost per million tokens?
DeepSeek V4-Pro costs $0.145 per million input tokens (cache hit), $1.74 per million input tokens (cache miss), and $3.48 per million output tokens. Compare to Claude Opus 4.6 ($5/M input, $25/M output) and GPT-5.4 ($2.50/M input, $15/M output). V4-Flash is significantly cheaper at $0.028/M input (cache hit) and $0.28/M output. Cache-hit pricing makes repeated system prompt workflows dramatically cheaper — input tokens approach zero cost on V4-Flash for high-cache workflows.
Is DeepSeek V4 safe for production use?
DeepSeek V4 is labeled as a preview release — DeepSeek's own technical report notes further post-training refinements are expected. For production workloads, evaluate V4 on your specific tasks before switching from a stable model. Additionally, DeepSeek's API infrastructure is China-based, which creates data sovereignty considerations for teams handling regulated or sensitive data. Self-hosting via open weights under the MIT License is the recommended path for teams with strict data residency requirements.
How to use DeepSeek V4 with Claude Code or OpenCode?
DeepSeek V4-Pro is confirmed compatible with Claude Code, OpenClaw, and OpenCode. For Claude Code: set ANTHROPIC_BASE_URL to DeepSeek's API endpoint and ANTHROPIC_AUTH_TOKEN to your DeepSeek API key. For OpenCode: update the model configuration to point at the DeepSeek API using the OpenAI-compatible base URL. Use model string deepseek-v4-pro or deepseek-v4-flash. Note that V4 does not include a Jinja-format chat template — use DeepSeek's Python encoding scripts from the Hugging Face repository for custom prompt construction.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Recommended Blogs
If this breakdown was useful, these posts cover the surrounding landscape of open-source AI and agentic coding models in 2026:
• Install & Use DeepSeek-R1 Locally for Free — Save $200/Month!
• Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5: Best Chinese AI for Coding 2026
References
Bloomberg — DeepSeek Unveils Newest Flagship AI Model (April 24, 2026)
OfficeChai — DeepSeek V4-Pro & V4-Flash Benchmarks & Pricing (April 24, 2026)
Reuters — DeepSeek V4 to Run on Huawei Chips (April 3, 2026)
mHC Technical Paper (arxiv) — Manifold-Constrained Hyper-Connections

