





DeepSeek V4 Flash: Review, Pricing & When to Use It (2026)
$0.28 per million output tokens. 79% on SWE-bench Verified. 83.6 tokens per second. 1 million token context window. MIT license, open weights, free commercial use. That is not the budget fallback — that is DeepSeek V4 Flash, released April 24, 2026, and it is the model I would default to for most production workloads right now.
There is one catch: almost nobody has written a builder-focused breakdown of Flash specifically. Every article covers V4 Pro — the 1.6 trillion parameter flagship. Flash gets a sentence or two. That is backward. For the majority of API use cases, Flash is the correct starting point, and Pro is the upgrade you apply selectively when Flash proves insufficient on your actual tasks.
I covered the V4-Pro architecture in depth in the DeepSeek V4-Pro full review and benchmark breakdown. This post is about Flash: when it is enough, when it is not, how to call it, what it costs, and the migration deadline your team needs to know about.
1. What Is DeepSeek V4 Flash? (Full Specs vs V4 Pro)
DeepSeek V4 Flash is the fast, cost-optimized tier of DeepSeek's fourth-generation model family, released simultaneously with V4 Pro on April 24, 2026, under the MIT license. Both models are available via the DeepSeek API and as open weights on Hugging Face.
Flash uses a Mixture-of-Experts (MoE) architecture with 284 billion total parameters and 13 billion active parameters per inference pass. It is not a distilled or stripped-down version of Pro — it was trained separately on the same 32 trillion token dataset, using the same architectural innovations (Compressed Sparse Attention, manifold-constrained hyper-connections, and the Muon optimizer) that make V4's 1M-token context economically viable to serve.
The MoE design is the core reason Flash is so cheap to run. If you want to understand why activating 13B out of 284B parameters per token matters for cost, the Mixture of Experts (MoE) architecture explainer walks through the math behind how DeepSeek, Kimi, and Qwen all use this to slash inference costs while preserving capability.
Full Specs: V4 Flash vs V4 Pro (April 2026)
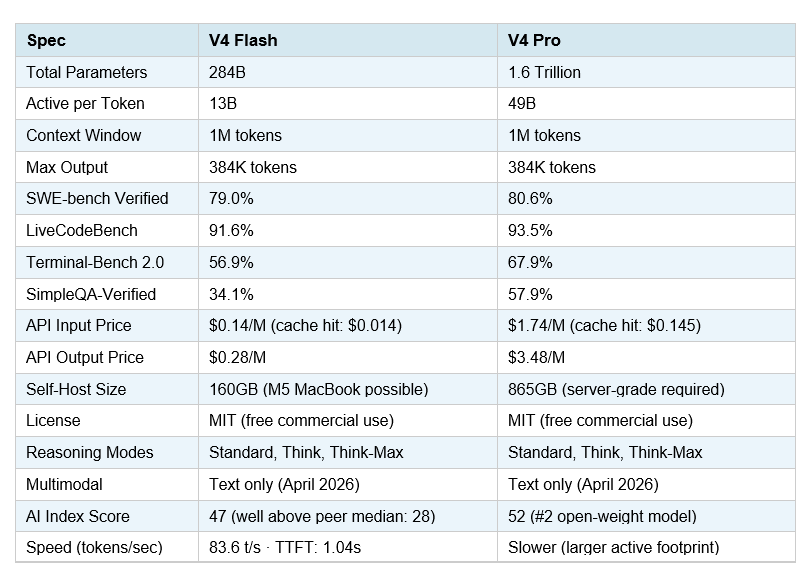
The key takeaway from this table: on coding benchmarks, Flash and Pro are within 1.6 percentage points of each other. The gap widens sharply on complex agentic tasks (Terminal-Bench 2.0: Flash 56.9% vs Pro 67.9%) and factual recall (SimpleQA-Verified: Flash 34.1% vs Pro 57.9%). For most developer use cases — chatbots, RAG pipelines, code autocomplete, summarization — the 1.6-point coding gap is functionally invisible. The 11-point terminal-agent gap is meaningful if you are building unattended, multi-step automation.
2. The Migration Alert: deepseek-chat Is Already Flash
This is the most important section for teams already using DeepSeek's API, and almost no one has covered it.
DeepSeek's official API docs confirm: the model names deepseek-chat and deepseek-reasoner are currently routing to the non-thinking and thinking modes of deepseek-v4-flash respectively. Both legacy endpoints will be fully retired and inaccessible after July 24, 2026.
That means if your team is currently calling deepseek-chat in production, you are already running on V4 Flash quality — at V4 Flash prices — without having explicitly migrated. This is good news for quality (you got a free upgrade) but a hidden gotcha for anyone relying on the old model behavior or who has not pinned a model version.
What to do right now:
• Swap model="deepseek-chat" → model="deepseek-v4-flash" in your API calls
• Swap model="deepseek-reasoner" → model="deepseek-v4-flash" with reasoning_effort="high"
• Test your downstream outputs — V4 Flash's reasoning style differs slightly from V3.2
• Set your calendar: July 24, 2026 is the hard deprecation deadline
The migration is a single string change in your model parameter. The API surface (base_url, authentication, message format, tool calling, JSON output) is identical. There is no reason to wait.
3. Full Benchmark Breakdown
DeepSeek published benchmark results for both V4 models at launch. All figures below are vendor-reported from the official V4 technical report, cross-referenced with Artificial Analysis evaluations. Independent third-party reproductions are still emerging as of late April 2026 — treat exact figures as directional until broader verification catches up.
Where Flash matches Pro (within 2 points)
• SWE-bench Verified: Flash 79.0% vs Pro 80.6% — essentially equivalent for standard coding tasks
• LiveCodeBench Pass@1: Flash 91.6% vs Pro 93.5% — both well above Gemini 3.1 Flash and GPT-5.4 Mini
• MMLU-Pro (broad knowledge): Flash within 3 points of Pro on this benchmark
• Simple agent tasks: DeepSeek confirms Flash "performs on par with Pro on simple agent tasks"
• Flash-Max reasoning mode closely approaches Pro-Max when given a larger thinking budget
Where Flash loses to Pro (meaningful gaps)
• Terminal-Bench 2.0: Flash 56.9% vs Pro 67.9% — multi-step terminal automation gap is real
• SimpleQA-Verified: Flash 34.1% vs Pro 57.9% — factual recall under complex queries drops sharply
• Toolathlon (agentic tool use): Flash falls further behind on deeply chained, multi-tool workflows
• HLE (expert cross-domain reasoning): Flash places lower than Pro — complex academic tasks are weaker
For comparison: GPT-5.5 scores 82.7% on Terminal-Bench 2.0 and 88.7% on SWE-bench Verified, and Claude Opus 4.7 hits 87.6% on SWE-bench Verified. If your workload requires the absolute frontier on complex agentic tasks, Flash is not the answer — you want Pro or a closed-source model. For the full frontier comparison, see the Best AI Models April 2026 benchmark rankings.
One metric worth highlighting: Artificial Analysis clocked Flash at 83.6 tokens per second with a 1.04-second time to first token on DeepSeek's hosted API. Both figures are well above the median for open-weight models of comparable size. Flash is fast for a model this capable — it does not feel like a budget option in production.
4. The Real Cost Math: Workload Pricing Tables
Most pricing comparisons stop at headline per-token rates. That number misleads you. The real cost depends on two things most articles ignore: cache hit rates and output token ratios.
Official pricing (April 2026, cache-miss rates)
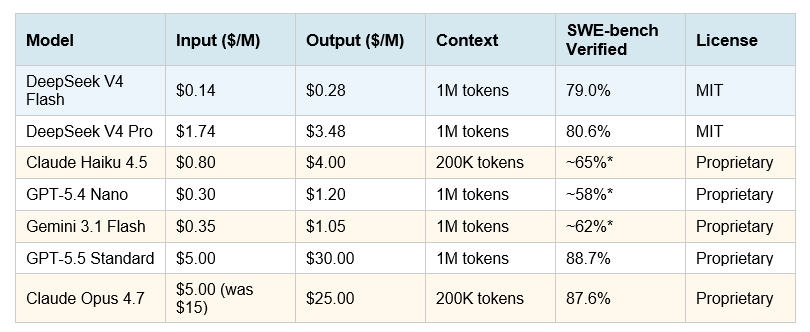
*Estimated based on comparable model benchmarks. Flash pricing includes 80–90% cache-hit discounts for repeated system prompts — effective input cost drops to ~$0.014/M tokens in high-cache workflows. Off-peak discount (Beijing nighttime) applies a further 50% reduction. Source: DeepSeek API Docs, April 2026.
Simon Willison confirmed in his April 24 analysis: "DeepSeek-V4-Flash is the cheapest of the small models, beating even OpenAI's GPT-5.4 Nano" — which is remarkable given Flash's 79% SWE-bench score puts it in a completely different capability tier than Nano.
What workloads actually cost at 100M output tokens / month
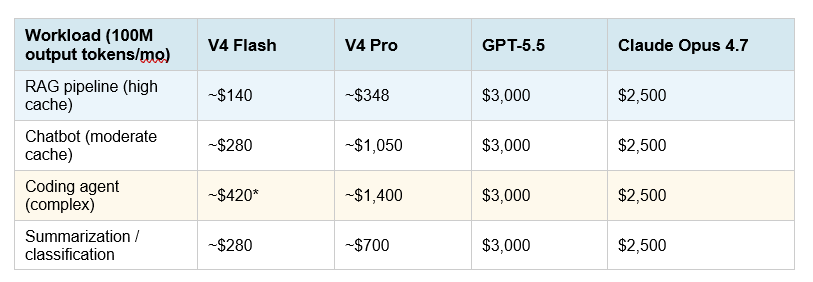
*For complex agentic coding, use V4 Pro — Flash loses ground on multi-step tool use (Terminal-Bench 2.0: Flash 56.9% vs Pro 67.9%). Prices are estimates at standard cache-miss rates. Actual costs with caching will be significantly lower. Source: DeepSeek API Docs, Lushbinary pricing analysis, April 2026.
The cache math is the most underreported story. RAG pipelines, legal document agents, and customer support chatbots reuse system prompts and tool schemas on almost every request. At 65–70% cache hit rates (typical for conversational workloads), V4 Flash's effective input cost drops to roughly $0.014/M tokens. That is not a rounding error — at that rate, the cost gap between Flash and Western proprietary models is closer to 50x than the 7x headline figure.
Hot take: if your team is spending more than $500/month on LLM API costs for tasks that involve summarization, RAG, classification, or standard coding, you owe it to your budget to run Flash against your actual workload for one week. The ceiling of what Flash can handle is much higher than its price tag implies.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Where Flash Wins (and Dominates)
Flash is the right default for any of the following workloads. Use Pro only if you can demonstrate Flash underperforms on the specific task.
RAG pipelines and document agents
The combination of 1M-token context and $0.14/M input pricing makes Flash the obvious backbone for retrieval-augmented generation. You can feed in entire codebases or multi-year document archives without chunking, and the cache pricing means repeated system prompts and tool schemas cost almost nothing after the first call.
To implement a production RAG pipeline with DeepSeek Flash, start with the Gen AI Experiments cookbook repository — the RAG implementation notebooks use the OpenAI-compatible base_url pattern, meaning you can swap to DeepSeek Flash with a single model string change and your existing LangChain or LlamaIndex stack.
High-volume chatbots and customer support
At $0.28/M output tokens, Flash is cheap enough that token cost stops being an engineering conversation. You can run a customer support chatbot at massive scale without thinking hard about token budgets. The 1.04-second TTFT makes it responsive enough for interactive use.
Code autocomplete and inline suggestions
Flash's 91.6% LiveCodeBench score and sub-second TTFT make it competitive with dedicated code completion models. For in-IDE autocomplete, CI-time code review, and test generation at scale, Flash delivers frontier-adjacent quality at what is effectively Haiku-tier pricing.
Routing layers in multi-model architectures
One pattern I keep recommending: use Flash as the default routing layer in a multi-model stack. Flash handles 80% of queries. Only escalate to Pro (or Claude Opus 4.7, or GPT-5.5) when the task requires deep agentic reasoning. This architecture cuts costs dramatically while preserving quality where it matters. See the every AI model compared guide for a framework on matching tasks to models.
Classification, summarization, and data extraction
These are Flash's bread and butter. Simple, bounded tasks with high volume and clear outputs. At 10,000 classification calls (2K context, 200 output tokens each), Flash costs around $0.28. On GPT-5.5, the same batch costs $6.00. For any team running production data pipelines at scale, that math compounds into thousands of dollars of monthly savings.
6. Where Flash Loses to Pro
I said I would be honest about where Flash underperforms. Here it is.
Complex terminal and computer-use agents
Terminal-Bench 2.0 measures real autonomous command-line execution across multi-step workflows with a 3-hour timeout. Flash scores 56.9%. Pro scores 67.9%. GPT-5.5 scores 82.7%. If you are building unattended coding agents that navigate file systems, run tests, fix bugs across multiple files, and deploy code — Flash is not the right model. The gap to Pro is real and it widens further on the most complex autonomous workflows.
Factual recall at depth
SimpleQA-Verified: Flash 34.1%, Pro 57.9%. If your use case requires the model to accurately recall specific facts, names, dates, statistics, or technical specifications from its training data — rather than reasoning from context provided in the prompt — Flash shows a meaningful reliability gap. For RAG use cases where facts come from documents in the context window, this gap largely disappears. For "what is X" questions from parametric memory, Pro or Gemini 3.1 Pro have a real edge.
Expert cross-domain reasoning without tools
HLE (Humanity's Last Exam) tests PhD-level cross-domain reasoning without tool assistance. Flash scores below Pro on this benchmark, and both trail Gemini 3.1 Pro (44.4%) and Claude Opus 4.7 (46.9%). If your use case involves complex scientific analysis, advanced mathematics, or expert-level research synthesis, the closed-source frontier models still hold a measurable lead. See the Kimi K2.6 vs GPT-5.4 vs Claude Opus comparison for how the top frontier models stack up on these harder benchmarks.
No multimodal support (yet)
Both V4 Flash and V4 Pro are text-only as of April 2026. DeepSeek has said multimodal capabilities are in development, but no timeline has been published. If your use case involves image, audio, or video understanding, you need a different model — Claude Opus 4.7, GPT-5.5, or MiMo-V2.5-Pro all offer native multimodal support.
7. Python Quickstart: Calling Flash in 10 Lines
DeepSeek V4 Flash uses the OpenAI-compatible API surface. If you already use the openai Python SDK, swapping to Flash is a base_url change and a model string change — nothing else.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com"
)
# Non-thinking mode — fast, direct answers
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Explain MoE in 2 sentences."}],
)
print(response.choices[0].message.content)
# Thinking mode — step-by-step reasoning
response_thinking = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Debug this Python function..."}],
extra_body={"reasoning_effort": "high"}
)
print(response_thinking.choices[0].message.content)
# Anthropic-compatible endpoint (same pricing)
# base_url="https://api.deepseek.com/anthropic"
# IMPORTANT: deepseek-chat → deepseek-v4-flash after July 24, 2026
# Migrate now: just swap the model string.
The OpenAI-compatible endpoint accepts the same message format, tool_calls, JSON output mode, and streaming as the standard OpenAI SDK. The Anthropic-compatible endpoint (base_url="https://api.deepseek.com/anthropic") uses the same pricing — choose whichever SDK your stack already depends on. Note: V4 Flash does not include a Jinja-format chat template. For custom prompt construction, use DeepSeek's Python encoding scripts from the DeepSeek V4 Flash Hugging Face repository.
Thinking mode: when to use it
• Non-thinking (default): fast Q&A, summarization, classification, code autocomplete
• Think (reasoning_effort="high"): debugging, multi-step code generation, analysis tasks
• Think-Max (reasoning_effort="max"): requires 384K+ context allocated; use for the hardest reasoning tasks
Pricing does not change between modes — you are billed on tokens generated. Think-Max generates significantly more tokens (the reasoning chain is verbose), so effective cost is higher. For most developer tasks, "think" mode hits the right balance.
8. Reliability: Routing Flash Through Third-Party Providers
DeepSeek's hosted API routes through infrastructure in China. During peak demand — particularly around major model launches or viral moments — 503 errors and latency spikes are a documented issue. For hobby projects and cost-sensitive workloads with tolerance for occasional hiccups, the direct API is hard to beat. For mission-critical production systems, you need a reliability layer.
Recommended third-party providers for V4 Flash
• OpenRouter — unified gateway, routes to DeepSeek with fallback options; slight markup on DeepSeek's rates
• Together AI — reliable hosted inference with SLA commitments; V4 Flash available within days of launch
• Fireworks AI — fast inference infrastructure with flash model support and monitoring
At peak cache-hit rates through a third-party provider, the effective cost of V4 Flash is still a fraction of any Western frontier model. The modest routing premium (typically 10–20% over DeepSeek direct) is worth paying for teams with uptime requirements. For how other Chinese open-source models handle reliability tradeoffs, see the Qwen vs GLM vs Kimi comparison for production API use.
Enterprise context: DeepSeek's hosted API involves Chinese data residency. For teams in regulated industries or with US compliance requirements, self-hosting the open weights is the clean path — it sidesteps data sovereignty concerns entirely and gives you full control over inference behavior.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. Self-Hosting V4 Flash Locally
V4 Flash is 160GB on Hugging Face (FP4/FP8 mixed precision). V4 Pro is 865GB. Flash is the model that is realistically self-hostable for most teams — and possibly the individual developer, depending on hardware.
Hardware requirements
• API serving (recommended): 2× NVIDIA H100 or H200 (80GB VRAM each) — comfortable serving latency
• Consumer GPU self-hosting: 2× RTX 4090 (24GB VRAM each) + CPU offload — possible but slow
• Apple Silicon: M5 MacBook Pro (128GB unified memory) — early community tests suggest it is feasible with quantization; not confirmed for production throughput
• M3/M4 Max (48–128GB): Quantized Flash may be runnable; expect significant speed reduction
Quantized versions from Unsloth (Dynamic GGUFs) were not available as of April 24, 2026. Expect them to land within 1–2 weeks. Bartowski and ubergarm GGUFs typically follow within a similar timeframe. If you want to experiment with local Flash before quantized versions are available, vLLM supports the native FP4/FP8 checkpoints out of the box.
For the GLM-5.1 model (another strong open-weight option at MIT license), we covered its 8-hour autonomous local coding capability in the GLM-5.1 full review — it gives useful context for what serious self-hosted open-weight models can achieve in 2026.
10. Verdict: Start With Flash
Here is my honest recommendation, and I will make it short.
If you are building a new project: default to deepseek-v4-flash. Test it on your actual task distribution. Measure quality. If Flash fails on specific tasks — complex terminal agents, deep factual recall, expert-level reasoning — upgrade those specific calls to V4 Pro. Do not default to Pro "just to be safe." That is paying 12x for tasks Flash handles without breaking a sweat.
If you are currently using deepseek-chat or deepseek-reasoner: you are already on Flash. Migrate the model string explicitly before July 24, 2026 and pin the version. Done.
If you are comparing Flash against Claude Haiku or GPT-5.4 Nano: Flash wins on price and wins on benchmark capability. The tradeoff is data residency and production reliability — route through a third-party provider if uptime matters and you want to avoid direct Chinese API dependency.
For a broader picture of where V4 Flash fits in the full 2026 model landscape — including GPT-5.5 at 82.7% Terminal-Bench, Claude Opus 4.7 at 87.6% SWE-bench Verified, and how the open-source tier has closed the frontier gap — the GPT-5.5 full review and pricing analysis gives the complete competitive picture.
The bottom line: DeepSeek V4 Flash is not the budget option. It is the economically rational default for the majority of production LLM workloads in 2026.
Frequently Asked Questions
What is DeepSeek V4 Flash and how does it differ from V4 Pro?
DeepSeek V4 Flash is the fast, cost-optimized tier of DeepSeek's V4 model family, released April 24, 2026. It has 284 billion total parameters and 13 billion active per token, versus V4 Pro's 1.6 trillion total and 49 billion active. Both share a 1M-token context window and MIT license. Flash costs $0.14/M input and $0.28/M output; Pro costs $1.74/M input and $3.48/M output. On coding benchmarks, Flash is within 1.6 percentage points of Pro. On complex terminal-agent tasks, Pro leads by ~11 points.
How much does DeepSeek V4 Flash cost per million tokens?
The official DeepSeek API rate (April 2026) is $0.14 per million input tokens and $0.28 per million output tokens at cache-miss rates. Cache-hit input drops to $0.014/M — 1/10th of the standard rate. A 50% off-peak discount applies during Beijing nighttime hours. At typical 65–70% cache-hit rates for conversational workloads, effective input cost is roughly $0.06/M tokens. A 75% limited-time discount on V4 Pro is valid until May 5, 2026.
How do I migrate from deepseek-chat to deepseek-v4-flash?
Change model="deepseek-chat" to model="deepseek-v4-flash" in your API calls. The base_url, authentication, and message format are identical. If you use deepseek-reasoner, switch to model="deepseek-v4-flash" with reasoning_effort="high". The legacy endpoints are deprecated on July 24, 2026.
Is DeepSeek V4 Flash good enough for production?
For most production workloads — RAG pipelines, chatbots, code autocomplete, summarization, data classification — yes. Flash scores 79.0% on SWE-bench Verified and 91.6% on LiveCodeBench. The caveats: it is text-only (no multimodal), the hosted API runs in China (use a third-party provider for uptime SLAs), and it underperforms on complex terminal-agent tasks and deep factual recall. Test it on your actual workload for one week before committing.
Can DeepSeek V4 Flash handle a 1 million token context?
Yes. Both V4 Flash and V4 Pro support 1 million token context windows with a maximum output of 384,000 tokens. DeepSeek's hybrid CSA/HCA attention architecture makes 1M-context inference economically viable — V4 requires only 10% of the KV cache that V3.2 needed at the same context length. For Think-Max reasoning mode, DeepSeek recommends allocating at least 384K tokens to the context window.
How does DeepSeek V4 Flash compare to Claude Haiku 4.5?
On price, Flash wins clearly: $0.28/M output vs Haiku's ~$4.00/M output — roughly 14x cheaper on output. On capability, Flash scores 79.0% on SWE-bench Verified, which puts it well above most budget-tier models. Haiku 4.5 is proprietary (no self-hosting), runs on Anthropic's reliable infrastructure, and supports multimodal inputs that Flash does not. For pure cost-per-capability, Flash is the better deal. For teams needing Anthropic's reliability SLAs, enterprise compliance, or multimodal support, Haiku 4.5 may still be the right choice.
What are the hardware requirements to self-host V4 Flash?
V4 Flash weighs 160GB on Hugging Face (FP4/FP8 mixed precision). Recommended: 2× NVIDIA H100 or H200 GPUs. Consumer hardware experimentation is possible with 2× RTX 4090s using CPU offload, or an Apple M5 MacBook Pro (128GB) with quantization — but expect lower throughput than the hosted API. Quantized GGUFs from Unsloth and bartowski were not available at launch (April 24) but typically arrive within 1–2 weeks of major releases.
What happens to deepseek-chat after July 24, 2026?
The deepseek-chat and deepseek-reasoner endpoints will be fully retired and inaccessible after July 24, 2026. They currently route to deepseek-v4-flash non-thinking and thinking modes respectively, as a compatibility measure. Teams must explicitly migrate to deepseek-v4-flash or deepseek-v4-pro model IDs before the deadline. Waiting until after the deprecation date will cause API calls to fail.
Recommended Blogs
- DeepSeek V4-Pro Review: Benchmarks, Pricing & Architecture (2026)
- GPT-5.5 Review: Benchmarks, Pricing & Vs Claude (2026)
- Mixture of Experts (MoE) Explained: Why It Makes Flash So Cheap (2026)
- Best AI Models April 2026: Ranked by Benchmarks
- GLM-5.1: #1 Open Source AI Model? Full Review (2026)
- Kimi K2.6 vs GPT-5.4 vs Claude Opus: Who Wins? (2026)
- Every AI Model Compared: Best One Per Task (2026)
References
- DeepSeek. (2026, April 24). DeepSeek V4 Preview Release. DeepSeek API Docs.
- DeepSeek AI. (2026). DeepSeek-V4-Flash Model Card. Hugging Face.
- DeepSeek. (2026). Models & Pricing. DeepSeek API Docs.
- TechCrunch. (2026, April 24). DeepSeek previews new AI model that "closes the gap" with frontier models.
- Willison, S. (2026, April 24). DeepSeek V4—almost on the frontier, a fraction of the price.
- Artificial Analysis. (2026, April 24). DeepSeek V4 Flash (Reasoning, Max Effort) Analysis.
- Artificial Analysis. (2026, April 24). DeepSeek is back among the leading open weights models with V4 Pro and V4 Flash.
- MIT Technology Review. (2026, April 24). Three reasons why DeepSeek's new model matters.
- Lushbinary. (2026, April 24). DeepSeek V4-Pro vs V4-Flash: Benchmarks, Pricing & Guide.

