





GPT-5.5 Review: OpenAI's Smartest Agentic Model - Benchmarks, Pricing & Vs Claude (2026)
On April 16, 2026, Anthropic released Claude Opus 4.7 and reclaimed the coding crown with 64.3% on SWE-bench Pro. Exactly one week later, OpenAI fired back.
GPT-5.5 — codenamed 'Spud' internally — launched on April 23, 2026, to ChatGPT Plus, Pro, Business, and Enterprise subscribers. OpenAI's Greg Brockman called it 'a new class of intelligence' and 'a big step towards more agentic and intuitive computing.' The model is the first fully retrained base model since GPT-4.5, natively omnimodal, and leads every publicly available model on Terminal-Bench 2.0 at 82.7%. Its long-context reasoning jump is extraordinary: MRCR v2 at 1M tokens goes from 36.6% (GPT-5.4) to 74.0% — more than doubling.
There is one catch. The API price doubled from $2.50/$15 to $5/$30 per million input/output tokens. OpenAI says the effective cost increase is about 20% once you account for token efficiency. That math is worth examining — and I will.
Here is everything you need to know: what GPT-5.5 actually does, the full benchmark breakdown, the honest pricing math, how it compares to Claude Opus 4.7, and who should use which model for what task.
What Is GPT-5.5? (And What Makes It Different From GPT-5.4)
GPT-5.5 is OpenAI's most capable frontier model as of April 24, 2026 — the first fully retrained base model since GPT-4.5. Every model between GPT-4.5 and GPT-5.5 was an incremental update on the same architectural foundation. GPT-5.5 is a ground-up retraining pass, which is why OpenAI can claim meaningfully different characteristics rather than just better benchmark numbers.
Three things genuinely changed. First, the architecture is natively omnimodal — text, images, audio, and video are processed in a single unified system, not stitched together from separate models. Most previous 'multimodal' offerings were pipelines in a trench coat. GPT-5.5 is a single model that processes all modalities end-to-end. Second, the model was co-designed with NVIDIA's GB200 and GB300 NVL72 rack-scale systems — a hardware-software co-design process that let OpenAI optimize inference efficiency at a level prior models couldn't achieve. Third, in a detail that received surprisingly little coverage: GPT-5.5 and Codex helped rewrite OpenAI's own serving infrastructure before launch. Codex analyzed weeks of production traffic and rewrote load-balancing heuristics, resulting in a 20% boost in token generation speed. The model tuned the infrastructure that serves it.
The two GPT-5.5 variants work as follows. Standard GPT-5.5 is available to Plus, Pro, Business, and Enterprise users. GPT-5.5 Pro deploys extra parallel test-time compute on harder questions — it's the same underlying model, not a separate training run. Pro access is limited to Pro, Business, and Enterprise users. For most workloads, standard GPT-5.5 is the right starting point. GPT-5.5 Pro earns its keep on research tasks, hard math, and the deepest BrowseComp searches (90.1% vs 83.4% on standard).
For context on where GPT-5.5 sits within the full April 2026 AI model landscape — including open-source competitors like DeepSeek V4 and Qwen3.6 — our April 2026 AI model benchmark rankings covers the complete competitive picture across all major models.
Full Benchmark Breakdown: Where GPT-5.5 Wins and Where It Trails
OpenAI published a detailed benchmark table at launch comparing GPT-5.5 against Claude Opus 4.7, GPT-5.4, and Gemini 3.1 Pro. Unlike many model launches, they included benchmarks where they trail — a sign of genuine confidence. Here is the full picture:
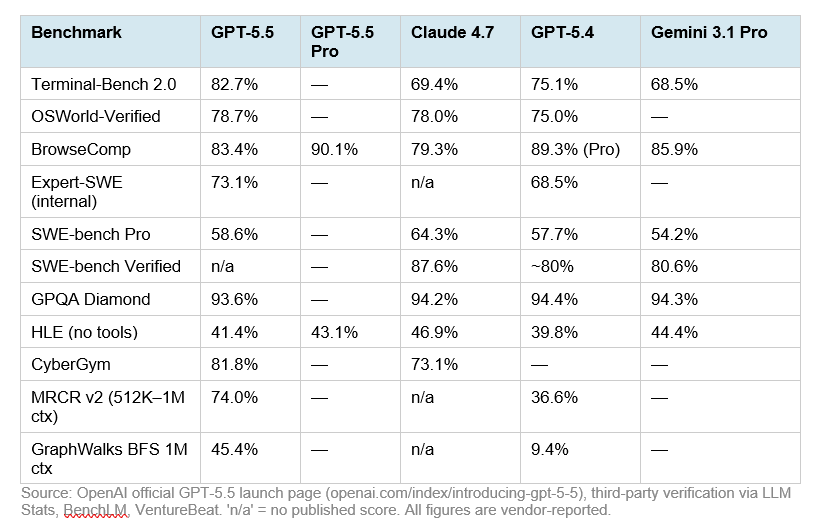
Source: OpenAI official GPT-5.5 launch page (openai.com/index/introducing-gpt-5-5), third-party verification via LLM Stats, BenchLM, VentureBeat. 'n/a' = no published score. All figures are vendor-reported.
Where GPT-5.5 Wins Clearly
Terminal-Bench 2.0 at 82.7% is GPT-5.5's most decisive win. This benchmark tests real command-line workflows: planning, iteration, and tool coordination in a sandboxed terminal environment. GPT-5.4's previous score was 75.1%. Claude Opus 4.7 sits at 69.4%. For developers building unattended terminal agents, pipeline runners, or DevOps automation, this benchmark matters more than SWE-bench. No publicly available model is close.
The long-context story is the most underreported improvement. On MRCR v2 at 512K–1M token contexts, GPT-5.5 jumps to 74.0% from GPT-5.4's 36.6% — a 37-point improvement. On GraphWalks BFS at 1M tokens, GPT-5.4 scored 9.4%. GPT-5.5 scores 45.4%. This is not marginal. If your workflows involve processing entire codebases, large document sets, or multi-hour conversation logs, GPT-5.5's long-context performance represents a qualitative leap over GPT-5.4.
OSWorld-Verified at 78.7% gives GPT-5.5 a marginal lead over Claude Opus 4.7 (78.0%) on real-computer-environment task completion — the benchmark that matters most for true computer-use agents that navigate actual software interfaces.
Where GPT-5.5 Trails
SWE-bench Pro is the clearest gap. Claude Opus 4.7 scores 64.3% versus GPT-5.5's 58.6% — a 5.7-point difference that is meaningful on this benchmark. SWE-bench Pro tests real GitHub issue resolution across multiple programming languages. For teams building production-grade coding agents that resolve novel PRs and multi-file bugs, Claude Opus 4.7 holds a genuine lead on this specific task type.
HLE (Humanity's Last Exam, no tools) shows Claude Opus 4.7 at 46.9% versus GPT-5.5's 41.4%. This benchmark tests expert-level cross-domain reasoning without tool assistance. Gemini 3.1 Pro (44.4%) and Claude Opus 4.7 both outperform GPT-5.5 here, suggesting that on raw knowledge-recall-heavy academic reasoning, OpenAI's model has not yet fully closed the gap.
MCP-Atlas: Claude Opus 4.7 scores 79.1% versus GPT-5.5's 75.3%. For teams heavily invested in multi-tool orchestration via the Model Context Protocol, Claude's lead on this benchmark reflects better tool-call reliability in complex, chained scenarios.
A note on methodology: OpenAI's system card includes an asterisk on SWE-bench Pro noting 'evidence of memorization' from other labs. Anthropic has published a filter re-score analysis showing their Opus 4.7 margin holds on decontaminated subsets. OpenAI did not publish a matched re-run. Keep this context in mind when comparing SWE-bench Pro scores between the two.
For a deeper look at Claude Opus 4.7's benchmark strengths — particularly the 64.3% SWE-bench Pro score and the 87.6% SWE-bench Verified result — our GLM-5.1 full review covers the competitive coding landscape that set the stage for both these flagship releases.
The Token Efficiency Story: Why 2x Price Isn't Really 2x Cost
The most counterintuitive claim in the GPT-5.5 launch: the API price doubled from GPT-5.4's $2.50/$15 to $5/$30 per million input/output tokens, yet OpenAI argues the effective cost increase is closer to 20% for most Codex workloads. How?
GPT-5.5 uses approximately 40% fewer output tokens to complete the same Codex task as GPT-5.4. If a task that cost GPT-5.4 100K output tokens at $0.015 per 1K tokens ($1.50) now costs GPT-5.5 60K output tokens at $0.030 per 1K tokens ($1.80), the per-task cost increased by $0.30 — not $1.50. OpenAI's own intelligence-per-cost analysis on the Artificial Analysis Index shows GPT-5.5 delivering 'state-of-the-art intelligence at half the cost of competitive frontier coding models.' That comparison is against Gemini 3.1 Pro and similar, not GPT-5.4.
The practical math for production teams: if you are running Codex at scale with 100 million output tokens per month on GPT-5.4, you paid $1,500. At the same task volume on GPT-5.5 (40% fewer tokens = 60M output tokens), you pay $1,800. The cost increase is 20%, not 100%. For teams where Codex's higher task completion rate means fewer retries, the efficiency argument is even stronger — failed tasks are pure cost with no output.
The contrarian view: this token-efficiency claim is entirely self-reported. OpenAI has not published the benchmark scaffold or token-count data from the Codex task comparison. Treat the 40% figure as a directional claim worth verifying on your own workloads before committing infrastructure decisions to it. Sam Altman can tweet efficiency gains — your billing dashboard will tell the truth.
One specific access detail worth knowing from OpenAI's Codex pricing page: GPT-5.5 uses significantly fewer tokens to achieve results comparable to GPT-5.4, with 'generous usage limits despite GPT-5.5 being a significantly more capable model.' OpenAI is actively absorbing some of the token efficiency gains to maintain subscription tier value — meaning Plus users get more done per month even if the model is pricier on the API side.
Pricing Deep Dive: GPT-5.5 vs Claude 4.7 vs DeepSeek V4
Here is the full pricing table across all major frontier options as of April 24, 2026:
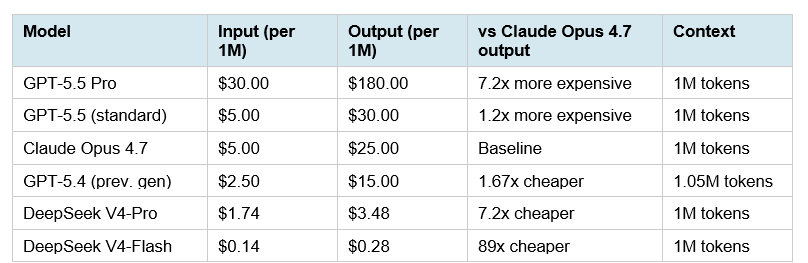
Source: Official OpenAI pricing page, Anthropic API pricing, DeepSeek API pricing (April 24, 2026). Pricing subject to change.
The practical cost scenarios for teams choosing between GPT-5.5 and Claude Opus 4.7:
At 10M output tokens/month: GPT-5.5 standard = $300. Claude Opus 4.7 = $250. GPT-5.5 standard costs 20% more. If GPT-5.5's better agentic performance means 25% fewer tasks (because it completes things in fewer passes), you break even.
At 100M output tokens/month: GPT-5.5 standard = $3,000. Claude Opus 4.7 = $2,500. DeepSeek V4-Pro = $348. For high-volume pipelines where the task type fits DeepSeek's strengths, the open-source option's cost advantage at scale is difficult to argue against.
GPT-5.5 Pro at $30/$180 per million tokens is a different product tier entirely. At $180/M output, it's designed for tasks where a single correct answer is worth more than the compute cost — legal review, financial analysis, scientific research. Reaching for GPT-5.5 Pro on bulk coding tasks is the fastest way to burn your API budget.
For the complete open-source alternative cost landscape including DeepSeek V4-Flash at $0.28/M output, see our DeepSeek V4-Pro full review and pricing breakdown — the 7x output cost advantage versus Claude Opus 4.7 changes the math significantly for teams who can accept open-source reliability tradeoffs.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
How to Access GPT-5.5 Right Now
GPT-5.5 rolled out beginning at approximately 10 AM PT on April 23, 2026. Access varies by subscription tier:
ChatGPT (Immediate)
GPT-5.5 Thinking is now live for Plus ($20/month), Pro ($200/month), Business, and Enterprise subscribers. GPT-5.5 Pro is available to Pro, Business, and Enterprise users only. Free-tier users remain on older model checkpoints for now — OpenAI has not announced a free-tier rollout timeline. Select GPT-5.5 from the model switcher at the top of the chat interface.
Codex (Immediate)
GPT-5.5 powers Codex for Plus, Pro, Business, Enterprise, Edu, and Go plan users with a 400K context window. A Fast mode is available at 1.5x speed for 2.5x the credit cost. OpenAI confirmed on April 23 that Pro users get 2x Codex usage through May 31, 2026, and that GPT-5.5 uses fewer tokens per Codex task than GPT-5.4, effectively maintaining or improving the practical usage limits despite the model upgrade.
API (Coming Soon)
The API is not yet live at the time of writing. OpenAI says it is coming 'very soon' pending additional safety and security guardrails for serving at scale. Announced pricing: $5/$30 per million input/output tokens for GPT-5.5 standard; $30/$180 per million for GPT-5.5 Pro. Both will support 1M token context windows in the API versus 400K in Codex. Batch and Flex modes will be available at half the standard API rate. Priority mode at 2.5x.
For a practical implementation pattern using OpenAI's API format that you can adapt when GPT-5.5 API goes live, the multi-model routing cookbook using Kimi K2.5 on OpenRouter demonstrates the exact base URL and model-routing architecture that applies to any OpenAI-compatible endpoint.
GPT-5.5 vs Claude Opus 4.7: The Routing Decision Framework
The April 2026 AI frontier is a two-model world for most teams. GPT-5.5 and Claude Opus 4.7 are not competing on the same axis — they optimized for different task categories. The most efficient stack routes tasks to the right model rather than picking one for everything.
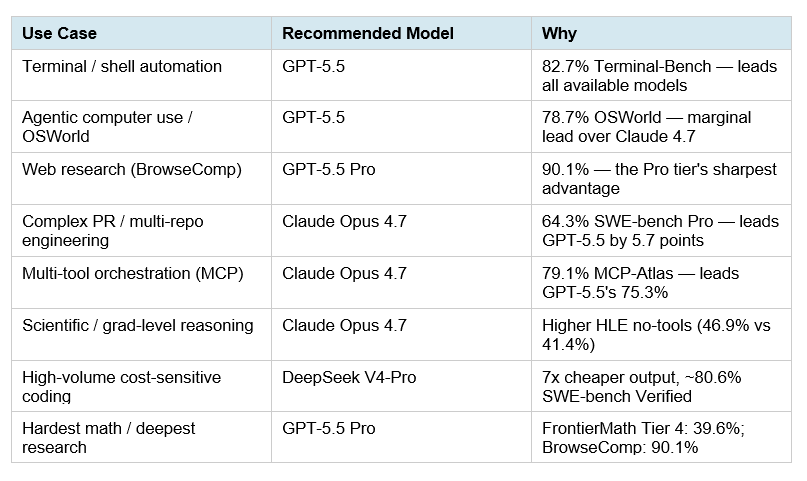
My honest read on the routing logic: if your agents are terminal-first (shell execution, pipeline running, DevOps automation), GPT-5.5 is the model to default to in April 2026. If your agents are codebase-first (PR review, multi-language refactoring, IDE-integrated agentic coding), Claude Opus 4.7 currently leads. The 5.7-point SWE-bench Pro gap is real and relevant for production software engineering.
For teams that can afford neither at scale: the open-source tier has genuinely closed the gap. DeepSeek V4-Pro at $3.48/M output scores 80.6% on SWE-bench Verified and 67.9% on Terminal-Bench 2.0. GLM-5.1 leads SWE-bench Pro at 58.4% under the MIT license. These are not 'good enough with caveats' options anymore — they are production-viable models at a fraction of frontier API costs.
For teams building multi-model routing architectures, the Qwen 3.6 Plus cookbook shows the OpenAI-compatible base URL swap pattern that makes implementing a GPT-5.5 / Claude / DeepSeek routing layer straightforward in practice.
The Super App Strategy: What OpenAI Is Actually Building
Greg Brockman called GPT-5.5 'one step closer to the creation of OpenAI's super app' during the press briefing. This framing is more important than the benchmark table.
The super app strategy is convergence: ChatGPT (conversation), Codex (coding agent), an AI browser (in development), and GPT-Image-2 (visual generation) merging into a single unified interface where AI can see your screen, read your files, browse the web, write and run code, and generate outputs — all in one session. NVIDIA's integration validates the direction. Over 10,000 NVIDIA employees across engineering, legal, marketing, finance, HR, and operations all have access to GPT-5.5-powered Codex. Jensen Huang's 'jump to lightspeed' email to all employees is a landmark data point: this is not a developer-only tool anymore. A company of 30,000+ people is restructuring work around AI agents.
I think the more honest version of this story is that the six-week release cadence — GPT-5.4 on March 5, GPT-5.5 on April 23 — is the real signal. OpenAI is not releasing models at this pace to win benchmarks. They are releasing at this pace to establish category lock-in before enterprise procurement cycles close. The company that has 10,000 employees at NVIDIA, all 30,000 employees at a Fortune 500, and tens of millions of ChatGPT users standardized on its interface has won the enterprise AI race regardless of which model has the highest SWE-bench Pro score in Q3 2026. That is the super app bet.
For historical context on how the GPT-5.x model family evolved from GPT-5.4 to here, our March 2026 AI model launches roundup covers the GPT-5.4 release that GPT-5.5 supersedes, including the tool search architecture and the 33% factual error reduction that made the 5.4 generation significant.
Frequently Asked Questions
What is GPT-5.5?
GPT-5.5 is OpenAI's most capable frontier model as of April 23, 2026 — the first fully retrained base model since GPT-4.5. It is natively omnimodal (processing text, images, audio, and video in a single unified architecture), achieves a state-of-the-art 82.7% on Terminal-Bench 2.0, and is designed for complex agentic workflows that require multi-tool coordination, long-horizon reasoning, and autonomous task execution. The internal codename was 'Spud.' It is currently available in ChatGPT and Codex for paid subscribers, with API access coming soon.
Is GPT-5.5 better than Claude Opus 4.7?
It depends on the task. GPT-5.5 leads on Terminal-Bench 2.0 (82.7% vs 69.4%), OSWorld-Verified (78.7% vs 78.0%), long-context retrieval (MRCR v2: 74% vs n/a), and CyberGym (81.8% vs 73.1%). Claude Opus 4.7 leads on SWE-bench Pro (64.3% vs 58.6%), SWE-bench Verified (87.6% vs n/a), HLE without tools (46.9% vs 41.4%), and MCP-Atlas tool orchestration (79.1% vs 75.3%). For terminal-first agentic workflows, GPT-5.5 is the stronger default. For production coding and multi-tool orchestration, Claude Opus 4.7 still leads.
How much does GPT-5.5 cost per million tokens?
GPT-5.5 standard costs $5 per million input tokens and $30 per million output tokens. GPT-5.5 Pro costs $30 per million input tokens and $180 per million output tokens. These prices represent a 2x increase over GPT-5.4 ($2.50/$15). However, OpenAI reports that GPT-5.5 uses approximately 40% fewer output tokens to complete the same Codex tasks as GPT-5.4, which can partially or fully offset the price increase depending on the workload. Claude Opus 4.7 costs $5/$25 per million tokens — 17% cheaper on output versus GPT-5.5 standard.
What is the difference between GPT-5.5 and GPT-5.4?
GPT-5.5 is the first fully retrained base model since GPT-4.5, while GPT-5.4 was an incremental update. Key differences: GPT-5.5 is natively omnimodal (unified multimodal architecture vs stitched pipeline), uses 40% fewer tokens per Codex task, scores 82.7% on Terminal-Bench 2.0 vs GPT-5.4's 75.1%, and achieves 74.0% on 1M-token MRCR v2 vs GPT-5.4's 36.6%. The API price doubled from $2.50/$15 to $5/$30. GPT-5.5 was co-designed with NVIDIA GB200/GB300 NVL72 rack-scale systems and matches GPT-5.4's per-token latency in real-world serving despite being a significantly more capable model.
How to access GPT-5.5 in ChatGPT?
GPT-5.5 Thinking is available now for ChatGPT Plus ($20/month), Pro ($200/month), Business, and Enterprise subscribers. Select it from the model switcher at the top of the ChatGPT interface. GPT-5.5 Pro is available to Pro, Business, and Enterprise users only. Free-tier users do not have access at launch. For Codex, GPT-5.5 is available across Plus, Pro, Business, Enterprise, Edu, and Go plans with a 400K context window. API access is coming 'very soon' at $5/$30 per million tokens with a 1M context window.
Is GPT-5.5 worth the price increase from GPT-5.4?
For teams running Codex-heavy workflows, OpenAI's self-reported 40% fewer tokens per task partially offsets the 2x per-token price — potentially reducing the effective cost increase to around 20%. Verify this on your own workloads before relying on it for budget planning. For teams that primarily use the API for standalone queries (not agentic Codex loops), the 2x price increase is real and Claude Opus 4.7 at $5/$25 is the better value at comparable capability. For research-grade tasks and deep web research, GPT-5.5 Pro's 90.1% BrowseComp score justifies premium pricing where that capability is the requirement.
What does agentic AI mean in GPT-5.5?
Agentic AI refers to a model that can plan, take multi-step actions, use tools, check its own work, and continue working toward a goal with minimal human supervision. GPT-5.5 is designed specifically for this mode: it can browse the web, write and debug code, analyze data, fill spreadsheets, and coordinate across software tools in a single autonomous session. The key improvement over prior models is that GPT-5.5 better understands the overall 'shape' of a complex task — why something is failing, where the fix needs to land, and what else in a codebase is affected — rather than treating each step as an isolated question.
What is GPT-5.5 Pro and who should use it?
GPT-5.5 Pro is a higher-accuracy variant that deploys extra parallel test-time compute on problems where it matters. It uses the same underlying model as standard GPT-5.5 but applies more inference compute on harder questions. It is available to Pro ($200/month), Business, and Enterprise users in ChatGPT. Key benchmark strengths: BrowseComp at 90.1% (leads all publicly available models), FrontierMath Tier 4 at 39.6%, HLE with tools at 57.2%. API pricing is $30/$180 per million tokens. Use GPT-5.5 Pro for legal review, financial analysis, scientific research, and tasks where the cost of a wrong answer significantly exceeds the compute cost.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Recommended Blogs
If this breakdown was useful, these posts cover the surrounding competitive landscape in April 2026:
References
TechCrunch — OpenAI releases GPT-5.5 (April 23, 2026)
Axios — OpenAI releases 'Spud' GPT-5.5 model (April 23, 2026)
VentureBeat — GPT-5.5 vs Claude Mythos Preview benchmarks (April 23, 2026)
NVIDIA Blog — OpenAI's New GPT-5.5 Powers Codex on NVIDIA Infrastructure
Lushbinary — GPT-5.5 vs Claude Opus 4.7: Benchmarks, Pricing & Coding
LLM Stats — GPT-5.5 vs Claude Opus 4.7 Full Comparison
Fortune — GPT-5.5 and AI model launches looking like software updates (April 23, 2026)

