





Kimi K2.6 vs GPT-5.4 vs Claude Opus 4.6: Who Actually Wins in 2026?
On April 20, 2026, Moonshot AI dropped Kimi K2.6 — and the developer community had the same reaction it did when DeepSeek R1 landed in January 2025. Overnight benchmarks showed a $0.60-per-million-token open-source model beating GPT-5.4 on SWE-Bench Pro and topping HLE with tools. I've been watching the Kimi series since K2 launched last July, and this release is different. It's not just iteratively better. It's the first open-weight model that I'd actually trust to run a 12-hour autonomous coding session without babysitting it.
So let's settle the comparison properly. Numbers, architecture, pricing, real limitations — and my honest verdict on which model to use for what.
1. What Is Kimi K2.6? (The Fast Version)
Kimi K2.6 is Moonshot AI's latest open-source multimodal agentic model, released on April 20, 2026, with 1 trillion total parameters and 32 billion active per token via a Mixture-of-Experts (MoE) architecture. It supports text, image, and video input, runs in both thinking and non-thinking modes, and ships under a Modified MIT License — meaning commercial use is free unless you exceed 100 million monthly active users or $20 million in monthly revenue.
Moonshot AI is a Beijing-based startup founded in 2023 and backed by Alibaba, currently valued at $4.8 billion. They've shipped five major model updates in nine months: K2 (July 2025), K2-0905 (September), K2-Thinking (November), K2.5 (January 2026), and now K2.6. Each version pushed a specific capability forward. K2.6 consolidates everything around one conviction: stamina. The ability to keep running complex tasks for hours without degrading.
I covered the K2.6 Code Preview when it launched on April 13 — if you want the full technical breakdown of what changed from K2.5, the Kimi Code K2.6 Preview walkthrough has the detailed comparison. But the short version: code accuracy up 12%, long-context stability up 18%, tool invocation success rate at 96.6%.
The model is available now on kimi.com (chat and agent mode), via the Kimi Code CLI, through the Moonshot API at platform.moonshot.ai, and as open weights on Hugging Face.
2. Benchmark Breakdown: K2.6 vs GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro
Kimi K2.6 leads the field on five of eight major agentic and coding benchmarks — while remaining the only open-weight model in the comparison.
Here's the full table. All results reflect vendor-published numbers as of April 21, 2026, with thinking modes enabled at maximum effort for each model:
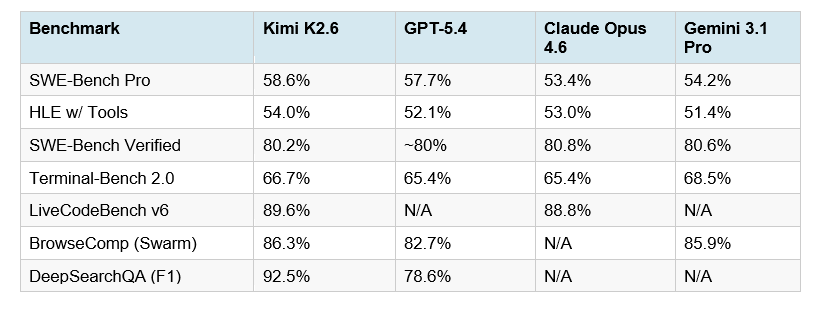
The number that should stop you: 54.0% on Humanity's Last Exam with tools. HLE is the hardest knowledge benchmark in current use, and the with-tools variant tests real-world agentic performance — how well a model actually uses external resources to solve problems it can't answer from memory alone. K2.6 leads every model in this category, including GPT-5.4 at 52.1% and Claude Opus 4.6 at 53.0%.
SWE-Bench Pro at 58.6% is equally significant. The benchmark tests real GitHub issue resolution across complex repositories. K2.6's 58.6% outpaces GPT-5.4 (57.7%), Claude Opus 4.6 (53.4%), and Gemini 3.1 Pro (54.2%). And it does this as an open-source model you can download and self-host.
For historical context: when I wrote the GPT-5.3 Codex vs Claude Opus vs Kimi comparison in February, Kimi K2.5 was sitting at 76.8% on SWE-Bench Verified and trailing the proprietary models on SWE-Bench Pro. K2.6 reversed that in three months.
DeepSearchQA at 92.5% F1 score versus GPT-5.4's 78.6% is the most lopsided win in the table. For any workflow involving autonomous web research and information synthesis, K2.6 is in a different category.
3. The Agent Swarm Upgrade: 300 Agents, 4,000 Steps, 12 Hours
The headline capability of K2.6 is not a single benchmark number. It's stamina. The model can run 300 parallel sub-agents executing 4,000 coordinated steps — and sustain this for over 12 hours of continuous autonomous coding.
K2.5 supported 100 sub-agents at 1,500 steps. K2.6 triples the agent count and nearly triples the step depth. That's not an incremental update. That's a fundamentally different operational ceiling.
Here's what this looks like in practice. In Moonshot's published showcase run, K2.6 took a prompt to optimize a locally deployed Qwen3.5-0.8B model for inference speed. The model downloaded the weights, rewrote the inference stack in Zig (a niche systems language), iterated through 14 optimization cycles over 4,000+ tool calls, and improved throughput from approximately 15 tokens per second to 193 tokens per second — a 20% speed improvement over LM Studio. Total runtime: 12 hours. Zero human intervention.
The new Claw Groups feature takes the swarm concept further. Instead of Moonshot's own infrastructure handling all sub-agents, Claw Groups lets external agents join the swarm: agents running on local laptops, mobile devices, cloud instances, and human workers. K2.6 acts as the coordinator, dynamically assigning tasks based on each participant's skills, detecting when a node stalls, and reassigning automatically.
If you want to build on top of this architecture yourself, the Kimi K2.5 Agent Swarm Cookbook in our gen-ai-experiments repo walks through the full parallel agent setup — the K2.6 swarm API follows the same patterns, just with expanded concurrency limits.
My take: the 12-hour autonomous run is not a demo flourish. For teams running overnight CI/CD agents, large-scale codebase refactors, or batch code generation pipelines, this is the operational minimum that makes agents actually useful in production. Every other frontier model right now requires more hand-holding than K2.6 for this class of task.
4. Architecture: Why MoE Gives K2.6 an Unfair Cost Advantage
Kimi K2.6 uses a Mixture-of-Experts (MoE) architecture: 1 trillion total parameters, but only 32 billion activate per forward pass. This is the same design philosophy that made DeepSeek V3 so disruptive — you get the intelligence of a trillion-parameter model at the inference cost of a 32B model.
The technical upgrades in K2.6 include a SwiGLU activation function (more hardware-efficient than its predecessor), a MoonViT vision encoder (native multimodal processing for text, image, and video), and a context length of 262,144 tokens. The model runs in both thinking and non-thinking modes, and supports native INT4 quantization for 2x faster inference on consumer hardware.
One interesting downstream consequence: Cursor's Composer 2, released in March 2026, is built on top of Kimi K2.5's MoE architecture. As I covered in the Cursor Composer 2 review, Cursor used K2.5 as the base and applied its own RL training on top. The MoE architecture made that commercially viable because the inference cost profile stays manageable even at IDE scale.
Deployment options for self-hosting: vLLM, SGLang, and KTransformers are all officially supported. Weights are on Hugging Face under the Modified MIT License. Ollama cloud support launched on day one — which tells you how fast the ecosystem moved on this.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Pricing Comparison: What You Actually Pay
This is where the K2.6 argument gets genuinely hard to argue with. Frontier performance at 4-17x lower cost than proprietary alternatives is not a minor efficiency gain — it's a budget-level decision for any team running agents at scale.
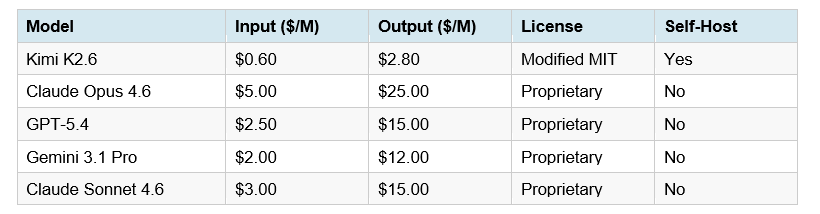
Running 100 million input tokens and 10 million output tokens monthly — a realistic load for a mid-sized startup running coding agents — costs roughly $85 with Kimi K2.6. The same workload on Claude Opus 4.6 costs approximately $2,550. Annual difference: $29,580. That's a meaningful engineering hire.
Context caching makes the K2.6 economics even better. Cached input tokens cost $0.15 per million (versus $0.60 standard) — a 75% reduction that happens automatically with no configuration. Teams maintaining large system prompts or repeated context across sessions see this benefit immediately. For a full cost modeling exercise, the Kimi K2.5 review with Claude cost comparison has a detailed annual spend breakdown for different usage tiers.
One caveat on the Kimi Code subscription tier: the token quota system allocates 300 to 1,200 API calls per 5-hour window with a max concurrency of 30. For automated pipelines running continuously, you need to be quota-aware. This is fine for most developer workflows but matters for heavy overnight batch jobs.
6. Where K2.6 Does NOT Win (Honest Assessment)
K2.6 is the best open-source agentic coding model available right now. It is not the best model for everything, and being clear about the gaps matters more than headline hype.
Pure reasoning benchmarks: GPT-5.4 still leads on AIME 2026 (99.2% vs K2.6's 96.4%) and GPQA Diamond (92.8% vs 90.5%). For tasks requiring flawless single-shot reasoning on self-contained hard problems — advanced math, physics — GPT-5.4 is still the safer pick.
Raw vision tasks: Gemini 3.1 Pro holds the lead on pure vision benchmarks, benefiting from deep Google infrastructure integration. K2.6's MoonViT encoder is capable, but Gemini's multimodal depth remains stronger for heavy document-processing workloads.
GUI-based automation: GPT-5.4 leads OSWorld (75.0%) — the benchmark for desktop GUI task completion. For agents that need to navigate desktop interfaces rather than terminal/API environments, GPT-5.4 has a meaningful edge.
Context window: GPT-5.4 reportedly supports a 1M token context in Codex. K2.6's 262K is large, but for workflows requiring truly massive context (entire codebases in a single prompt), this gap is real.
Model version pinning: The Moonshot API currently returns "kimi-for-coding" as the model identifier regardless of which underlying version is active. For teams running reproducible CI/CD workflows where pinning an exact model version matters, this is a real friction point.
My contrarian point: I think most teams default to Claude Opus 4.6 for frontend work when Sonnet 4.6 is the correct answer — and the same pattern applies here. For most coding agent workflows, K2.6 is the right default, with proprietary models reserved for the specific task types where they demonstrably lead. If you're still figuring out model routing for frontend work specifically, this guide on the best AI models for UI development in 2026 breaks down where each model actually wins on visual coding tasks.
7. How to Get Started with Kimi K2.6
There are four ways to access K2.6 today, depending on what you need:
kimi.com: Free access in chat and agent mode with usage limits. Best for testing before committing to API costs.
Kimi Code CLI: The fastest path for coding workflows. Install the CLI, authenticate, and set kimi-k2.6 as your default model. Supports 300-agent swarm mode from the terminal.
Moonshot API (platform.moonshot.ai): OpenAI-compatible API. Drop in your Moonshot API key with the api.moonshot.ai/v1 endpoint and your existing SDK calls work without changes. Pricing at $0.60/M input and $2.80/M output. Recommended temperature 1.0 for thinking mode, 0.6 for instant mode.
Hugging Face (self-host): Weights available at moonshotai/Kimi-K2.6. Deploy via vLLM, SGLang, or KTransformers. The Modified MIT License covers commercial use below the revenue and MAU thresholds.
Ollama (cloud): Run ollama launch openclaw --model kimi-k2.6:cloud or ollama launch claude --model kimi-k2.6:cloud. Zero setup, cloud-hosted inference.
One thing to know: when using tools in thinking mode, tool_choice can only be set to "auto" or "none". Setting any other value throws an error. And keep reasoning_content from the assistant message in context during multi-step tool calling — dropping it causes errors in chained calls.
Frequently Asked Questions
What is Kimi K2.6 and who made it?
Kimi K2.6 is an open-source multimodal agentic AI model released on April 20, 2026 by Moonshot AI, a Beijing-based startup backed by Alibaba and valued at $4.8 billion. It has 1 trillion total parameters with 32 billion active per token via a Mixture-of-Experts architecture, and is available free under a Modified MIT License on Hugging Face and kimi.com.
Is Kimi K2.6 better than GPT-5.4 for coding?
On SWE-Bench Pro, Kimi K2.6 scores 58.6% versus GPT-5.4's 57.7% — making it the top-ranked model on real-world GitHub issue resolution. K2.6 also leads on HLE with tools (54.0% vs 52.1%) and DeepSearchQA (92.5% F1 vs 78.6%). GPT-5.4 retains the lead on pure reasoning benchmarks like AIME 2026 and desktop GUI tasks (OSWorld: 75.0%). For agentic coding workflows, K2.6 is currently the stronger choice.
How does Kimi K2.6 compare to Claude Opus 4.6?
K2.6 outperforms Claude Opus 4.6 on SWE-Bench Pro (58.6% vs 53.4%), HLE with tools (54.0% vs 53.0%), and DeepSearchQA. Claude Opus 4.6 leads on SWE-Bench Verified (80.8% vs 80.2%) and pure enterprise reasoning tasks. K2.6's API costs $0.60/M input versus Claude Opus's $5.00/M — roughly an 8x cost advantage.
What is Agent Swarm in Kimi K2.6?
Agent Swarm is K2.6's multi-agent execution architecture that coordinates up to 300 parallel sub-agents, each executing up to 4,000 steps. The orchestrator decomposes a task into specialized subtasks, assigns them to domain-specific agents, monitors for failures, and reassigns automatically. K2.6 can sustain this for over 12 hours of continuous autonomous execution across Rust, Go, Python, and other languages.
Is Kimi K2.6 free to use?
Yes, with limits. Free access is available via kimi.com in chat and agent mode with usage caps. API access through platform.moonshot.ai costs $0.60 per million input tokens and $2.80 per million output tokens. Model weights are free to download from Hugging Face for self-hosting under the Modified MIT License, with commercial use permitted below 100 million monthly active users and $20 million monthly revenue.
Can I self-host Kimi K2.6?
Yes. Model weights are published on Hugging Face at moonshotai/Kimi-K2.6 under the Modified MIT License. Supported inference engines include vLLM, SGLang, and KTransformers, with native INT4 quantization for 2x faster inference on consumer hardware. Moonshot also provides a Kimi Vendor Verifier to confirm correct output from third-party deployments.
How does the Kimi K2.6 API pricing compare to Claude Sonnet 4.6?
Kimi K2.6 costs $0.60 per million input tokens and $2.80 per million output tokens. Claude Sonnet 4.6 costs $3.00 per million input and $15.00 per million output — making K2.6 approximately 5x cheaper on input and 5-6x cheaper on output. For a team processing 100 million input tokens and 10 million output tokens monthly, K2.6 costs roughly $85 versus $450 for Claude Sonnet 4.6.
What is Claw Groups in Kimi K2.6?
Claw Groups is a research preview feature in K2.6 that extends the Agent Swarm architecture beyond Moonshot's own infrastructure. It allows users to add external agents from any device (local laptops, mobile, cloud) and human workers into the same swarm. K2.6 acts as the central coordinator, dynamically routing tasks based on each participant's skills and managing failures automatically across the hybrid human-agent network.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Recommended Blogs
These are real posts on BuildFastWithAI that go deeper on the models and concepts covered in this article:
• GPT-5.3 Codex vs Claude Opus vs Kimi: February 2026 Comparison
• Cursor Composer 2 Review: Benchmarks, Pricing & The Kimi K2.5 Connection

