





Best AI for Coding 2026: Nemotron 3 Super vs GPT-5.3-Codex vs Claude Opus 4.6
Open-source AI just made a decision that closed-source labs should be genuinely worried about.
On March 11, 2026, NVIDIA dropped Nemotron 3 Super at GTC. A 120-billion-parameter model. Open weights. Free to self-host. And it just hit 60.47% on SWE-Bench Verified, leading every open-weight model on the planet for real-world software engineering tasks. That same week, GPT-5.3-Codex and Claude Opus 4.6 were sitting at 80% on the same benchmark, confident in their proprietary moats. But here's the thing nobody is talking about: Nemotron runs on 64GB of RAM. You can deploy it today. For free.
I've been watching the gap between open and closed AI narrow month by month. In 2023 it was years. In 2024 it was months. Today? For coding specifically, you are choosing between "20 points better and costs money" versus "free forever, getting better every quarter, and already good enough for most production work." That choice is going to define a lot of engineering budgets in 2026.
This piece breaks down the three most important coding AI releases of the year: NVIDIA Nemotron 3 Super, GPT-5.3-Codex, and Claude Opus 4.6. Real benchmarks, real cost math, real deployment scenarios.
What Is NVIDIA Nemotron 3 Super?
Nemotron 3 Super is NVIDIA's open-weight flagship for agentic coding, released March 11, 2026. The headline architecture is unusual: a hybrid that combines Mamba-2 state space model layers, Transformer attention layers, and a new mixture-of-experts design called LatentMoE, all in one 120-billion-parameter model with only 12 billion active parameters per token.
That 12B active parameter number is what makes Nemotron competitive. You get the reasoning depth of a 120B model at the compute cost of something far smaller. NVIDIA's LatentMoE compresses tokens into a latent space before routing to experts, activating 4x more experts at the same compute cost as older MoE designs. The result is 2.2x higher inference throughput than GPT-OSS-120B and up to 7.5x faster than Qwen3.5-122B on comparable hardware.
The context window is 1 million tokens. Unlike most models that degrade badly past 256K, Nemotron 3 Super holds 91.75% accuracy at 1M tokens on the RULER benchmark versus GPT-OSS-120B's 22.30% at the same length. For agentic coding workflows involving large codebases, that retention difference is not trivial.
I think NVIDIA is playing a long game here. They train the hardware most AI runs on, and now they are releasing the model that runs best on that hardware. Nemotron 3 Super was pre-trained for over 25 trillion tokens with a data cutoff of June 2025, trained natively in NVFP4 4-bit precision from the first gradient update. The entire training recipe is publicly released.
SWE-Bench Scores Side by Side
SWE-Bench Verified is still the best single proxy for real-world software engineering capability. It tests models on actual GitHub issues, measures whether they can generate patches that pass unit tests, and runs everything in an isolated environment. Here is where things stand as of March 2026:
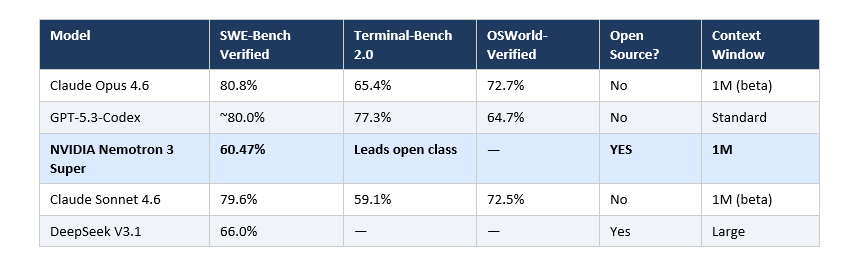
The 20-point gap between Nemotron and the top proprietary models is real and meaningful for complex tasks. For multi-file refactors with intricate dependencies or obscure bug traces, Opus 4.6 and GPT-5.3-Codex will outperform.
But here is the contrarian read: the benchmark gap looks bigger than the real-world gap. SWE-Bench Verified is Python-only. The harness (the agent scaffolding around the model) explains enormous variance, sometimes more than 22 points on SWE-Bench Pro. Nemotron's 45.78% on SWE-Bench Multilingual versus GPT-OSS-120B's 30.80% suggests that on non-Python tasks, the gap narrows considerably.
GPT-5.3-Codex has a meaningful edge on Terminal-Bench 2.0, scoring 77.3% versus Opus 4.6's 65.4%, an 11.9-point lead for CLI-heavy workflows. If your work is infrastructure-as-code, DevOps automation, or terminal-based debugging loops, Codex is the specialist for that job.
Open Source vs Paid: When Does Free Win?
The honest answer is: free wins more often than the benchmark leaderboard suggests.
The reason is economics. A team running 50 coding tasks per day on Claude Opus 4.6 at $5 per million input tokens and $25 per million output tokens accumulates real costs fast. GPT-5.3-Codex pricing is in a similar range for paid users. Nemotron 3 Super via DeepInfra API runs at $0.10 per million input and $0.50 per million output tokens. That is roughly 10-50x cheaper per token before you even consider self-hosting.
Self-hosting is where the economics flip entirely. Nemotron 3 Super can run on a machine with 64GB of RAM or VRAM at GGUF quantized precision. The NVIDIA Open Model License is commercially usable, grants perpetual royalty-free rights, and allows derivative fine-tuned models as long as attribution is included.
Three scenarios where free clearly wins:
- High-volume automation: Batch coding agents, automated code review at CI/CD scale, or test generation pipelines. The cost difference at 10M+ tokens per month dwarfs the accuracy gap.
- Data privacy requirements: Many enterprises cannot send proprietary code to any external API. For these teams, Nemotron 3 Super is not just cheaper, it is the only viable frontier option.
- Budget teams and solo devs: For an indie developer or a small startup, $100-500 per month on API costs for AI coding assistance has real budget impact. Nemotron removes that constraint.
Where proprietary wins:
- Single-turn tasks where accuracy is binary and debugging wasted time costs more than API fees
- Terminal-heavy DevOps workflows where GPT-5.3-Codex's 77.3% Terminal-Bench is best available
- Deep scientific reasoning tasks requiring Opus 4.6's 91.3% GPQA Diamond performance
Local Deployment Cost Analysis
Let me make this concrete with numbers.
Self-Hosting (BF16 Full Precision)
- Hardware requirement: 8x H100-80GB GPUs
- Cloud rental estimate: ~$20-25/hour per node
- For 8 hours of daily batch workloads: ~$160-200/day
- Monthly cost: ~$4,800-6,000 for dedicated capacity
- Best for: Enterprise teams doing high-volume automated code review
Self-Hosting via GGUF Quantization
- Hardware requirement: 64GB RAM/VRAM (single A100 80GB or Mac Studio Ultra)
- Comparable cloud instance: ~$2-4/hour
- For 8 hours/day: $16-32/day, or run locally at near-zero marginal cost
- Best for: Solo developers, small teams, or anyone with existing GPU hardware
API Cost Comparison
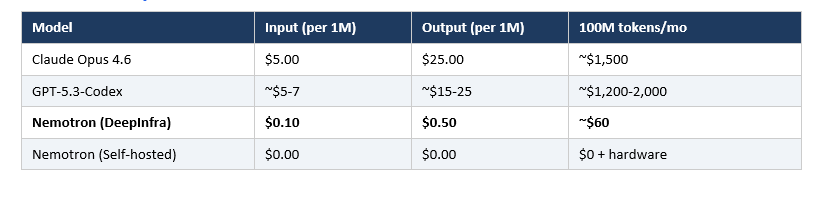
The honest conclusion: for teams spending more than $500/month on AI coding APIs, it is worth running a two-week pilot of Nemotron 3 Super on your actual tasks and measuring acceptance rate, not benchmark score. Generic benchmarks do not predict your specific repo.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
What Each Model Does Best
These three models have genuinely different personalities, not just different scores.
NVIDIA Nemotron 3 Super: The Agentic Workhorse
Its PinchBench score of 85.6%, making it the best open model as the brain of a multi-step coding agent, is more indicative of its real strengths than SWE-Bench alone. The built-in Multi-Token Prediction achieves a 3.45 average acceptance length per verification step (versus DeepSeek-R1's 2.70), giving 2-3x wall-clock speedup in structured code generation without a separate draft model. For long-running autonomous agents that need to maintain context across hours of work, Nemotron is the open-source answer.
GPT-5.3-Codex: The Terminal Specialist
The 77.3% Terminal-Bench 2.0 score is not noise. OpenAI trained this model specifically for the pattern of execute command, read output, decide next action, repeat. It is 25% faster than its predecessor. If your primary use case is CLI automation, SRE tooling, or CI/CD pipeline management, GPT-5.3-Codex is the most purpose-built option available.
Claude Opus 4.6: The Deep Reasoner
The 80.8% SWE-Bench Verified plus 72.7% OSWorld-Verified plus 91.3% GPQA Diamond forms a combination no other model matches across the full stack. The 1M-token context window with 76% accuracy at that length (versus GPT-5.2's 18.5%) makes it the only model suited to actually reading an entire enterprise codebase. Anthropic's Agent Teams feature enables parallel multi-agent coordination for complex, multi-step engineering projects. For large architectural refactors, security audits, or anything requiring sustained reasoning over massive context, Opus is still the clear choice.
Best For: Solo Devs, Enterprise, and Budget Teams
Solo Developers
Start with Nemotron 3 Super via DeepInfra at $0.10/$0.50 per million tokens for the bulk of your work. For the 10-20% of tasks requiring deep multi-file reasoning, escalate to Claude Sonnet 4.6 at $3/$15, which sits at 79.6% on SWE-Bench and is five times cheaper than Opus. You will have a two-tier system that covers 90% of use cases at minimal cost.
Enterprise Teams With Data Privacy Requirements
Self-host Nemotron 3 Super. The NVIDIA Open Model License explicitly permits commercial use, grants ownership of all outputs, and allows fine-tuned derivatives. A single A100 80GB running quantized Nemotron can serve a small engineering team effectively.
Budget Teams (Startups, Early-Stage Companies)
The math is simple. Nemotron 3 Super API costs are 25x lower than Claude Opus 4.6. At 20M tokens per month, that is $12 versus $300. Use the savings to buy human engineering time.
AI Agent Developers Building Production Pipelines
Multi-agent systems running in parallel are exactly the use case where Nemotron's 2.2x throughput advantage compounds. More agents per dollar, longer context retention, and open-source means full customization of the serving layer.
Enterprise Teams Needing Maximum Output Quality
Claude Opus 4.6 remains the benchmark leader for complex, multi-file software engineering. The $5/$25 pricing is premium, but for tasks where one error costs $50,000 in debugging time, the accuracy premium pays for itself.
What's Coming Next
NVIDIA has stated that Nemotron 3 Super is one model in a continuing family. The RL training infrastructure (NeMo Gym) and the full recipe are public, meaning the research community can build on them. I expect SWE-Bench Verified scores for open-weight models to breach 70% before the end of 2026.
GPT-5.4 (already released as of March 2026) consolidates Codex's coding strengths with broader reasoning in a single model. The coding specialist category may consolidate into general-purpose frontier models rather than remaining separate.
My honest prediction: in 18 months, the open-source vs. proprietary coding debate looks completely different. The gap at the frontier will probably stay. But the "good enough for 80% of tasks" threshold will be well within open-source territory for anyone willing to self-host.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 (2026)
- General Purpose LLM Agent: Architecture and Setup
- Building Smart AI Agents with ReAct Patterns
- Atomic Agents: Modular AI for Scalable Applications
- OpenAI Agents: Automate AI Workflows
Want to learn how to build AI coding agents and production apps using models like these? Join Build Fast with AI's Gen AI Launchpad, an 8-week structured program to go from 0 to 1 in Generative AI. Register here: buildfastwithai.com/genai-course
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Frequently Asked Questions
What is NVIDIA Nemotron 3 Super?
NVIDIA Nemotron 3 Super is a 120-billion-parameter open-weight AI model released at GTC on March 11, 2026. It uses a hybrid Mamba-Transformer MoE architecture with only 12 billion active parameters per token. It scores 60.47% on SWE-Bench Verified, leading all open-weight models, and runs on hardware with 64GB of RAM or VRAM.
How does Nemotron 3 Super compare to GPT-5.3-Codex on coding benchmarks?
GPT-5.3-Codex scores approximately 80% on SWE-Bench Verified versus Nemotron's 60.47%, roughly a 20-point lead on Python coding tasks. However, GPT-5.3-Codex costs significantly more per token and cannot be self-hosted. On multi-language tasks, the gap narrows: Nemotron scores 45.78% on SWE-Bench Multilingual versus GPT-OSS-120B's 30.80%.
Can I self-host NVIDIA Nemotron 3 Super for free?
Yes. The model weights are available on Hugging Face under the NVIDIA Open Model License, which permits commercial use. Full-precision deployment requires 8x H100-80GB GPUs. Quantized GGUF versions run on a single device with 64GB of RAM or VRAM.
What is Claude Opus 4.6's pricing in 2026?
Claude Opus 4.6 is priced at $5 per million input tokens and $25 per million output tokens for prompts under 200K tokens. For prompts exceeding 200K tokens, input pricing doubles to $10 per million and output increases to $37.50 per million.
Which AI model is best for solo developers in 2026?
For solo developers, the most cost-effective setup is Nemotron 3 Super via DeepInfra ($0.10/$0.50 per million tokens) for high-volume tasks, with Claude Sonnet 4.6 ($3/$15) for complex reasoning. This two-tier system delivers excellent coverage at a fraction of the cost of Opus 4.6 or GPT-5.3-Codex.
Is NVIDIA Nemotron 3 Super good enough for production coding work?
For most production use cases, yes. A 60.47% SWE-Bench Verified score means successful resolution on over 60% of real GitHub issues. Combined with its 85.6% PinchBench score (best open model for agentic tasks) and 1M-token context retention at 91.75% accuracy, it handles long-horizon agent workflows at reasonable cost.
What is SWE-Bench Verified and why does it matter?
SWE-Bench Verified tests AI models on 500 real-world GitHub issues from open-source repositories. Models must generate code patches that pass the original test suites, all within isolated Docker containers. It is considered the most realistic proxy for actual software engineering capability because it uses real bugs and real tests rather than synthetic problems.
References
- NVIDIA Nemotron 3 Super Technical Report — NVIDIA Research
- Introducing NVIDIA Nemotron 3 Super (Developer Blog) — NVIDIA Developer Blog
- Introducing GPT-5.3-Codex — OpenAI
- Claude Opus 4.6 Benchmarks and Features — Digital Applied
- Nemotron 3 Super Benchmarks and Architecture — LLM Stats
- Best AI for Coding 2026: Every Model Ranked — Morph LLM
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 — Build Fast with AI

