





Best AI Models April 2026: GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro and 5 More — Fully Compared
Published: April 26, 2026 | By Build Fast with AI | 14 min read
Twelve significant AI model releases dropped in a single week in March 2026. Then April arrived — and one-upped it. GPT-5.5, Claude Opus 4.7, DeepSeek V4, Qwen 3.6 Max-Preview, and Meta Muse Spark all launched within the same month, running in parallel with Grok 4.20's maturing API and GLM-5.1's historic open-source benchmark record. If you're trying to figure out which model to use, build on, or bet on — this is the guide.
We've benchmarked all eight models, compared them on performance, features, and use cases, identified the winner for every major task, and analyzed what April's release wave tells us about where AI is heading.
1. April 2026 at a Glance — The Month That Rewrote the Rankings
April 2026 is already the most consequential single month in AI model history, and we're still in it. The benchmark leaderboards changed hands multiple times. An open-source model (GLM-5.1) briefly held the #1 spot on SWE-bench Pro — the first time any open-weight model ever topped that benchmark — before Claude Opus 4.7 arrived and reclaimed it nine days later. GPT-5.5 then launched with a fully retrained base architecture, the first since GPT-4.5, and claimed the top spot on the Artificial Analysis Intelligence Index. All of this happened in a single 26-day window.
Here is the timeline of what shipped:
- April 2, 2026 — Google Gemma 4 (open, Apache 2.0, up to 31B)
- April 5, 2026 — Meta Llama 4 Scout + Maverick (open MoE)
- April 7, 2026 — GLM-5.1 open weights released by Z.ai (MIT)
- April 8, 2026 — Meta Muse Spark (first proprietary Meta model ever)
- April 16, 2026 — Claude Opus 4.7 by Anthropic (generally available)
- April 20, 2026 — Qwen 3.6 Max-Preview by Alibaba
- April 23, 2026 — GPT-5.5 by OpenAI (first fully retrained base since GPT-4.5)
- April 24, 2026 — DeepSeek V4-Pro + V4-Flash preview (MIT open weights)
For the full March context that led into this wave, see our breakdown of the 12+ AI Models That Dropped in March 2026 — it covers how GPT-5.4, Grok 4.20, and Gemini 3.1 Pro set the stage.
2. The 8 Models: Individual Deep Dives
GPT-5.5 — OpenAI's First Full Retrain Since GPT-4.5
Released April 23, 2026, GPT-5.5 is not a post-training increment. OpenAI rebuilt the architecture, pretraining corpus, and objectives from scratch — the first time they've done that since GPT-4.5. Every GPT-5.x release between (5.1 through 5.4) was a post-training iteration on the same base. This one is not.
The result is a model that tops the Artificial Analysis Intelligence Index at 60, scores 82.7% on Terminal-Bench 2.0 (7.6 points above GPT-5.4), and finishes Codex coding tasks with roughly 40% fewer output tokens than its predecessor. The doubling of API price to $5/$30 per million tokens is the obvious downside — but Artificial Analysis measured the effective cost increase at around 20% when token efficiency is factored in.
• Context: 1M tokens (API), 400K (Codex)
• Pricing: $5/$30 per MTok standard; $30/$180 for Pro variant
• Strength: Agentic coding, computer use, long-horizon planning, FrontierMath
• Weakness: Hallucinations higher than Claude, trails on SWE-bench Pro (58.6% vs Claude's 64.3%)
• Output speed: 74.7 tokens/second
Gemini 3.1 Pro — Google's Science and Reasoning Champion
Released February 19, 2026, Gemini 3.1 Pro is Google DeepMind's most significant mid-cycle update ever — and the pricing is unchanged from Gemini 3 Pro. It accepts text, images, audio, video, and code in a single 1M-token context window. On GPQA Diamond (graduate-level science reasoning), it hits 94.3% — the top score of any model on this list. On ARC-AGI-2, it reaches 77.1%, more than double the previous version's 31.1%.
My honest take: at $2/$12 per million tokens, Gemini 3.1 Pro is the best price-to-performance model at the frontier right now. You get near-top-tier intelligence at 60% less than Claude and GPT-5.5. The catch is output length — it generates more tokens per task than competitors, which eats into the cost advantage at scale.
• Context: 1M tokens; max output 65K tokens
• Pricing: $2/$12 per MTok (under 200K context); $4/$18 above
• Strength: Scientific reasoning (GPQA #1), output speed (129 t/s), price-performance
• Weakness: Trails Claude on expert knowledge-work preference (GDPVal-AA Elo: 1,317 vs 1,753)
Claude Opus 4.7 — The Coding and Agentic Workflow Leader
Released April 16, 2026, Claude Opus 4.7 is Anthropic's most capable generally available model and the one I'd recommend for any team doing serious production agentic work. At the same $5/$25 price as Opus 4.6, it delivers an 87.6% SWE-bench Verified score (up from 80.8%), a 64.3% SWE-bench Pro score (up from 53.4%), and the best MCP Atlas tool-use performance of any model (79.1%). Coding is the headline, but vision is the surprise — image resolution jumped from 1.15MP to 3.75MP, enabling dense screenshot analysis that wasn't viable before.
One practical migration warning: Opus 4.7 uses a new tokenizer that can increase token counts by 1.0–1.35x for the same input. Budget-sensitive teams should replay real workloads before switching.
• Context: 1M tokens; max output 128K tokens
• Pricing: $5/$25 per MTok — unchanged from Opus 4.6
•New: xhigh effort level, 3.75MP vision, task budgets (beta), /ultrareview in Claude Code
•Strength: Coding (SWE-bench #1), agentic tool use (MCP Atlas #1), vision resolution
•Weakness: BrowseComp regressed vs Opus 4.6 (79.3% vs 83.7%); Terminal-Bench trails GPT-5.5
Meta Muse Spark — The Billion-User Distribution Play
Released April 8, 2026, Muse Spark is the most strategically interesting release of the month, and the one that gets the least technical coverage. This is Meta's first proprietary closed-weights model — a full reversal from their Llama open-source strategy — developed by Meta Superintelligence Labs under Alexandr Wang, nine months after Meta's $14.3 billion Scale AI deal. The model uses "thought compression" during reinforcement learning, forcing it to solve complex problems with fewer reasoning tokens.
On the Artificial Analysis Intelligence Index, Muse Spark scores 52, placing it within striking distance of Claude Opus 4.7 (53) and Gemini 3.1 Pro (57). On figure-understanding vision tasks (CharXiv Reasoning), it scores 86.4 — outperforming Claude Opus 4.6 (65.3) and GPT-5.4 (82.8). The practical impact: Meta has 3+ billion monthly active users across WhatsApp, Instagram, and Facebook. No other AI company can distribute to that audience. Muse Spark isn't competing on benchmarks — it's competing on reach.
Context: Undisclosed; consumer-facing only
Pricing: No API; access via meta.ai, WhatsApp, Instagram, Messenger, Ray-Ban glasses
Strength: Multimodal vision (CharXiv #2), distribution scale, thought-compression efficiency
Weakness: No API access, no developer ecosystem, no published context window or architecture specs
Grok 4.20 — xAI's Multi-Agent Real-Time Machine
Full API access since March 10, 2026, Grok 4.20 is the most architecturally different model on this list. Instead of a single model call, every request runs through four specialized AI agents in parallel — Grok (coordinator), Harper (research), Benjamin (math/logic), and Lucas (creativity). They debate intermediate conclusions before a synthesized answer is produced. The result is a 2M token context window (the largest of any Western closed frontier model), real-time X (Twitter) data integration, and a self-reported 83% non-hallucination rate — independently confirmed at 79–82% by community testing.
The cost model is unusually favorable: $2/$6 per million tokens with a 90% cache discount (dropping cached input to $0.20/M). The latency is the trade-off — responses take 8–20 seconds versus GPT-5.5's 3–6 seconds. For research workflows where a wrong confident answer is expensive, that wait is worth it. For real-time chat interfaces, it isn't.
Context: 2M tokens (largest on this list)
Pricing: $2/$6 per MTok; $0.20/M on cache hits (90% off)
Strength: Real-time data, 2M context, lowest hallucination rate, output speed (~235 t/s)
Weakness: 8–20 second latency; two 2+ hour outages in April; no open weights
Qwen 3.6 Max-Preview — Alibaba's Benchmark-Crusher
Released April 20, 2026, Qwen 3.6 Max-Preview claims the top position on six major coding and agent benchmarks — SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, and SciCode. The model is a Mixture-of-Experts architecture activating only 3 billion of 35 billion total parameters per inference, making it dramatically cheaper to serve than dense models of equivalent capability. This is the first time in Qwen history that a flagship model ships as closed-weights only — a strategic pivot that mirrors what Meta did with Muse Spark.
Important caveat: this is still a preview. Alibaba explicitly labels it as "in active development." Final pricing hasn't been announced. Independent verification of the benchmark claims is still early. The open-source Qwen 3.6-35B-A3B variant (Apache 2.0, released April 16) gives developers a self-hostable alternative with a 1M native context window.
- Context: 260K tokens (Max-Preview); 1M tokens (open-source 35B-A3B)
- Pricing: Preview TBD; Qwen3-Max (prior flagship) at ~$0.78/$3.90 per MTok
- Strength: Top coding benchmarks (SWE-bench Pro, Terminal-Bench 2.0), efficient MoE inference
- Weakness: Preview status; closed-weights only for flagship; 260K context window (smaller than peers)
DeepSeek V4-Pro — The Open-Source Math and Long-Context King
Released April 24, 2026 as a preview under the MIT license, DeepSeek V4-Pro is the most geopolitically significant AI release of the month. It runs on Huawei Ascend 950PR chips — not Nvidia — and ships as open weights on Hugging Face. The architecture is a 1.6 trillion parameter Mixture-of-Experts model with 49 billion active parameters, using a novel hybrid attention mechanism (Compressed Sparse Attention + Heavily Compressed Attention) that requires only 27% of the single-token inference FLOPs of DeepSeek-V3.2 at 1M-token context.
The math benchmarks are the headline: 95.2% on HMMT 2026 February, 89.8% on IMOAnswerBench, and a perfect 120/120 on Putnam-2025. For teams that need frontier-level reasoning at open-source prices, V4-Pro is the answer. For teams that need a production-stable API today, it's worth noting the preview label — DeepSeek has not published final pricing or a finalization timeline.
- Context: 1M tokens; max output 384K tokens
- Pricing: Preview TBD; expected well below $5/$25 based on DeepSeek's historical pricing patterns
- Strength: Open-source (MIT), 1.6T/49B MoE, math reasoning (Putnam 120/120), 1M long-context efficiency
- Weakness: Preview status; self-hosting requires cluster-scale hardware (V4-Pro); V4-Flash more practical for local
GLM-5.1 — The Open-Source Model That Made History
Released April 7, 2026, GLM-5.1 from Z.ai (formerly Zhipu AI) made history as the first open-weight model to ever top the SWE-bench Pro leaderboard, scoring 58.4% versus GPT-5.4's 57.7% and Claude Opus 4.6's 57.3%. It held that #1 position for nine days until Claude Opus 4.7 launched. The model is a 744 billion parameter MoE with 40 billion active parameters, trained entirely on 100,000 Huawei Ascend 910B chips — zero Nvidia hardware — by a company on the US Entity List.
The signature capability is long-horizon agentic execution: GLM-5.1 can maintain autonomous task execution for up to eight hours without performance degradation. In one demonstration, it ran 655 iterations with 6,000+ tool calls to build a high-performance vector database from scratch, reaching 21,500 QPS — 6x the best single-session result from any previous model. API pricing at $1/$3.20 per million tokens makes it the most affordable frontier-adjacent model with open weights.
- Context: 200K tokens; max output 128K tokens
- Pricing: $1/$3.20 per MTok API; MIT weights free to self-host
- Strength: Open-source (MIT), long-horizon agent execution (8 hours, 6K+ tool calls), historic benchmark moment
- Weakness: 200K context (smallest on this list); GPQA Diamond trails frontier closed models (86.2% vs 94.3%)
3. Head-to-Head Benchmark Comparison
The table below consolidates the most reliable third-party verified benchmark scores across all eight models. Where labs have self-reported scores without independent verification, that is noted with an asterisk. The Artificial Analysis Intelligence Index is a composite benchmark covering reasoning, knowledge, math, and coding — it is the most reliable single-number comparison across different model families.
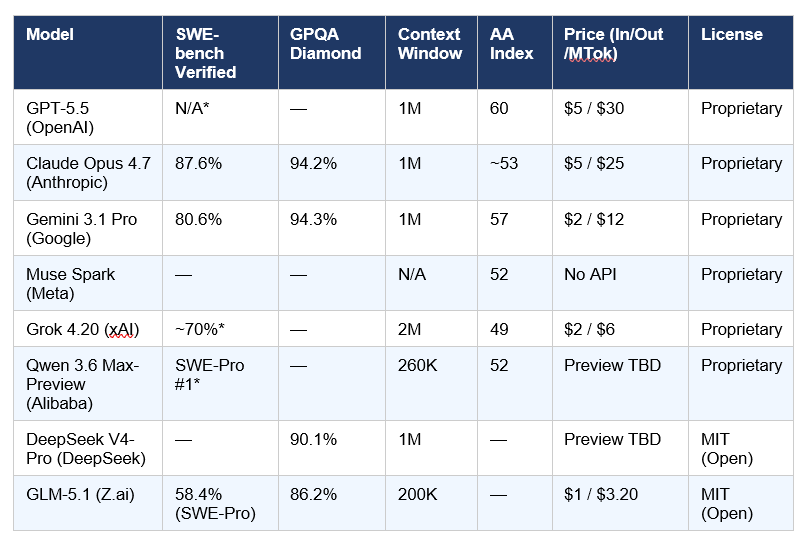
GPT-5.5 was not scored on SWE-bench Verified at launch. Grok 4.20 SWE-bench estimate is from community testing. *Qwen 3.6 Max-Preview SWE-bench Pro #1 claim is self-reported by Alibaba and has not yet been independently confirmed by a third-party lab. The Artificial Analysis Intelligence Index scores for DeepSeek V4-Pro and GLM-5.1 reflect earlier generation data — independent scoring of the latest versions is pending.
For a deeper per-task benchmark breakdown, the Every AI Model Compared: Best One Per Task (2026) guide covers every major benchmark category with real-world context.
4. Which Model Wins Each Use Case?
There is no universally best AI model in April 2026. What exists instead is a clear winner for almost every specific use case. The table below reflects decisions based on verified benchmark data, production reliability, API availability, and pricing.
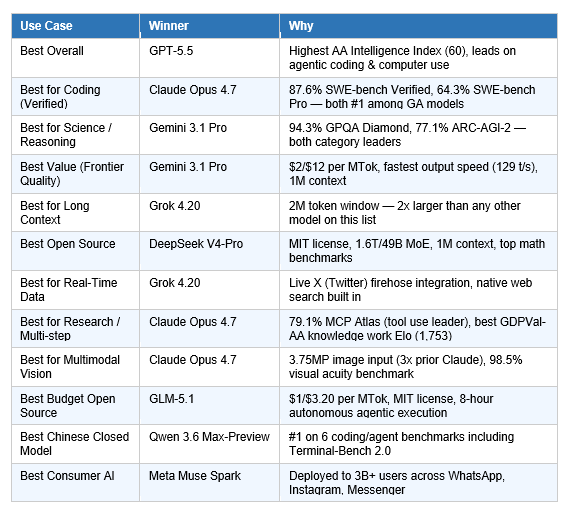
A few decisions worth unpacking:
Why Gemini 3.1 Pro wins value — not GPT-5.5
GPT-5.5 leads on the Intelligence Index at 60 vs Gemini's 57, but at $2/$12 per million tokens versus $5/$30, Gemini delivers roughly the same reasoning quality on most tasks at 60% of the cost. For enterprises running millions of API calls per day, that difference is not marginal. Gemini's 129 token/second output speed — the fastest of any frontier model on this list — compounds the cost advantage for real-time applications.
Why Claude wins coding despite GPT-5.5's Terminal-Bench lead
GPT-5.5 outperforms Claude Opus 4.7 on Terminal-Bench 2.0 (82.7% vs 69.4%) — that's real, and if your primary use case is command-line automation and scripted agentic workflows in a terminal, GPT-5.5 is the better choice. But Claude leads on SWE-bench Verified (87.6% vs N/A for GPT-5.5), SWE-bench Pro (64.3% vs 58.6%), CursorBench (70%), and MCP Atlas tool use (79.1%). For developers using AI inside an IDE or building production coding agents, the Claude advantage is decisive.
Why DeepSeek V4-Pro wins open source — not GLM-5.1
GLM-5.1 made history and held the #1 benchmark spot for nine days — but DeepSeek V4-Pro ships with a 1M token context window, 1.6T parameter MoE scale, perfect math benchmarks, and is more broadly capable across reasoning tasks. GLM-5.1's long-horizon agentic execution (8 hours, 6K+ tool calls) remains unmatched — if that specific capability is your requirement, GLM-5.1 is still the answer.
If you are evaluating models for AI development workflows specifically, the 7 AI Tools That Changed Developer Workflow in March 2026 shows how these models integrate with IDE tools like Cursor, Windsurf, and Claude Code.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. April 2026 Trends: What These Releases Signal About AI's Direction
If you read these eight model launches in isolation, you get benchmark numbers. If you read them together, you see where AI is structurally heading over the next 12 months. Here are the trends that matter.
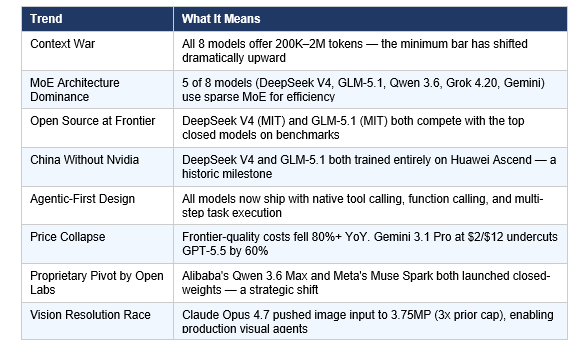
The Open-Source Frontier Moment
The most historically significant event in April 2026 wasn't GPT-5.5. It was GLM-5.1 claiming the #1 position on SWE-bench Pro on April 7 — an open-weight, MIT-licensed, Nvidia-free model briefly outperforming every closed-source system on the world's most respected coding benchmark. Even though Claude Opus 4.7 reclaimed the top spot nine days later, the moment itself is irreversible. The assumption that closed-source models hold a permanent frontier lead is now empirically false.
To understand what this means for teams considering self-hosted AI infrastructure, the NVIDIA AI Models 2026 guide covers the open-weight serving ecosystem including Nemotron 3 Ultra — which targets exactly the enterprise agentic workflows where open models are most practical.
The Geopolitics of the Chip-Free Frontier
Three of the eight models on this list — DeepSeek V4, GLM-5.1, and Qwen 3.6 — were trained without Nvidia hardware, using Huawei Ascend chips. All three are now competitive with the best Western closed models on at least some benchmark categories. The US export controls on AI chips that were supposed to slow Chinese AI development have demonstrably failed to prevent frontier-level training. Whether those controls accelerated domestic Chinese chip development (by forcing labs to optimize on inferior hardware) or whether the trajectory was always going to converge is a question the policy community will be debating for years.
April 2026 Quantified
- 8 frontier-class model launches in 26 days
- 3 different labs held the #1 SWE-bench Pro position within a 10-day window
- 5 of 8 models use sparse Mixture-of-Experts architecture
- 2 of 8 models are fully open-source (MIT license)
- 3 of 8 models trained without Nvidia hardware
- API pricing for frontier-quality models: down 80%+ year-over-year
- Largest context window doubled: 1M (Feb 2026) to 2M (Grok 4.20)
6. Honest Takes: What the Marketing Won't Tell You
GPT-5.5 has a hallucination problem
The Artificial Analysis Intelligence Index puts GPT-5.5 at the top overall — but their independent testing also flags a "notable weakness with hallucinations" compared to Claude and Gemini. GPT-5.5 is better at the right answer when it's confident, but it's also more willing to confabulate when it isn't. For agentic workflows that self-evaluate during execution, a confident wrong action compounds downstream. If your workflow grades outputs before acting on them, GPT-5.5 is excellent. If it doesn't, Claude Opus 4.7's more careful behavior may cost less in real-world errors.
Gemini's context window is the most underrated spec
Every frontier model on this list advertises a 1M token context window. Gemini 3.1 Pro is the only one with documented 2M token support in production (with step-up pricing above 200K). In practice, loading entire codebases, year-long conversation histories, or large document collections requires the actual headroom — not just the marketing ceiling.
DeepSeek V4 is a preview, not a release
DeepSeek V4 launched April 24 with significant fanfare — but Reuters reported on the same day that it is explicitly a preview, with no finalization timeline. The API model IDs and pricing are live, which matters for developers. But the weights are not yet stable, and behavior updates are expected. If you're building production systems, treat it as a preview and maintain V3.2 as your fallback until V4 reaches stable status.
Meta Muse Spark matters more than its benchmarks suggest
Muse Spark sits at 52 on the Artificial Analysis Intelligence Index — below GPT-5.5, Gemini, and Claude. Based on raw benchmark ranking, you'd skip it. But Meta has 3+ billion monthly users across its platforms, and Muse Spark is rolling out as the default AI across all of them. The competitive dynamic here isn't about which developer ecosystem adopts it — it's about which AI becomes the default for people who never type a system prompt or call an API. That's a different race, and Muse Spark is currently winning it.
To see how Claude Opus 4.7 performs in the context of visual design work — one of the newer application categories for frontier models — the Claude Design launch guide covers Anthropic's April 17 product launch powered by Opus 4.7's new 3.75MP vision.
For developers who want to run these models hands-on, the gen-ai-experiments cookbook repository has practical notebooks for building with Claude, GPT, Gemini, and DeepSeek — including multi-model comparison setups you can run today.
7. Frequently Asked Questions
What is the best AI model in April 2026?
GPT-5.5 leads on the Artificial Analysis Intelligence Index (score: 60) and performs best on agentic coding and computer use benchmarks. Claude Opus 4.7 leads on SWE-bench Verified (87.6%) and expert knowledge-work preference. Gemini 3.1 Pro leads on scientific reasoning (GPQA Diamond: 94.3%). There is no single winner — the best model depends entirely on what you're building.
How does GPT-5.5 compare to Claude Opus 4.7?
GPT-5.5 scores higher on the composite Intelligence Index (60 vs ~53), Terminal-Bench 2.0 (82.7% vs 69.4%), and FrontierMath Tier 4 (35.4% vs 22.9%). Claude Opus 4.7 leads on SWE-bench Pro (64.3% vs 58.6%), MCP Atlas tool use (79.1% vs 75.3%), Finance Agent (64.4% vs 61.5%), vision resolution, and expert knowledge-work preference (GDPVal-AA Elo 1,753 vs GPT-5.5's comparable score). GPT-5.5 is $5/$30; Claude Opus 4.7 is $5/$25 per million tokens.
Which AI model is best for coding in 2026?
Claude Opus 4.7 is the top choice for production agentic coding: 87.6% on SWE-bench Verified, 64.3% on SWE-bench Pro, 70% on CursorBench — all category-leading scores. GPT-5.5 leads on Terminal-Bench 2.0 (82.7%), making it stronger for terminal-based automated scripting. Qwen 3.6 Max-Preview self-reports #1 on multiple coding benchmarks including SWE-bench Pro, but this has not yet been independently verified.
Is DeepSeek V4 better than GPT-5.5?
On math benchmarks, DeepSeek V4-Pro-Max is extraordinarily competitive — 95.2% HMMT, 89.8% IMOAnswerBench, perfect 120/120 on Putnam-2025. On overall intelligence, GPT-5.5 leads (Intelligence Index 60). DeepSeek V4 is also still in preview status. For math-heavy research and long-context tasks on an open-source budget, DeepSeek V4 wins. For general agentic workflows and production stability, GPT-5.5 is ahead.
What AI model should I use for research?
For scientific research and literature synthesis, Gemini 3.1 Pro is the best choice: 94.3% GPQA Diamond (best on list), 1M context window for loading entire paper sets, and native multimodal support for analyzing charts, tables, and figures in PDFs. Claude Opus 4.7 leads on agentic tool-use research tasks (MCP Atlas 79.1%), making it better for multi-step research agents that call APIs, verify sources, and compile outputs across multiple tools.
What were the biggest AI releases in April 2026?
By benchmark impact: GPT-5.5 (first full retrain since GPT-4.5, top composite score), Claude Opus 4.7 (SWE-bench Pro record at 64.3%), DeepSeek V4 (MIT open-source at 1.6T scale). By strategic significance: Meta Muse Spark (first proprietary Meta model, 3B user distribution), and GLM-5.1's nine-day hold of SWE-bench Pro #1 — the first time an open-weight model ever topped that benchmark.
Which model has the largest context window?
Grok 4.20 has the largest context window at 2 million tokens — twice the 1M window offered by GPT-5.5, Claude Opus 4.7, DeepSeek V4-Pro, and Gemini 3.1 Pro. For loading entire multi-year codebase histories, extended research conversations, or large document archives in a single session, Grok 4.20 is the only option.
Are any of these models open source?
Yes. DeepSeek V4-Pro and V4-Flash are both fully open-weight under the MIT license, available on Hugging Face. GLM-5.1 is also MIT-licensed and self-hostable via vLLM and SGLang. The Qwen 3.6-35B-A3B variant is open under Apache 2.0. Meta's Muse Spark and Alibaba's Qwen 3.6 Max-Preview are proprietary with no open weights, which represents a strategic pivot from both companies' prior open-source commitments.
8. Recommended Reading
Go deeper on the topics covered in this guide:
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.

