





In 2023, Chinese open-source AI was 2 years behind the frontier. In 2024, 1 year. In 2025, 6 months. On May 3, 2026, a developer ran a live coding challenge — 8 frontier AI models, one puzzle board — and a Chinese open-weight model nobody outside AI Twitter had heard of won outright.
That model was Kimi K2.6 from Moonshot AI, a Beijing-based startup founded in 2023. The challenge was a Word Gem sliding-tile puzzle, run by developer Rohana Rezel as part of his ongoing AI Coding Contest series. K2.6 finished 1st place with 22 match points (7-1-0). MiMo V2-Pro from Xiaomi came second. GPT-5.5 was third. Claude Opus 4.7 finished fifth. Every Western frontier model placed below the top two Chinese open-weight models.
The Hacker News thread hit 311 upvotes and 172 comments. The thing about HN is it does not reward hype — it rewards genuinely surprising results that developers can verify themselves. This was both.
So let me tell you what Kimi K2.6 actually is, what it actually scores, where it legitimately beats GPT-5.5 and Claude, and where you need to be skeptical before switching your stack.
What Is Kimi K2.6?
Kimi K2.6 is Moonshot AI's latest open-weight model, released on April 20, 2026, and publicly available on Hugging Face under a Modified MIT license. It is a 1-trillion-parameter Mixture-of-Experts model with 32 billion parameters active per token — meaning inference runs at the cost of a 32B model while the full capacity of a trillion-parameter architecture is available for routing.
That architecture math is the pricing argument in one sentence.
Specs that matter:
- Architecture: MoE, 1T total / 32B active, 384 experts (8 selected + 1 shared), 61 layers, Multi-head Latent Attention (MLA)
- Context window: 262,144 tokens (256K)
- Modes: Thinking mode (extended chain-of-thought) and Instant mode (fast responses)
- Vision: MoonViT encoder — text, image, and video inputs
- Native INT4 quantization baked into training (not post-hoc), enabling 2x speed gains
- API compatibility: OpenAI and Anthropic SDK compatible — one base URL change to switch
- Available on: Kimi.com, Moonshot API, OpenRouter, Cloudflare Workers AI, Vercel AI Gateway, Hugging Face
This is the fourth major release in the Kimi K2 family in under a year: K2 in July 2025, K2 Thinking in November 2025, K2.5 in January 2026, and now K2.6 in April 2026. The cadence is not accidental.
I already wrote a detailed three-week hands-on review of K2.5 in the Kimi K2.5 vs Claude for coding deep-dive. If you are new to the Kimi family, start there. K2.6 is a direct upgrade from that baseline.
The Benchmark Story: Where K2.6 Wins and Where It Does Not
Kimi K2.6 leads all frontier models on SWE-Bench Pro, scoring 58.6%, compared to GPT-5.4 at 57.7%, Claude Opus 4.6 at 53.4%, and Gemini 3.1 Pro at 54.2%. That is the number that matters most for developers. SWE-Bench Pro is a harder, more practical evaluation of real-world software engineering than the standard SWE-Bench Verified, requiring models to resolve genuine GitHub issues across production-grade codebases.
Here is the full benchmark picture:
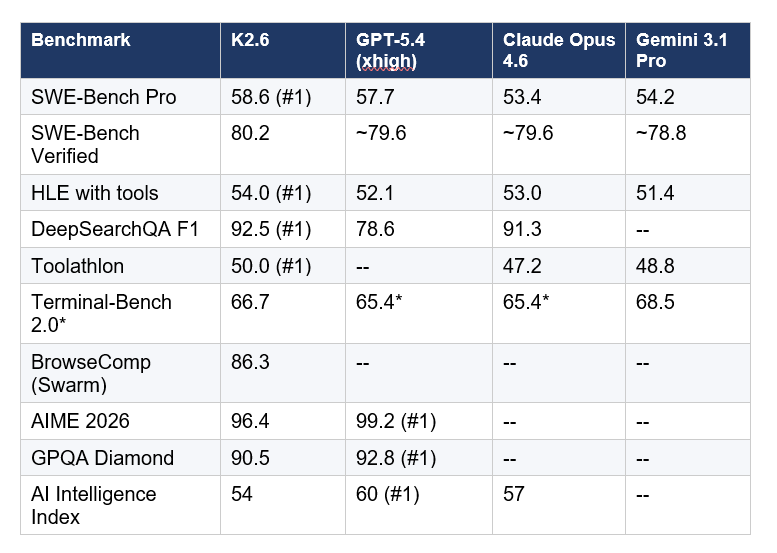
*Terminal-Bench 2.0 caveat: Moonshot uses the Terminus-2 harness, which gives GPT-5.4 a score of 65.4%. Other evaluations using Codex CLI or custom agent harnesses put GPT-5.4 at 75.1%. K2.6's apparent lead on that benchmark is harness-dependent. Do not use this number as a clean conclusion.
Three things I want you to take away from that table.
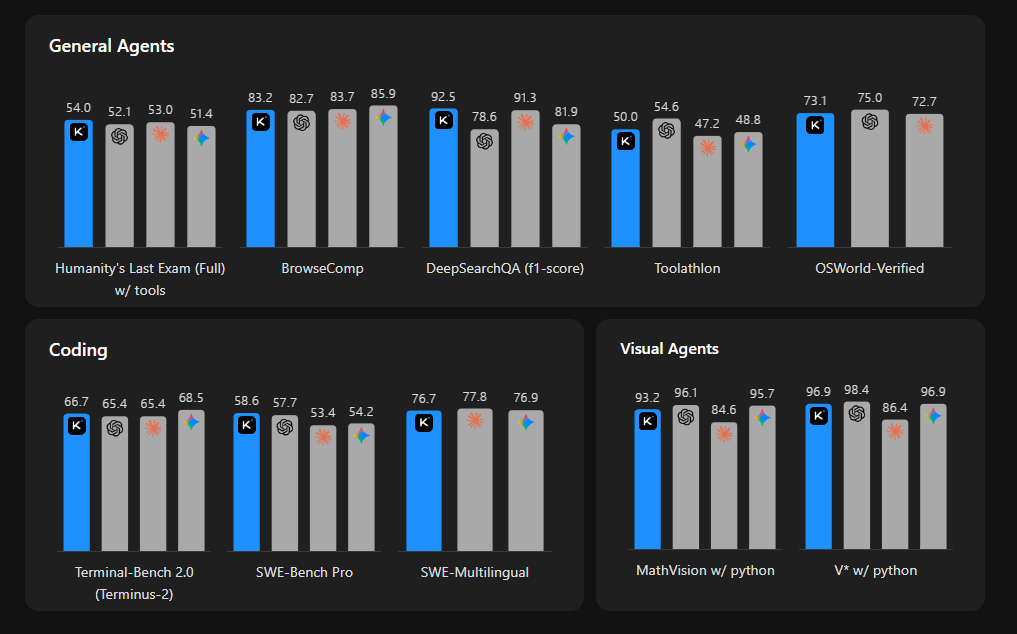
First, K2.6 is a coding and agentic specialist, not a universal frontier model. On overall intelligence (Artificial Analysis Intelligence Index), GPT-5.5 leads at 60, Claude Opus 4.7 at 57, and K2.6 at 54. That 6-point gap from GPT-5.5 shows up on math (AIME 2026: GPT-5.4 at 99.2% vs K2.6 at 96.4%) and deep reasoning (GPQA Diamond: 92.8% vs 90.5%). If those are your primary workloads, K2.6 is the wrong starting point.
Second, K2.6 hits #1 on the benchmarks that directly map to developer workflows. SWE-Bench Pro, HLE with tools (how well a model uses external resources autonomously), DeepSearchQA, and Toolathlon are all real-world agentic tasks. That is not cherry-picking. That is where the model was built to win.
Third, the multimodal story is weak. K2.6 ranks 26th out of 115 models on multimodal and grounded tasks, with an average score of 68.1. If vision-heavy workflows are central to your use case, the MoonViT encoder is not the strongest option available.
For full leaderboard context across all models released this spring, the best AI models May 2026 leaderboard has every major model ranked with sourced benchmark citations.
Agent Swarm: 300 Parallel Sub-Agents, 12-Hour Autonomous Runs
If there is one feature that separates Kimi K2.6 from every other model on the market, open or closed, it is Agent Swarm. No other frontier system ships anything like it.
Agent Swarm scales horizontally to 300 parallel sub-agents executing 4,000 coordinated steps simultaneously. That is triple K2.5's capacity of 100 sub-agents at 1,500 steps. The system can run for 12 hours continuously on a single task, decomposing complex projects into parallel, domain-specialized subtasks, and delivering full end-to-end outputs including documents, websites, slides, and spreadsheets in a single autonomous run.
Moonshot has published two concrete proof-of-work demos that are harder to dismiss than benchmark numbers:
- 13-hour autonomous rewrite of exchange-core, an 8-year-old open-source financial matching engine. Result: 185% medium throughput gain, 133% performance throughput gain, 1,000+ tool calls across the entire session
- 12-hour port of Qwen 0.8B inference to Zig on a Mac. Across 4,000+ tool calls and 14 iterations, throughput improved from roughly 15 tokens per second to 193 tokens per second, 20% faster than LM Studio
These are vendor-reported results from Moonshot's own team. Independent third-party verification of the 12-hour claims has not been published as of May 4. That matters. Treat them as strong directional evidence, not audited benchmarks.
The other Agent Swarm innovation is Claw Groups, currently in research preview. Claw Groups opens the swarm to a heterogeneous ecosystem: agents running on different devices, running different underlying models, and humans can all collaborate in a shared workspace simultaneously. K2.6 acts as the adaptive coordinator: it dynamically matches tasks to agents based on their skill profiles, detects when an agent stalls or fails, automatically reassigns the task or regenerates subtasks, and manages the full lifecycle. A developer can take over a subtask mid-execution, hand it back, or redirect a sub-agent without stopping the entire swarm.
The agent coordination patterns underlying this architecture, specifically multi-step tool use and parallel execution loops, are covered in the Building Smart AI Agents guide, which walks through the ReAct reasoning loop that drives agentic execution like this.
My honest read: the Agent Swarm capability, if it holds up at scale under independent testing, is the most technically novel thing any AI lab has shipped in Q1 2026. The Claw Groups concept is even more interesting. Heterogeneous agent coordination where humans and diverse models share a live workspace is not something OpenAI or Anthropic have publicly shipped. The question is whether the 12-hour reliability claims survive production loads that Moonshot's own team isn't running.
Pricing: The Math That Actually Matters
Kimi K2.6 costs $0.60 per million input tokens and $2.50 per million output tokens on the Moonshot API. On OpenRouter it runs $0.74 input / $3.49 output. The weights are free to download from Hugging Face for self-hosting.
The comparison numbers:
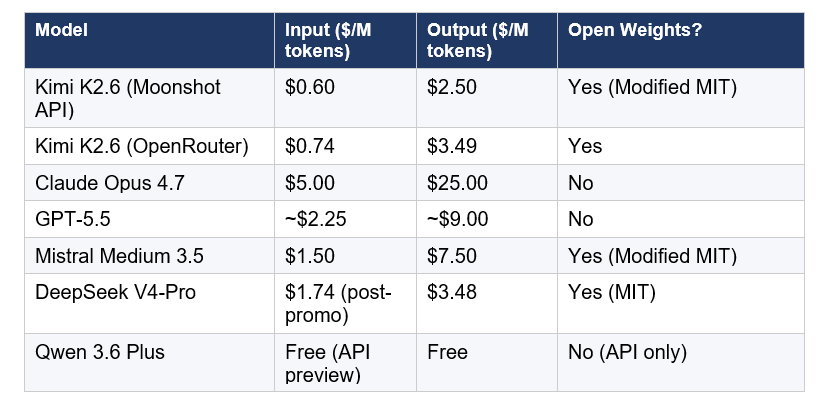
The 8.3x price gap versus Claude Opus 4.7 on input is the headline. In real dollar terms: an agent-scale workload burning 10 million output tokens per month costs roughly $25 on K2.6's API versus $250 on Claude Opus 4.7. That gap changes what product architectures are financially viable.
There is a cost trap worth flagging, though. K2.6 in thinking mode generates significantly more output tokens than comparably-capable closed models. Artificial Analysis measured K2.6 producing 170 million output tokens across their Intelligence Index evaluation, compared to a median of 47 million for similarly-sized models. If you are running long-context agentic tasks in thinking mode, the output cost can erode the input cost advantage faster than you expect. Always benchmark your specific workload before projecting costs.
One license clause that matters at scale: the Modified MIT license requires visible Kimi K2.6 branding on products with 100 million or more monthly active users or $20 million or more in monthly revenue. For most companies this is irrelevant. For hyperscalers planning to embed K2.6 in user-facing products, it is a legal review item before launch.
For a full breakdown of how K2.6 pricing compares to the open-weight Chinese model field including DeepSeek V4 and GLM-5.1, the DeepSeek V4-Pro review and pricing analysis has the detailed cost math for production-scale agentic workloads.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
The Broader Context: Distillation, Cursor, and the Open-Source Race
Kimi K2.6 doesn't exist in a vacuum. There is a messy competitive context worth understanding before you put it in production.
In February 2026, Anthropic publicly accused Moonshot AI (along with DeepSeek and MiniMax) of violating terms of service by using thousands of fraudulent accounts to generate millions of Claude conversations for training data distillation. Moonshot has not publicly confirmed or denied this. The accusation remains unresolved and is part of the backdrop to K2.6's competitive positioning against Claude.
In March 2026, Cursor, a code editor valued at roughly $50 billion, was caught by developers using Kimi K2.5 as the underlying model for its Composer 2 feature, without disclosing this in the initial launch. Cursor co-founder Aman Sanger confirmed: 'It was a miss to not mention the Kimi base in our blog from the start.' This is now a disclosed partnership, and it tells you something important: a company with $50 billion in valuation chose a Chinese open-source model over closed-source alternatives when it mattered commercially.
Andreessen Horowitz has estimated that 80% of US startups currently use Chinese base models in some part of their stack. The US House is also considering legislation that could affect Chinese AI companies operating internationally. For enterprise teams with compliance requirements, the vendor jurisdiction of Moonshot AI is a procurement consideration alongside the technical capability.
The full competitive picture of Chinese open-source models competing for the same workloads is covered in the Qwen vs GLM vs Kimi: best Chinese AI for coding 2026 comparison, which tests all three in real workflows with honest results.
My take: the distillation accusation is serious and unresolved. The Cursor situation shows that open-source Chinese models are already embedded in Western developer toolchains at significant scale, with or without explicit acknowledgment. The compliance risk is real for regulated industries. The technical advantage is also real for everyone else.
Who Should Actually Use Kimi K2.6?
The honest answer splits clearly along four lines.
Use K2.6 when:
- Cost is a hard constraint and the workload is coding: front-end generation, UI prototyping, batch refactors, test generation, dependency upgrades. For these tasks, K2.6 delivers 80-90% of Claude Code quality at roughly 12% of the API cost.
- You need autonomous long-horizon coding: 4,000-step agent runs, multi-file orchestration across large codebases, CI investigation and resolution. This is K2.6's design target and where Agent Swarm makes the biggest practical difference.
- Open weights are required: compliance, data residency, or self-hosting for cost control. Weights are on Hugging Face, deploy with vLLM or SGLang, OpenAI SDK compatible.
- You are already in the Kimi ecosystem: Kimi Code CLI (6,400+ GitHub stars, Apache 2.0) integrates natively. If you ran K2.5, upgrade is straightforward.
Look elsewhere when:
- High-stakes single-turn reasoning: financial decisions, medical analysis, legal interpretation. K2.6 lags GPT-5.4 on GPQA Diamond (90.5% vs 92.8%) and AIME 2026 (96.4% vs 99.2%). The gap is small but real.
- You need a 1M+ context window in a single pass: K2.6's 262K is its structural ceiling. GLM-5.1 and DeepSeek V4 support larger contexts for full-repository ingestion.
- Vendor jurisdiction matters for procurement: Moonshot AI is a Chinese company. For regulated industries or US government contracts, the compliance review will take longer than a technical evaluation.
- You need the best multimodal performance: K2.6 ranks 26th out of 115 on multimodal benchmarks. Gemini 3.1 Pro is meaningfully stronger here.
For a first-principles look at how to structure the kind of agent pipeline K2.6 is designed to power, the build your first AI agent and automation guide walks through the architecture patterns that map directly to Agent Swarm-style workflows.
The pattern I expect most serious developers to land on: use K2.6 for the 70-80% of tasks that are coding, batch operations, and routine agentic work. Keep Claude Code or GPT-5.5 for the edge cases that require deeper reasoning or regulated context. The routing logic is one API key swap.
Frequently Asked Questions
What is Kimi K2.6?
Kimi K2.6 is an open-weight multimodal AI model released by Moonshot AI on April 20, 2026. It uses a Mixture-of-Experts architecture with 1 trillion total parameters and 32 billion active per token, a 256K context window, and configurable thinking and instant modes. It scores 58.6% on SWE-Bench Pro, leading GPT-5.4 (57.7%) and Claude Opus 4.6 (53.4%), and runs 300 parallel sub-agents for long-horizon autonomous coding tasks.
Did Kimi K2.6 beat GPT-5.5 on coding?
In a live programming challenge on May 3, 2026, run by developer Rohana Rezel (Word Gem Puzzle, AI Coding Contest), K2.6 finished 1st with 22 match points (7-1-0), ahead of GPT-5.5 (3rd), Claude Opus 4.7 (5th), and Gemini. On the formal SWE-Bench Pro benchmark, K2.6 scores 58.6% versus GPT-5.4 (xhigh) at 57.7%. On the Artificial Analysis overall Intelligence Index, GPT-5.5 leads at 60 versus K2.6 at 54 — K2.6 is a coding specialist, not a universal frontier model.
How does Kimi K2.6 compare to Claude Opus 4.7?
On SWE-Bench Pro (coding), K2.6 leads Claude Opus 4.6 by 5.2 points (58.6% vs 53.4%). On HLE with tools (autonomous agentic performance), K2.6 scores 54.0 vs Claude Opus 4.6's 53.0. On overall Intelligence Index, Claude Opus 4.7 leads at 57 vs K2.6's 54. On price, K2.6 costs $0.60 per million input tokens vs Claude Opus 4.7's $5.00 — an 8.3x difference. Claude Opus 4.7 maintains leads on high-stakes reasoning benchmarks and has more established safety evaluations.
What is Agent Swarm in Kimi K2.6?
Agent Swarm is a multi-agent orchestration system built into K2.6 that scales to 300 parallel sub-agents executing 4,000 coordinated steps simultaneously, triple the capacity of K2.5's 100 sub-agents and 1,500 steps. K2.6 decomposes a complex task into parallel, domain-specialized subtasks, runs them simultaneously, and synthesizes end-to-end outputs including documents, websites, and spreadsheets. Sessions can run continuously for 12+ hours. All benchmark claims from Moonshot's own reports; independent third-party verification has not been published as of May 4, 2026.
What is Claw Groups?
Claw Groups is a research preview feature in Kimi K2.6 that extends Agent Swarm to include heterogeneous agents. Agents running on any device, using any underlying model, and human participants can all collaborate in a shared workspace simultaneously. K2.6 acts as the adaptive coordinator, dynamically matching tasks to agents based on skill profiles, detecting failures, and reassigning tasks. Users can take over individual subtasks mid-execution and hand them back without stopping the swarm.
How much does Kimi K2.6 cost?
On the Moonshot API at platform.moonshot.ai, K2.6 costs $0.60 per million input tokens and $2.50 per million output tokens. On OpenRouter the rates are $0.74 input and $3.49 output. Weights are free on Hugging Face under a Modified MIT license (commercial use allowed; branding required for products with 100M+ MAU or $20M+ monthly revenue). Free to use with rate limits on Kimi.com and the Kimi app.
Is Kimi K2.6 open source and can I self-host it?
K2.6 weights are available on Hugging Face under a Modified MIT license, which allows commercial use and self-hosting. Self-hosting the full model requires significant hardware: the INT4-quantized version runs at roughly 32B parameter inference cost but the full model needs around 250GB+ of combined VRAM and RAM. Recommended deployment: vLLM or SGLang with tensor parallelism. The API is OpenAI and Anthropic SDK compatible, so switching from Claude or GPT requires only a base URL change.
What are the honest limitations of Kimi K2.6?
K2.6 lags the top closed models on overall intelligence (AI Index: 54 vs GPT-5.5's 60), math (AIME 2026: 96.4% vs GPT-5.4's 99.2%), and reasoning (GPQA Diamond: 90.5% vs 92.8%). It ranks 26th out of 115 models on multimodal benchmarks. High-token thinking mode tasks generate significantly more output tokens than comparable models, eroding cost advantage on complex reasoning jobs. The 12-hour autonomous run claims are vendor-reported and not independently verified. Moonshot AI was also accused by Anthropic of using Claude conversation data for training distillation — a dispute that remains unresolved.
Recommended Blogs
These are real posts on buildfastwithai.com that go deeper on the topics in this article:
- Kimi K2.5 vs Claude for Coding: Three-Week Hands-On Review — the predecessor deep-dive with real workflow testing
- Qwen vs GLM vs Kimi: Best Chinese AI for Coding 2026 — full comparison of the three Chinese open-source frontrunners
- DeepSeek V4-Pro Review 2026 — pricing math and benchmark breakdown for the MIT-licensed alternative
- Best AI Models May 2026 Leaderboard — every major model ranked by benchmark, cost, and use case
- Building Smart AI Agents — the ReAct loop and multi-step tool-use patterns that Agent Swarm scales on top of
- Build Your First AI Agent and Automation — beginner-friendly introduction to the agent architectures K2.6 is built for
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
References
- Moonshot AI — Kimi K2.6 Official Technical Blog: Advancing Open-Source Coding
- Hugging Face — moonshotai/Kimi-K2.6 Model Card with Architecture and Benchmarks
- ThinkPol — An Open-Weights Chinese Model Just Beat Claude, GPT-5.5, and Gemini in a Programming Challenge
- Hacker News — Kimi K2.6 just beat Claude, GPT-5.5, and Gemini in a coding challenge (311 upvotes)
- MarkTechPost — Moonshot AI Releases Kimi K2.6 with Long-Horizon Coding, Agent Swarm Scaling to 300 Sub-Agents
- Kilo Code — Kimi K2.6 Has Arrived: An Open-Weight Powerhouse for Agentic Work
- Handy AI — Model Drop: Kimi K2.6 (Benchmarks, Pricing, Architecture)
- OfficeChai — Moonshot AI Releases Kimi K2.6, Beats Top US Models On Some Benchmarks
- OpenRouter — Kimi K2.6 API Pricing and Providers
- Cloudflare — Kimi K2.6 Now Available on Workers AI (April 20, 2026)

