





Claude Opus 4.7: Full Review, Benchmarks & Is It Worth Upgrading? (2026)
64.3% on SWE-bench Pro. That is the number that tells you everything about Claude Opus 4.7.
Released on April 16, 2026, Anthropic's latest flagship model scores 64.3% on the benchmark that measures real-world GitHub issue resolution. GPT-5.4 scores 57.7%. Gemini 3.1 Pro scores 54.2%. For a model priced at the exact same $5/$25 per million tokens as its predecessor, that is a meaningful jump. And it comes after weeks of vocal complaints from developers that Opus 4.6 had quietly gotten worse.
I have been tracking Anthropic's release cadence since Opus 4.5. This one is different from a pure numbers perspective. The SWE-bench Pro gain from Opus 4.6 to 4.7 is 10.9 percentage points in a single release. For context, the jump from 4.5 to 4.6 was about 5 points on SWE-bench Verified. Anthropic is accelerating.
This is the full review: every benchmark explained, all new features with implementation details, comparisons against GPT-5.4 and Gemini 3.1 Pro, pricing across all platforms, who should upgrade, and one weakness that is getting buried in the launch coverage.
What Is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's most capable publicly available AI model as of April 2026. The model ID is claude-opus-4-7. It is the direct successor to Claude Opus 4.6, which launched February 5, 2026, and it supports a 1 million token context window, 128k maximum output tokens, and adaptive thinking that automatically adjusts reasoning depth based on task complexity.
Anthropic built this model specifically for tasks where Opus 4.6 needed hand-holding: long-running agentic coding workflows, production-grade work in large multi-file codebases, enterprise knowledge work across documents and spreadsheets, and complex multi-tool reasoning chains that previously stalled or looped. The company says users can now "hand off their hardest coding work, the kind that previously needed close supervision, with confidence."
Worth knowing up front: this release comes directly after weeks of public criticism that Opus 4.6 had quietly degraded. An AMD senior director wrote on GitHub that Claude had "regressed to the point it cannot be trusted to perform complex engineering." Anthropic denied deliberate changes and said it would investigate. Whatever the root cause, Opus 4.7 is partly a reputational reset, and the benchmark numbers make a solid case for the upgrade.
If you want the full context on the Claude model lineup, the complete Claude AI guide for 2026 covers every model tier, pricing, and how Opus fits relative to Sonnet and Haiku.
Claude Opus 4.7 Benchmarks: The Full Picture
Claude Opus 4.7 leads all publicly available (non-preview) models on five major benchmarks as of April 16, 2026. The one exception is BrowseComp, which I will address in detail below.
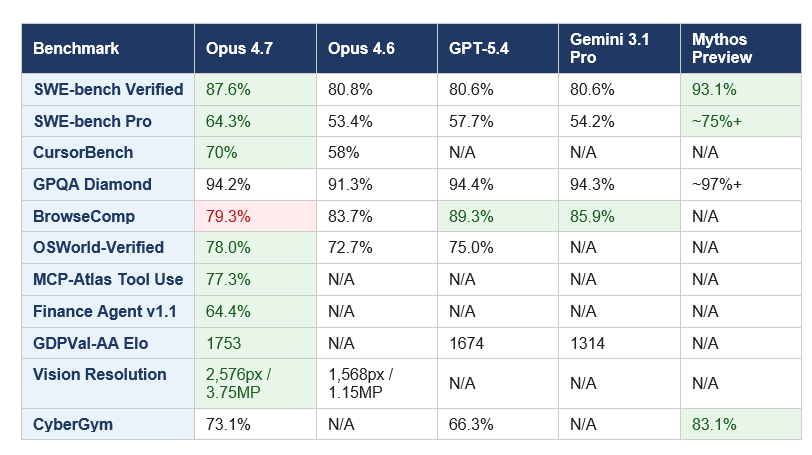
The headline: SWE-bench Pro jumped from 53.4% on Opus 4.6 to 64.3%, a 10.9-point gain in a single version bump. SWE-bench Verified, the curated subset of 500 human-validated GitHub issues, went from 80.8% to 87.6%. For CursorBench, which measures AI coding performance specifically inside the Cursor IDE, the improvement is 12 points (58% to 70%).
Knowledge work is where the competitive lead gets decisive. On GDPVal-AA, an Elo-based knowledge work benchmark, Opus 4.7 scores 1,753 versus GPT-5.4's 1,674 and Gemini 3.1 Pro's 1,314. That last number is not a close race. Enterprise teams running document-heavy workflows, legal analysis, or financial modeling should note that gap.
On graduate-level reasoning (GPQA Diamond), the frontier has converged. Opus 4.7 at 94.2%, GPT-5.4 at 94.4%, Gemini 3.1 Pro at 94.3%. These differences are within statistical noise. The benchmark is saturating, and differentiation is shifting entirely to applied performance on real-world tasks, which is exactly where Opus 4.7 is strongest.
The one number that slipped: BrowseComp dropped from 83.7% on Opus 4.6 to 79.3% on Opus 4.7. GPT-5.4 Pro scores 89.3% and Gemini 3.1 Pro scores 85.9% on that benchmark. If your agents rely heavily on web search and synthesis across multiple pages, that 10-point gap matters and it is worth routing those workloads to a different model. I will come back to this in the comparison section.
To see how Opus 4.7 fits within the broader April 2026 model landscape, including open-source competitors like GLM-5.1 and Qwen 3.6 Plus, check the best AI models ranked for April 2026 for the full picture.
Every New Feature in Claude Opus 4.7, Explained
xhigh Effort Level
Opus 4.7 adds a new xhigh effort setting that sits between the existing high and max options, giving developers finer-grained control over the depth-vs-latency tradeoff on hard problems. Claude Code now defaults to xhigh for all subscriber plans. Anthropic's own data shows xhigh approaches 75% on coding tasks, while max pushes higher but burns significantly more tokens. For most production agentic workflows, starting at high or xhigh is the recommended approach.
Task Budgets (Beta)
This is the most practically useful new API feature, and I think it is underrated in the launch coverage. Task budgets let developers set a hard token ceiling on an agentic loop. The model sees a running countdown and uses it to prioritize work, finishing gracefully as the budget is consumed rather than cutting off mid-task or generating an unexpected bill.
Activate it with the task-budgets-2026-03-13 beta header and add output_config.task_budget to your API call. Anthropic recommends experimenting with budget sizes per workload. If the budget is too tight for a given task, the model may complete it less thoroughly or decline entirely. For teams running overnight autonomous coding agents, this feature directly solves a production cost-control problem.
Opus 4.7 also scores 77.3% on MCP-Atlas, the benchmark that measures performance on scaled multi-tool agentic tasks. To see how MCP tool integration works end-to-end with Claude, the MCP Workshop cookbook walks through complete setup with runnable Jupyter notebooks, from connecting tools to handling multi-step Claude agentic loops in production.
/ultrareview Command
Inside Claude Code, /ultrareview triggers a multi-agent code review pass that catches bugs and design flaws that a standard single-pass review misses. CodeRabbit's evaluation showed recall improved by over 10% using Opus 4.7 on their most complex PRs, while precision held stable. For teams doing automated PR review at scale, this is worth benchmarking against your current setup.
3x Higher Vision Resolution
Maximum image resolution jumped from 1,568 pixels (1.15MP) to 2,576 pixels (3.75MP), a roughly 3.3x increase in pixel density. This is not a quality-of-life improvement. It is a genuine capability unlock for agents that work with dense UIs, architecture diagrams, financial charts, screenshots of large codebases, or any visual input where fine detail matters. OSWorld-Verified computer use improved from 72.7% to 78.0% in part because of this upgrade.
New Tokenizer
Opus 4.7 uses an updated tokenizer that processes text using 1.0x to 1.35x more tokens than Opus 4.6 for equivalent input. The tokenizer improves performance on a range of tasks, but it carries a real migration implication: your existing prompts may cost up to 35% more. Run /v1/messages/count_tokens against your production prompts before switching models. This is not a reason to avoid upgrading, but it is a reason to benchmark first.
Thinking Omitted By Default
Thinking blocks now appear in the response stream, but their content field is empty by default. This is a silent API change, meaning no error is raised. If your product surfaces model reasoning to users, you will see a long pause before output begins with the new default. Set "display": "summarized" to restore visible progress during thinking. Check your integrations before going to production with Opus 4.7.
Implicit-Need Tests
Opus 4.7 is the first Claude model to pass what Anthropic calls implicit-need tests: tasks where the model must infer which tools or actions are needed rather than being told explicitly. In Anthropic's evaluation, this capability produced a 14% improvement on complex multi-step workflows over Opus 4.6 while generating only one-third as many tool errors. In practice, this means fewer "which tool do I use here?" clarification steps in long agentic runs.
RAG pipelines and multi-step retrieval agents are one of the clearest production use cases for Opus 4.7's improved tool inference. If you want to build one from scratch, the How to Build Claude-Powered RAG from Scratch cookbook covers the full implementation, from chunking and embedding to retrieval and Claude API generation, with complete code you can adapt to your stack right away.
Claude Opus 4.7 vs Opus 4.6: What Actually Changed?
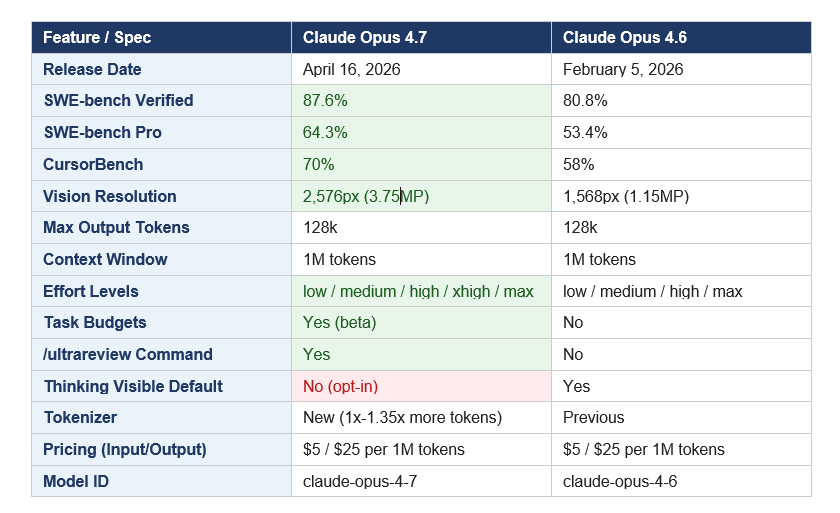
The single most striking change is the coding jump. On the 93-task internal coding benchmark used by Hex, Opus 4.7 lifted resolution by 13% over Opus 4.6, including four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve. Hex's framing: "low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6." That is a meaningful statement. You get prior-tier performance at a lower reasoning cost, which translates directly to reduced token spend on simpler tasks.
Instruction-following got stricter. Opus 4.6 would sometimes interpret ambiguous prompts loosely and fill in gaps helpfully. Opus 4.7 executes the exact text provided. This is an improvement for production systems that need predictable outputs, but prompts that relied on Opus 4.6's gap-filling behavior may produce literal-but-wrong results in 4.7. Explicit prompts will outperform vague ones in this model more than any previous Claude.
If you want a practical framework for writing prompts that work with Opus 4.7's literal instruction-following, the best Claude prompts guide for 2026 has 150 tested examples across use cases, including structuring instructions with XML tags.
The biggest migration risk is the tokenizer. Up to 35% more tokens for the same input means your cost estimates for existing workflows need to be rechecked before going to production. It also means some API integrations that count tokens for rate-limiting purposes will behave differently. Both impacts are manageable with testing, but neither is zero.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro: Full Comparison
Every major AI team is running this comparison right now, so here are the actual numbers rather than hedged general impressions.
On coding: Claude wins clearly.
SWE-bench Pro is the clearest signal: 64.3% for Opus 4.7 versus 57.7% for GPT-5.4 and 54.2% for Gemini 3.1 Pro. For CursorBench, Opus 4.7 scores 70%, the highest score among all evaluated models. On Rakuten's internal SWE-bench, Opus 4.7 resolved 3x more production tasks than Opus 4.6. These are not marginal differences.
On reasoning: essentially tied.
GPQA Diamond scores are 94.2% (Opus 4.7), 94.4% (GPT-5.4), and 94.3% (Gemini 3.1 Pro). Nobody wins this race anymore. The benchmark is saturating at the frontier, and the relevant differentiation has moved entirely to applied task performance.
On web research: Gemini and GPT lead.
BrowseComp drops Opus 4.7 to 79.3%, trailing GPT-5.4 Pro at 89.3% and Gemini 3.1 Pro at 85.9%. That is a 10-point gap. If your agent architecture involves real-time web retrieval, reading multiple pages, and synthesizing across sources, you should be benchmarking Gemini 3.1 Pro or GPT-5.4 on that specific task before committing to Opus 4.7 for those workloads.
On enterprise knowledge work: Claude dominates.
GDPVal-AA Elo of 1,753 versus GPT-5.4's 1,674 and Gemini 3.1 Pro's 1,314. BigLaw Bench at 90.9% for legal document analysis. Finance Agent v1.1 at 64.4%. For organizations doing legal review, financial modeling, or any high-stakes document work, Opus 4.7 is the current leader by a meaningful margin.
On price: Gemini undercuts Claude.
Gemini 3.1 Pro charges $2 per million input tokens and $12 per million output tokens, compared to Claude's $5/$25. If your workload does not require frontier coding performance and cost efficiency is the primary variable, Gemini 3.1 Pro is worth a serious evaluation. But for organizations where engineering productivity is the variable you are optimizing, the Claude pricing premium likely pays for itself given the benchmark lead on the tasks that matter.
For a detailed breakdown of how Claude Opus 4.6 stacked up against GPT-5.3-Codex and Kimi K2.5 earlier this year, the GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 comparison gives the historical context for how this competitive picture has evolved.
My honest take: Claude Opus 4.7 is the best model available for coding agents and enterprise knowledge work. GPT-5.4 is the better choice for web research-heavy agents. Gemini 3.1 Pro wins on price-to-performance for general workloads. The right answer depends entirely on what your agents actually do, not on which lab you prefer.
Pricing, Plans, and Platform Availability
Claude Opus 4.7 launched at the same price as Opus 4.6: $5 per million input tokens and $25 per million output tokens. Anthropic is delivering substantially better performance at unchanged cost, which is the right move for developer adoption.

Prompt caching saves up to 90% on repeated context, which matters for production agentic systems that pass large system prompts or tool definitions with every request. The Batch API provides a 50% discount on both input and output for non-real-time workloads. For US-only data residency requirements in healthcare, finance, or government, US-only inference is available at 1.1x pricing.
One thing worth flagging: GitHub Copilot is rolling out Opus 4.7 with a 7.5x premium multiplier as part of promotional pricing that runs until April 30, 2026. After that date, usage costs will increase. If you are running Opus 4.7 in a Copilot-integrated workflow, factor the post-promotion pricing into your evaluation before committing to it for production use.
For teams that want to use Opus 4.7 selectively without paying Opus prices for every request, the Anthropic Advisor Strategy guide covers a production-ready pattern where Sonnet 4.6 handles execution and Opus consults only on difficult sub-tasks, cutting cost per agentic task by 11.9% in Anthropic's benchmark.
Who Should (and Should Not) Use Claude Opus 4.7?
Upgrade to Opus 4.7 if:
- You run production coding agents on complex, multi-file codebases. The SWE-bench Pro jump from 53.4% to 64.3% is confirmed by multiple enterprise partners. Rakuten's benchmark showed 3x more production task resolutions compared to Opus 4.6.
- You are doing enterprise knowledge work: legal document review (BigLaw Bench 90.9%), financial analysis (Finance Agent v1.1 at 64.4%), or multi-session project management requiring context persistence.
- You are building computer-use agents that interact with dense UI screenshots or need to interpret complex visual content. The 2,576px vision upgrade is a genuine capability improvement, not a marketing claim.
- Your agentic workflows involve long-running tasks where loop resistance and graceful error recovery matter. Cognition (Devin) reported Opus 4.7 can work coherently "for hours" and pushes through tool failures that previously stopped Opus cold.
If you are building multi-agent systems with Opus 4.7 in a coordinator role, the Kimi K2.5 Agent Swarm Cookbook covers practical orchestration patterns you can adapt directly for Claude-based architectures, including parallelization strategies, sub-agent task delegation, and handling long-horizon agentic loops.
Consider staying on Opus 4.6 or Sonnet 4.6 if:
Your primary use case is web research synthesis. BrowseComp dropped 4.4 points (83.7% to 79.3%). GPT-5.4 and Gemini 3.1 Pro both outperform Opus 4.7 on this specific task type.
You are cost-sensitive and your workload does not need frontier coding performance. Sonnet 4.6 at $3/$15 per million tokens handles most production tasks well, and the new tokenizer adds up to 35% more token cost on the same prompts.
You have not tested your prompts for Opus 4.7's stricter instruction-following. Prompts that relied on Opus 4.6's interpretive behavior may need explicit rewrites before migrating.
You are running research-heavy autonomous agents where BrowseComp performance is the bottleneck.
The Cybersecurity Angle: Safeguards and the Verification Program
Anthropic deliberately trained Opus 4.7 to have lower cybersecurity capabilities than its unreleased Claude Mythos Preview. On CyberGym (vulnerability reproduction), Opus 4.7 scores 73.1%, well above GPT-5.4's 66.3%, but well below Mythos Preview's 83.1%.
This is part of Anthropic's broader strategy around Project Glasswing, launched in early April 2026. Mythos is being deployed exclusively for defensive cybersecurity work by a set of handpicked organizations including AWS, Apple, Cisco, Google, JPMorgan Chase, Microsoft, Nvidia, and CrowdStrike. The idea: test new cyber safeguards on less capable models first, before expanding access to frontier systems.
Opus 4.7 ships with automatic detection and blocking of prohibited cybersecurity uses. For legitimate security researchers including pen testers, red teamers, and vulnerability researchers, Anthropic launched the Cyber Verification Program. Verified researchers get access for legitimate offensive security work. For everyone else, these safeguards are invisible and will not affect normal development workflows.
For a full breakdown of Claude Mythos and why Anthropic considers it too risky for general release, the Claude Mythos 5 full review covers the leak, Project Glasswing, and what the 10-trillion parameter model can actually do.
My read on this: Anthropic is threading a needle between releasing capability and controlling risk. The Cyber Verification Program is a pragmatic approach that keeps the model useful for security professionals while limiting casual misuse. Whether that balance is right is a debate worth having, but the transparency around the tradeoff is at least honest.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Frequently Asked Questions
What is Claude Opus 4.7?
Claude Opus 4.7, released April 16, 2026, is Anthropic's most capable publicly available AI model. The model ID is claude-opus-4-7. It is available across claude.ai (Pro, Max, Team, Enterprise plans), the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, and GitHub Copilot (Pro+, Business, Enterprise). It improves on Opus 4.6 in coding, vision resolution, instruction-following, and agentic reliability.
How does Claude Opus 4.7 compare to Opus 4.6?
Claude Opus 4.7 scores 87.6% on SWE-bench Verified (up from 80.8%), 64.3% on SWE-bench Pro (up from 53.4%), and 70% on CursorBench (up from 58%). Vision resolution jumped from 1,568px (1.15MP) to 2,576px (3.75MP). New features include the xhigh effort level, task budgets (beta), and the /ultrareview command in Claude Code. The new tokenizer uses 1x to 1.35x more tokens than Opus 4.6. Pricing is unchanged at $5/$25 per million tokens.
Is Claude Opus 4.7 better than GPT-5.4?
On coding benchmarks, yes: Opus 4.7 scores 64.3% on SWE-bench Pro versus GPT-5.4's 57.7%. On CursorBench, Opus 4.7 leads at 70%. On enterprise knowledge work (GDPVal-AA), Opus 4.7 has an Elo of 1,753 versus GPT-5.4's 1,674. The exception is BrowseComp (web research), where GPT-5.4 Pro leads at 89.3% versus Opus 4.7's 79.3%. For coding agents, Claude wins. For research-heavy agents, GPT-5.4 is stronger.
How much does Claude Opus 4.7 cost?
Claude Opus 4.7 costs $5 per million input tokens and $25 per million output tokens via the Anthropic API, the same pricing as Opus 4.6. Prompt caching saves up to 90% on repeated context. The Batch API provides a 50% discount for non-real-time workloads. US-only inference is available at 1.1x pricing for data residency requirements.
What is the xhigh effort level in Claude Opus 4.7?
xhigh is a new effort level between high and max, introduced in Opus 4.7. It is now the default effort level for Claude Code on all subscriber plans. xhigh provides finer control over the tradeoff between reasoning depth and response latency. Anthropic recommends starting at high or xhigh for coding and agentic use cases. Max effort yields the highest scores but burns significantly more tokens. Benchmarks show xhigh approaches 75% on complex coding tasks.
What are task budgets in Claude Opus 4.7?
Task budgets are a beta feature that lets developers set a token ceiling on agentic loops. Activate with the task-budgets-2026-03-13 beta header and the output_config.task_budget parameter. The model sees a running countdown and finishes gracefully as the budget is consumed, preventing runaway token costs in autonomous agents. If the budget is too restrictive for a given task, the model may complete it less thoroughly or decline entirely.
Does Claude Opus 4.7 use more tokens than Opus 4.6?
Yes. Opus 4.7 uses a new tokenizer that processes text at 1.0x to 1.35x more tokens than Opus 4.6 for the same input, depending on content type. This means existing prompts can cost up to 35% more. Run /v1/messages/count_tokens against your production prompts before migrating. The tokenizer change also means token-counting integrations and rate-limit calculations will return different numbers for Opus 4.7 versus Opus 4.6.
Is Claude Opus 4.7 available to free users?
No. Opus 4.7 requires a paid Claude plan (Pro, Max, Team, or Enterprise). Free users on claude.ai have access to Claude Sonnet 4.6, not Opus 4.7. Via the Anthropic API, Opus 4.7 is available to any developer at $5/$25 per million tokens with no subscription required beyond an API key. GitHub Copilot requires Pro+, Business, or Enterprise status.
Recommended Blogs
These are real posts that exist on buildfastwithai.com and go deeper on related topics:
- Anthropic Advisor Strategy: Smarter AI Agents (2026)
- Claude Mythos 5 Review: Anthropic's Most Powerful Model (2026)
- Best AI Models April 2026: Ranked by Benchmarks
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 (2026)
- Claude AI 2026: Models, Features, Desktop & More
- Best Claude Prompts That Work in 2026 (150+ Tested Examples)
- Best AI for Coding 2026: Nemotron vs GPT-5.3 vs Opus 4.6
References
- Anthropic — Introducing Claude Opus 4.7 (Official Announcement)
- Anthropic — Claude Opus 4.7 Model Overview Page
- Anthropic API Docs — What's New in Claude Opus 4.7
- Anthropic API Docs — Models Overview (Pricing & Specs)
- Vellum AI — Claude Opus 4.7 Benchmarks Explained
- VentureBeat — Anthropic Releases Claude Opus 4.7
- The Next Web — Claude Opus 4.7 Coding and Agentic Benchmarks
- CNBC — Anthropic Releases Claude Opus 4.7, Less Risky Than Mythos
- Axios — Anthropic Releases Claude Opus 4.7, Concedes It Trails Mythos
- GitHub Changelog — Claude Opus 4.7 Generally Available
- AWS — Claude Opus 4.7 Now Available in Amazon Bedrock

