





Claude AI 2026: The Only Guide You Need for Every Model, Feature and Competitor
4% of all public GitHub commits are now authored by Claude Code. That number doubled in a single month.
Stop and reread that. Not 4% of AI-assisted commits. 4% of every public commit on GitHub. Anthropic has quietly moved from the thoughtful alternative to ChatGPT to running infrastructure that millions of developers rely on every working day. In the last 30 days alone they shipped more than most AI companies do in a year: memory for every free user, a security scanner that crashed cybersecurity stocks by up to 9%, a desktop productivity agent called Cowork, and a complete overhaul of Claude Code's architecture.
This guide covers everything: all three models, every new feature, pricing, real benchmark data, head-to-head comparisons against ChatGPT, Gemini, Grok, and DeepSeek, and a look at what Claude 5 might look like when it ships.
What Is Claude AI? The Basics for New Users
Claude is an AI assistant built by Anthropic, a safety-focused company founded in 2021 by Dario Amodei, Daniela Amodei, and a team of former OpenAI researchers. Claude is available as a web, mobile, and desktop chat interface at claude.ai, through the Anthropic API, on AWS Bedrock, and on Google Vertex AI.
What actually differentiates Claude from ChatGPT or Gemini is Constitutional AI. Instead of training purely on human preference ratings, Anthropic teaches Claude a set of principles (a 'constitution') and lets the model reason about its behavior against those principles. The 2026 version of that constitution has grown from 2,700 words in 2023 to 23,000 words today. That is not legal padding. It is an attempt to build a model with genuine ethical judgment, not just a rule filter.
I believe this is Anthropic's most underappreciated technical advantage. Scaling a coherent ethical reasoning framework as model capability increases is a harder and more defensible engineering problem than training on preference labels alone.
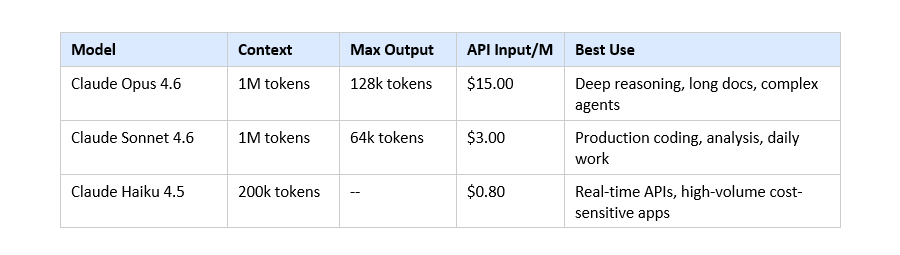
Claude is currently on its 4.6 generation of models. The top model, Opus 4.6, supports 1 million tokens of context and generates up to 128,000 output tokens per response.
All Three Claude Models Explained: Opus 4.6, Sonnet 4.6, Haiku 4.5
Claude Opus 4.6 - The Flagship
Opus 4.6 launched February 5, 2026. It is the most capable production model Anthropic has shipped. Specs: 1 million token context window, 128,000 max output tokens per response (doubled from the previous 64k cap), full adaptive thinking support, and 80.9% on GPQA Diamond (graduate-level science reasoning), 80.8% on SWE-bench verified. API pricing: $15/million input tokens, $75/million output tokens.
The 128k max output matters more than the spec suggests. It means Claude can generate an entire codebase module, a multi-file refactor, or a 50,000-word research report in a single response without truncation.
Claude Sonnet 4.6 - The Daily Driver
Sonnet 4.6 is where most professional users should default. Same 1M token context window as Opus. 64k max output. 79.6% on SWE-bench, which is near-Opus performance at 5x lower cost ($3/M input, $15/M output). For production coding agents, document analysis, or enterprise workflows, Sonnet 4.6 is almost always the rational pick.
Claude Haiku 4.5 - The Speed Model
Haiku 4.5 is built for throughput. 200k token context, 200+ tokens per second, $0.80/M input. The key achievement: it is the first Haiku model to support Extended Thinking, bringing chain-of-thought reasoning to the fastest and cheapest tier. Still scores 73.3% on SWE-bench at this price point
One million tokens equals approximately 750,000 words. Three complete novels side by side. For enterprises processing contracts, codebases, or research libraries in single prompts, this context window is not a benchmark stat. It is a workflow transformation.
Every New Feature Released in the Last 30 Days
Adaptive Thinking: Claude Decides When to Reason
This received the least press coverage and has the most technical significance. The previous Extended Thinking approach required developers to set a budget_tokens parameter: you told Claude exactly how many tokens it was allowed to use for internal reasoning. That method is now deprecated on Opus 4.6.
The new approach: thinking: {type: 'adaptive'}. Claude evaluates each request and independently decides whether and how deeply to engage extended reasoning. On complex problems it almost always activates. On simple prompts it skips reasoning entirely to save compute and latency. This is meta-cognition baked into the API layer.
Memory for Every User (March 2026)
Anthropic pushed persistent memory to all Claude users, including the free tier, in early March 2026. Claude now retains your name, communication style, writing preferences, and ongoing project context across separate conversations. You start a new chat; Claude already knows who you are.
ChatGPT has had this feature for paid users since early 2024. Anthropic gave it to everyone, with full transparency controls: you can view every stored memory, edit individual entries, or wipe the entire history at any time.
Claude Code Security (February 20, 2026)
The biggest product launch in Anthropic's history by market impact. Claude Code Security launched as a limited research preview for Enterprise and Team customers. It uses Opus 4.6 to scan production codebases for vulnerabilities by reasoning about data flows and component interactions, the way a human security researcher does, not pattern-matching like traditional static analysis tools.
In pre-launch testing, Anthropic found over 500 vulnerabilities in real open-source production codebases, including bugs undetected for years despite active expert review. Every finding is severity-rated. No patch is applied without explicit human approval.
The market reaction was immediate: CrowdStrike fell 8%, Cloudflare dropped 8.1%, Okta declined 9.2%, Zscaler lost 5.5%, and the Global X Cybersecurity ETF closed at its lowest since November 2023.
Fast Mode and Data Residency Controls
Two enterprise developer additions: speed: 'fast' with the fast-mode-2026-02-01 beta flag accelerates Opus output generation for time-sensitive pipelines. The inference_geo parameter routes API calls to US-only infrastructure, satisfying data residency requirements in healthcare, finance, and government deployments.
Claude Code 2026: What Changed in the February Overhaul
Claude Code started as a command-line AI pair programmer. After February 2026, it is closer to an autonomous software operations platform. Five new capabilities defined the upgrade:
- Remote Control: Access and monitor a running Claude Code session from a browser or mobile device. Start a long refactor at your desk, check progress from your phone.
- Scheduled Tasks: Claude Code executes recurring workflows without manual prompts. Security audits every Monday. Test coverage reports after each deployment. PR summaries every Friday afternoon.
- Plugin Ecosystem: Standardized MCP integrations let third-party tools plug into Claude Code natively, similar to VSCode extensions but at the agent layer.
- Parallel Agents: Large tasks decompose into subtasks executed by multiple coordinated Claude instances simultaneously. Build frontend and backend in parallel. Scan security while writing docs.
- Auto Memory: Persistent knowledge of your specific project - architecture decisions, naming conventions, team standards, past choices. Context that builds over time rather than restarting every session.
4% of all public GitHub commits are now authored by Claude Code. That figure doubled in one month. And approximately 90% of Claude Code's own code is now written by Claude Code itself, according to Anthropic engineers. These are not aspirational numbers. They are production metrics from a tool that has already escaped the experimental phase.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Claude Desktop App and Cowork: AI for Everyone
Claude Cowork launched January 12, 2026 in research preview. It is the desktop version of Claude's agentic capabilities, built for knowledge workers who do not live in terminals or code editors.
The interface is file-and-folder based. You grant Claude access to a directory. You describe the task. Claude reads existing files, executes the workflow, and produces deliverables in the same folder. Tasks it handles: restructuring messy file systems, pulling data from screenshots or PDFs into spreadsheets, drafting reports by synthesizing scattered documents, generating slide decks from raw notes, filling client briefs from email threads.
Anthropic's Head of Enterprise Scott White framed it as 'vibe working': the non-developer equivalent of vibe coding. The same way non-programmers can now describe a web app and have AI build it, knowledge workers can describe a deliverable and have Claude produce it.
Markets on launch day: ServiceNow -23%. Salesforce -22%. Thomson Reuters -31%. Institutional money read those moves as a verdict that a $20/month AI agent capable of doing workflow automation competes directly with enterprise software platforms charging hundreds of thousands of dollars annually.
Cowork requires a paid plan: Pro (~$20/month), Max ($100-$200/month), Team ($30/seat), or Enterprise. Connects to local files, Google Drive, Gmail, and Calendar via MCP integrations.
Claude Pricing in 2026: Every Plan and API Cost
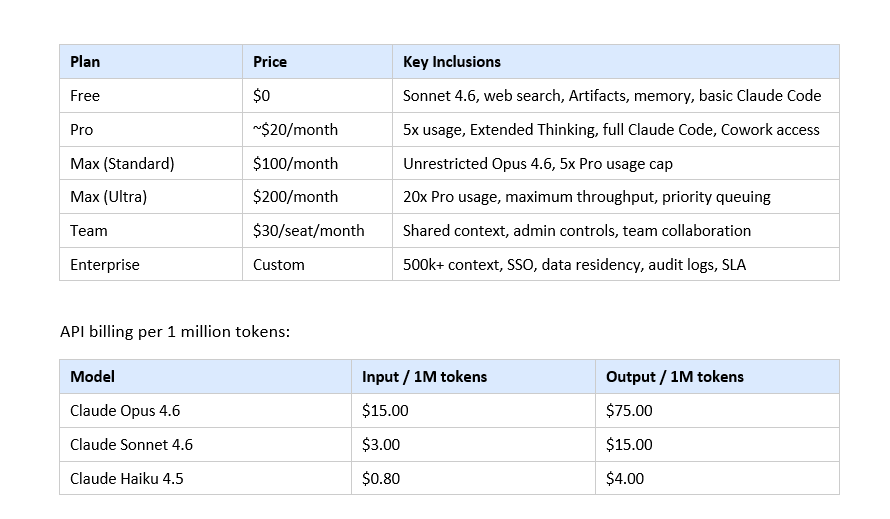
The free tier is the most competitive it has ever been. Memory, web search, Artifacts, and Sonnet 4.6 access for $0 is a serious offering. Claude Pro at $20/month with Extended Thinking, full Claude Code, and Cowork preview delivers more capability-per-dollar than any comparable AI subscription. The Max tier makes sense only for power users or professionals who run Opus 4.6 as their primary work tool.
Benchmark Data: Claude vs ChatGPT, Gemini, Grok, DeepSeek
Here are the actual numbers from independent benchmark sources as of March 2026. Not marketing claims.
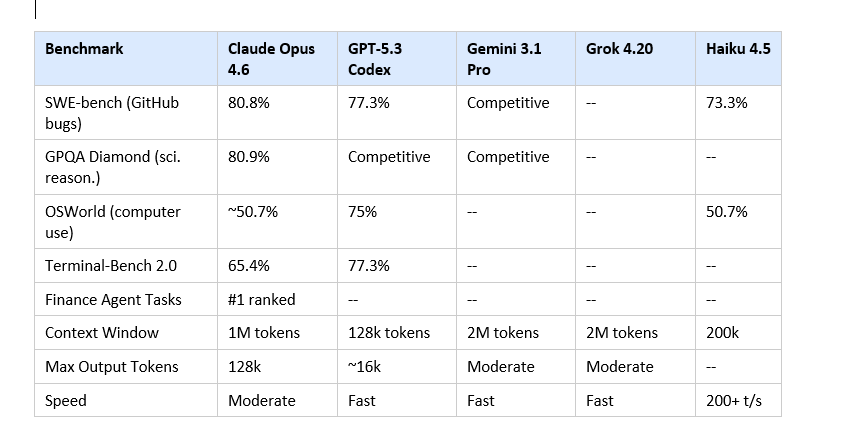
Three things I want to call out directly. First, GPT-5.3 Codex beats Claude on Terminal-Bench 2.0 by nearly 12 percentage points. That is a real gap for terminal-heavy agentic work; do not let Claude advocates minimize it. Second, both Gemini 3.1 Pro and Grok 4.20 offer 2M token context windows, which is larger than Claude's 1M. Third, on OSWorld computer use automation, Claude sits around 50% while GPT-5.4 has pushed to 75%. Anthropic appears to be making a deliberate choice to prioritize long-context quality over this specific benchmark.
Where Claude holds a defensible lead: SWE-bench (real-world software engineering), GPQA Diamond (graduate-level reasoning), 128k max output tokens (nobody else is close at these prices), and finance agent tasks (#1 ranked). These are not niche benchmarks. They are the tasks enterprises actually care about.
Claude Skills and Agentic Capabilities Explained
Skills are pre-built, reusable capability modules that extend what Claude can do inside Claude Code and Cowork. Think of them as specialized function libraries for AI agents, built on the Model Context Protocol (MCP) standard.
In Claude Code, skills enable actions that go beyond raw coding: running a full security audit, generating comprehensive test suites for a specific framework, producing API documentation from code comments, refactoring legacy code toward a modern standard. Each skill is a standardized MCP integration that Claude Code can invoke as part of a larger workflow.
The February 2026 Plugin Ecosystem opening means third parties can now publish skills into the Claude Marketplace. As of March 6, 2026, six enterprise partners are live:
- GitLab: Code review automation, CI/CD pipeline integration, PR analysis
- Harvey: Legal document analysis, contract review, regulatory compliance checking
- Lovable: No-code app generation and iteration without touching a terminal
- Replit: Cloud development environment creation and management
- Rogo: Financial report analysis, earnings transcript processing, market research
- Snowflake: Natural language querying of data warehouses, schema understanding
What this architecture enables in practice: a single Claude Code session can now orchestrate across GitHub, your database, your documentation system, your cloud infrastructure, and your legal review pipeline, using native skills for each, without custom integration code for every tool.
I think MCP and skills are the most underreported story in AI right now. Everyone covers benchmark scores. Almost no one is writing about the integration layer that turns benchmark scores into actual production value. The companies that figure out Claude as an orchestration layer, not just a smart autocomplete, are going to have significant workflow advantages by end of 2026.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Claude for Enterprise: Context, Market Share, and the Marketplace
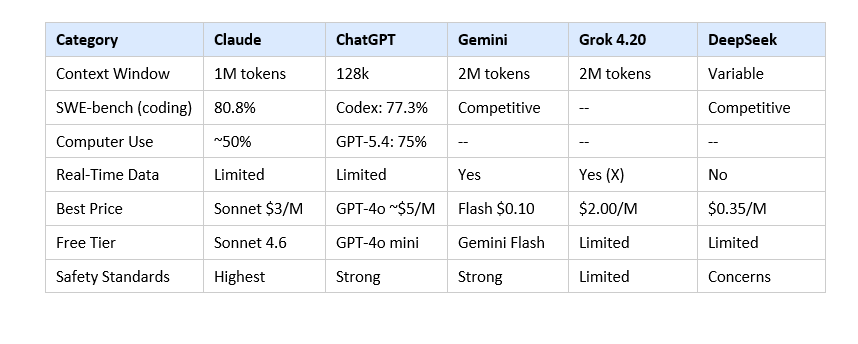
Consumer web traffic data from SimilarWeb in January 2026 shows ChatGPT at approximately 64.5% of AI chatbot traffic, Gemini at 21.5%. Claude's consumer share is smaller.
But consumer web traffic is the wrong metric for understanding Anthropic's actual position. Three enterprise data points tell a different story:
Claude Code revenue grew 5.5x between Q1 and Q3 2025. Claude Enterprise provides 500,000 token context windows, more than double what ChatGPT Enterprise offers, and this enables use cases like processing an entire year of financial filings or a 300-file codebase in a single prompt. And the Claude Marketplace, launched March 6, 2026, consolidates procurement across six partner tools into a single Anthropic billing relationship, which is how enterprise software sales actually work.
Multi-cloud availability is also strategically important. All Claude models run on the Anthropic API, AWS Bedrock, and Google Vertex AI. Large enterprises cannot migrate their entire stack to a new vendor's platform. Meeting them where they already are is why Anthropic is winning deals that purely API-native companies cannot.
Head-to-Head: Claude vs ChatGPT, Gemini, Grok, DeepSeek
Claude vs ChatGPT (OpenAI GPT-5 Family)
Context window is Claude's clearest structural enterprise advantage. Claude Enterprise offers 500,000 tokens; ChatGPT Enterprise offers less than half. In a controlled blind test across 8 prompts with 134 participants, Claude won 4 out of 8 rounds, ChatGPT won 1, Gemini won 3. When Claude won, margins were 35 to 54 points. When Gemini won, margins were 3 to 11. Claude wins decisively or loses.
ChatGPT's real advantages: 200 million weekly users, the largest developer ecosystem, OpenAI's Operator network, and GPT-5.4's 75% OSWorld computer use score. For general consumer use and computer use automation, ChatGPT leads. For enterprise long-context reasoning and production coding: Claude leads.
Claude vs Gemini 3.1 Pro (Google)
Gemini is faster, offers a 2M token context window, and integrates natively with Google Workspace, Firebase, and Android development workflows. If your team is built on Google infrastructure, Gemini is a serious tool. Where Claude wins: complex multi-step reasoning, debugging logic errors in large codebases, and sustained agentic performance across long sessions. Gemini can produce code that looks clean but has subtle logical errors. Claude's outputs tend to be more reliably correct and debuggable.
Claude vs DeepSeek V4
DeepSeek V4 is the best performance-per-dollar model available in 2026. No debate on that point. For cost-sensitive teams willing to handle their own infrastructure or accept Chinese data residency, DeepSeek is the rational economic choice. For regulated industries, US compliance requirements, or organizations that need Anthropic's safety guarantees and model reliability track record: Claude wins on everything except pure cost.
Claude vs Grok 4.20 (xAI)
Grok 4.20 launched February 17, 2026 with a genuinely different architecture: four specialized agents (Grok, Harper, Benjamin, and Lucas) running in parallel, covering coordination, real-time fact-checking with live X data, logic and math, and contrarian analysis. This peer-review mechanism reduces hallucinations from approximately 12% to 4.2% according to benchmark data. Context window: 2M tokens. Consumer access requires SuperGrok ($30/month) or X Premium+. For real-time information tasks and social media analysis, Grok has an edge no other model can match. For deep long-context reasoning, enterprise coding, and document processing: Claude wins.
Claude vs Kimi K2.5 (Moonshot AI)
Kimi K2.5 launched January 27, 2026 with comparable coding performance to Claude Opus 4.6 at approximately 10x lower API pricing. 1 trillion total parameters, 32B active via Mixture of Experts, 256k context window, fully open-source. It is the dark horse in the 2026 coding model race. For pure coding workloads where cost matters more than reasoning quality or enterprise compliance: Kimi deserves serious evaluation. Anthropic is not trying to compete on price here. They are competing on trust, safety reputation, and enterprise tooling quality.
Controversies, Ethics, and the Pentagon Standoff
Anthropic is navigating two situations that test whether their safety positioning is genuine or marketing.
The Pentagon standoff: In February 2026, the US Department of Defense demanded Anthropic remove contractual prohibitions on using Claude for mass domestic surveillance and fully autonomous weapons. Defense Secretary Pete Hegseth set a February 27, 2026 deadline for Anthropic's response. Anthropic declined to comply. Claude's use by US federal agencies is now being phased out.
Anthropic turned down significant federal government revenue rather than allow Claude to be used in ways their safety principles prohibit. Whatever your view on the specific prohibitions, the fact that they held that position under pressure from the Pentagon is meaningful evidence that the safety commitments are not just positioning.
The Constitution update: Philosopher Amanda Askell expanded Claude's constitutional guidelines from 2,700 words to 23,000. The expansion is not new restrictions. It is detailed reasoning context so Claude can apply judgment in novel situations rather than pattern-match to rules. Whether this produces better behavior than traditional fine-tuning is still an open empirical question in the field.
What Is Coming Next: Claude 5 Leaks and Roadmap
Multiple sources report that Claude 5 (Sonnet 5, codenamed 'Fennec') has already appeared in Google Vertex AI infrastructure logs. Expected release window: mid-2026.
What early intelligence suggests about Claude 5:
- Coding performance that surpasses Opus 4.6 at Sonnet-level pricing
- 'Dev Team' multi-agent mode: multiple specialized Claude instances coordinating on a single long-horizon engineering project
- Pricing approximately 50% lower than current flagship models
- Persistent memory baked into core architecture rather than layered on top
- Sustained multi-week reasoning for enterprise projects that span months, not sessions
The March 2026 memory rollout reads like architectural groundwork for Claude 5. If persistent memory gets baked into the model's core training rather than existing as a retrieval layer, the resulting assistant would be genuinely different from anything currently available: a tool that builds a detailed model of you, your preferences, and your work context over months rather than minutes.
Claude Cowork moving from research preview to general availability is also expected by mid-2026, and the Marketplace is scheduled to add 15+ new enterprise partner integrations by Q3 2026.
Frequently Asked Questions
What is Claude AI and how does it differ from ChatGPT in 2026?
Claude is built by Anthropic using Constitutional AI, a training method where the model reasons about its own behavior against ethical principles rather than just optimizing for human preference ratings. Practical differences: Claude offers 1M token context (vs ChatGPT's 128k), tops enterprise coding benchmarks, and gives free-tier users memory and Sonnet 4.6. ChatGPT has 200M+ weekly users and a broader consumer ecosystem. Neither is dominant across every category.
What Claude models are available in 2026?
Three: Claude Opus 4.6 (1M context, 128k output, $15/M input), Claude Sonnet 4.6 (1M context, 64k output, $3/M input), and Claude Haiku 4.5 (200k context, 200+ tokens/sec, $0.80/M input). All available via claude.ai, Anthropic API, AWS Bedrock, and Google Vertex AI.
What is Claude Cowork and who should use it?
Claude Cowork is a desktop agent for knowledge workers launched January 12, 2026 in research preview. You give Claude access to a folder; it reads files, executes multi-step workflows, and produces deliverables autonomously. No coding required. Best for operations professionals, analysts, executives, and anyone who manages complex documents or recurring deliverables. Requires a paid Claude plan starting at $20/month.
What happened with Claude Code Security in February 2026?
Claude Code Security launched February 20, 2026 for Enterprise and Team customers. Using Opus 4.6, it found over 500 vulnerabilities in production open-source codebases through reasoning about data flows rather than pattern-matching. The launch caused major cybersecurity stock drops: CrowdStrike -8%, Okta -9.2%, Cloudflare -8.1%, Zscaler -5.5%. Every finding requires human approval before action.
Is Claude better than ChatGPT for coding in 2026?
For enterprise software engineering measured by SWE-bench, Claude Opus 4.6 (80.8%) outperforms most GPT models. GPT-5.3 Codex beats Claude on Terminal-Bench 2.0 (77.3% vs 65.4%), making it stronger for terminal-heavy workflows. Most professional developers use both: Claude for complex reasoning and large codebases, GPT-5.3 Codex for terminal-heavy batch operations.
How much does Claude cost in 2026?
Claude Free: $0 (Sonnet 4.6). Claude Pro: ~$20/month. Claude Max: $100 or $200/month. Team: $30/seat/month. Enterprise: custom. API: Haiku 4.5 at $0.80/M input, Sonnet 4.6 at $3/M input, Opus 4.6 at $15/M input.
What is adaptive thinking in Claude?
Adaptive thinking (thinking: {type: 'adaptive'}) is the new Extended Thinking API mode for Opus 4.6 and Sonnet 4.6. Unlike the deprecated budget_tokens approach, adaptive thinking lets Claude independently decide whether a prompt requires extended reasoning. Complex tasks get full chain-of-thought. Simple tasks skip reasoning entirely. This reduces unnecessary compute costs and removes manual reasoning management from developers.
What is Claude's context window and why does it matter?
Claude Opus 4.6 and Sonnet 4.6 support 1 million token context windows, approximately 750,000 words. Haiku 4.5 supports 200,000 tokens. Claude Enterprise starts at 500,000 tokens. This enables enterprises to process entire codebases, year-long document histories, or hundreds of contracts in a single prompt, which is not possible with 128k-capped models.
When is Claude 5 expected to release?
Based on code named 'Fennec' appearing in Google Vertex AI logs, Claude 5 is expected in mid-2026. Early signals suggest near-Opus performance at Sonnet prices, a Dev Team multi-agent mode, pricing 50% lower than current flagships, and persistent memory baked into the model's core architecture rather than layered on.
Recommended Reads
If you found this guide useful, these posts from Build Fast with AI go deeper on related topics:
Grok 4.20 Beta Explained: Non-Reasoning vs Reasoning vs Multi-Agent (2026)
GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5: Who Actually Wins? (2026)
Best ChatGPT Prompts in 2026: 200+ Prompts for Work, Writing and Coding
What Is Agenta: The LLMOps Platform Simplifying AI Development
References
- Claude Models Overview — Anthropic API Documentation
- Claude 4.6 What's New — Anthropic API Documentation
- Claude Code Security Launch — Anthropic
- Claude Code February 2026 Update Analysis — Nagarro
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 — Build Fast with AI
- Grok 4.20 Beta Explained 2026 — Build Fast with AI
- Enterprise AI Comparison: Claude vs ChatGPT vs Gemini — Intuition Labs
- Best LLMs for Coding 2026 — Eden AI
Want to build real AI agents using Claude and other frontier models?
Join Build Fast with AI's Gen AI Launchpad - an 8-week structured program to go from 0 to 1 in Generative AI.

