




Qwen3.7-Max vs Claude, GPT-5.5, Kimi K2.6, GLM-5.1: Code Arena's 2026 Coding Leaderboard, Explained
On May 25, 2026, Arena.ai added Qwen3.7-Max (20260517) to its Code Arena leaderboard. It debuted at #4 overall — with a 1541 Elo — making it the highest-ranked Chinese-lab model on the board, ahead of GLM-5.1, ahead of Kimi K2.6, and on par with Anthropic's Claude Opus 4.6 family on agentic web development tasks. The only models above it on Code Arena are three Claude Opus variants from Anthropic.
That is the news headline. The actually interesting question for developers is what this means for model selection in May 2026. The frontier is no longer a two-horse race between OpenAI and Anthropic. It is a six-way fight — Claude Opus 4.7, GPT-5.5, Qwen3.7-Max, Kimi K2.6, GLM-5.1, Gemini 3.5 Flash — where each model wins on a different axis, and the right call depends entirely on what you are building.
This piece is the head-to-head comparison. Arena leaderboard reality, benchmark cross-references, price math, and the honest recommendation on which model to pick for which workload. Plus the broader signal everyone in AI is reading right now: China's frontier labs have closed the coding gap, and the pricing war that follows is going to reshape the economics of agent products through the rest of 2026.
1. What Code Arena actually measures
Before reading the rankings, it helps to know what they reward. Arena.ai's Code Arena is built on the same head-to-head human preference methodology that LM Arena (formerly Chatbot Arena) made famous. Developers submit real coding prompts — frontend tasks, backend tasks, debugging, refactoring — and two anonymized model outputs are returned. Voters pick which is better. Thousands of pairwise votes produce an Elo score per model.
Two things this measures well, and two things it does not. It measures real-world human preference on agentic web development tasks, where Qwen3.7-Max landed at #4 with 1541 Elo. It measures whether a model's output feels right to a working developer reviewing code. It does not capture single-shot correctness the way SWE-Bench Verified does — a model that produces beautiful code that fails to compile can still beat one that produces ugly code that ships. And it does not capture long-horizon agentic capability, where benchmarks like Terminal-Bench 2.0 are the better proxy.
The Code Arena rankings are the cleanest available signal for one specific question: which model writes code that developers prefer when they see it? On that question, Anthropic still holds three of the top three slots, and Qwen3.7-Max is the first non-Anthropic, non-Western model in the top tier.
2. The May 2026 Code Arena leaderboard (full table)
Here is the top-of-board as of the May 25 update, with Elo scores cross-referenced against Arena's official changelog and partner reporting. Numbers move daily as voting accumulates — treat them as a snapshot, not a fixed truth.
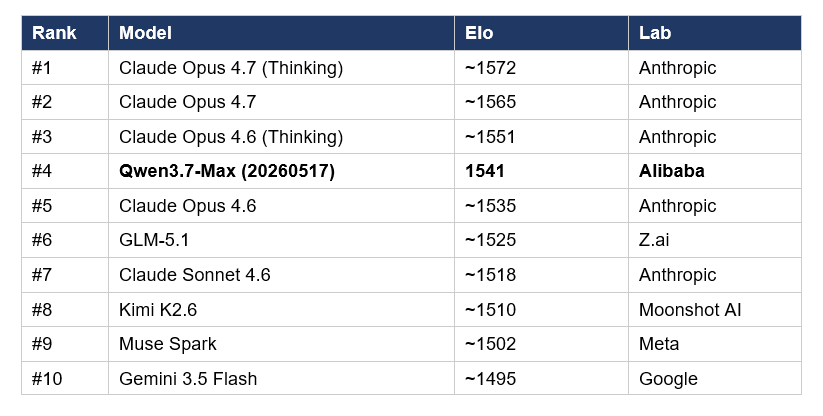
Note the spread. The gap from #1 to #11 is roughly 84 Elo points — about 5% across the entire top of the leaderboard. Everything on this list ships production code. The meaningful differences are in cost, context window, deployment economics, and specialization. For the broader competitive picture across every frontier model launched this year, the April + May 2026 Best AI Models leaderboard at Build Fast with AI tracks the full field with cost-per-intelligence math and use-case-specific verdicts.
Three things worth highlighting before we go into the head-to-heads. First, Qwen3.7-Max's #4 finish is significant because it places ahead of GLM-5.1 (#6), Kimi K2.6 (#8), and Gemini 3.5 Flash (#10) — meaning Alibaba is now the clear leader among Chinese labs on Code Arena. Second, Anthropic's dominance is real but no longer total: every top-3 slot is a Claude Opus variant, but the gap to Qwen3.7-Max is narrower than the gap from Qwen3.7-Max to GPT-5.5 (#11). Third, GPT-5.5 Xhigh's relatively low Code Arena position is misleading — OpenAI's model has stronger raw intelligence scores but is being penalized on a benchmark that measures human-preferred code style.
3. Qwen3.7-Max vs Claude Opus 4.7 — the engineering depth question
This is the comparison everyone is running. Claude Opus 4.7 is Anthropic's flagship — currently the highest-ranked publicly available model on Code Arena, leading on SWE-Bench Verified at ~82%, and the default choice for serious engineering teams. Qwen3.7-Max is the new contender, four rank positions behind.
Where Opus wins: raw engineering depth on large multi-file codebases, conversational quality, design system reasoning, and the broader ecosystem (Claude Code, MCP integrations, Cyber Verification Program). On Code Arena head-to-head voting, developers pick Opus over Qwen3.7-Max meaningfully more often. The 24-point Elo gap is small in absolute terms but compounds over hundreds of editing turns.
Where Qwen3.7-Max wins: agentic coding benchmarks specifically. Terminal-Bench 2.0 — the test that simulates a software engineer working in a sandboxed terminal — gives Qwen3.7-Max 69.7% versus Opus 4.6's 65.4%. SWE-Bench Pro is 60.6% versus 57.3%. And on cost, Qwen3.7-Max ships at $2.50/$7.50 per million tokens, versus $15/$75 for Opus — a 6× difference that compounds dramatically on multi-hour agent runs.
My honest read: Opus wins the chat surface and the per-turn quality contest. Qwen3.7-Max wins the multi-hour, multi-tool agent contest. If you are running short, dense engineering sessions, pick Opus. If you are running autonomous agent workflows that fire hundreds of tool calls — like the 35-hour, 1,158-tool-call autonomous kernel optimization run Alibaba demonstrated at launch — Qwen3.7-Max becomes the rational default. The cost difference alone makes that math obvious.
4. Qwen3.7-Max vs GPT-5.5 — the intelligence vs agent gap
GPT-5.5 leads on raw intelligence. Period. On the Artificial Analysis Intelligence Index v4.0, GPT-5.5 scores 60.2 versus Qwen3.7-Max's 56.6 and Opus 4.7's 57.3. On structured reasoning, dense logic puzzles, and academic benchmarks, OpenAI still has the strongest model in the field. The Code Arena ranking at #11 understates GPT-5.5's actual capability — Arena's preference-voting methodology penalizes the model's verbose, comment-heavy output style relative to Anthropic's leaner code aesthetic.
Qwen3.7-Max's advantage is the agent surface and the price tag. GPT-5.5 sits at $10/$30 per million tokens — meaningfully cheaper than Opus, but still 4× the input cost and 4× the output cost of Qwen3.7-Max. For high-volume agentic workloads where the model is firing dozens of tool calls per task, Qwen3.7-Max's cost-per-completion is genuinely difficult to justify ignoring.
The other gap: context. GPT-5.5 ships with a 400K-token context window, which is large but meaningfully smaller than Qwen3.7-Max's 1 million tokens. For tasks that require loading entire codebases or multi-document research into a single prompt, Qwen3.7-Max has structural advantages GPT-5.5 cannot match on a per-request basis.
My read: if your workload is dense academic reasoning, technical writing, or scientific analysis, GPT-5.5 wins. If it is anything resembling an agent loop or a long-context task, Qwen3.7-Max wins on math alone.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Qwen3.7-Max vs Kimi K2.6 vs GLM-5.1 — the Chinese frontier war
This is the comparison that matters most for the next 12 months of AI economics. Three Chinese labs — Alibaba (Qwen), Moonshot AI (Kimi), and Z.ai (GLM) — are now shipping models that compete at the frontier on coding tasks. Each has a distinct positioning.
Qwen3.7-Max — the closed flagship
API-only, no open weights as of late May 2026. 1M-token context, $2.50/$7.50 pricing, 1541 Code Arena Elo at #4. Strongest on long-horizon agent benchmarks (Terminal-Bench 2.0, MCP-Atlas) and large-context tasks. Alibaba's most aggressive frontier release to date.
Kimi K2.6 — the open-weight winner
Modified MIT license, 262K-token context, $0.95/$3.50 pricing, ~1510 Code Arena Elo at #8. Kimi K2.6 achieved Tier A (87/100) on real-world coding tasks — the only Chinese model to reach that tier — and supports 300-agent parallel swarm orchestration. Cheapest of the three by a wide margin, and the only one you can actually self-host.
GLM-5.1 — the SWE-Bench specialist
Open weights, 1M-token context, $3/month Coding Plan for managed API access, ~1525 Code Arena Elo at #6. GLM-5.1 was the first open-weight model to top SWE-Bench Pro earlier in 2026, and remains the strongest pure-coding open model for teams that need MIT-style flexibility and full downloadable weights.
If you are weighing all three side by side for production deployment, the depth comparison we ran on the predecessor cohort is the right starting point: Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5 — Best Chinese AI for Coding 2026. Most of those structural differences carry forward to the current generation.
Practical translation. Pick Qwen3.7-Max if you need a closed, frontier-tier model with the longest agent runs and the largest context window. Pick Kimi K2.6 if you need open weights and the cheapest API pricing. Pick GLM-5.1 if you need open weights with strong SWE-Bench performance and the $3/month subscription is the right shape for your team.
6. Gemini 3.5 Flash — the instruction-following dark horse
Google's Gemini 3.5 Flash landed on Arena's Code leaderboard on May 19, 2026 at #10 with roughly 1495 Elo. The Elo score understates what makes Flash interesting. It is the fastest model in the top 11. It has the lowest latency. And developers on X have been consistently praising its instruction-following discipline — it does exactly what you ask, no more, no less. That is unusually rare in 2026's frontier models, most of which add unrequested context, explanations, or refactors to your output.
Where Flash wins: high-volume API workloads where consistency, latency, and price matter more than peak quality. Code completion. Templated generation. Batch processing where you are dispatching thousands of requests per hour. For agentic systems where the model is one component among many, Flash's predictable behavior is genuinely valuable.
Where Flash loses: it is not a frontier-tier reasoning model. For complex multi-step refactors, novel algorithm design, or anything requiring deep architectural thinking, Flash will not beat Opus, GPT-5.5, or Qwen3.7-Max. It is the wrong tool for that job — and Google is positioning it that way deliberately. Gemini 3.1 Pro is Google's frontier model; Flash is the cost-efficient workhorse layer underneath it.
7. The full head-to-head benchmark table
Here is the consolidated comparison across Qwen3.7-Max, Claude Opus 4.7, GPT-5.5, and Kimi K2.6 on the metrics that matter most for engineering teams:
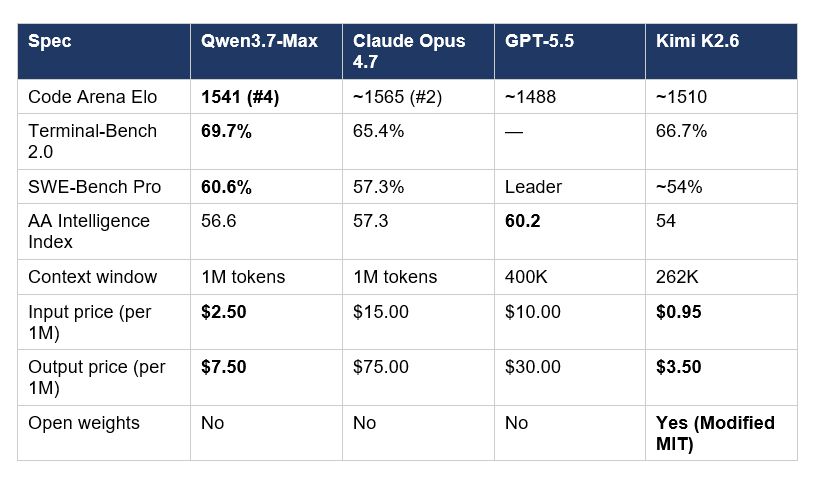
Two patterns to take away. First, Qwen3.7-Max and Kimi K2.6 are the two genuinely affordable frontier-tier options — both cost less than $4 per million output tokens, versus $30–$75 for OpenAI and Anthropic's flagships. Second, the benchmark winners depend entirely on which benchmark you look at. Claude Opus 4.7 wins Code Arena. Qwen3.7-Max wins Terminal-Bench 2.0 and SWE-Bench Pro. GPT-5.5 wins the Intelligence Index. Kimi K2.6 wins open-weight flexibility. There is no single best model in May 2026.
8. Pricing, access, and the cost-per-intelligence math
Cost-per-intelligence is the framework that actually matters for production deployment. Take the Artificial Analysis Intelligence Index score, divide by the blended cost per million tokens, and you get a single number that tells you which model gives you the most capability per dollar.
Quick math at typical agentic workload ratios (~70% input, 30% output):
- Qwen3.7-Max: 56.6 / blended $4.00 = 14.15 capability-per-dollar
- Kimi K2.6: 54.0 / blended $1.72 = 31.40 capability-per-dollar (winner)
- GPT-5.5: 60.2 / blended $16.00 = 3.76 capability-per-dollar
- Claude Opus 4.7: 57.3 / blended $33.00 = 1.74 capability-per-dollar
On this framework, Kimi K2.6 wins outright. Qwen3.7-Max is the closest second. GPT-5.5 and Claude Opus 4.7 are the premium options where intelligence-per-dollar is being traded for absolute capability or ecosystem benefits. This is the math that is going to drive infrastructure decisions through the rest of 2026 — and the reason every Western lab is now under serious pricing pressure from the Chinese frontier.
Access points for Qwen3.7-Max specifically: Alibaba Cloud Model Studio (primary, Singapore region), OpenRouter (OpenAI-compatible API), Together AI, and chat.qwen.ai for direct experimentation. Cached input drops to $0.25 per million tokens — a 90% discount that meaningfully changes the math for repeat-prompt agentic workflows.
9. Which model should you actually use?
The honest answer for May 2026 is that you should be using two or three, depending on workload. Here is the practical recommendation table:

If you want to see how these models perform specifically on UI generation and frontend design system tasks — not just generic coding — the deep comparison on the best AI models for frontend UI development covers Tailwind output quality, React component structure, and design system awareness in a way that Code Arena Elo alone cannot.
And for teams building production agent systems that compose multiple models, the 130+ open-source GenAI cookbooks in gen-ai-experiments cover the LangChain, LangGraph, and CrewAI patterns for routing different workload types to different models — which is now the rational architecture for any serious agent product in 2026.
My honest take after a week of running all of these in real workflows: the chatbot-as-single-default era is over. The model-as-routed-component era is here. Build your agent stack with Opus as the deep-reasoning brain, Qwen3.7-Max as the long-context agent backbone, Kimi K2.6 as the cost-sensitive parallel worker, and Gemini Flash as the high-throughput instruction follower. That is the architecture that wins on both cost and capability through the rest of 2026.
10. Frequently Asked Questions
What is Qwen3.7-Max's Code Arena Elo score?
Qwen3.7-Max (model ID qwen3.7-max-20260517) scored 1541 Elo on Arena.ai's Code Arena leaderboard, where it debuted at #4 overall on May 25, 2026. It is the highest-ranked Chinese-lab model on the board and ranks ahead of GLM-5.1, Kimi K2.6, Gemini 3.5 Flash, and GPT-5.5. Only three Claude Opus variants from Anthropic rank above it.
Is Qwen3.7-Max better than Claude Opus 4.7?
It depends on the workload. Claude Opus 4.7 leads on overall Code Arena Elo, raw engineering depth, and large-codebase reasoning. Qwen3.7-Max leads on agentic coding benchmarks specifically — Terminal-Bench 2.0 (69.7% vs 65.4%) and SWE-Bench Pro (60.6% vs 57.3%) — and costs roughly 6× less per token. For multi-hour autonomous agent runs, Qwen3.7-Max wins on math; for short, high-stakes engineering sessions, Opus wins on quality.
How does Qwen3.7-Max compare to GPT-5.5?
GPT-5.5 leads on raw intelligence (60.2 on the AA Intelligence Index versus 56.6 for Qwen3.7-Max), structured reasoning, and academic benchmarks. Qwen3.7-Max leads on context window (1M tokens vs 400K), price ($2.50/$7.50 vs $10/$30), and long-horizon agent tasks. The Code Arena gap (Qwen3.7-Max at #4, GPT-5.5 at #11) understates GPT-5.5's capability — it reflects Arena's preference for Anthropic-style lean code aesthetics, not raw reasoning ability.
Which is the best Chinese AI coding model in 2026?
It depends on what you optimize for. Qwen3.7-Max is the highest-ranked Chinese model on Code Arena (#4, 1541 Elo) and the strongest closed-source option. Kimi K2.6 is the best open-weight option, with 87/100 real-world coding tier and the lowest pricing. GLM-5.1 is the SWE-Bench Pro specialist with full open weights and a $3/month managed plan. Pick Qwen3.7-Max for closed-source frontier work, Kimi K2.6 for cost-sensitive open-weight deployment, GLM-5.1 for self-hosted production engineering.
Is Qwen3.7-Max better than Kimi K2.6 or GLM-5.1?
Qwen3.7-Max ranks higher on Code Arena (#4 vs #8 for Kimi K2.6 and #6 for GLM-5.1) and has a larger context window than Kimi K2.6. But Kimi K2.6 is roughly 2.5× cheaper, ships with open weights under a Modified MIT license, and supports 300-agent parallel swarm orchestration. GLM-5.1 is also open-weight with a $3/month managed option. For pure capability, Qwen3.7-Max wins. For cost and deployment flexibility, the open-weight Chinese models win.
How expensive is Qwen3.7-Max?
Qwen3.7-Max costs $2.50 per million input tokens and $7.50 per million output tokens via Alibaba Cloud Model Studio, OpenRouter, and Together AI. Cached input drops to $0.25 per million tokens — a 90% discount. For comparison, Claude Opus 4.7 costs $15/$75 per million tokens and GPT-5.5 costs $10/$30, making Qwen3.7-Max roughly 6× cheaper than Opus and 4× cheaper than GPT-5.5 on output.
Does Qwen3.7-Max beat Gemini 3.5 Flash?
On Code Arena, yes — Qwen3.7-Max sits at #4 with 1541 Elo while Gemini 3.5 Flash sits at #10 with roughly 1495 Elo. But Flash competes on a different axis. Flash is optimized for speed, latency, and instruction-following discipline, which makes it well-suited for high-volume code completion and templated generation where consistency matters more than peak reasoning quality. Qwen3.7-Max is the better choice for complex agentic workloads; Flash is the better choice for fast, predictable bulk-API workflows.
Is Qwen3.7-Max open source?
No. Qwen3.7-Max is proprietary and API-only as of late May 2026. Alibaba has historically released open-weight versions of Qwen models weeks to months after the flagship API launch — for example, Qwen3.6-35B-A3B shipped under Apache 2.0 in April 2026 — so an open-weight Qwen3.7 variant is likely but not yet confirmed. For an open-weight Chinese model at the frontier today, Kimi K2.6 and GLM-5.1 are the options.
Recommended Blogs
- Qwen3.7-Max Review: Alibaba's 1M-Token Agent Model
- Qwen3.7 Max Preview: Arena Ranks, Features & What's Next
- Kimi K2.6 vs Qwen 3.6 vs Opus 4.7 vs GPT-5.5: Which Wins?
- Claude Opus 4.7: Full Review, Benchmarks & Features (2026)
- Kimi K2.6: Open-Source Just Beat GPT-5.5 at Coding
- Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5: Best Chinese AI for Coding 2026
- Best AI Models: April + May 2026 Leaderboard
- Best AI Models for Frontend UI Development in 2026
References
- Arena.ai — Code Arena leaderboard
- Arena.ai — Leaderboard Changelog (qwen3.7-max-20260517 added May 25, 2026)
- Qwen — Qwen3.7: The Agent Frontier (Alibaba Cloud blog)
- MarkTechPost — Qwen Introduces Qwen3.7-Max
- Artificial Analysis — Qwen3.7-Max Intelligence, Performance & Price Analysis
- VentureBeat — Alibaba's Qwen3.7-Max can run for 35 hours autonomously
- DataCamp — Qwen3.7-Max: Features, Benchmarks and Agent Capabilities
- Cogni Down Under (Medium) — Claude Opus 4.7 leads on Code, GPT-5.5 wins Intelligence
- OpenRouter — Qwen3.7-Max API pricing and benchmarks
- Together AI — Qwen3.7-Max model card

