




Kimi K2.6 vs Qwen 3.6 Plus vs Claude Opus 4.7 vs GPT-5.5: Which Model Actually Wins? (2026)
Between April 16 and April 23, 2026, four major frontier AI models launched within seven days of each other. That has never happened before. Claude Opus 4.7 dropped on the 16th. Kimi K2.6 on the 20th. GPT-5.5 on the 23rd. Qwen 3.6 Plus had already landed on March 31 — and was already free on OpenRouter. Developers barely had time to benchmark one before the next landed.
This guide cuts through the noise. We compare all four across every benchmark that matters for production agentic work: coding, long-horizon execution, reasoning, vision, tool use, and cost per task — not cost per token. We also include the honest limitations and a routing framework so you know which model to use for which job.
Hot take upfront: there is no single winner. But for most developers who care about cost, Kimi K2.6 is the open-source bet. For teams that care about raw quality on hard problems, Claude Opus 4.7 and GPT-5.5 are still ahead — and GPT-5.5 is more efficient per task than its price suggests.
1. The Context: Why This 7-Day Window Changed the Model Landscape
Six months ago, the framing was simple: open-source models were interesting but not production-grade for hard coding and agentic tasks. Claude Opus and GPT-4o held the crown by a clear margin.
That is no longer true. Three data points establish the shift:
- On April 20, 2026, Kimi K2.6 posted 58.6% on SWE-Bench Pro — beating GPT-5.4 at 57.7% — at $0.60 per million tokens. Claude Opus 4.7 costs $5 per million input tokens. That is an 8x price gap at near-equivalent performance on the hardest software engineering benchmark.
- On May 3, 2026, developer Rohana Rezel ran a live 8-model coding challenge. Kimi K2.6 finished first. MiMo V2-Pro second. GPT-5.5 third. Claude Opus 4.7 fifth. Every Western frontier model placed below the top two Chinese open-weight models. The Hacker News thread hit 311 upvotes.
- Qwen 3.6 Plus was available free on OpenRouter during preview — 1 million token context, 78.8% SWE-bench Verified, always-on chain-of-thought reasoning. For developers building prototypes, this changed the economics of exploration entirely.
The honest framing: this is not "open source won." It is "the gap is now narrow enough that task, context, and cost should drive your model choice — not brand loyalty." To understand where this fits historically, our Best AI Models May 2026 Leaderboard covers the full competitive landscape across all model tiers.
2. Model Profiles at a Glance
Before the benchmark tables, here is what each model actually is — the architecture, the positioning, and the key differentiator in one paragraph each.
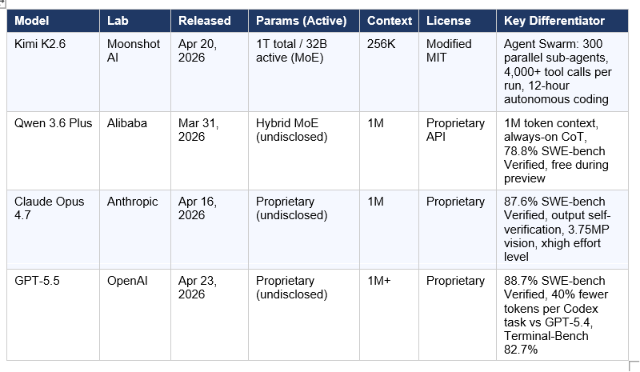
Kimi K2.6
Kimi K2.6 is Moonshot AI's fourth major release in under a year — a 1-trillion-parameter Mixture-of-Experts model with 32 billion parameters active per inference. That architecture math is the entire pricing argument: you pay for a 32B model while getting the routing capacity of a 1T system. The model is open-weight under a Modified MIT license, meaning full self-hosting rights below a 100M MAU / $20M monthly revenue threshold. Its standout architectural claim is Agent Swarm — scaling to 300 domain-specialized sub-agents executing up to 4,000 coordinated steps in a single autonomous run.
Qwen 3.6 Plus
Qwen 3.6 Plus is Alibaba's next-generation flagship, released March 31, 2026 on OpenRouter. Its headline differentiator is a native 1-million-token context window with up to 65,536 output tokens. Chain-of-thought reasoning is always active — no toggle, no thinking mode switch. The model scores 78.8% on SWE-bench Verified, achieves a #7 Code Arena ranking, and supports tool use, function calling, and vision natively. During the preview period it was available free on OpenRouter. For the full technical breakdown, our Qwen 3.6 Plus Preview deep-dive covers the architecture upgrade in detail.
Claude Opus 4.7
Claude Opus 4.7 is Anthropic's most capable publicly available model as of May 2026. Released April 16, it hits 87.6% on SWE-bench Verified (up from 80.8% on Opus 4.6) and introduces four targeted improvements: output self-verification before reporting back, more literal instruction following, 3.75-megapixel vision (3x the resolution of Opus 4.6), and a new xhigh effort level for finer reasoning-latency control. It also ships with task budgets in public beta — a mechanism to cap token spend per agentic run. Pricing is unchanged at $5/$25 per million input/output tokens, but a new tokenizer can use up to 35% more tokens for the same input text. For the full benchmark story, see our Claude Opus 4.7 review.
GPT-5.5
GPT-5.5 is OpenAI's frontier model as of April 23, 2026 — built on the GPT-5 family architecture with a post-training and inference upgrade. Its headline number: 88.7% on SWE-bench Verified and 82.7% on Terminal-Bench 2.0, the highest of the four models in this comparison on both metrics. The more important number for production use: GPT-5.5 generates approximately 40% fewer output tokens to complete the same Codex task as GPT-5.4. At double the per-token price ($5/$30 vs $2.50/$15 for GPT-5.4), this 40% efficiency gain brings the real per-task cost increase closer to 20% for most Codex workflows. For the full pricing math, see our GPT-5.5 review and benchmark analysis.
3. Benchmark Head-to-Head: The Numbers That Actually Matter
A note on methodology: vendor-published benchmarks are used where independent verification is not yet available. All Kimi K2.6 results use thinking mode enabled. All Claude Opus 4.7 results use xhigh effort. GPT-5.5 uses xhigh reasoning. Qwen 3.6 Plus uses always-on chain-of-thought. SWE-bench Pro is the harder, multi-language benchmark; SWE-bench Verified is the standard.
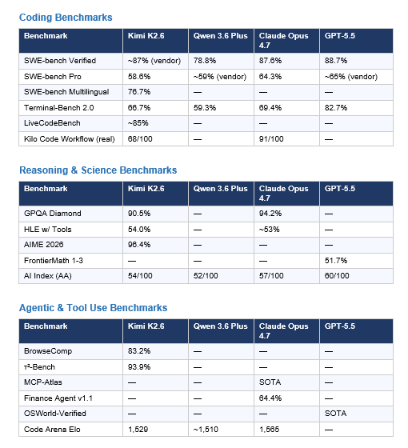
What the benchmark table actually says: GPT-5.5 leads on terminal-native, multi-step agentic tasks (Terminal-Bench 82.7%) and raw coding (SWE-bench Verified 88.7%). Claude Opus 4.7 leads on scientific reasoning (GPQA Diamond 94.2%), financial agents (Finance Agent 64.4%), and structured tool orchestration (MCP-Atlas). Kimi K2.6 leads on agentic search (BrowseComp 83.2%), multilingual coding (SWE-bench Multilingual 76.7%), and conversational agents (τ²-Bench 93.9%) while being the only open-weight model in this tier. Qwen 3.6 Plus is the most practical for long-context workflows with its 1M token window, though it trails on most head-to-head benchmarks.
4. Pricing and Real Per-Task Cost Math
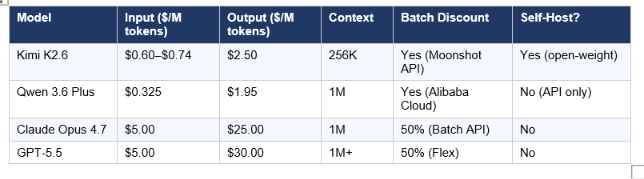
Per-token pricing is the wrong comparison metric. Per-task cost is what actually matters in production. Here is the full pricing table and the math on three realistic workloads.
API Pricing
Real Per-Task Cost Comparison
Three representative workloads, estimated based on published benchmark run data and community testing:
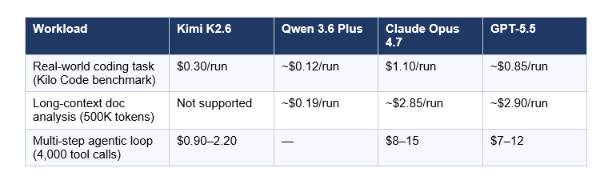
The cost math on coding: Kimi K2.6 runs a typical coding task at 3.6× cheaper than Claude Opus 4.7 ($0.30 vs $1.10 per run). But Kilo Code's real-world workflow benchmark scored Claude Opus 4.7 at 91/100 and Kimi K2.6 at 68/100 — a 23-point gap concentrated in edge-case handling, lease management, and live event streaming. Kimi K2.6 delivers approximately 75% of Claude's quality at 19% of the cost. Whether that ratio is acceptable depends entirely on your error tolerance.
The cost math on long context: Qwen 3.6 Plus wins outright for 500K+ token workflows due to its 1M context window and $0.325/M input pricing. Neither Kimi K2.6 nor a comparable open-weight model supports this scale natively.
The GPT-5.5 efficiency claim: GPT-5.5 generates approximately 40% fewer output tokens per Codex task than GPT-5.4. At the doubled per-token price, a task that cost $1.50 on GPT-5.4 costs approximately $1.80 on GPT-5.5 — a 20% increase, not 100%. For teams already on Codex, this is the migration math.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Architecture Deep-Dive: Why Kimi and Qwen Can Be This Cheap
The pricing gap between open-weight and closed models is not a temporary market inefficiency. It is architectural. Understanding why helps you predict where the gap holds and where it narrows.
Mixture-of-Experts: The Math Behind Kimi K2.6's Pricing
Kimi K2.6 uses a 1-trillion-parameter MoE architecture — 384 experts per layer, 8 routed plus 1 shared per token, with Multi-head Latent Attention to compress KV cache. At inference, only 32 billion parameters activate per token. You pay for 32B compute while the model routes through 1T of learned capacity. That is the entire pricing argument in one sentence: inference cost stays at the 32B level while model capacity is 1T.
The Agent Swarm capability is built on top of this. Scaling to 300 sub-agents executing 4,000 coordinated steps is possible because each sub-agent runs at 32B inference cost. For the practical implementation of building on this architecture, the Kimi K2.6 vs GPT-5.4 vs Claude Opus benchmark comparison covers how Claw Groups extend this to hybrid human-agent swarms.
Qwen 3.6 Plus: Hybrid Attention for 1M Context
Qwen 3.6 Plus uses a hybrid architecture combining efficient linear attention with sparse MoE routing. The key innovation is Thinking Preservation — retaining reasoning traces across conversation turns rather than recomputing from scratch. In a multi-step agent loop, this reduces redundant computation significantly. The always-on chain-of-thought is a deliberate design choice: Alibaba is betting that consistent, auditable reasoning produces more reliable agentic outputs than a model that toggles reasoning on demand.
Why Claude and GPT Still Lead on Hard Problems
The frontier models' quality advantage on hard tasks is real and not purely architectural. It comes from substantially more post-training compute on safety, instruction following, and edge-case reliability — areas where open-weight models with less post-training data show consistent gaps. Claude Opus 4.7's output self-verification (the model proactively writes tests and sanity-checks before declaring a task complete) is a post-training behavior, not an architecture feature. It is also why the Kilo Code benchmark gap clusters in edge cases rather than common patterns.
6. Where Each Model Wins: Honest Use-Case Breakdown
Kimi K2.6 Wins At
- High-volume parallel coding tasks where you run many sub-agent instances simultaneously. At $0.30/run, the economics of Agent Swarm architectures become viable where Claude-tier pricing would be prohibitive.
- Frontend generation and visual coding. Kimi K2.6's coding-driven design capabilities — generating production-ready UI from simple prompts or screenshots — are a noted strength. The model supports native video input as well as image.
- Multi-language software engineering. The 76.7% SWE-bench Multilingual score is the strongest published result in this category — Moonshot explicitly trained on Rust, Go, Python, and niche languages like Zig.
- Budget-constrained agentic pipelines where 75–80% of Claude-quality is acceptable and cost is the binding constraint.
Qwen 3.6 Plus Wins At
- Long-context workflows requiring 500K–1M tokens in a single prompt. No other model in this comparison natively supports this. See our Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5 coding comparison for workflow-specific results.
- Tool-calling reliability at scale. Qwen 3.6 Plus led every model on MCPMark in independent testing — making it the strongest open-model choice for MCP-heavy agentic pipelines.
- Cost-sensitive exploration and prototyping. During the free preview period, Qwen 3.6 Plus costs nothing. Even at paid pricing ($0.325/M input), it is the cheapest model in this comparison by a meaningful margin.
- Multilingual and Asian-language tasks. Alibaba's training data advantage on Asian-language content is consistent across the Qwen series.
Claude Opus 4.7 Wins At
- The hardest software engineering tasks where edge-case correctness is non-negotiable. The SWE-bench Pro score (64.3%) and Kilo Code real-world benchmark (91/100) reflect a model that handles lease expiry, concurrency, and live event streaming better than any alternative in this comparison.
- High-resolution vision workflows. At 3.75 megapixels (3x the resolution of Opus 4.6), Opus 4.7 is the right model for dense screenshot reading, diagram extraction, and UI analysis. Visual acuity jumped from 54.5% to 98.5% in early-access testing. See the Claude Opus 4.7 full review for the full vision benchmark breakdown.
- Financial agent and enterprise knowledge work. The 64.4% Finance Agent score (state-of-the-art at launch) reflects the model's strength on multi-step financial analysis, planning, and coherent professional output.
- Production workflows where output self-verification reduces error rates on long-running tasks. Anthropic explicitly designed Opus 4.7 to write its own tests and sanity-check outputs before reporting back.
GPT-5.5 Wins At
- Terminal-native, multi-step agentic execution. The 82.7% Terminal-Bench 2.0 score is the highest of any model in this comparison and reflects OpenAI's deep investment in Codex-style autonomous coding infrastructure.
- Teams already on the OpenAI ecosystem. MCP servers configured for OpenAI work without modification, and the Codex CLI integrations (VS Code, JetBrains, GitHub Copilot) are more mature than comparable tooling for other models.
- Token efficiency over GPT-5.4. If you are already running GPT-5.4 in Codex and paying per token, GPT-5.5's 40% output token reduction brings real per-task cost down even at the doubled rate card.
- Computer use tasks. GPT-5.5 leads on OSWorld-Verified, making it the strongest choice for browser automation and GUI-level AI agents.
7. The Routing Framework: Which Model for Which Job
My honest recommendation for 2026: stop optimizing for a single model. Optimize for a routing strategy. The cost gap between tiers is now so large that paying for Claude Opus 4.7 on every task is the equivalent of renting a data center for every spreadsheet calculation.
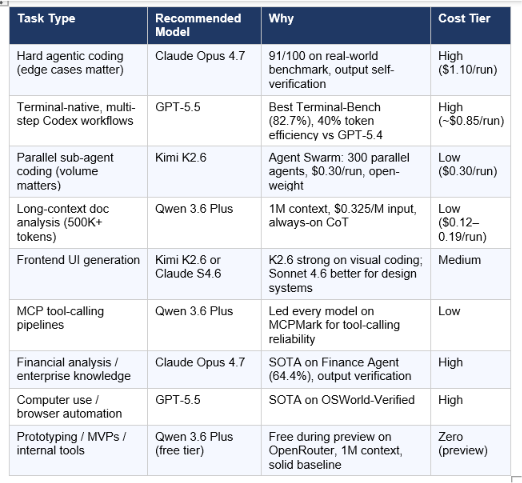
The practical setup most experienced developers are landing on in 2026: route 60–70% of traffic through the cheapest capable model (Kimi K2.6 or Qwen 3.6 Plus), reserve Claude Opus 4.7 for tasks where the quality delta is provably worth the cost, and use GPT-5.5 on Codex for terminal-native workflows where OpenAI's toolchain integration matters. For a broader view of how this routing strategy fits across the full model landscape, see our Best AI Models: April + May 2026 Leaderboard.
8. Limitations Nobody Talks About
Every model in this comparison has been covered with extensive positive coverage. Here are the honest downsides that matter for production decisions.
Kimi K2.6 Limitations
- 256K context ceiling. For workflows requiring 500K+ token contexts — entire codebases, large document collections — Kimi K2.6 cannot compete with Qwen 3.6 Plus or Claude Opus 4.7's 1M token support. This is a hard architectural ceiling, not a configurable parameter.
- The 12-hour autonomous run claims are vendor-reported and not independently verified at the time of this writing. Community testing confirms solid multi-hour execution, but the edge cases of 12-hour runs in production remain underexplored.
- Moonshot AI was accused by Anthropic in February 2026 of using Claude conversation data for training distillation. This dispute remains unresolved. For enterprises in regulated industries, this is a compliance risk worth flagging.
- High-token thinking mode tasks can generate significantly more output tokens than comparable models, partially eroding the cost advantage on reasoning-heavy jobs.
Qwen 3.6 Plus Limitations
- Preview-period data collection. The free tier on OpenRouter explicitly collects prompt and completion data for model improvement. Do not route sensitive production data through the free preview endpoint.
- No production SLA during preview. For mission-critical workflows, Qwen 3.6 Plus on the free preview tier is a development tool, not a production backend.
- Always-on chain-of-thought adds latency overhead on simple tasks. For interactive, low-complexity queries, this is a consistent friction point that users of the Qwen 3.5 series also experienced.
Claude Opus 4.7 Limitations
- The new tokenizer can produce up to 35% more tokens for the same input text compared to Opus 4.6. The rate card is unchanged, but your real bill per request can increase even if the listed price did not. Replay representative traffic before migrating.
- Strict instruction following is a deliberate new behavior, but prompts written for earlier models that relied on loose interpretation may break. Anthropic explicitly flags this as a migration concern.
- At $5/$25 per million input/output tokens, Opus 4.7 is the most expensive production option for volume coding workflows. The quality advantage is real, but the cost delta demands hard justification against Kimi K2.6 for high-volume use cases.
GPT-5.5 Limitations
- API pricing doubled from GPT-5.4 ($2.50/$15 to $5/$30 per million tokens). The 40% token efficiency improvement offsets this for many Codex workloads, but for non-Codex API use, the effective cost increase is closer to 60–70%.
- Knowledge cutoff is December 2025 — the earliest of any model in this comparison. For tasks requiring current events or real-time information, this matters.
- The API was not live at ChatGPT launch. OpenAI released it "coming very soon." Teams building on the API rather than Codex CLI faced a gap between the public hype and actual availability.
Frequently Asked Questions
Is Kimi K2.6 better than Claude Opus 4.7?
On most benchmarks, Claude Opus 4.7 leads — 87.6% vs approximately 87% on SWE-bench Verified (vendor-reported for K2.6), 94.2% vs 90.5% on GPQA Diamond, and 91/100 vs 68/100 on a real-world Kilo Code workflow test. Kimi K2.6 leads on BrowseComp (83.2%), SWE-bench Multilingual (76.7%), and conversational agent benchmarks (τ²-Bench 93.9%), and is approximately 8× cheaper on input tokens. For most developers, the honest answer is: Claude Opus 4.7 is better at hard, edge-case-sensitive work; Kimi K2.6 is better when you need to run many parallel coding tasks at minimal cost.
Is Qwen 3.6 Plus really free?
During the preview period on OpenRouter, yes — Qwen 3.6 Plus Preview has been available at $0/token. This preview period comes with a meaningful caveat: Alibaba collects prompt and completion data during this window for model training. The paid production version is priced at $0.325/M input and $1.95/M output tokens via Alibaba Cloud. The preview free tier is the right environment for development, prototyping, and evaluation. Do not route sensitive production data through it.
What is the real per-task cost difference between Kimi K2.6 and Claude Opus 4.7?
For a typical real-world coding task on the Kilo Code benchmark, Kimi K2.6 costs approximately $0.30 per run and Claude Opus 4.7 costs approximately $1.10 — a 3.6× cost difference. The quality gap on that same benchmark is 23 points (68 vs 91 out of 100). At roughly $0.80 per run saved, you are trading that quality delta against cost. For high-volume pipelines running thousands of tasks per day, this delta is the difference between a $900/day and a $3,300/day infrastructure budget at scale.
Can Kimi K2.6 replace Claude Opus 4.7 in production?
For well-defined, repeatable coding tasks without complex edge-case requirements — yes, for many teams. For tasks requiring output self-verification, precision on complex orchestration (lease handling, concurrency, live event streaming), or the highest-resolution vision inputs, no. The honest routing answer: pilot Kimi K2.6 on your lowest-stakes production workload, measure quality and error rates against your own tasks, and expand from there. A blanket swap without task-specific evaluation is the wrong move in either direction.
How does GPT-5.5 compare to Claude Opus 4.7 for coding?
GPT-5.5 edges ahead on raw benchmark scores: 88.7% vs 87.6% on SWE-bench Verified, and 82.7% vs 69.4% on Terminal-Bench 2.0 — a meaningful gap on terminal-native agentic work. Claude Opus 4.7 leads on MCP-Atlas (structured tool orchestration) and Finance Agent (64.4% vs GPT-5.5's unreported score). In practical terms, GPT-5.5 is better for Codex CLI workflows; Claude Opus 4.7 is better for enterprise knowledge work and vision-heavy tasks. At identical list pricing ($5/M input), the deciding factor for most teams is ecosystem fit, not raw benchmark score.
Is Kimi K2.6 truly open source?
Kimi K2.6 is open-weight under a Modified MIT License. The weights are publicly available on Hugging Face and you can self-host below a threshold of 100 million monthly active users or $20 million in monthly revenue. Above those thresholds, you must display "Kimi K2" prominently in your product UI. For the vast majority of developers and startups, this functions as standard MIT — full commercial use, modification, and redistribution rights. The training data and training code are not publicly released, which is the technical distinction between open-weight and fully open source.
Which model should I use for a $5/month VPS AI agent setup?
Kimi K2.6 via the Moonshot API or OpenRouter is the strongest choice for constrained-budget agentic setups. At $0.30–0.60 per million input tokens, you get a Tier A coding model with Agent Swarm capabilities, 20 messaging platform integrations via tools like Hermes Agent, and full self-hosting rights if you have the GPU infrastructure. Qwen 3.6 Plus is the alternative if your workflow needs 1M token context and you can tolerate the preview data collection terms.
When does the open-source quality gap still matter?
The gap is most visible in three scenarios: (1) complex orchestration with edge cases — lease handling, concurrency bugs, live streaming correctness — where Claude Opus 4.7's output self-verification makes a measurable difference; (2) highest-resolution vision tasks where Opus 4.7's 3.75MP support has no open-weight equivalent; and (3) long-running autonomous workflows in regulated industries where Claude and GPT's safety fine-tuning and content policy reliability are material compliance requirements. Outside these three scenarios, the open-source quality gap has narrowed to a point where task-specific testing, not general assumptions, should drive the decision.
Recommended Blogs
- Kimi K2.6: Open-Source Just Beat GPT-5.5 at Coding
- Claude Opus 4.7: Full Review, Benchmarks & Features (2026)
- Qwen 3.6 Plus Preview: 1M Context, Speed & Benchmarks 2026
- GPT-5.5 Review: Benchmarks, Pricing & vs Claude (2026)
- Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5: Best Chinese AI for Coding 2026
- Best AI Models: April + May 2026 Leaderboard
- Kimi K2.6 vs GPT-5.4 vs Claude Opus: Who Wins? (2026)
References
- Moonshot AI — Kimi K2.6 Official Tech Blog
- Hugging Face — moonshotai/Kimi-K2.6 Model Card
- Anthropic — Introducing Claude Opus 4.7
- Anthropic — Claude Opus 4.7 API Documentation (What's New)
- Qwen Team — Qwen3.6-Plus: Towards Real World Agents (Official Blog)
- OpenRouter — Qwen 3.6 Plus API Pricing & Benchmarks
- OpenRouter — GPT-5.5 API Pricing & Benchmarks
- Kilo AI — Claude Opus 4.7 vs Kimi K2.6: Workflow Orchestration Benchmark
- AkitaOnRails — LLM Coding Benchmark May 2026: DeepSeek V4, Kimi K2.6, GPT-5.5
- Artificial Analysis — Intelligence Index: Kimi K2.6, GPT-5.5, Claude Opus 4.7
- Latent Space — AINews: Moonshot Kimi K2.6 & Qwen3.6-Max-Preview

