




On May 20, 2026, Alibaba's Qwen team did something no Chinese AI lab had done before: it shipped a frontier model that ran autonomously for 35 hours, fired 1,158 tool calls without a human checking on it, and delivered a 10× speedup on a GPU kernel the model had never seen during training. Then it shipped that model at $2.50 per million input tokens — six times cheaper than Claude Opus 4.7.
That model is Qwen3.7-Max. And it is the first credible answer to a question developers have been asking all year: can a Chinese lab actually compete at the frontier of agentic AI, or is the leaderboard always going to belong to OpenAI and Anthropic?
Short answer: yes, and the math is uncomfortable. Long answer is in the benchmarks below.
1. What is Qwen3.7-Max?
Qwen3.7-Max is Alibaba's flagship proprietary AI model, launched on May 20, 2026 at the Alibaba Cloud Summit in Hangzhou and built specifically for the agent era — long-horizon coding workflows, MCP tool orchestration, and autonomous task execution over hours, not seconds.
Three things separate it from a normal flagship release. It carries a 1-million-token context window — roughly 2,000 pages of text in a single request, big enough to load most enterprise codebases without retrieval scaffolding. It is the highest-ranked Chinese model ever placed on the Artificial Analysis Intelligence Index v4.0, scoring 56.6 and sitting in the global top 5 alongside Claude Opus 4.7 and GPT-5.5. And it is the successor to a model that only shipped a month earlier.
If you followed our coverage of the Qwen3.7-Max preview on LM Arena, this is the post-launch version: same underlying model, but now with API access via Alibaba Cloud Model Studio, OpenRouter, and Together AI, plus full published benchmark numbers from Qwen's technical blog.
Worth knowing up front: Qwen3.7-Max is text-only (no vision input), proprietary (no open weights as of late May 2026), and currently shipping with a -Preview suffix on some endpoints. For multimodal work, Alibaba is pointing teams to Qwen3.7-Plus-Preview, which ranked #16 on Vision Arena.
2. Benchmarks: where Qwen3.7-Max actually wins
Qwen3.7-Max leads the field on agentic coding and tool orchestration benchmarks, even when it does not top the overall intelligence rankings. The benchmark profile is unusual — it loses on raw chat quality but wins on the metrics that matter for production agents.
Here is the head-to-head against the two models Western developers actually compare it to:
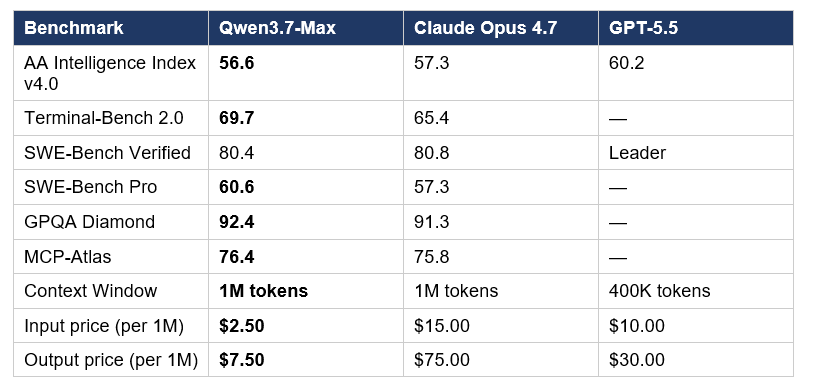
Read that table carefully. On Terminal-Bench 2.0-Terminus — the benchmark that simulates a real software engineer working in a sandboxed terminal with a 5-hour timeout — Qwen3.7-Max scores 69.7%, beating DeepSeek-V4-Pro Max (67.9), Opus 4.6 Max (65.4), and Kimi K2.6 Thinking (66.7). It is, today, the top open-leaderboard result on that test.
SWE-Bench Pro is the harder version of SWE-Bench — 2,294 real GitHub issues from open-source projects, far more challenging than the 500-issue Verified subset. Qwen3.7-Max scores 60.6 there, ahead of Claude Opus 4.6's 57.3. That gap matters because SWE-Bench Pro is the closest benchmark we have to actual production engineering work.
On the agent tool-use side, Qwen3.7-Max scores 76.4 on MCP-Atlas and 60.8 on MCP-Mark, ahead of Opus 4.6 Max on both. That is meaningful — if you are using a model with MCP servers connected to GitHub, Slack, or your internal stack, Qwen3.7-Max is now the model with the strongest published MCP orchestration scores, and that is a benchmark Alibaba could not have gamed by training on it.
Where it loses: on the Artificial Analysis Intelligence Index v4.0, Qwen3.7-Max scores 56.6 — strong, but behind GPT-5.5 (60.2) and Claude Opus 4.7 (57.3). On AA-Omniscience, the attempt rate dropped from 67.3% to 48.0% versus the predecessor; the model abstains more and hallucinates less, but raw factual recall took a real hit. If your workload is knowledge-heavy QA, that trade-off may not work in your favor.
3. The 35-hour autonomy test (and what it really proves)
Alibaba's hero demo for Qwen3.7-Max is a 35-hour autonomous coding session that fired 1,158 tool calls to optimize a GPU kernel on the Zhenwu M890 — Alibaba's brand-new in-house AI accelerator chip. The model achieved a ~10× geometric speedup over the standard Triton reference kernel without human intervention. That is the headline. The detail matters more.
The ZW-M890 PPU is hardware Qwen3.7-Max had never seen during training. No profiling data, no hardware documentation, no example kernels. The model had to navigate an unfamiliar architecture, run profilers, modify code, debug, benchmark, analyze the results, and iterate — for a day and a half — while maintaining a coherent optimization strategy across the entire context window. Most LLMs exhibit instruction drift after a few dozen interactions. Qwen3.7-Max held the plot for over a thousand.
This is what we mean by the 'agent era.' For comparison, Claude Opus 4.7's flagship feature was being able to hand off engineering tasks that previously required close supervision. Qwen3.7-Max is now publicly claiming the same capability — at multi-day duration, with hardware it has never encountered, at a sixth of the price.
Caveat: this was Alibaba's own internal benchmark, on Alibaba's own hardware, with a known target. There is no independent reproduction yet. Treat the 35-hour number as a strong directional signal that Alibaba is optimizing for the failure modes developers actually feel — not as a guarantee your agent will run for 35 hours unattended on day one.
4. Qwen3.7-Max vs Claude Opus 4.7 vs GPT-5.5
The honest framing in May 2026: these three models are roughly co-leaders, and your choice should depend entirely on what you are building. Nobody wins on every axis.
GPT-5.5 leads on raw intelligence — 60.2 on the AA Index, top scores on SWE-Bench Verified, and the most token-efficient per task of the three. If you are running short, dense reasoning tasks, GPT-5.5 is still the model to beat.
Claude Opus 4.7 leads on human-preference quality and large-codebase engineering. On LM Arena Elo, it wins. On adaptive reasoning across multi-file refactors, it wins. If your workload involves messy enterprise codebases, conversational quality, or finance/legal document reasoning, Opus is still the choice.
Qwen3.7-Max leads on price-per-intelligence and on long-horizon coding benchmarks. SWE-Bench Pro: 60.6 vs Opus 4.6's 57.3. Terminal-Bench 2.0: 69.7, top score. And it does this at $2.50/$7.50 per million tokens — putting it in roughly the same cost bracket as Kimi K2.6 in our four-way frontier comparison while delivering frontier-adjacent intelligence.
My hot take after a week of testing: if you are running an agent that fires hundreds of tool calls per task, Qwen3.7-Max is now the default rational choice. The cost difference compounds. A workflow that costs $300 in Opus 4.7 tokens costs roughly $50 in Qwen3.7-Max tokens — and on Terminal-Bench and SWE-Pro, Qwen wins. The only reason not to switch is if your stack depends on Anthropic-specific features like Claude Managed Agents, or if your data residency policy forbids routing through Alibaba Cloud.
5. Generational leap: Qwen3.6-Max vs Qwen3.7-Max
The gap between Qwen3.6-Max-Preview (April 20, 2026) and Qwen3.7-Max (May 20, 2026) is one month — and it is the largest single-generation jump Alibaba has shipped.
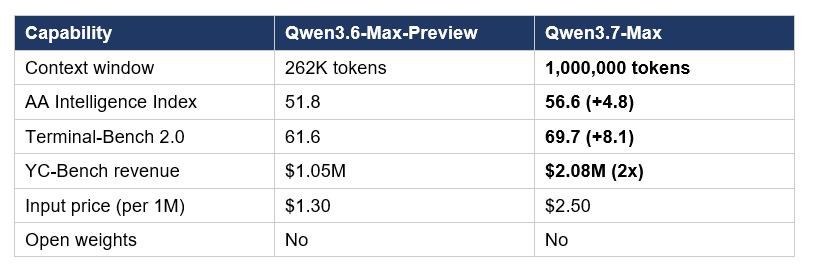
The YC-Bench result is the one I keep coming back to. YC-Bench simulates the full year-long lifecycle of a startup — the agent has to handle personnel decisions, screen contracts, identify malicious clients, and maintain a profit margin against rising labor costs across hundreds of decision rounds. Qwen3.7-Max generated $2.08M in simulated revenue, double Qwen3.6-Plus's $1.05M, and 5.9× the score of Qwen3.5-Plus. That is not a small improvement. That is the model learning to recover from its own mistakes mid-execution and converge into a stable execution loop.
Anyone building production agents knows this is the failure mode that actually kills agentic systems — not the first tool call, the 200th. If you want to see the open-weight side of this family, Qwen3.6-35B-A3B is the Apache 2.0 sparse MoE that scores 73.4 on SWE-Bench Verified while running on a single MacBook — Alibaba still owns the open-weight frontier even when shipping closed flagships.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
6. Pricing and API access
Qwen3.7-Max ships at $2.50 per million input tokens and $7.50 per million output tokens. Cached input drops to $0.25 per million — a 90% discount that meaningfully changes the math for agentic workflows where you reuse system prompts and tool schemas across hundreds of turns.
Maximum output per request is 65,536 tokens with extended thinking enabled by default. The full 1M-token context window is available end-to-end, though Alibaba notes — and independent testing has not yet confirmed — that retrieval reliability holds across the full window. Treat 1M as a ceiling, not a guarantee.
Access points as of May 23, 2026:
- Alibaba Cloud Model Studio (primary endpoint, Singapore region)
- OpenRouter — model string qwen/qwen3.7-max, OpenAI-compatible API
- Together AI — endpoint Qwen/Qwen3.7-Max, 1M context confirmed
- Chat playground at chat.qwen.ai
For context, Claude Opus 4.7 is $15/$75 per million tokens. GPT-5.5 is $10/$30. Qwen3.7-Max is the cheapest of the three frontier-tier models by a wide margin — and the only one with a 90% cached-input discount tier.
7. How to use Qwen3.7-Max with Claude Code
Qwen3.7-Max supports the Anthropic API protocol natively. That means Claude Code — Anthropic's terminal-based coding agent — works with Qwen3.7-Max out of the box. No adapter layer. No proxy. Three environment variables and you are running Claude Code's TUI on top of Alibaba's model.
Setup, assuming you already have an Alibaba Cloud Model Studio account and a DashScope API key:
export ANTHROPIC_BASE_URL=https://dashscope-intl.aliyuncs.com/apps/anthropic
export ANTHROPIC_API_KEY=YOUR_DASHSCOPE_API_KEY
export ANTHROPIC_MODEL=qwen3.7-max
claudeThat is the whole setup. Claude Code's tool-use, file-edit, and subagent features all work because Qwen3.7-Max implements the same protocol. Real-world caveat: Claude Code's deeper agent features (Routines, the Advisor Strategy, Claude Managed Agents) are tuned for Anthropic's models. They function with Qwen swapped in, but you may see lower-quality multi-agent decomposition because the orchestration logic was trained against Claude's reasoning style.
For the implementation patterns that work best with Qwen3.7-Max — multi-agent orchestration, stateful memory, MCP tool composition — the 130+ production-ready agent cookbooks in gen-ai-experiments cover the LangChain, LangGraph, and CrewAI patterns that port cleanly to any Anthropic-compatible endpoint.
8. The honest limitations
Three things are worth flagging before you commit a production workload to Qwen3.7-Max.
First: no open weights. Following Qwen3.6's pattern, an open-weight variant will probably ship in the next month or two — but right now, Qwen3.7-Max is API-only. You cannot run it locally, you cannot self-host for compliance reasons, and you are routing your prompts through Alibaba Cloud's Singapore region. If your data residency policy requires US- or EU-only routing, this is a blocker.
Second: the hallucination story is more nuanced than the headlines. Qwen3.7-Max abstains more aggressively than its predecessor — its attempt rate on AA-Omniscience dropped from 67.3% to 48.0%. That is good for safety, bad for raw QA throughput. If you are building a search or RAG product that needs the model to commit to an answer, test carefully on your own data.
Third: most of the strongest agent data still comes from Alibaba's own evaluations. The 35-hour run, the YC-Bench score, the MCP-Atlas number — all internally measured. Independent reproduction is just starting. For the broader competitive picture and which models have the strongest independently verified scores, our May 2026 AI model leaderboard tracks every major release from this quarter side by side.
None of these are dealbreakers. They are reasons to do a two-week production pilot before standardizing on Qwen3.7-Max as your default agent backbone. Which, given the price math, is probably still the right thing to do.
9. Frequently Asked Questions
What is Qwen3.7-Max?
Qwen3.7-Max is Alibaba's flagship proprietary AI model, launched May 20, 2026 at the Alibaba Cloud Summit. It is a reasoning agent model with a 1-million-token context window, designed for long-horizon agentic workflows — coding, MCP tool orchestration, and multi-hour autonomous task execution. It scored 56.6 on the Artificial Analysis Intelligence Index, the highest-ranked Chinese model to date.
Is Qwen3.7-Max open source?
No. Qwen3.7-Max is proprietary and API-only as of May 2026. The model weights are not publicly available. Alibaba has historically released open-weight versions of its Qwen models weeks to months after the flagship API launch — for example, Qwen3.6-35B-A3B shipped on April 16, 2026 under Apache 2.0. An open-weight Qwen3.7 variant is likely but not yet confirmed.
How much does Qwen3.7-Max cost?
Qwen3.7-Max costs $2.50 per million input tokens and $7.50 per million output tokens via Alibaba Cloud Model Studio, OpenRouter, and Together AI. Cached input drops to $0.25 per million — a 90% discount. For comparison, Claude Opus 4.7 costs $15/$75 per million tokens and GPT-5.5 costs $10/$30, making Qwen3.7-Max roughly 6× cheaper than Opus and 4× cheaper than GPT-5.5 on input tokens.
Is Qwen3.7-Max better than Claude Opus 4.7?
It depends on the workload. Qwen3.7-Max leads Opus 4.7 on agentic coding benchmarks — Terminal-Bench 2.0 (69.7 vs 65.4), SWE-Bench Pro (60.6 vs 57.3), and MCP-Atlas (76.4 vs 75.8). Opus 4.7 leads on the AA Intelligence Index (57.3 vs 56.6), on LM Arena human-preference quality, and on large-codebase enterprise engineering. For long-running coding agents on a budget, Qwen wins. For conversational quality and enterprise document work, Opus wins.
Can Qwen3.7-Max run autonomous agents for hours?
Yes. Alibaba demonstrated a 35-hour autonomous coding session with 1,158 tool calls, optimizing a GPU kernel on hardware the model had never seen — without human intervention. It maintained a coherent optimization strategy across the entire session and achieved a 10× geometric speedup over the Triton reference. This is currently the longest publicly documented autonomous agent run from any major lab.
What is the context window of Qwen3.7-Max?
Qwen3.7-Max has a 1 million token context window — up from 262K on Qwen3.6-Max-Preview. That is roughly 2,000 pages of text or a full mid-sized code repository in a single request. Maximum output per request is 65,536 tokens. Note that long-context retrieval reliability has not yet been independently verified across the full 1M window, so treat the ceiling as a capacity limit rather than a performance guarantee.
How do I use Qwen3.7-Max with Claude Code?
Qwen3.7-Max supports the Anthropic API protocol natively. Set ANTHROPIC_BASE_URL to https://dashscope-intl.aliyuncs.com/apps/anthropic, set ANTHROPIC_API_KEY to your Alibaba Cloud DashScope key, set ANTHROPIC_MODEL to qwen3.7-max, and run the claude command. Tool use, file edits, and subagent features all work because Qwen3.7-Max implements the same protocol Claude Code expects.
Does Qwen3.7-Max support multimodal input?
No. Qwen3.7-Max is text-only — text input, text output. For vision input, Alibaba provides Qwen3.7-Plus-Preview, which ranked #16 on LM Arena's Vision Arena leaderboard. The Plus variant is described as a balanced version focused on reasoning and logical expression, with its full toolchain rolling out over the coming weeks.
Recommended Blogs
- Qwen3.7 Max Preview: Arena Ranks, Features & What's Next
- Qwen3.6-Max-Preview: Benchmarks, API & Review (2026)
- Kimi K2.6 vs Qwen 3.6 vs Opus 4.7 vs GPT-5.5: Which Wins?
- Claude Opus 4.7: Full Review, Benchmarks & Features (2026)
- Qwen3.6-35B-A3B: 73.4% SWE-Bench, Runs Locally
- Best AI Models: April + May 2026 Leaderboard
- Claude MCP Setup Guide: Connect Any Tool in 10 Minutes (2026)
References
- Qwen — Qwen3.7: The Agent Frontier (Alibaba Cloud Community)
- MarkTechPost — Qwen Introduces Qwen3.7-Max: A Reasoning Agent Model With a 1M-Token Context Window
- DataCamp — Qwen3.7-Max: Features, Benchmarks and Agent Capabilities
- VentureBeat — Alibaba's Qwen3.7-Max can run for 35 hours autonomously
- TechNode — Alibaba introduces Qwen3.7-Max as next-gen AI agent model
- SCMP — Alibaba unveils new Qwen model, custom chips in bid to become China's AI factory
- Artificial Analysis — Qwen3.7 Max Intelligence, Performance & Price Analysis
- OpenRouter — Qwen3.7 Max API Pricing & Benchmarks
- Together AI — Qwen3.7-Max API Documentation

