





Claude Opus 4.8 Review: Benchmarks, Dynamic Workflows, and Honest Trade-offs (May 2026)
Anthropic released Claude Opus 4.8 on May 28, 2026 — just 41 days after Opus 4.7, the fastest version cadence Anthropic has ever run. Same price. 88.6% on SWE-Bench Verified. 69.2% on SWE-Bench Pro (a 4.9-point jump in six weeks). 74.6% on Terminal-Bench 2.1. A 27-point leap on USAMO 2026 math from 69.3% to 96.7%. And a new orchestration system called Dynamic Workflows that lets Claude Code spawn up to 1,000 parallel subagents to run repository-scale migrations in the background.
Pricing held flat at $5 per million input tokens and $25 per million output tokens. Fast Mode dropped from $30/$150 to $10/$50 — three times cheaper than Fast Mode on Opus 4.7, while running at roughly 2.5× the speed of standard Opus inference. Anthropic also confirmed Mythos-class models — the restricted Project Glasswing model that found 23,019 vulnerabilities in its first month — will be generally available 'in the coming weeks.'
This is the detailed review. Real benchmark deltas against Opus 4.7. Honest comparison with GPT-5.5, Gemini 3.1 Pro, and Qwen3.7-Max. The Dynamic Workflows feature explained with the Bun port case study where Jarred Sumner used it to migrate roughly 750,000 lines of Rust in 11 days. Effort control, Messages API changes, Fast Mode pricing math, and the honest answer on whether you should upgrade today or wait.
1. What is Claude Opus 4.8?
Claude Opus 4.8 is Anthropic's newest flagship public model, released on May 28, 2026. The API model ID is claude-opus-4-8. It is a direct upgrade to Opus 4.7 — same 1M-token context window, same multimodal input stack (text + vision in, text out), same standard pricing — with measurable gains on coding benchmarks, long-context retrieval, mathematical reasoning, and Anthropic's own honesty and alignment evaluations.
The release reflects an unusual delivery pattern from Anthropic. The 41-day gap between Opus 4.7 and 4.8 is the shortest the Opus line has ever run. By comparison, Sonnet 4.6 is now three months old, Haiku 4.5 is seven months old, and the historical Opus cadence was closer to two months. The compression here is partly competitive pressure — OpenAI's Codex CLI and Google's Gemini 3.5 Flash have both shipped major updates in the same window — and partly the result of what some early testers called a chilly reception to Opus 4.7.
For full context on the predecessor model, our Claude Opus 4.7 review covers the benchmark profile, deliberate cybersecurity capability cap, and the broader release strategy that explains why Anthropic ships two tiers: the public Opus model that customers can buy, and the restricted Mythos model that only 50 partner organizations can access through Project Glasswing.
2. Opus 4.8 release date, pricing, and availability
The release facts, in plain terms:
- Released: May 28, 2026 (Thursday)
- API model ID: claude-opus-4-8
- Standard pricing: $5 / $25 per million input / output tokens (unchanged from Opus 4.7)
- Fast Mode pricing: $10 / $50 per million tokens at ~2.5× speed (3x cheaper than Opus 4.7's $30/$150 Fast Mode)
- Context window: 1M tokens (200K on Microsoft Foundry at launch)
- Available on: claude.ai, Claude Code v2.1.154+, Cowork, Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry, and Cursor
The drop-in compatibility story matters for any team already running Opus 4.7. The Messages API contract is identical except for the model string — change claude-opus-4-7 to claude-opus-4-8 in your config and you are running the new model. No new auth flow, no breaking changes to tool use or thinking budgets, no new SDK version required.
Two things did change at the API level. The Messages API now accepts system entries inside the messages array itself, not just at the top-level system parameter. That means you can update Claude's instructions mid-conversation without breaking the prompt cache — useful for long agentic runs where steering happens mid-flight. Second, the effort enum (low/medium/high/xhigh/max) is now exposed on claude.ai and Cowork, not just in Claude Code. We'll come back to that in section 7.
3. Benchmarks — every meaningful number, with context
Anthropic's own framing of Opus 4.8 is 'a modest but tangible improvement on its predecessor.' That phrasing is doing a lot of work. The improvements on standard coding benchmarks are incremental. The improvements on the harder benchmarks — and on the failure modes that matter for long agent runs — are not.
Coding benchmarks (incremental but real)
SWE-Bench Verified moves from 87.6% to 88.6% — a 1-point gain on a benchmark where everyone above 85% is in the noise. SWE-Bench Pro, the harder version with 2,294 real GitHub issues from open-source projects, jumps from 64.3% to 69.2% — a 4.9-point gain in 41 days that matters because Pro is the closest proxy we have for production engineering work. Terminal-Bench 2.1 jumps from 66.1% to 74.6% — an 8.5-point gain on the sandboxed-terminal benchmark, which is the proxy for agent-style coding.
Long-context and math (large jumps)
USAMO 2026 (USA Math Olympiad) moves from 69.3% to 96.7% — a 27-point jump. GraphWalks F1 at 1M tokens moves from 40.3% to 68.1% — a 27.8-point jump on long-context retrieval. These are the kind of single-cycle gains the field has not seen since the original Opus 4 to 4.5 transition. Anthropic does not say what changed architecturally, but the pattern (large gains on hard reasoning, modest gains on already-saturated benchmarks) suggests a meaningful training data and curriculum overhaul rather than just a parameter scale-up.
Honesty and alignment
This is the metric Anthropic put front and center in the launch post. The company reports Opus 4.8 is roughly four times less likely than Opus 4.7 to let defects in its own code pass unmentioned. In plain English: when Opus 4.8 writes buggy code, it is much more likely to flag the uncertainty than to confidently ship the bug. The figure is self-reported, produced by Anthropic's own Alignment team, with the underlying protocol not yet published — read it as a directional signal, not a verified benchmark.
CursorBench
Cursor's CEO confirmed Opus 4.8 'exceeds prior Opus models across every effort level' on CursorBench — Cursor's internal coding benchmark. This matters because Cursor sees real production code from millions of developers daily, and their evaluation reflects production reliability rather than benchmark-curated test cases. For IDE-bound teams, this is the closest you'll get to an independent endorsement of the upgrade.
Legal Agent Benchmark
Less talked about in launch coverage: Opus 4.8 set a record on Anthropic's Legal Agent Benchmark and became the first model to break 10% overall on the all-pass standard. For knowledge workflows beyond coding — legal research, contract analysis, document review — this is the more meaningful signal. Customers in regulated industries who previously routed Opus calls through human review may now be in a position to lift more of that workload.
4. Opus 4.7 vs 4.8 — what changed in 41 days
Here is the consolidated delta table for the model itself (companion launches like Dynamic Workflows are covered in section 6):
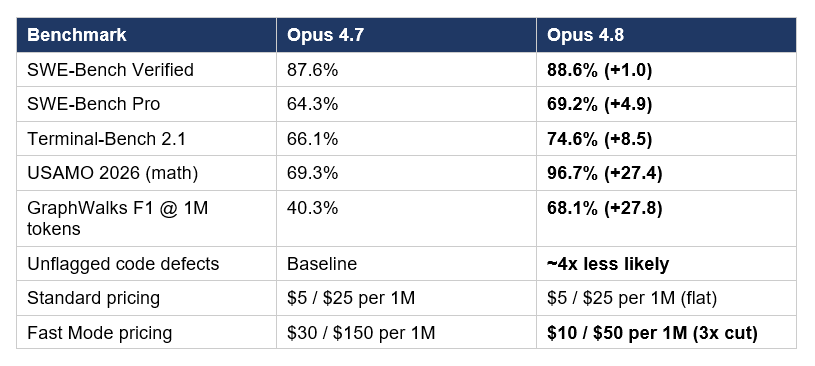
Read that table carefully. The benchmark gains in 41 days are real, but the Fast Mode pricing change is arguably the bigger commercial story. Dropping the 2.5×-speed tier from $30/$150 to $10/$50 means latency-sensitive workloads that previously routed to GPT-5.5 or Gemini 3.1 Pro for response time now have a viable Claude option at three times the previous price-per-speed ratio. For an interactive coding agent, an in-IDE assistant, or a customer-facing chat product where p95 latency matters, this changes the math entirely.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Opus 4.8 vs GPT-5.5 vs Gemini 3.1 Pro vs Qwen3.7-Max
The four-way head-to-head across May 2026's frontier models:
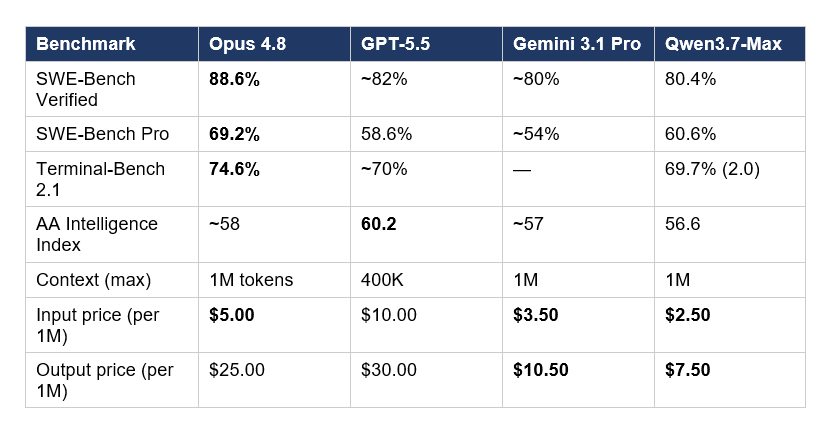
Read that table the same way developers actually pick models in practice. Opus 4.8 leads on every coding benchmark in the table — SWE-Bench Verified, SWE-Bench Pro, Terminal-Bench 2.1 — and is also the highest-priced of the four. GPT-5.5 still leads the AA Intelligence Index for raw reasoning. Qwen3.7-Max wins on cost-per-intelligence by a wide margin, and Gemini 3.1 Pro sits in a balanced middle position with strong reasoning, a 1M-token context, and the best long-context pricing of the four.
For the specific Qwen3.7-Max vs Claude Opus head-to-head, including Code Arena Elo and the cost-per-intelligence math, our Qwen3.7-Max vs Claude Code Arena comparison has the detailed breakdown. The framing from that piece carries over: Opus is the engineering depth winner, Qwen is the agent-cost winner.
My honest read: Opus 4.8 is the right pick for production engineering teams where reliability matters more than per-token cost. GPT-5.5 is the right pick for raw intelligence and structured reasoning. Gemini 3.1 Pro is the right pick for long-context analysis with moderate cost sensitivity. Qwen3.7-Max is the right pick for high-volume agent workloads where you're firing hundreds of tool calls per task and the cost difference compounds dramatically.
6. Dynamic Workflows — how 1,000 parallel agents actually work
Dynamic Workflows is the headline companion launch — and it is structurally different from previous Claude Code features in a way that matters.
Here is what it actually does. You mention 'workflow' in a prompt to Claude Code. Claude writes a JavaScript orchestration script that describes how the task should be decomposed and delegated. A runtime executes that script in the background, spawning up to 1,000 subagents that run tasks in parallel — each on its own portion of the work — and intermediate results live in JavaScript variables, not in Claude's context window. Subagents review and validate each other's work. The final coordinated output comes back to your session.
The critical detail is that intermediate results live in script variables. This is the difference between 'subagents' (the existing feature where Claude spawns helper instances inside its own context) and 'dynamic workflows' (orchestration where Claude builds a real script that executes outside its context window). For repository-scale work, this matters enormously: you are no longer bounded by the parent model's context for coordinating the parallel work. The plan moves into code; Claude's context holds only the final answer.
The Bun port case study
Anthropic highlighted one large example at launch. Jarred Sumner, creator of the Bun JavaScript runtime, used Dynamic Workflows to port approximately 750,000 lines of Rust code over an 11-day period. The migration involved a full test suite as the correctness bar, and the dynamic-workflow orchestration coordinated parallel subagents across thousands of files. This is the kind of codebase-scale work that previously required a multi-engineer team working for months.
Realistic caveats here matter. Sumner is a power user with deep familiarity in both the source and target codebases. He approved subagent outputs as they came back, and human oversight remained the correctness check at every checkpoint. The 750,000-lines-in-11-days framing is real but not turnkey — replicating that result requires substantial engineering scaffolding and a robust test suite.
Dynamic Workflows is available on Claude Code Team, Enterprise, and Max plans as a research preview. For builders who want to compose multi-agent patterns on top of any provider — Anthropic, OpenAI, or open-weight — the 130+ open-source agent cookbooks at Build Fast with AI cover the LangChain, LangGraph, and CrewAI patterns that compose into similar orchestration systems on top of the Anthropic API directly.
Cost reality check
A workflow that spawns up to 1,000 subagents can consume tokens at a startling rate. Each subagent runs against a meaningful chunk of Opus 4.8's context. Anthropic ships Dynamic Workflows as a research preview specifically because the cost math is unsettled and the pricing structure may change. A repository-scale migration that takes 11 days and 1,000 subagents will not be cheap. The reasonable framing is: this is the right tool for migrations that would otherwise cost a multi-engineer team months of work — not for routine refactors that fit inside a single Claude Code session.
7. Fast Mode and effort control — the cost-quality dial
Two companion launches that change how teams structure their Claude usage.
Fast Mode
Opus 4.8 introduces a Fast Mode that runs at roughly 2.5× the standard speed for double the per-token rate — $10/$50 per million tokens. The headline is not the 2× rate; it is that this is three times cheaper than Fast Mode on previous Opus models, which ran at $30/$150 per million tokens. Anthropic positions Fast Mode for latency-critical workloads — interactive coding agents, IDE assistants, customer-facing chat where p95 latency matters. Enable it in Claude Code with the /fast command; on the API, contact your account manager for access or join the waitlist.
Effort control
The effort control feature lets you dial how much thinking Claude does per response. Five levels: low (minimum thinking, fastest, cheapest), medium (balanced), high (Opus 4.8's default on claude.ai and Cowork — best balance of quality and latency), xhigh (extra thinking, exposed in Claude Code), and max (for hardest tasks and long-running workflows, most thinking, slowest, highest cost). The enum replaces hand-tuning thinking.budget_tokens for most use cases.
Practical use. Set effort=low for cheap chat-style help where speed matters more than depth. Use effort=high (the default) for everyday work. Reserve effort=xhigh for hard engineering tasks where you'd accept a meaningful token-cost increase for the quality improvement. Reserve effort=max for long-running autonomous tasks where you're going to be away from the keyboard while the model works — and you'd rather burn tokens than have to restart the run.
8. The Mythos question — what's coming next
Anthropic's most capable model is not Opus 4.8. It is Mythos — the restricted-access model that powers Project Glasswing's cybersecurity work and found 23,019 vulnerabilities across 1,000+ open-source projects in its first month. Mythos has remained behind the 50-partner wall since April 2026, deliberately restricted because Anthropic determined the cybersecurity capability was too dangerous to release broadly.
That position is now softening. In the Opus 4.8 launch post, Anthropic confirmed: 'We're making swift progress on developing these safeguards and expect to be able to bring Mythos-class models to all our customers in the coming weeks.' Combined with Axios's reporting that Mythos-class general availability is 'expected in the coming weeks,' the runway is now measurable in weeks rather than the open-ended 'late 2026 at earliest' framing that our Mythos release-date deep-dive flagged in March. This is the most aggressive public timeline Anthropic has given on Mythos to date.
What that means for Opus 4.8 specifically: it is the last flagship release in the pre-Mythos era. Once Mythos-class models are generally available — likely under a different model name like 'Claude Mythos 5' or similar — the Opus tier becomes the mid-range option in Anthropic's lineup, not the flagship. If you are making infrastructure decisions today, plan for that transition arriving within the next 4-8 weeks.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. How to use Opus 4.8 in Claude Code (setup guide)
If you are already on Claude Code, the upgrade is essentially zero-effort. Three steps:
Step 1: Update Claude Code to v2.1.154 or later
# Check your current version
claude --version# Update to latest
npm install -g @anthropic-ai/claude-code@latestDynamic Workflows specifically requires Claude Code v2.1.154 or later. The basic Opus 4.8 model is available on any recent Claude Code version, but for the new orchestration features, the v2.1.154 minimum applies.
Step 2: Switch the active model
Inside any Claude Code session, switch models with the /model command:
/model claude-opus-4-8
Or set it as the default in your config file. On Claude Code Pro plans, Opus 4.8 is now the default model. Team, Enterprise, and Max plans get default Opus 4.8 plus the Dynamic Workflows preview.
Step 3: Try Dynamic Workflows
For tasks that would benefit from parallel decomposition, include the word 'workflow' in your prompt:
Run a workflow to migrate all our Python services from requests to httpx, update each service's tests, and create a single PR per service.
Claude will generate a JavaScript orchestration script that describes how the task will be split across subagents, present it for your review, and execute it in the background. You can keep working in your session while the workflow runs.
For the broader Claude Code ecosystem context — plugin marketplace, security plugin, MCP integrations — our complete Claude AI 2026 guide covers the full surface, and the security-guidance plugin we covered last week pairs well with Opus 4.8 to give you real-time vulnerability detection on top of the improved coding capability.
10. The honest verdict — should you upgrade?
Three scenarios, three answers.
If you're on Opus 4.7 via the API
Upgrade today. The model ID change is a one-line edit, the price is identical, the SWE-Bench Pro gain is real, and Fast Mode is now three times cheaper. There is no scenario where staying on 4.7 makes sense. The risk profile is essentially zero — Anthropic explicitly designed 4.8 as a drop-in replacement.
If you're a Claude Code user
Update to v2.1.154 and switch to Opus 4.8 as your default. The CursorBench numbers and early developer feedback both confirm the upgrade is real. Dynamic Workflows is worth trying if you have a codebase-scale task on the roadmap — repository migrations, multi-service refactors, large bug sweeps — but treat it as a research preview with real token-cost implications, not a turnkey production feature.
If you're evaluating Opus 4.8 against alternatives. Run real workloads against both, on your codebase, with your test suite as the bar. The benchmark numbers tell you where Opus 4.8 leads (coding, agentic tool use, long-context retrieval) and where it doesn't (raw reasoning index, per-token cost). For the broader frontier comparison and the full April + May 2026 leaderboard with cost-per-intelligence math, the right answer is often to route workloads — Opus 4.8 for engineering depth, Qwen3.7-Max or Kimi K2.6 for high-volume agent loops, Gemini 3.1 Pro for long-context analysis.
If you're waiting for Mythos
Use Opus 4.8 now. The Mythos timeline ('coming weeks') is the most aggressive public commitment Anthropic has made, but 'coming weeks' has slid before. The cost of waiting an unknown number of weeks for an unknown pricing tier on a model with unknown rate limits is higher than the cost of running Opus 4.8 today and migrating to Mythos when it ships. The infrastructure work for switching models is genuinely minimal — model ID, prompt tuning, regression testing — and you'll be far better positioned to evaluate Mythos against a known Opus 4.8 baseline than to evaluate it cold.
11. Frequently Asked Questions
When was Claude Opus 4.8 released?
Claude Opus 4.8 was released on May 28, 2026 — exactly 41 days after Opus 4.7's April 17, 2026 release. This is the fastest version cadence Anthropic has run on the Opus line. The API model ID is claude-opus-4-8.
Is Opus 4.8 in Claude Code?
Yes. Opus 4.8 is available in Claude Code v2.1.154 and later. It is now the default model on Claude Code Pro, Team, Enterprise, and Max plans. Switch to it with the command /model claude-opus-4-8 inside any Claude Code session. The Dynamic Workflows feature is available specifically on Team, Enterprise, and Max plans as a research preview.
What is Dynamic Workflows in Claude Code?
Dynamic Workflows is a Claude Code feature that lets Claude write a JavaScript orchestration script to decompose large tasks and delegate them across up to 1,000 parallel subagents. The script runs in a background runtime, with intermediate results stored in script variables rather than in Claude's context window. Use it for codebase-scale migrations, repository-wide bug sweeps, and multi-service refactors. Mention 'workflow' in your prompt to trigger it.
How is Claude Opus 4.8 different from Opus 4.7?
Opus 4.8 improves on Opus 4.7 across coding benchmarks (SWE-Bench Pro 69.2% vs 64.3%, Terminal-Bench 2.1 74.6% vs 66.1%), math (USAMO 2026 96.7% vs 69.3%), long-context retrieval (GraphWalks F1 68.1% vs 40.3% at 1M tokens), and honesty (4× less likely to ship unflagged code defects). Standard pricing is identical at $5/$25 per million tokens. Fast Mode drops from $30/$150 to $10/$50.
Is Claude Opus 4.8 better than GPT-5.5?
On coding benchmarks, yes — Opus 4.8 leads GPT-5.5 on SWE-Bench Verified (88.6% vs ~82%), SWE-Bench Pro (69.2% vs 58.6%), and Terminal-Bench 2.1 (74.6% vs ~70%). On the AA Intelligence Index for raw reasoning, GPT-5.5 still leads (60.2 vs ~58). VentureBeat reports Opus 4.8 beats GPT-5.5 on at least 12 benchmarks, with GPT-5.5 winning on terminal/CLI workflows and tying on web browsing and graduate-level science. Pick Opus 4.8 for engineering work; pick GPT-5.5 for structured reasoning and academic tasks.
How much does Claude Opus 4.8 cost?
Standard pricing is $5 per million input tokens and $25 per million output tokens — unchanged from Opus 4.7. Fast Mode is $10 per million input and $50 per million output at roughly 2.5× speed (three times cheaper than Fast Mode on Opus 4.7). The same pricing applies on the Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry.
How do I use Opus 4.8 in Claude Code?
Update Claude Code to v2.1.154 or later with npm install -g @anthropic-ai/claude-code@latest, then switch the active model inside any session with the command /model claude-opus-4-8. On Claude Code Pro and higher plans, Opus 4.8 is now the default model — no manual switch needed. For Dynamic Workflows, include the word 'workflow' in your prompt and Claude will generate an orchestration script for review before execution.
What is Fast Mode in Opus 4.8?
Fast Mode runs Opus 4.8 at roughly 2.5× the standard inference speed at double the per-token rate ($10/$50 per million tokens vs $5/$25 standard). It is currently a research preview. Enable it in Claude Code with the /fast command; on the API, contact your account manager for access or join the waitlist. Fast Mode is three times cheaper than the equivalent on Opus 4.7, which used to cost $30/$150 per million tokens.
Is Opus 4.8 better than Mythos?
No. Claude Mythos is Anthropic's most capable model, sitting in a compute tier above Opus. Mythos remains restricted to ~50 Project Glasswing partner organizations as of late May 2026. Anthropic has confirmed Mythos-class general availability is 'expected in the coming weeks' — likely within 4-8 weeks of the Opus 4.8 launch. Opus 4.8 is the most capable publicly available model right now, but it is positioned as the public flagship, not Anthropic's most capable system.
What is the Opus 4.8 release lineage?
The full Opus generational progression:
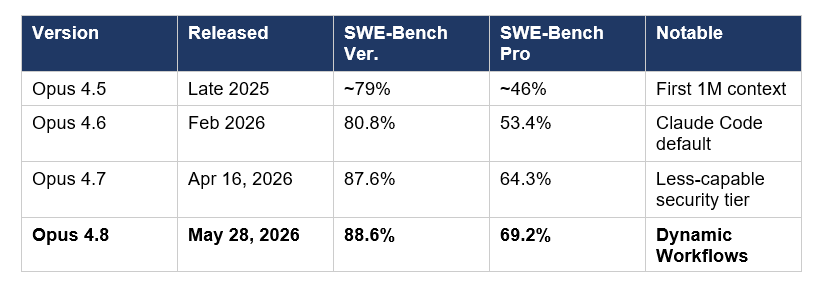
Recommended Blogs
- Claude Opus 4.7: Full Review, Benchmarks & Features (2026)
- Project Glasswing: How Claude Mythos Found 23,019 Vulnerabilities
- Claude Mythos: Release Date, Access, and What Comes Next (2026)
- Claude Code Security-Guidance Plugin Review (2026)
- Qwen3.7-Max vs Claude Opus: Code Arena 2026 Comparison
- Best AI Models: April + May 2026 Leaderboard
- What Is Claude Cowork? The 2026 Guide
- Claude AI 2026: Models, Features, Desktop & More
- Grok Build: xAI's New Agent CLI Reviewed
References
- Anthropic — Introducing Claude Opus 4.8 (official launch)
- TechCrunch — Anthropic releases Opus 4.8 with Dynamic Workflows
- VentureBeat — Claude Opus 4.8 with 3x cheaper Fast Mode
- MarkTechPost — Claude Opus 4.8 with workflows capped at 1,000 subagents
- Axios — Anthropic releases new model, Opus 4.8
- Winbuzzer — Anthropic ships Opus 4.8 with Dynamic Workflows
- Actuia — Claude Opus 4.8: Anthropic emphasizes a more honest model
- LLM Stats — Claude Opus 4.8 release, benchmarks and more
- Finout — Claude Opus 4.8 Pricing 2026: Everything You Need to Know

