




Gemini 3.5 Flash Review: Benchmarks, Price & API (2026)
Google just broke one of the unwritten rules of AI model releases: the cheap, fast Flash tier now outperforms the previous flagship Pro model on coding and agentic benchmarks. Gemini 3.5 Flash launched on May 19, 2026 at Google I/O, and it scores 76.2% on Terminal-Bench 2.1 while running 4x faster than comparable frontier models — and it costs less than Gemini 3.1 Pro. That is not how Flash releases are supposed to work.
This is the most complete breakdown you will find today: full benchmark data, API pricing, thinking level mechanics, competitor comparison, and an honest take on when you should — and should not — reach for Gemini 3.5 Flash.
1. What Is Gemini 3.5 Flash? Key Specs
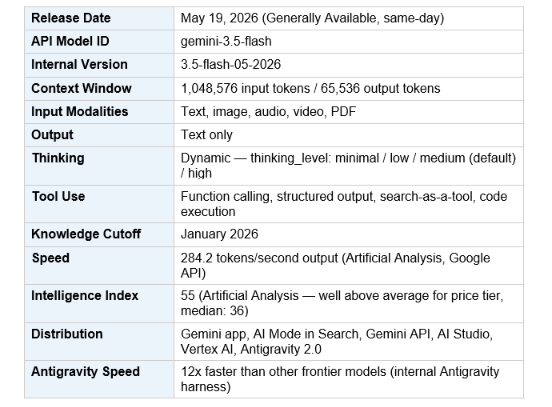
Gemini 3.5 Flash is Google DeepMind's newest and fastest frontier model, released generally available on May 19, 2026 at Google I/O 2026. It is the first model in the Gemini 3.5 family and the strongest agentic and coding model the Flash tier has ever shipped. Unlike previous Flash releases — which made explicit quality trade-offs for speed — 3.5 Flash claims frontier-level intelligence at Flash-tier latency.
The stable API model ID is gemini-3.5-flash (no preview suffix), replacing the gemini-3-flash-preview identifier used during the preview window. As of today, it is the default model powering the Gemini app and AI Mode in Google Search for over 900 million monthly active users worldwide. For context on where this model fits in the current landscape, see Build Fast with AI's May 2026 AI model leaderboard.
Full Spec Sheet
2. The Price Paradox: 3x More Than Flash, Cheaper Than Pro
The pricing of Gemini 3.5 Flash is one of the most discussed details since launch — and the framing matters. Google is marketing this as a cheap, fast model. The reality is more nuanced.
Gemini 3.5 Flash costs $1.50 per million input tokens and $9.00 per million output tokens. Cached input tokens cost $0.15 per million. Non-global regions are $1.65/$9.90. On OpenRouter, it is listed at the same $1.50/$9.00 rate. This price sits roughly 40% below Gemini 3.1 Pro ($2.00/$12.00), which is genuinely significant for high-volume API users. For a complete Gemini pricing breakdown across the full model family, see our Gemini in Google Workspace guide (2026) which covers subscription tiers and API economics together.
Gemini Flash Pricing Evolution
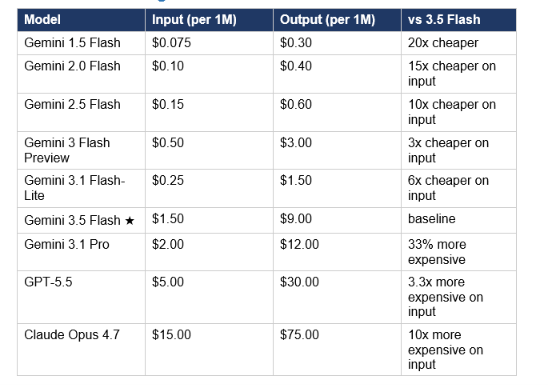
The honest read: 3.5 Flash is 3x the price of Gemini 3 Flash Preview and 6x the price of 3.1 Flash-Lite. Artificial Analysis found it cost approximately 5.5x more to run their full benchmark suite than the previous Flash, driven by both higher per-token prices and more agentic turns consuming more input tokens. Both things are true simultaneously: it is sharply more expensive than its Flash predecessors while landing well below flagship rivals. If you were budgeting on 3 Flash Preview pricing, build in a 3x input-cost increase before migrating.
3. Full Benchmark Breakdown: Where It Wins and Where It Loses
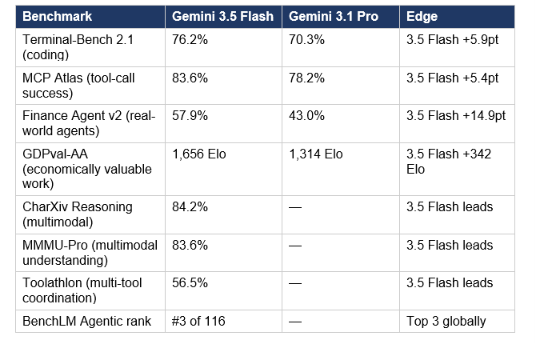
Google's published benchmark table is the primary source here. I have added the Gemini 3.1 Pro score for every row where it was available, so you can see which claims represent real inversions and which are the model playing to its strengths.
Agentic and Coding Benchmarks (3.5 Flash leads)
Where Gemini 3.1 Pro Still Wins
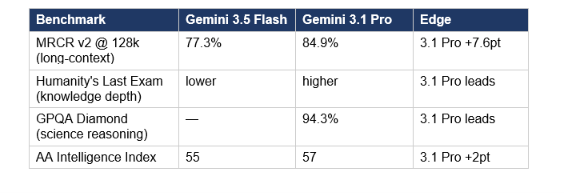
The pattern is clear: 3.5 Flash is an agentic and coding specialist. The 14.9-point gap on Finance Agent v2 and the 342 Elo jump on GDPval-AA are not incremental improvements — they represent a meaningful tier change for multi-step workflow performance. If your use case is long-document retrieval, scientific reasoning, or Humanity's Last Exam-style knowledge depth, Gemini 3.1 Pro remains the stronger choice until Gemini 3.5 Pro ships next month.
One number worth flagging from Artificial Analysis: 3.5 Flash generates roughly 73 million output tokens to complete their benchmark suite — well above the 36M average for models at this price point. It is a verbose model. On tasks billed per output token, verbosity matters. Budget accordingly.
4. Competitor Comparison: Gemini 3.5 Flash vs GPT-5.5 vs Claude Opus 4.7
This is the comparison developers are actually running. Gemini 3.5 Flash is not a Pro-tier model — it is being compared to models that cost 3–10x more per token. That context changes the evaluation frame entirely.
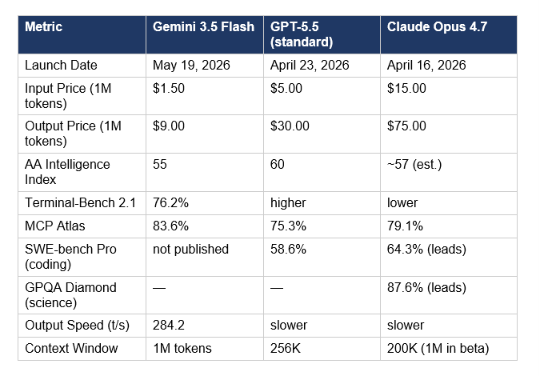
My honest read: Gemini 3.5 Flash wins on MCP-orchestrated multi-step tool use — it leads MCP Atlas at 83.6%, 4.5 points clear of Opus 4.7 and 8.3 points clear of GPT-5.5. For repo-scale software engineering where you need to ship production code that a senior developer would review, Claude Opus 4.7 still wins SWE-bench Pro at 64.3%. For terminal-native agentic work, GPT-5.5 still leads Terminal-Bench 2.0. The full breakdown of the prior-generation comparison is in our Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro piece — the dynamic from that analysis has now shifted in Gemini's favor on tool-use specifically.
At one-third the input cost of GPT-5.5 and one-tenth the cost of Opus 4.7, Gemini 3.5 Flash changes the production routing calculation even if it does not claim every benchmark crown. For high-volume MCP-driven agentic pipelines, the cost differential alone is worth a serious evaluation.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Thinking Levels API: What Changed and What to Migrate
The most important developer-facing change in Gemini 3.5 Flash is the thinking control surface — and it contains a silent production risk that most write-ups have not flagged clearly enough.
The integer thinking_budget parameter that shipped with Gemini 3 Flash Preview has been replaced by a string enum called thinking_level. The new values are minimal, low, medium (default), and high. For a complete API migration walkthrough covering the google-genai Python SDK, see our Gemini Deep Research API tutorial which covers the full SDK migration path from the preview identifier.
Critical Migration Warning

A practical migration checklist: (1) Update model ID strings to gemini-3.5-flash. (2) Explicitly set thinking_level: 'high' if your old prompts relied on high-reasoning defaults. (3) Run token-count comparisons on your most common prompt templates — verbosity increases 40-100% on complex tasks. (4) Adjust any timeout logic: TTFT at 'high' level is 17.75 seconds, compared to sub-5 seconds at 'low' or 'medium'.
6. Where Gemini 3.5 Flash Is Already Deployed
Google has moved quickly on production rollout. As of May 19, 2026, the following are confirmed live deployments powering Gemini 3.5 Flash:
- Gemini app (web, Android, iOS) — default model for all users, free tier included
- AI Mode in Google Search — worldwide rollout, no cost to end user
- Gemini Spark (personal AI agent) — running on dedicated GCloud VMs with Antigravity harness
- Antigravity 2.0 desktop app — optimized at 12x speed for developer agent workflows
- Google AI Studio — Build mode vibe coding environment
- Vertex AI — enterprise API access with tiered SLAs
- Macquarie Bank — piloting for customer onboarding over 100+ page financial documents
- Ramp — OCR over messy invoice batches using the 1M token context window
The Macquarie Bank and Ramp deployments are the most signal-rich: they represent exactly the finance-agentic use case where 3.5 Flash's 14.9-point Finance Agent v2 lead over 3.1 Pro translates to real operational improvement. These are not demo deployments.
7. Limitations and Honest Criticism
Three things that require honest coverage: First, the price increase is real. If you are migrating from Gemini 3 Flash Preview, your input costs triple and your output costs triple. Artificial Analysis clocked a 5.5x increase in total benchmark run cost. Google's own blog framed this as a capability upgrade, which it is — but teams running high-volume Flash workloads need a budget line item for this migration. For context on what the 3 Flash Preview era cost, see our earlier Gemini 3.2 Flash pre-I/O analysis which has cost math for the 3.x family.
Second, Gemini 3.5 Pro was delayed to next month, and the I/O audience reportedly audibly groaned. If your primary use case requires the absolute frontier of reasoning — Humanity's Last Exam, GPQA Diamond, long-context retrieval — 3.5 Flash is not that model yet. It is a strong second choice while you wait for Pro.
Third, 3.5 Flash has no computer use capability in this release. Unlike GPT-5.5 (which scores 75%+ on OSWorld desktop automation benchmarks), Gemini 3.5 Flash cannot directly interact with desktop applications. If your agentic workflow requires computer use, GPT-5.5 remains the only published option at this capability level.
Hot take: The 'Flash beats Pro' framing is real on coding and agentic benchmarks but misleading as a general claim. This model wins in the scenarios Google built it for — fast MCP-orchestrated workflows, Finance Agent, multimodal understanding. It is not a better all-around model than 3.1 Pro. The category boundaries just shifted.
8. How to Use Gemini 3.5 Flash via the API
Gemini 3.5 Flash is available immediately, with no waitlist, across all standard Gemini API distribution points.
Access Points
- Gemini app (web / Android / iOS) — free, no API key required
- Google AI Studio (aistudio.google.com) — free tier with daily quotas
- Gemini API — pay-as-you-go at $1.50/$9.00 per million tokens
- Vertex AI — enterprise tier with tiered SLAs and regional endpoints
- OpenRouter — google/gemini-3.5-flash at same $1.50/$9.00 pricing
- Antigravity 2.0 — standalone desktop app, optimized at 12x speed
Python Quick Start
Install the SDK: pip install -U google-genai
Then use the new model ID directly:
from google import genai
client = genai.Client()
response = client.models.generate_content(
model='gemini-3.5-flash',
contents='Analyze this codebase for security vulnerabilities',
config={'thinking_config': {'thinking_level': 'high'}}
)
print(response.text)Key note: if you are migrating from gemini-3-flash-preview, explicitly set thinking_level: 'high' if your previous code relied on high reasoning defaults — the new default is 'medium'. For a full migration walkthrough with MCP, file grounding, and the new Interactions API, the Gemini Deep Research API Python tutorial covers the full SDK migration path including the google-genai v3.x breaking changes.
Frequently Asked Questions
What is Gemini 3.5 Flash?
Gemini 3.5 Flash is Google DeepMind's newest Flash-tier AI model, launched generally available on May 19, 2026 at Google I/O 2026. It is the first model in the Gemini 3.5 family, features a 1M-token context window, multimodal input support (text, image, audio, video, PDF), and outperforms Gemini 3.1 Pro on coding and agentic benchmarks while running 4x faster and costing ~40% less.
How much does Gemini 3.5 Flash cost per million tokens?
$1.50 per million input tokens and $9.00 per million output tokens via the Gemini API. Cached input tokens are $0.15/M (90% discount). Non-global regions are $1.65/$9.90. This is 3x the price of Gemini 3 Flash Preview ($0.50/$3.00) and 6x the price of Gemini 3.1 Flash-Lite ($0.25/$1.50), but ~40% cheaper than Gemini 3.1 Pro ($2.00/$12.00).
Is Gemini 3.5 Flash better than GPT-5.5?
On MCP Atlas (multi-tool coordination), Gemini 3.5 Flash leads at 83.6% vs GPT-5.5's 75.3%. On Terminal-Bench 2.0 and ARC-AGI-2 reasoning, GPT-5.5 leads. On price, Gemini 3.5 Flash costs $1.50/$9 vs GPT-5.5's $5/$30 — roughly one-third the cost for comparable or better agentic tool-use performance. GPT-5.5 is stronger for reasoning-heavy and computer-use workflows.
How does Gemini 3.5 Flash compare to Gemini 3.1 Pro?
On agentic and coding benchmarks — Terminal-Bench 2.1 (76.2% vs 70.3%), MCP Atlas (83.6% vs 78.2%), Finance Agent v2 (57.9% vs 43.0%) — 3.5 Flash leads. On long-context retrieval (MRCR v2 at 128k: 77.3% vs 84.9%), science reasoning (GPQA Diamond), and Humanity's Last Exam, Gemini 3.1 Pro still leads. The intelligent routing decision: use 3.5 Flash for agentic and coding, use 3.1 Pro for knowledge-intensive research until 3.5 Pro ships next month.
What is the thinking_level parameter?
thinking_level replaces the old integer thinking_budget parameter. New values are minimal, low, medium (default), and high. Critical migration note: the default dropped from 'high' (Gemini 3 Flash Preview) to 'medium' (3.5 Flash). If you port from gemini-3-flash-preview to gemini-3.5-flash without changing config, your model silently reasons less. Explicitly set thinking_level: 'high' to restore prior behavior.
When is Gemini 3.5 Pro releasing?
Google confirmed at Google I/O 2026 that Gemini 3.5 Pro is in development and rolling out 'next month' — approximately June 2026. No specific date was given. The I/O audience audibly reacted when Sundar Pichai delivered this news, signaling the Pro model was the most anticipated part of the 3.5 family.
Is Gemini 3.5 Flash free to use?
Yes — in the Gemini app (web, Android, iOS) and AI Mode in Google Search, Gemini 3.5 Flash is free for all users with no API key required. Developers pay $1.50/$9.00 per million tokens through the Gemini API. Google AI Studio provides a free daily quota for prototyping without payment information required.
What is the Gemini 3.5 Flash context window?
Gemini 3.5 Flash supports 1,048,576 input tokens (~786K words) and 65,536 output tokens (~49K words). This is the same 1M context window as Gemini 3.1 Pro, GPT-5.5 (which has 256K), and competitive with Claude Opus 4.7 (200K standard, 1M in beta). For large codebase analysis or processing year-long document archives in a single call, the 1M window is the practical differentiator.
Does Gemini 3.5 Flash support computer use?
No. Gemini 3.5 Flash does not have published computer use capability in this release. Google's Antigravity 2.0 provides browser-based and filesystem agentic capabilities, but direct desktop/OS interaction comparable to GPT-5.5's OSWorld (75%+) score has not been announced for this model. Computer use remains a GPT-5.5 exclusive capability at the frontier tier as of May 2026.
Recommended Blogs
- Best AI Models May 2026 Leaderboard — GPT-5.5, Claude Opus 4.7, DeepSeek V4
- Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro: Best All-Rounder in 2026?
- Best AI Models Leaderboard: April 2026 Update
- Gemini 3.1 Flash Lite vs 2.5 Flash: Speed, Cost & Benchmarks (2026)
- GPT-5.4 vs Gemini 3.1 Pro (2026): Which AI Wins?
- Gemini Deep Research API: Full Python Tutorial (2026)
- Google AI Studio Vibe Coding: Full Guide (2026)
Building with Gemini 3.5 Flash or any frontier model? Join Build Fast with AI's Gen AI Launchpad — hands-on projects, 100+ tutorials, and a community of 30,000+ builders. New cohort open now at buildfastwithai.com.
References
- Google DeepMind — Gemini 3.5 Flash Launch (Google I/O 2026)
- LLM Stats — Gemini 3.5 Flash: Benchmarks, Pricing, and Complete Specs
- Artificial Analysis — Gemini 3.5 Flash Intelligence, Performance & Price Analysis
- BenchLM — Gemini 3.5 Flash Benchmarks 2026: Scores, Rankings & Performance
- Digital Applied — Gemini 3.5 Flash: Benchmarks, Thinking & API Guide 2026
- Simon Willison — Gemini 3.5 Flash: More Expensive, But Google Plan to Use It for Everything
- OpenRouter — Gemini 3.5 Flash API Pricing & Providers
Neowin — Google Announces Gemini 3.5 Flash, Its Strongest Coding Model Yet

