




Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro: The Best All-Rounder in 2026?
Six models now score within 0.8 points of each other on SWE-bench Verified. Three of them launched in the last five weeks. If you're still picking your AI stack based on which company you liked in 2024, you are leaving money on the table — and probably shipping worse code than the developer next to you.
This is the comparison that actually matters for 2026: Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro. Not the flagship tier (Opus 4.7 costs $5/$25 per million tokens — that's a different conversation). The mid-to-frontier tier where most real work happens, where pricing decisions get made, and where the answer is genuinely close.
We've pulled verified benchmark scores, confirmed API pricing as of May 2026, and mapped each model to specific use cases. If you want the full historical benchmark trajectory across all frontier models, the Best AI Models Leaderboard at Build Fast with AI runs monthly updates. Here, we focus on the three-way fight.
1. TL;DR — Which Model Wins What
Don't have 9 minutes? Here's the short version. No single model wins in 2026 — the leaderboard has fractured by task, and the right answer depends entirely on what you're building.
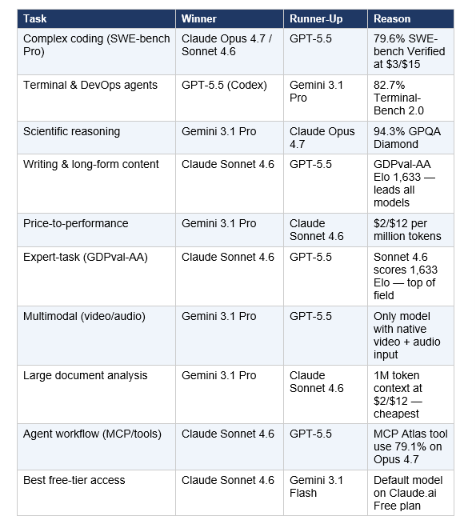
My contrarian take: the question 'which is the best all-rounder' is the wrong question in 2026. The right question is which model you should use for which specific task category in your workflow — because routing across multiple models costs less and performs better than committing to one.
2. Model Overview & Context
These three models all landed in a compressed window. Understanding what each one is — and what it's actually optimized for — changes how you read the benchmarks.
Claude Sonnet 4.6 - Anthropic's Workhorse
Released February 17, 2026, Claude Sonnet 4.6 is Anthropic's mid-tier model positioned as the daily-driver replacement for most workflows that previously required Opus-class pricing. The headline number: in Claude Code head-to-head testing, developers preferred Sonnet 4.6 over the previous generation's flagship (Opus 4.5) 59% of the time. For a model priced at $3/$15 per million tokens versus Opus 4.5's $5/$25, that preference inversion is the real story.
Key upgrades in Sonnet 4.6: computer use accuracy jumped to 94% on insurance benchmarks (the highest of any model tested), long-context retrieval improved dramatically, and the model now matches Opus 4.6 on OfficeQA — enterprise document, chart, PDF, and table comprehension. Sonnet 4.6 is the default model on Claude.ai's Free and Pro plans.
GPT-5.5 - OpenAI's Rebuilt Flagship
GPT-5.5 launched April 23, 2026, and it's not a post-training increment on earlier versions. OpenAI rebuilt the architecture, pretraining corpus, and objectives from scratch — the first time they've done this since GPT-4.5. The result: GPT-5.5 leads the Artificial Analysis Intelligence Index (score: 60), tops SWE-bench Verified at 88.7%, and posts 82.7% on Terminal-Bench 2.0 — the strongest agentic coding performance of any general-purpose model in this comparison.
For developers running terminal-heavy agentic workflows — deployment scripts, CI/CD debugging, infrastructure management — GPT-5.5 (via Codex) has a meaningful and documented lead. That gap is not marketing noise.
Gemini 3.1 Pro — Google's Price-Performance King
Gemini 3.1 Pro launched February 19, 2026, and immediately took the top position on multiple reasoning benchmarks. Its GPQA Diamond score of 94.3% — measuring graduate-level physics and science reasoning — is the highest of any commercial model. At $2 input / $12 output per million tokens, it's the cheapest frontier model in this comparison. That price-performance ratio, combined with a 1M token context window and native multimodal support (text, images, audio, video), makes it the default recommendation for any team where cost discipline matters.
The catch: Gemini 3.1 Pro generates more tokens per task than competitors, which erodes its cost advantage at scale. For creative writing and narrative work, Claude Sonnet 4.6 consistently produces higher-quality prose.
3. Full Benchmark Comparison Table
All scores sourced from SWE-bench leaderboard, Artificial Analysis Intelligence Index, and published vendor evaluations as of May 2026. Scaffold and evaluation conditions affect scores — a 0.2% difference between models is within noise. Use the table directionally, not as absolute rankings
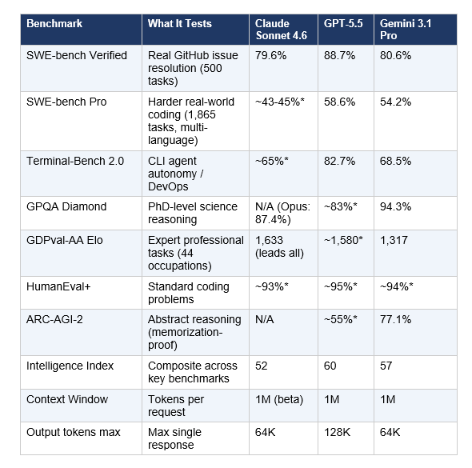
*Community consensus estimates — vendor has not published official numbers for this exact benchmark/model combination.
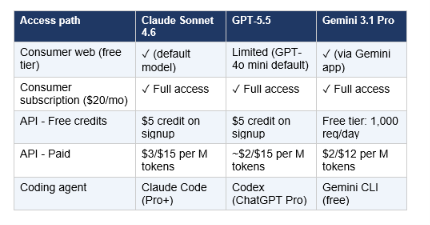
4. Pricing: What You Actually Pay
Pricing shapes model choice as much as capability does. Here's the confirmed API pricing as of May 2026. Note that all three models also offer $20/month consumer subscriptions (Claude Pro, ChatGPT Plus, Google One AI Premium) that bundle web access — these are the better choice if you're an individual, not a developer billing via API.
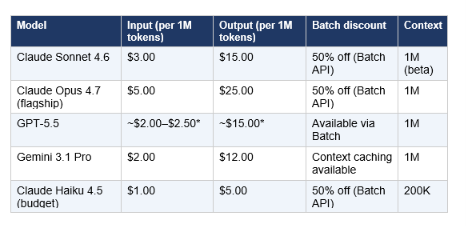
*GPT-5.5 pricing quoted from OpenRouter and community sources as of May 2026. OpenAI has not published official per-token pricing for GPT-5.5 at the time of writing.
The math that matters: for a team processing 100 million input tokens and 10 million output tokens monthly, Gemini 3.1 Pro costs roughly $320 versus $450 for Claude Sonnet 4.6. A 29% input cost advantage is real, but the output quality difference often justifies Sonnet for writing-heavy workflows. The practical recommendation: use Gemini 3.1 Pro as your high-volume default. Escalate to Claude Sonnet 4.6 for writing, reasoning-heavy agent work, and any task where instruction-following precision matters.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Coding Performance Deep-Dive
Coding is where this comparison gets interesting — and complicated. The right answer depends entirely on which type of coding task you're running.
Standard Algorithmic Coding (HumanEval+)
All three models score in the 93–95% range on HumanEval+, which tests standard algorithmic coding problems. At this level, the differences are within measurement noise. For routine function writing, bug fixing, and boilerplate generation, all three are effectively equivalent.
Real-World Coding (SWE-bench Verified)
This is where GPT-5.5 pulls ahead clearly. At 88.7% SWE-bench Verified, it resolves roughly 443 of 500 real GitHub issues autonomously. Gemini 3.1 Pro posts 80.6% (403 issues). Claude Sonnet 4.6 scores 79.6% (398 issues). For the developers who run Claude Code in production, note that Claude Code running on Opus 4.7 achieves 87.6% — the agent harness matters as much as the model weights.
Terminal & DevOps Agents (Terminal-Bench 2.0)
GPT-5.5's biggest lead is here: 82.7% versus Gemini 3.1 Pro's 68.5% and Claude's estimated ~65%. If your workflow involves deployment scripts, CI/CD debugging, infrastructure automation, or heavy terminal use, GPT-5.5 via Codex is the documented choice. The 14-point gap on Terminal-Bench over Gemini is not noise — it's a real architectural difference in how GPT-5.5 handles command execution chains.
Hard Real-World Coding (SWE-bench Pro)
SWE-bench Pro uses 1,865 tasks across 41 repositories in Python, Go, TypeScript, and JavaScript — harder and less contaminated than the standard Verified set. Here GPT-5.5 leads at 58.6%, Gemini 3.1 Pro posts 54.2%, and Claude Sonnet 4.6 is estimated around 43-45%. If you want the full benchmark breakdown including Kimi K2.6, DeepSeek, and open-source alternatives, the coding AI benchmarks comparison covers the full landscape.
Code Quality & Readability
Here's the comparison that benchmarks miss: in head-to-head testing across recursion, error handling, and edge-case logic, GPT-5.5 produces fewer failures. But Claude Sonnet 4.6's code is consistently cleaner, better-commented, and easier to maintain. The tradeoff is real. If your team cares about technical debt and long-term maintainability, Claude's code quality advantage is worth the slightly lower raw benchmark score. If you care about resolution rate and autonomous task completion, GPT-5.5 has the documented edge
6. Writing & Content Tasks
This is Claude Sonnet 4.6's clearest win. In blind human evaluations by independent research groups in Q1 2026, Claude-generated content was preferred 47% of the time versus 29% for GPT-5.5 variants and 24% for Gemini 3.1 Pro. That gap didn't come from a single evaluation — it's consistent across multiple testing setups.
The GDPval-AA Elo benchmark measures AI performance on 44 professional knowledge work occupations across finance, legal, analysis, documentation, and writing. Claude Sonnet 4.6 scores 1,633 Elo — the highest of any model tested, beating Opus 4.6 (1,453), Gemini 3.1 Pro (1,317), and GPT-5.5 variants.
Why the writing gap exists: Claude maintains consistent voice across 10,000+ word outputs where other models drift. Its structural coherence across long documents is measurably better. And it adheres more precisely to complex style guides and formatting requirements — which matters enormously for teams producing high-volume, brand-consistent content.
Practical recommendation: Use Claude Sonnet 4.6 for drafting, GPT-5.5 for editing passes and factual enrichment. The combination outperforms either model alone. If you want specific prompting strategies that extract the best writing quality from Claude, the 150 Best Claude Prompts guide covers the patterns that actually work.
7. Reasoning & Science Benchmarks
Gemini 3.1 Pro's standout category. It leads every published reasoning benchmark as of May 2026 among these three models
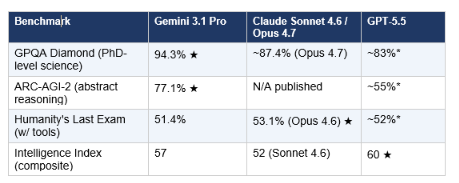
If your work involves interpreting research papers, answering expert-level medical or scientific questions, or running structured experiments through an AI system, Gemini 3.1 Pro is the call. The 94.3% GPQA Diamond score — measuring graduate-level physics, biology, and chemistry — represents the clearest advantage of any model in any category in this comparison.
The one area where Gemini's reasoning lead erodes: practical, tool-augmented research workflows. Claude's tool integration is more reliable in multi-step agent loops that require web search, database queries, and calculation chaining. Gemini leads on pure benchmark reasoning; Claude leads on agentic research execution.
8. Multimodal Capabilities
This category has a clear winner: Gemini 3.1 Pro. It's the only model in this comparison with native audio and video input alongside text, images, and code in a single 1M-token context window. That's not a marginal difference — it's a category capability
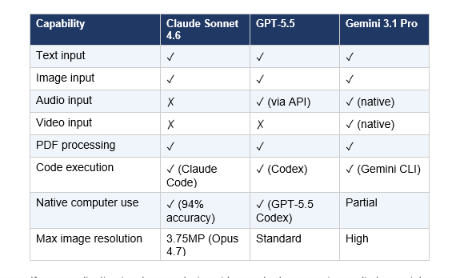
If your application involves analyzing video content, processing audio transcripts, or building multimodal pipelines without preprocessing steps, Gemini 3.1 Pro is the practical choice — not because the other models are incapable, but because native support eliminates the integration overhead.
9. Is Claude Sonnet 4.6 Free?
This is the question appearing most in Google autocomplete data — and the answer is more nuanced than a yes/no.
For consumers (Claude.ai)
Yes — Claude Sonnet 4.6 is the default model on Claude.ai's Free plan. You get access to it at no cost, with a daily message limit. The free tier now also includes file creation, connectors, skills, and context compaction — features that were previously Pro-only. This is genuinely competitive free-tier access.
For developers (API access)
No — there's no free API tier for Claude Sonnet 4.6. New Anthropic accounts receive approximately $5 in API credits on signup (no credit card required), which is enough to test the model but not production use. API access is then billed at $3 input / $15 output per million tokens.
Is Claude Sonnet 4.6 available in Claude Code?
Yes — Claude Code is available on the $20/month Claude Pro plan and all higher tiers. The Free plan does not include Claude Code. Within Claude Code, Sonnet 4.6 is the default model and handles approximately 80% of coding tasks. Pro users can also escalate to Opus 4.7 ($5/$25 per million tokens) for complex multi-file work
10. Pros and Cons of Each Model
Claude Sonnet 4.6
Pros:
- Leads GDPval-AA Elo (1,633) — best expert-task performance of any model in this price tier
- Best writing quality and long-form coherence — preferred by humans 47% vs 29% (GPT-5.5) in blind tests
- 94% computer use accuracy — highest tested on insurance benchmark
- Default on Free and Pro plans — genuine no-cost access for consumers
- Same pricing as Sonnet 4.5 ($3/$15) with significant intelligence upgrade
- 1M context window beta — handles entire codebases in one session
Cons:
- SWE-bench Pro score lags GPT-5.5 by ~14 points — real gap for complex multi-language coding
- Terminal-Bench 2.0 trails GPT-5.5 by ~17 points — GPT-5.5 via Codex is stronger for DevOps
- No native audio or video input — preprocessing required for multimodal pipelines
- Intelligence Index composite score (52) sits below Gemini 3.1 Pro (57) and GPT-5.5 (60)
GPT-5.5
Pros:
- Leads Artificial Analysis Intelligence Index (score: 60) — strongest composite model
- 88.7% SWE-bench Verified and 82.7% Terminal-Bench 2.0 — agentic coding leader
- Rebuilt architecture (not an incremental update) — first since GPT-4.5
- Native computer use across desktop interfaces
- 128K max output tokens — 2x Claude and Gemini's 64K limit for long generation tasks
- Largest ecosystem of third-party integrations and tool support
Cons:
- Official pricing not yet published — community quotes $2–$2.50 input, subject to change
- Writing quality rated lower than Claude in blind human evaluations (29% preference vs 47%)
- Requires ChatGPT Pro ($200/month) for Codex agent access with full capabilities
- Less reliable for nuanced instruction-following compared to Claude Sonnet 4.6
Gemini 3.1 Pro
Pros:
- Cheapest frontier model at $2/$12 per million tokens — 33% cheaper than Sonnet 4.6 on input
- 94.3% GPQA Diamond — highest scientific reasoning score of any model
- 77.1% ARC-AGI-2 — strongest abstract reasoning score, up 2.5x from prior version
- Native audio and video input — only model with full multimodal stack
- 1,000 free API requests per day — most generous free developer tier
- Strong Google Workspace integration — advantage for Google-native teams
Cons:
- GDPval-AA Elo 1,317 vs Sonnet 4.6's 1,633 — meaningfully weaker on expert professional tasks
- Writing quality rated lowest of three models in blind human preference tests (24%)
- Generates more tokens per task — erodes cost advantage at high output volume
- Prompt interpretation issues on ambiguous tasks — commits to wrong interpretation confidently
- Creative writing benchmarks below Claude Sonnet 4.6 and GPT-5.5 on narrative flexibility
11. Who Should Use Which Model
The honest recommendation matrix for 2026:
Use Claude Sonnet 4.6 if you are...
- A content team producing high-volume, brand-consistent writing — best writing quality in this tier
- A developer building production AI agents where instruction-following precision matters
- Working within the Anthropic/Claude Code ecosystem (GitHub Copilot now defaults to it)
- Running complex expert-level analysis, document review, or knowledge work tasks
- A consumer who wants the best free-tier experience — Claude.ai Free gives Sonnet 4.6 access at $0
Use GPT-5.5 / Codex if you are...
- A DevOps or SRE team running terminal-heavy, CLI-based agentic workflows
- Building complex multi-file coding agents where SWE-bench Pro performance is the priority
- Already deeply embedded in the OpenAI/ChatGPT ecosystem of tools
- Needing 128K output tokens for single-pass large codebase generation
Running agent loops at scale — see the GPT-5.3 Codex vs Claude vs Kimi benchmark comparison for the full cost and performance breakdown.
Use Gemini 3.1 Pro if you are...
- A researcher or scientist needing PhD-level reasoning (94.3% GPQA Diamond wins this category)
- Building multimodal applications that ingest video, audio, or mixed media natively
- Running high-volume production APIs where cost efficiency is the primary constraint
- A Google Workspace-native team that benefits from native Workspace integration
Processing large document corpora — 1M context at $2/$12 is unbeatable for this use case. If you want to go deeper on the Every AI Model Compared per task article covers 12 task categories with current winners.
The Model Routing Play (2026's Best Strategy)
The smartest architecture is not picking one model. A typical 2026 production stack routes 70% of traffic to a cheap capable model (Gemini 3.1 Flash at $0.35/$1.05 per million tokens), 25% to a mid-tier model (Claude Sonnet 4.6 or Gemini 3.1 Pro), and 5% to a frontier model for complex tasks. This achieves near-frontier overall performance at roughly 15% of the all-frontier cost. For implementation patterns, the Best AI Agent Frameworks guide shows how to wire multi-model routing into production pipelines.
Frequently Asked Questions
Is Claude Sonnet 4.6 free?
Yes — for consumers. Claude Sonnet 4.6 is the default model on Claude.ai's Free plan with no subscription required. You get daily message access, file creation, and connectors at no cost. For API access, it is not free: pricing is $3 input / $15 output per million tokens, with a $5 signup credit on new Anthropic accounts.
What is Claude Sonnet 4.6 good for?
Claude Sonnet 4.6 leads the GDPval-AA Elo benchmark (1,633 points) for expert professional tasks — knowledge work across writing, analysis, documentation, and coding. It's the best model in its price tier for long-form content quality, instruction-following precision, and agentic computer use (94% accuracy on enterprise benchmarks). It's also the default model powering GitHub Copilot's coding agent as of early 2026.
Is Claude Sonnet 4.6 available on Claude Code?
Yes — Claude Sonnet 4.6 is the default model in Claude Code and available on the $20/month Claude Pro plan and higher. Free plan users can access Claude Sonnet 4.6 on Claude.ai but not through the Claude Code CLI. Within Claude Code, developers can also access Claude Opus 4.7 for more complex multi-file work.
Which is better: GPT-5.5 or Gemini 3.1 Pro?
It depends on the task. GPT-5.5 leads on the composite Intelligence Index (60 vs 57) and dominates Terminal-Bench 2.0 for agentic coding (82.7% vs 68.5%). Gemini 3.1 Pro leads on scientific reasoning with 94.3% GPQA Diamond and costs 33% less on input tokens ($2 vs $2.50 per million). For most production workloads, Gemini 3.1 Pro offers better price-to-performance. For terminal-heavy DevOps agents, GPT-5.5 is the documented choice.
Is Gemini 3.1 Pro good for coding?
Yes — Gemini 3.1 Pro scores 80.6% on SWE-bench Verified and 54.2% on SWE-bench Pro, placing it in the top tier for real-world code generation. Its 1M token context window gives it a meaningful advantage on large codebase analysis. However, GPT-5.5 leads on SWE-bench Pro (58.6%) and Terminal-Bench 2.0 (82.7%) for the hardest agentic coding tasks. For general coding at scale, Gemini 3.1 Pro's price-performance is hard to beat.
Is Claude Sonnet 4 better than GPT-4?
Claude Sonnet 4.6 (released February 2026) significantly outperforms GPT-4 and GPT-4o across all major benchmarks. On SWE-bench Verified, Sonnet 4.6 scores 79.6% versus GPT-4o's ~33%. The 2026 generation of mid-tier models like Sonnet 4.6 competes with 2025 flagship models, not 2023-era GPT-4.
Which is the best AI all-rounder in 2026?
There is no single best all-rounder — the leaderboard has fractured by task. Claude Sonnet 4.6 wins on writing quality and expert professional tasks. GPT-5.5 wins on agentic coding and terminal workflows. Gemini 3.1 Pro wins on scientific reasoning and price-to-performance. The correct 2026 strategy is model routing: use Gemini 3.1 Flash for high-volume tasks, Claude Sonnet 4.6 for writing and analysis, and GPT-5.5 or Claude Opus 4.7 for complex agentic coding.
What is the context window for Claude Sonnet 4.6?
Claude Sonnet 4.6 supports a 1 million token context window in beta — the same as Gemini 3.1 Pro and GPT-5.5. At standard $3/$15 pricing with no surcharge for large contexts (unlike the Sonnet 4.5 long-context beta which charged 2x), this makes Sonnet 4.6 a cost-effective option for large document and codebase analysis.
Is Claude Sonnet 4.6 vs Opus 4.6 worth the upgrade?
For most workflows, yes — Sonnet 4.6 is the right default. In Claude Code head-to-head testing, developers preferred Sonnet 4.6 over Opus 4.5 (the previous flagship) 59% of the time. It matches Opus 4.6 on OfficeQA and delivers roughly 90% of Opus quality at 40% of the cost. Reserve Opus 4.7 for the 10-20% of tasks involving deep architectural reasoning, multi-agent coordination, or complex multi-file refactoring.
Recommended Blogs
- Best AI Models Leaderboard: April + May 2026 (GPT-5.5, Claude Opus 4.7, DeepSeek V4)
- Every AI Model Compared: Best One Per Task (2026)
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5: Who Actually Wins?
- Claude AI 2026: Models, Features, Desktop & More
- Best AI Models April 2026: Ranked by Benchmarks
- Best AI Agent Frameworks in 2026: LangGraph, CrewAI, AutoGen and More
The model landscape shifts every few weeks. Follow Build Fast with AI for monthly leaderboard updates, hands-on benchmark testing, and the workflows that professional developers actually use in production.
References
- Anthropic — Claude Sonnet 4.6 Model Card and Pricing
- Build Fast with AI — Best AI Models April 2026
- AI Magicx — Claude Opus 4.6 vs GPT-5.4 vs Gemini 3.1 Pro Benchmark Breakdown
- MindStudio — GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro Real Benchmarks
- LumiChats — Gemini 3.1 Pro vs Claude Sonnet 4.6 vs GPT-5.4 April 2026
- Morph LLM — Best AI for Coding 2026: Every Model Ranked
- Finout — Anthropic API Pricing 2026 Complete Guide
- Bind AI — Gemini 3.1 Pro vs Claude Sonnet 4.6 vs GPT-5.3 Coding Comparison

