




A Reddit post titled "Opus 4.7 is not an upgrade but a serious regression" collected 2,300 upvotes within 48 hours of launch. On X, a post claiming no improvement over 4.6 hit 14,000 likes. VentureBeat ran: "Is Anthropic nerfing Claude?" The Register quoted AMD's AI director calling Claude Code "dumber and lazier."
This is not the usual grumbling that follows any major model release. The complaints are specific, the data is real, and the timing — with GPT-5.5 dropping seven days later — turned a rough launch into a full narrative shift in the developer community. Developers who built workflows around Claude are actively switching to Codex. Some have the receipts to prove it.
Here is what actually happened to Opus 4.7, what regressed and why, where it still leads, and what this means for your stack in 2026.
What Is Claude Opus 4.7? (The Upgrade That Wasn't Fully an Upgrade)
Claude Opus 4.7 is Anthropic's current publicly available flagship model, released April 16, 2026. It is the successor to Claude Opus 4.6 and the highest-tier model below the internal-only Mythos Preview.
On paper, the improvements are real. SWE-Bench Pro jumped from 53.4% to 64.3% — a 10.9-point gain, the largest single-version improvement in the Opus line. Vision resolution tripled from 1.15 megapixels to 3.75 megapixels. A new xhigh reasoning effort level landed between high and max. Pricing stayed flat at $5 per million input and $25 per million output tokens.
Cursor CEO Michael Truell confirmed that Opus 4.7 "lifted resolution by 13% over Opus 4.6" on Cursor's internal 93-task benchmark and solved four tasks that neither Opus 4.6 nor Sonnet 4.6 could touch. For context on how this fits into the broader model landscape, the Best AI Models April 2026 benchmark leaderboard covers every major release from that month side by side.
The gap between the benchmark story and the developer experience story is the real subject of this post. Both are true. That's what makes it complicated.
The Three Real Regressions in Opus 4.7
Three specific, documented issues drove the backlash — not vague vibes, not benchmark skepticism. These are real problems that real developers hit.
1. Tokenizer Cost Inflation
Anthropic changed the tokenizer in Opus 4.7. This is not technically a price increase — the listed price per million tokens is unchanged from Opus 4.6. In practice, code-heavy and structured-data-heavy prompts now use 20–35% more tokens on identical inputs. The effective API bill went up even though the headline price didn't.
This was the most financially impactful issue for production teams running high-volume pipelines. A team paying $5,000/month for Opus 4.6 could be looking at $6,000–$6,750 for the same workload on 4.7 without any explicit pricing announcement or change.
2. Safety RLHF Spillover in Claude Code
Multiple developers reported that Opus 4.7, when used through Claude Code, flagged routine benign code as malware and refused to complete standard file operations, network calls, and library usage that 4.6 handled without issue. Anthropic acknowledged this and adjusted the default reasoning level in Claude Code after reports came in.
The underlying mechanism: after a model ships, Anthropic's safety team continues RLHF updates to address newly discovered issues. These updates are not surgical. When the safety team tightened a specific category, it produced spillover effects that degraded agentic coding behavior. One user described watching the model "argue with itself about a non-issue for fifteen minutes while the actual bug sat in plain sight in the file it never bothered to re-read."
3. Early Abandonment and Reduced Persistence
The third complaint is the hardest to benchmark but the most consistent across developer reports: Opus 4.7 gives up early. Ask it to take test coverage from 55% to 80%. It writes a few tests, declares victory at 58%, asks if you want to continue. You say yes. It writes two more, declares victory at 60%, asks again. The persistence that made Opus 4.6 valuable in long agentic sessions degraded.
This mirrors exactly what happened with Opus 4.6 mid-cycle. For the full story of that regression and how Anthropic addressed it, the GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 comparison covers the competitive context that led Anthropic to build Opus 4.7 the way they did — and why the same pattern keeps recurring.
Why It Happened: Tokenizer + RLHF Spillover
The tokenizer change is a deliberate architectural decision. New tokenizers can improve model efficiency and multilingual handling but often change how tokens are counted on technical content. Anthropic made this change without clearly communicating its cost implications — which is why teams discovered it through their API bills, not through a release note.
The RLHF spillover problem is structural to how frontier labs update models post-launch. Targeted safety updates narrow down on a specific failure category — a type of harmful output, a refusal pattern — and run a reinforcement learning pass to correct it. The update doesn't work like a surgical edit. It shifts behavior across a distribution. When the correction category overlaps with agentic coding behavior, you get the Claude Code malware-flagging bug: a safety update that caught something real, but also caught things it shouldn't have.
Anthropic's stated response for Opus 4.8 is twofold: narrower-scoped RLHF correction data with explicit holdout testing on agentic tasks, and an internal regression benchmark specifically for multi-step agentic instruction-following that must pass before any mid-cycle update ships. Whether that holds in practice remains to be seen. The Opus 4.6 mid-cycle regression and the Opus 4.7 launch regression are the same failure mode appearing twice. That is a pattern worth tracking.
Hot take: the deeper problem here is not the regression itself. Every lab ships regressions. The problem is the changelog gap. Anthropic did not publish release notes that would let developers distinguish between a model regression, a safety update, and normal prompt-sensitivity variation. That transparency gap is what turned a fixable technical problem into a community trust event.
Where Opus 4.7 Still Leads — and by How Much
Opus 4.7 leads GPT-5.5 on the benchmarks that matter most for long-horizon software engineering — and the margins are not small.
- SWE-Bench Pro: 64.3% vs GPT-5.5's 58.6% — a 5.7-point gap on the harder, less benchmark-contaminated evaluation. This represents hundreds of real GitHub issues where Claude ships working code and GPT-5.5 doesn't.
- GPQA Diamond (graduate-level science reasoning): Opus 4.7 leads. Relevant for any codebase with serious algorithmic complexity.
- MCP Atlas and FinanceAgent v1.1: Opus 4.7 leads. Relevant for financial services and complex tool-use orchestration.
- Vision: Opus 4.7 at 3.75 megapixels versus GPT-5.5's ~1.15 megapixel envelope. For computer-use agents reading high-resolution screenshots, this matters.
- Time-to-first-token: ~0.5s for Opus 4.7 versus ~3.0s baseline for GPT-5.5. For interactive developer workflows, this latency gap is noticeable.
Tom's Guide ran both models against the same tasks and reported Claude Opus 4.7 won across 7 categories. The benchmarks that GPT-5.5 wins — Terminal-Bench 2.0 at 82.7% vs Opus 4.7's 69.4%, OSWorld-Verified, BrowseComp — are real wins, but they cluster around terminal-heavy and browser-automation use cases, not broad software engineering.
The full competitive picture, including where Gemini 3.1 Pro, DeepSeek V4, and open-source models like GLM-5.1 sit relative to both, is in the April + May 2026 AI model leaderboard — which covers every major frontier model with consistent benchmark data.
GPT-5.5 vs Claude Opus 4.7: Benchmark Comparison
Here is the full head-to-head data as of April 2026. Green cells indicate the leader. Pricing is per million tokens.
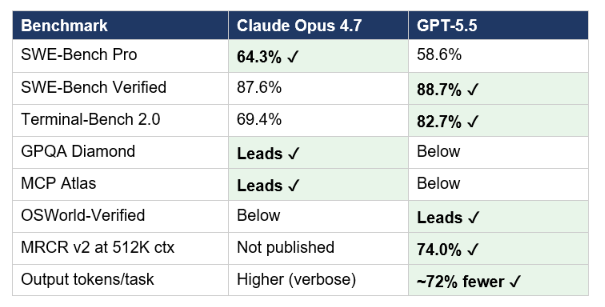
The key insight from this table: Opus 4.7 leads on the coding benchmarks that require sustained multi-step reasoning (SWE-Bench Pro), while GPT-5.5 leads on terminal-heavy tool use and long-context retrieval. The token efficiency gap is structural — GPT-5.5 generates roughly 72% fewer output tokens on equivalent Codex tasks, which partially offsets its higher output price ($30 vs $25 per million tokens).
For the complete GPT-5.5 pricing breakdown — including the math on whether token efficiency actually makes it cheaper than Opus 4.7 at different usage volumes — the GPT-5.5 full review and pricing analysis covers every scenario with real numbers.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Why Developers Are Switching — and What the Spend Data Shows
The spending data in the original report is real signal, not noise: one team ran $4,642 on GPT-5.5 versus $640 on Claude Opus 4.7 in a single week — and preferred GPT-5.5 despite its higher cost. That spending ratio reflects deliberate preference, not accident.
The developer community reactions are directionally consistent: @Jaytel posted "4.7 is completely unusable." @kapilsuham wrote that he has both Codex and Claude Code "but lately I am using Codex almost every time for everything." @rnd_neo_bot_end described Claude as "shallower than before, less persistent, more unstable midway through tasks." These are not niche complaints from people who disliked Claude to begin with. They are from heavy Claude users describing a specific change in behavior.
At the same time, @TechWithMatteo noted "Sonnet 4.6 has been solid for me lately, maybe depends a lot on the type of tasks." @OliverMolander observed: "Vibes change incredibly fast in the AI world. Codex now growing faster than Claude Code. This is great for users." Both are accurate.
The honest read on the switching behavior: developers who rely on agentic, terminal-heavy, or long multi-file coding sessions experienced a real degradation in Opus 4.7 that made GPT-5.5 + Codex competitive for the first time. Developers doing structured knowledge work, PM tasks, or non-agentic coding often report Opus 4.7 as an improvement over 4.6.
For developers evaluating open-source cost alternatives — where the switching cost is even lower — GLM-5.1 at $1.40/M input tokens achieves approximately 94.6% of Claude Opus 4.6's overall coding benchmark performance under an MIT license.
What Anthropic Said and Did
Anthropic published a partial postmortem acknowledging bugs affecting output quality. They adjusted the default reasoning level in Claude Code after the malware-flagging reports. They have not published a comprehensive changelog for Opus 4.7 that would let developers distinguish between a regression, a safety update, and prompt sensitivity.
The structural change Anthropic announced for future releases: a narrower-scoped RLHF correction approach, and an internal regression benchmark specifically for agentic multi-step tasks that must pass before any mid-cycle update ships. This is a direct response to the Opus 4.6 mid-cycle regression playing out again with 4.7.
What Anthropic has not done: allowed model version pinning via the API. This is the number one request from developers who experienced the Opus 4.6 mid-cycle regression and don't want to be caught by the same pattern again. Until version pinning ships, developers using Claude on production pipelines cannot guarantee behavioral stability between deploys.
What You Should Actually Do With Your Stack
The decision depends entirely on your workload. Here is the honest breakdown based on the benchmark data and community evidence:
- Stay on Opus 4.7 if: your work is multi-file codebase reasoning, PR review, complex architectural refactors, or knowledge-heavy tasks where output accuracy matters more than speed. Opus 4.7 leads on SWE-Bench Pro by 5.7 points. For work where getting the code right matters more than getting it fast, Claude is still the right default.
- Switch to Codex + GPT-5.5 if: your work is terminal-heavy DevOps, CI/CD automation, or agentic pipelines where you need high throughput and token efficiency. GPT-5.5 leads Terminal-Bench 2.0 by 13.3 points and uses 72% fewer output tokens on Codex tasks.
- Use both (driver/worker pattern) if: you have mixed workloads. The pattern gaining traction among advanced teams: Claude Code (Opus 4.7) as the architect and planner, Codex (GPT-5.5) as the executor. Claude plans the work, Codex runs the code, results come back to Claude for reasoning. This extracts the best of both models.
- Use Sonnet 4.6 if: you were using Opus 4.7 for general coding and hit the regression. Sonnet 4.6 at $3/$15 per million tokens scores 79.6% on SWE-Bench Verified — within 8 points of Opus 4.7 at 40% of the cost. For most teams, it is the better default right now.
If cost is the primary constraint, the Kimi K2.6 comparison covering open-weight alternatives covers models that compete with Opus 4.6-level performance at dramatically lower pricing — including K2.6 at 58.6% SWE-Bench Pro with 300 parallel agents for free.
For implementation patterns to evaluate these models on your own codebase before committing, the multi-agent orchestration notebooks in the gen-ai-experiments repository include evaluation harnesses you can adapt for side-by-side testing of Opus 4.7 and GPT-5.5 on your specific tasks.
Frequently Asked Questions
Is Claude Opus 4.7 worse than Opus 4.6 for coding?
It depends on the task. For agentic, terminal-heavy, and long multi-step coding sessions, Opus 4.7 shows documented regressions: reduced persistence, the RLHF-induced malware-flagging behavior in Claude Code (since patched), and effective cost inflation from the tokenizer change. For complex multi-file reasoning and PR review, Opus 4.7 is measurably better — SWE-Bench Pro jumped 10.9 points from 53.4% to 64.3%.
What exactly changed in the Claude Opus 4.7 tokenizer?
Anthropic updated the tokenizer architecture in Opus 4.7. The listed price per million tokens is unchanged from Opus 4.6 ($5 input, $25 output). In practice, code-heavy and structured-data-heavy prompts consume 20–35% more tokens on identical inputs under the new tokenizer. This is not a price increase in the literal sense but functions as one for most developer workloads.
Why did Claude Code flag my code as malware after the Opus 4.7 update?
This was a documented bug caused by safety RLHF spillover. Anthropic's post-launch safety updates use reinforcement learning to correct specific failure categories. A targeted update produced spillover effects that caused Claude Code to flag routine file operations, network calls, and standard library usage as potentially harmful. Anthropic acknowledged the issue and adjusted the default reasoning level in Claude Code. The behavior should be resolved in the current deployment.
Is GPT-5.5 better than Claude Opus 4.7 for coding in 2026?
GPT-5.5 leads on terminal-heavy agentic tasks: Terminal-Bench 2.0 at 82.7% versus Opus 4.7's 69.4%, plus better token efficiency (72% fewer output tokens on Codex tasks). Claude Opus 4.7 leads on multi-file software engineering: SWE-Bench Pro at 64.3% versus GPT-5.5's 58.6%, plus GPQA Diamond and MCP Atlas. The correct answer is workload-specific. For DevOps and pipeline automation, GPT-5.5 + Codex. For complex PR review and architectural refactors, Opus 4.7.
Should I switch from Claude Code to Codex?
If your workload is terminal-heavy, token-cost-sensitive, or agentic with high throughput requirements, yes — test Codex with GPT-5.5. If your workload is complex multi-file coding, architectural reasoning, or long-context technical work, stay on Claude Code with Opus 4.7 or drop to Sonnet 4.6 for cost efficiency. The most sophisticated teams run both in a driver/worker pattern: Claude Code plans, Codex executes.
Can I pin a model version in the Claude API to avoid mid-cycle regressions?
Not yet. Model version pinning is the most-requested feature from developers who experienced both the Opus 4.6 mid-cycle regression and the Opus 4.7 launch regression. Anthropic has not announced a pinning mechanism as of May 2026. The current workaround is to maintain a separate evaluation suite, run it after every Claude release, and have a rollback plan to Sonnet 4.6 or Opus 4.6 if regressions are detected.
What is Anthropic's response to the Opus 4.7 backlash?
Anthropic published a partial postmortem acknowledging output quality bugs, adjusted Claude Code's default reasoning level to address the malware-flagging issue, and announced structural changes to their post-launch safety update process for future releases. They have committed to narrower-scoped RLHF corrections with explicit holdout testing on agentic tasks, and an internal regression benchmark that must pass before mid-cycle updates ship. A comprehensive public changelog for Opus 4.7 has not been published.
Recommended Blogs
- GPT-5.5 Review: Benchmarks, Pricing & Vs Claude (2026) — buildfastwithai.com
- Best AI Models April + May 2026 Leaderboard (GPT-5.5, Claude Opus 4.7, DeepSeek V4) — buildfastwithai.com
- Best AI Models April 2026: GPT-5.5, Claude & Gemini Compared — buildfastwithai.com
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 (2026) — buildfastwithai.com
- Kimi K2.6 vs GPT-5.4 vs Claude Opus: Who Wins? (2026) — buildfastwithai.com
- GLM-5.1: #1 Open Source AI Model? Full Review (2026) — buildfastwithai.com
- Best AI for Coding 2026: Nemotron vs GPT-5.3 vs Opus 4.6 — buildfastwithai.com
References
- Anthropic — Claude Opus 4.7 Release (April 16, 2026)
- OpenAI — Introducing GPT-5.5 (April 23, 2026)
- Xlork — Claude Opus 4.7: What's New and Why Developers Are Frustrated
- Startup Fortune — Developers Reporting Claude Opus 4.7 Coding Regressions
- MindStudio — Claude Opus 4.7 vs GPT-5.5: Which Model Should You Build On?
- LLM Stats — GPT-5.5 vs Claude Opus 4.7 Full Comparison
- DataCamp — GPT-5.5 vs Claude Opus 4.7: Real-World Comparison
- Lushbinary — GPT-5.5 vs Claude Opus 4.7: Benchmarks, Pricing & Coding
- Medium (Raian) — Why I Really Hate Claude's New Update, Opus 4.7
Builder.io — Codex vs Claude Code: Which Is the Better AI Coding Agent?

