





Best AI Models June 2026: Full Ranked Leaderboard, Benchmarks and Comparisons
Two hundred and fifty-five model releases landed in Q1 2026 alone. That is roughly three significant releases per day. By June 2026, the AI model landscape has fractured beyond any single winner: there is a top coding model, a top reasoning model, a top open-source model, a top multimodal model, and a top value model, and none of them are the same system. If you are still using the same model you picked six months ago, you are almost certainly leaving performance and money on the table.
This is the June 2026 comprehensive leaderboard. It covers every model that matters right now: Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro, Grok 4.3, DeepSeek V4 Pro, Kimi K2.7 Code, GLM-5.2, MiniMax M3, NVIDIA Nemotron 3 Ultra, Qwen 3.7 Max, Llama 4 Scout, and more. Every benchmark number is sourced and attributed. Every comparison is honest about what has been independently verified versus what is vendor-reported. For the previous month's full breakdown, the May 2026 AI model leaderboard at Build Fast with AI tracks the shifts release by release. What follows is the June 2026 update.
1. The June 2026 AI Landscape: What Changed Since May
Three things define the June 2026 model landscape that were not true in May.
First, Claude Opus 4.8 arrived on May 28, 2026 and immediately retook the top of the Artificial Analysis Intelligence Index with a score of 61.4, its highest ever, pulling ahead of GPT-5.5 at 60.2. It also reclaimed the GDPval-AA Elo at 1,890, 121 points ahead of GPT-5.5 in second. This is the first time since April that Anthropic held the top position across both benchmarks simultaneously.
Second, the open-source field shipped three significant models in the first two weeks of June alone: MiniMax M3 (June 1, 1 million token context, 59.0% SWE-bench Pro), NVIDIA Nemotron 3 Ultra (June 4, 550 billion parameters, fully permissive license), and Kimi K2.7 Code (June 12, 1 trillion parameters, 30% fewer thinking tokens than K2.6). On top of those, GLM-5.2 from Z.ai landed on June 13 with a 1 million token context window. The open-source field is not just competitive with the frontier on specific benchmarks; it is now shipping faster.
Third, the pricing floor has moved again. DeepSeek V4 Flash, released April 24, reset the low-cost agent market with a 0.28 dollar per million output token price, and MiniMax M3 launched at 1.20 dollars per million output tokens for a model that scores 59.0% on SWE-bench Pro. The gap between what a dollar buys in raw coding performance versus what it bought at the start of 2026 has roughly doubled. For the comprehensive breakdown of every open-source LLM release and how they stack up, the Build Fast with AI leaderboard collection tracks every change with sourced benchmark numbers.
2. The June 2026 Master Leaderboard: All Models Ranked
The table below reflects the June 15, 2026 snapshot. AA Index = Artificial Analysis Intelligence Index. All benchmark scores are third-party verified unless marked with (*) which indicates vendor-reported first-party numbers. Prices are per 1 million tokens (input / output) from official API pages.
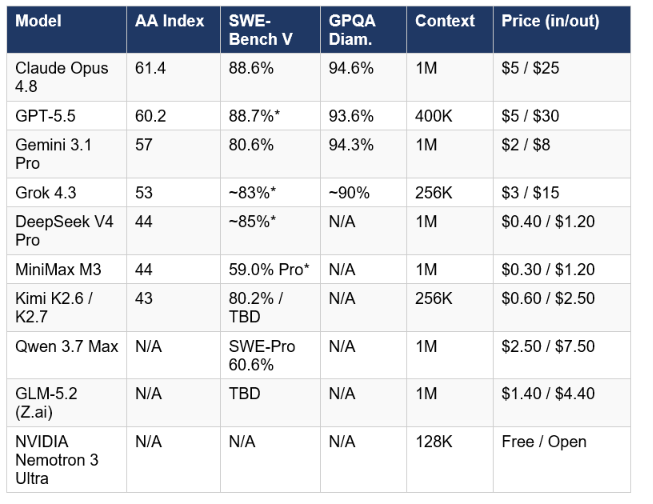
* = vendor-reported, not independently verified on all benchmarks. TBD = benchmark result pending at time of writing (June 15, 2026). SWE-Bench V = SWE-bench Verified. SWE-Pro = SWE-bench Pro (harder). AA Index = Artificial Analysis Intelligence Index v4.1.
3. Closed Frontier Models: Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro, Grok 4.3
Claude Opus 4.8 - The June 2026 Overall Leader
Released May 28, 2026, Claude Opus 4.8 is Anthropic's current flagship and the top model on the Artificial Analysis Intelligence Index at 61.4, the highest score any released model has achieved. It leads on both the GDPval-AA economic task benchmark (Elo 1,890) and retakes the top coding position across SWE-bench Verified (88.6%) and SWE-bench Pro. The model carries Anthropic's largest context window at 1 million tokens, matching Gemini 3.1 Pro.
The hallucination profile is the most careful of any frontier model: 35.9% hallucination rate and 46.6% accuracy on AA-Omniscience, with early testers specifically noting it flags uncertainty instead of making unsupported claims. This calibration stability, held across two full flagship generations, is Anthropic's clearest differentiator from GPT and Gemini on high-stakes enterprise tasks.
Weakness: at 5 dollars per million input tokens and 25 dollars per million output tokens, it is the most expensive model in the Anthropic lineup and 5x to 8x more expensive than comparable open-source performers on coding tasks. Teams running high-volume agent workflows need to run the math carefully before committing to Opus 4.8 as their primary model.
One thing to plan around: Anthropic has confirmed that Mythos-class models are expected for general availability within weeks. Mythos Preview is currently restricted to roughly 50 Project Glasswing partner organizations for defensive cybersecurity work. When Mythos ships publicly, Opus 4.8 will shift to mid-range positioning. If you are making infrastructure decisions today, plan for a Mythos tier above Opus 4.8 within the next 4 to 8 weeks.
GPT-5.5 - The Terminal Agent Champion
Released April 23, 2026, GPT-5.5 is OpenAI's current flagship and the strongest model for terminal-native agentic workflows, scoring 82.7% on Terminal-Bench 2.0. Its Artificial Analysis Intelligence Index score of 60.2 puts it 1.2 points behind Claude Opus 4.8. On SWE-bench Verified, OpenAI reports 88.7% while independent trackers show approximately 82.6%, reflecting a methodology gap worth acknowledging.
GPT-5.5 is the right choice when your primary workload lives in the terminal or in Codex CLI. The 82.7% Terminal-Bench score is the highest of any verified model and reflects genuine engineering focus on agentic command-line execution. Where it falls behind Opus 4.8: GPQA Diamond reasoning (93.6% vs Opus 4.8's 94.6%), GDPval-AA economic task Elo (second to Opus 4.8's 1,890), and the hallucination calibration story. For a full head-to-head breakdown between Claude Code and Codex CLI, the Claude Code vs Codex comparison covers every benchmark and pricing scenario in detail.
Pricing: 5 dollars per million input tokens, 30 dollars per million output tokens. GPT-5.5 is slightly more expensive than Claude Opus 4.8 on output, which matters significantly for high-output agentic applications. Context window is 400,000 tokens, smaller than both Opus 4.8 and Gemini 3.1 Pro's 1 million.
Gemini 3.1 Pro - The Reasoning and Multimodal Winner
Released February 2026, Gemini 3.1 Pro holds the Artificial Analysis Intelligence Index score of 57, third behind Opus 4.8 and GPT-5.5. Its strength is concentrated in reasoning (leading GPQA Diamond at 94.3%, ahead of both Claude and GPT-5.5 in some evaluations) and multimodal capabilities, where it leads the frontier with native processing of text, images, video, and audio in a single model.
The 1-million-token context window and 2 dollar per million input token pricing (4 dollars per million output) make Gemini 3.1 Pro the highest-value closed frontier model in June 2026. You get a model within 4 points of Claude Opus 4.8 on most reasoning benchmarks at less than half the price. For data analysis pipelines, research synthesis, and multimodal workflows, Gemini 3.1 Pro is the rational choice that most teams underweight because of brand familiarity with Claude or GPT.
The honest criticism: Gemini 3.1 Pro's coding performance, while strong, does not match Claude Opus 4.8 or GPT-5.5 on SWE-bench Pro, and its hallucination rate is higher than Anthropic's models on calibrated knowledge tasks.
Grok 4.3 - The Budget Frontier Pick
Released April 30, 2026, Grok 4.3 holds the Artificial Analysis Intelligence Index score of 53, fourth in the frontier ranking. It is the cheapest closed frontier model at approximately 3 dollars per million input tokens, with strong scores on agentic and tool-use benchmarks. The key limitation is the 256,000-token context window, considerably smaller than the three models above it. Grok 4.3 Beta also has feature paywalling: its strongest capabilities require the 300 dollar per month SuperGrok Heavy tier, which creates a confusing pricing structure for teams trying to evaluate it seriously.
Best fit: teams that are price-sensitive on input tokens and whose workloads fit within a 256K context window. Not the right choice for very long-context or enterprise knowledge tasks where Gemini 3.1 Pro at a similar price delivers better performance.
4. Open-Source and Open-Weight Leaders in June 2026
Kimi K2.7 Code - Moonshot AI's Token-Efficient Coding Model
Released June 12, 2026, Kimi K2.7 Code is the most recent major open-source model release and the most efficient coding model in the K2 family. Built on the same 1 trillion parameter MoE architecture as K2.6, it activates 32 billion parameters per token and delivers roughly 30% fewer reasoning tokens than K2.6 while scoring higher on Moonshot's internal coding benchmarks. The detailed architecture and benchmark breakdown is covered in our Kimi K2.7 Code full review. The headline: 81.1% on MCP Mark Verified tool-use accuracy, beating Claude Opus 4.8's 76.4% on the same benchmark, at a price of 0.95 dollars per million input tokens. Independent SWE-bench scores are still pending as of June 15, 2026.
Key spec: 256K context window, Modified MIT license, mandatory thinking mode (cannot be disabled). Available on Hugging Face at moonshotai/Kimi-K2.7-Code and via Kimi API. Supports Cline, RooCode, OpenCode, and vLLM deployment.
GLM-5.2 - Z.ai's 1 Million Token Context Flagship
Released June 13, 2026, GLM-5.2 is Z.ai's newest flagship, landing one day after Kimi K2.7 Code and headlined by a usable 1 million token context window, the largest of any open-source model currently available. It inherits the 744 billion parameter MoE architecture (40 billion active per token) from the GLM-5 family and adds two new thinking-effort levels: High and Max. The full GLM-5.2 architecture and benchmark context is covered in our GLM-5.2 review. At launch, GLM-5.2 is available to GLM Coding Plan subscribers, with open weights and standalone API access announced for the following week. It will be released under MIT license. Priced at approximately 1.40 dollars per million input tokens, 4.40 dollars per million output tokens through the Z.ai international API.
Predecessor context: GLM-5.1, released April 7, 2026, was the first open-weight model to top the SWE-bench Pro leaderboard at 58.4%, holding that position for nine days before Claude Opus 4.7 reclaimed it. GLM-5.2's 5x context expansion (200K to 1M tokens) is the largest single jump in context window of any model in the June 2026 field.
MiniMax M3 - The Open-Source Model Nobody Saw Coming
Released June 1, 2026, MiniMax M3 is the open-weight model that has generated the most discussion in early June, primarily because it arrived with a 59.0% SWE-bench Pro score (if independently confirmed, this would exceed GPT-5.5 and Gemini 3.1 Pro on that benchmark) alongside a 1 million token context window, native image and video input, and a price of 0.30 dollars per million input tokens and 1.20 dollars per million output tokens.
The Artificial Analysis Intelligence Index places MiniMax M3 at 44, tied with DeepSeek V4 Pro and making it the top-ranked open-weight model on the AA Index. The MiniMax Sparse Attention architecture enables the 1M context window while maintaining efficient inference. The license and deployment terms have not attracted the same level of scrutiny as the Kimi or DeepSeek licenses yet, which is worth verifying before production deployment.
NVIDIA Nemotron 3 Ultra - The Permissively Licensed Giant
Released June 4, 2026, NVIDIA Nemotron 3 Ultra is a 550 billion parameter model (55 billion active) that stands out for one specific reason: it is the most capable open model under a fully permissive license at its scale. While Kimi K2.7, GLM-5.2, and Kimi K2.6 all use Modified MIT licenses with commercial thresholds, Nemotron 3 Ultra ships with clean permissive terms that allow commercial use with no user count or revenue thresholds. For enterprise teams with compliance constraints around the Modified MIT license terms used by Chinese AI labs, Nemotron 3 Ultra is the highest-capability alternative.
DeepSeek V4 Pro - The Value Champion
Released April 24, 2026, DeepSeek V4 Pro is a 1.6 trillion parameter MoE model (49 billion active) with a 1 million token context window, available under MIT license. At 0.40 dollars per million input tokens and 1.20 dollars per million output tokens, it delivers a verified approximately 85% on SWE-bench Verified at one of the lowest prices in the frontier-equivalent tier. The Hybrid Attention Architecture (Compressed Sparse Attention plus Heavily Compressed Attention) achieves only 27% of single-token inference FLOPs and 10% of KV cache compared to the previous V3.2 at 1M context, making it genuinely more efficient for long-context production workloads.
The reason DeepSeek V4 Pro is not the top recommendation for every budget-conscious team: the MIT license comes with the same geopolitical risk profile as all DeepSeek models, and some enterprise legal teams have flagged uncertainty about ongoing compliance with US export regulations. For teams where that is not a constraint, it is the clearest value-per-benchmark play in the open-source field.
Qwen 3.7 Max - Alibaba's Knowledge Champion
Qwen 3.7 Max is Alibaba's latest flagship from the Qwen 3.7 series, carrying the highest knowledge scores of any model in the comparison at 71.2 average on knowledge benchmarks versus DeepSeek V4 Pro's 66.1. On SWE-bench Pro, Qwen 3.7 Max scores 60.6% versus DeepSeek V4 Pro's 55.4%, the larger margin of any single benchmark comparison between the two. The 1 million token context window and agentic capabilities (35-hour continuous operation benchmark with 1,158 tool calls in a single session) make it genuinely competitive for long-horizon tasks. The primary disadvantage versus DeepSeek V4 Pro is pricing: at 2.50 dollars per million input tokens and 7.50 dollars per million output tokens, it is roughly 6x more expensive per output token than DeepSeek V4 Pro.
Llama 4 Scout - The Long-Context Open-Source Leader
Meta's Llama 4 Scout holds the largest context window of any model in the June 2026 landscape at 10 million tokens, four times larger than the 1 million token window of Claude Opus 4.8 and Gemini 3.1 Pro. Available under MIT license with Meta's community terms, it is free to self-host and is the top pick for applications that need to process book-length documents, massive codebases, or multi-year conversation histories in a single context. Raw reasoning scores are lower than the frontier closed models at approximately 80% GPQA Diamond. For the hands-on open-source coding comparison across GLM-5.1, Kimi K2.6, and Qwen 3.7, see the Qwen vs GLM vs Kimi Chinese AI coding comparison for task-specific guidance.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Model Comparisons: Head-to-Head Across Six Task Categories
No single model wins everything in June 2026. The leaderboard has fractured by task. The table below records the top performers per category with the specific metric used.
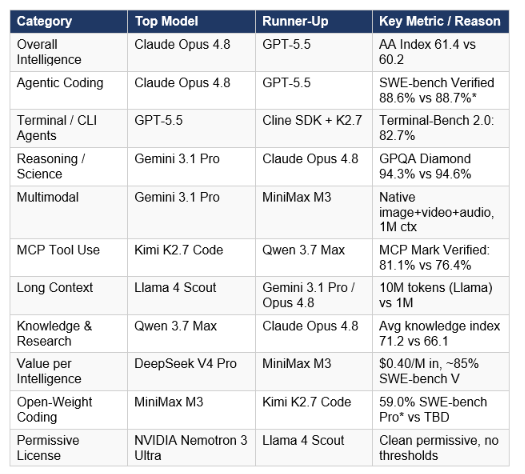
Hot take: the most underrated model in this table is Gemini 3.1 Pro. It wins reasoning, leads multimodal, holds a 1M context window, and costs 2 dollars per million input tokens. The only reason it is not the consensus recommendation is that Claude's brand dominance in developer tooling creates selection bias toward Opus 4.8. If you are choosing primarily on benchmarks and price, Gemini 3.1 Pro is the strongest argument against Opus 4.8 for most tasks.
6. Pricing Comparison: Cost-Per-Intelligence Across All Major Models
The numbers below are confirmed from official API pages as of June 15, 2026. All prices are per million tokens.
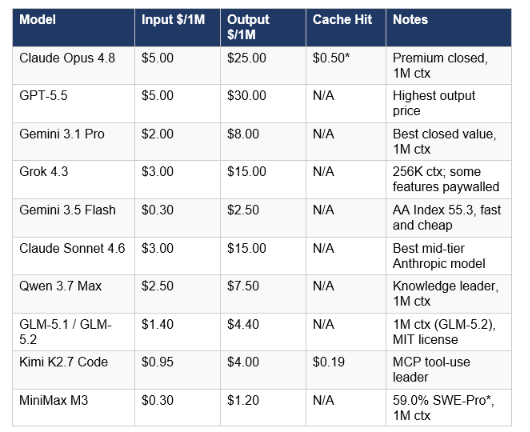
The cost-per-intelligence math has fundamentally changed in June 2026. In January 2026, running a production-grade coding agent required either paying Claude or GPT prices or accepting significant performance degradation. In June 2026, MiniMax M3 at 1.20 dollars per million output tokens and DeepSeek V4 Pro at 1.20 dollars per million output tokens both post credible SWE-bench scores within 3 to 5 points of the closed frontier. For a deeper dive into the open-source models driving this cost compression, the Kimi K2.6 vs GPT-5.5 head-to-head from May 2026 is the most comprehensive pricing analysis across the Chinese open-source models.
7. Category Winners: Best Model for Every Use Case
Best for Complex Agentic Coding
Claude Opus 4.8. The 88.6% SWE-bench Verified score, combined with the 1M context window and Anthropic's track record on multi-file, multi-step engineering tasks, makes it the right default for teams where coding output quality is non-negotiable and budget is not the primary constraint. The caveat is the Mythos timing: if you are signing a long-term contract on Opus 4.8, confirm your pricing for when Mythos ships.
Best for Terminal and CLI Agent Work
GPT-5.5 via Codex CLI. The 82.7% Terminal-Bench 2.0 score is independently verified and reflects genuine engineering investment in headless, command-line execution workflows. For teams who live in the terminal and want the tightest integration with OpenAI's tooling ecosystem, GPT-5.5 is the clear choice.
Best Value Closed Model
Gemini 3.1 Pro. At 2 dollars per million input tokens with a 1M context window, 80.6% SWE-bench Verified, and the top position on several reasoning benchmarks including GPQA Diamond, it delivers more capability per dollar than any other closed model. The multimodal lead makes it even stronger for teams processing images, video, or audio alongside text.
Best Open-Source Model for Production Coding
MiniMax M3 (if its 59.0% SWE-bench Pro score is confirmed independently) or Kimi K2.7 Code for MCP-tool-heavy workflows. Both sit at comparable pricing around 1.20 dollars per million output tokens. For teams that are already using Kimi K2.6 and want a drop-in upgrade with better token efficiency, K2.7 Code is the easier transition. For teams starting fresh, wait for MiniMax M3's independent SWE-bench verification. For a detailed walkthrough of deploying either of these in Cline, Claude Code, or OpenCode, the gen-ai-experiments cookbook repository has notebooks that map directly to both models.
Best for Long Context
Llama 4 Scout for open-source (10M tokens, free to self-host). Claude Opus 4.8 or Gemini 3.1 Pro for closed models (both 1M tokens). GLM-5.2 for Chinese open-source (1M tokens, MIT license pending, competitive pricing).
Best for Budget High-Volume Agents
DeepSeek V4 Flash at 0.28 dollars per million output tokens with a verified 79.0% SWE-bench Verified score is the most cost-effective option for any team running high-frequency inference loops where quality above that threshold is acceptable. MiniMax M3 at 1.20 dollars per million output tokens is the step up if you need stronger performance. Our GLM-5.1 open-source review explains when paying for the Z.ai premium over DeepSeek's lower price makes sense for structured output and hallucination-sensitive tasks.
8. What to Expect in July and August 2026
Four developments are worth planning around before the July update.
- Claude Mythos public release: Anthropic has confirmed Mythos-class capabilities are expected for general availability within weeks of the Opus 4.8 launch. When Mythos ships, it will become the new top-tier Anthropic model and Opus 4.8 will be repositioned as mid-tier, likely with a price adjustment. This will shift the leaderboard meaningfully at the top.
- Independent benchmarks for June's open-source models: MiniMax M3's 59.0% SWE-bench Pro score and GLM-5.2's benchmark performance are both still pending independent verification as of mid-June. When SWE-bench Pro and Terminal-Bench 2.0 results land for these models, the open-source rankings could shift significantly in either direction.
- DeepSeek R2: Multiple infrastructure and deployment guides reference DeepSeek R2 as the expected reasoning-focused successor to R1, likely in Q3 2026. If DeepSeek's pattern holds, R2 will target the scientific reasoning benchmarks where Gemini 3.1 Pro and Claude Opus 4.8 currently lead.
- Kimi K3: Multiple sources have referenced a 3 to 4 trillion parameter Kimi K3 as the next major architecture jump from Moonshot AI, potentially landing in Q3 2026. Given that K2.6 and K2.7 Code are post-training refinements of the K2 MoE backbone, K3 would represent a genuine scale-up with potentially frontier-matching benchmark results.
The meta-trend that overrides all of these: the release cadence is now so fast that any infrastructure decision made on a single model's current performance has a 30 to 60 day shelf life. The teams winning in this environment are not the ones who found the best model. They are the ones who built model-agnostic infrastructure that can swap providers in a configuration change rather than a code rewrite.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Frequently Asked Questions
What is the best AI model in June 2026?
As of June 15, 2026, Claude Opus 4.8 leads the Artificial Analysis Intelligence Index at 61.4 and the GDPval-AA economic task benchmark with a 1,890 Elo. However, there is no single best model for all tasks. GPT-5.5 leads Terminal-Bench 2.0, Gemini 3.1 Pro leads multimodal and GPQA Diamond reasoning, and DeepSeek V4 Pro leads on value per benchmark point. The right model depends entirely on your workload.
Is Claude Opus 4.8 better than GPT-5.5?
On overall intelligence (AA Index 61.4 vs 60.2) and GDPval-AA economic tasks, Claude Opus 4.8 leads. GPT-5.5 leads on Terminal-Bench 2.0 (82.7% vs no published Opus 4.8 score) and SWE-bench Verified if using OpenAI's reported 88.7% (vs Opus 4.8's 88.6%). Both are within 1 point on SWE-bench Verified. The honest answer: Opus 4.8 for most production coding and knowledge tasks; GPT-5.5 for terminal-native agentic workflows.
What is the best open-source AI model in June 2026?
MiniMax M3 (released June 1, 2026) leads the Artificial Analysis Intelligence Index among open-weight models at 44, tied with DeepSeek V4 Pro, with a reported 59.0% SWE-bench Pro score pending independent verification. Kimi K2.7 Code leads on MCP tool-use accuracy (81.1% on MCP Mark Verified). DeepSeek V4 Pro leads on verified benchmark scores at the lowest commercial API price. For permissive licensing with no commercial thresholds, NVIDIA Nemotron 3 Ultra is the top option.
Which AI model is best for coding in 2026?
For the best results regardless of cost: Claude Opus 4.8 (88.6% SWE-bench Verified, 1M context, top coding agent performance). For the best open-source coding value: MiniMax M3 or Kimi K2.7 Code at roughly 1.20 dollars per million output tokens. For terminal-native agentic coding: GPT-5.5 via Codex CLI (82.7% Terminal-Bench 2.0). For the lowest cost above 79% SWE-bench Verified: DeepSeek V4 Flash at 0.28 dollars per million output tokens.
What AI models were released in June 2026?
The major June 2026 releases as of June 15: MiniMax M3 (June 1, open-weight, 1M context, 59.0% SWE-bench Pro*); NVIDIA Nemotron 3 Ultra (June 4, 550B parameters, permissive license); Kimi K2.7 Code (June 12, 1T MoE, 30% lower thinking tokens); GLM-5.2 (June 13, 1M context, High and Max effort modes); Gemini-SQL2 (June 12, Google's text-to-SQL capability). Claude Opus 4.8 shipped May 28 and is the dominant model entering June.
How does Gemini 3.1 Pro compare to Claude Opus 4.8?
Gemini 3.1 Pro leads on GPQA Diamond reasoning (94.3% vs Opus 4.8's 94.6%, effectively tied) and multimodal capability (native image, video, audio). Claude Opus 4.8 leads on overall intelligence (AA Index 61.4 vs 57), SWE-bench coding, and hallucination calibration. Gemini 3.1 Pro costs 2 dollars per million input tokens versus Opus 4.8's 5 dollars, a 2.5x price advantage with comparable performance on most tasks. For most teams, Gemini 3.1 Pro is the stronger value choice unless specific Anthropic capabilities like Claude Code integration or Mythos-tier access are required.
What is the best cheap AI model in 2026?
For the cheapest model with acceptable coding quality: DeepSeek V4 Flash at 0.14 dollars per million input tokens and 0.28 dollars per million output tokens, with a verified 79.0% SWE-bench Verified score. For more capable performance at a low price: MiniMax M3 at 0.30 dollars per million input tokens and 1.20 dollars per million output tokens, or DeepSeek V4 Pro at 0.40 and 1.20. For completely free self-hosting: Llama 4 Scout or NVIDIA Nemotron 3 Ultra under their permissive licenses.
Is DeepSeek V4 Pro better than GPT-5.5?
On coding benchmarks where both have independent scores, DeepSeek V4 Pro is closer to GPT-5.5 than the price gap suggests: approximately 85% on SWE-bench Verified versus GPT-5.5's 82.6 to 88.7% depending on the methodology. On Terminal-Bench 2.0 and creative tasks, GPT-5.5 leads clearly. DeepSeek V4 Pro is 12x cheaper per output token. For most high-volume coding workloads where the 5 to 10 point quality gap is acceptable, DeepSeek V4 Pro at 1.20 dollars per million output tokens is the rational economic choice. For the tasks where that gap is not acceptable (senior engineering code review, complex multi-file refactors, research-grade tasks), GPT-5.5 or Claude Opus 4.8 justify the premium.
Recommended Blogs
- Best AI Models: April + May 2026 Leaderboard (GPT-5.5, Claude Opus 4.7, DeepSeek V4)
- Kimi K2.7 Code Review 2026: 1T Coding Model Tested
- GLM-5.2 Review 2026: Z.ai's New 1M-Context Flagship AI Model
- Kimi K2.6 vs Qwen 3.6 vs Opus 4.7 vs GPT-5.5: Which Wins? (2026)
- GLM-5.1 Review: Can It Beat Claude Opus 4.6? (2026)
- Claude Code vs Codex: Which Terminal AI Tool Wins in 2026?
- Best AI Models April 2026: Ranked by Benchmarks
References
- Artificial Analysis - AI Model Leaderboard and Intelligence Index v4.1 (June 2026)
- Build Fast with AI - Best AI Models June 2026 Leaderboard
- Anthropic - Claude Opus 4.8 Launch and Benchmarks (May 28, 2026)
- Moonshot AI - Kimi K2.7 Code Official Model Page
- Hugging Face - moonshotai/Kimi-K2.7-Code Model Card
- DeepInfra - DeepSeek V4 Pro Model Overview, Features and Performance Guide
- MarkTechPost - Moonshot AI Releases Kimi K2.7-Code (June 12, 2026)
- LLM Stats - Comprehensive Leaderboard Score, Pricing, and Metadata (June 2026)
- Felloai - Best AI Models in June 2026: Rankings and Comparisons
- DevTk.AI - AI API Pricing Comparison: 50+ Models Side-by-Side (June 2026)
AI Flash Report - AI Model Release Timeline 2025-2026 (Updated June 2026)

