





Kimi K2.7 Code Review 2026: Full Benchmark Breakdown and Model Comparisons
The open-source coding race just moved again. On June 12, 2026, Moonshot AI released Kimi K2.7 Code on Hugging Face and through the Kimi API, marking the fifth major release in the K2 series in under a year. This is not a new base model. It is a focused coding upgrade built on the Kimi K2.6 foundation, targeting two things that matter most in production agentic workflows: better output on long-horizon coding tasks and fewer tokens burned getting there.
The numbers Moonshot published are directionally exciting: plus 21.8 percent on their Kimi Code Bench v2, plus 11.0 percent on Program Bench, plus 31.5 percent on MLS Bench Lite, and approximately 30 percent lower reasoning-token consumption than K2.6. The honest caveat is that every single one of those numbers comes from Moonshot's own benchmark suites, not from SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, or any independent leaderboard. This review is clear about what has been proven and what is still pending.
Here is what we know with certainty: K2.7 Code runs a 1-trillion-parameter Mixture-of-Experts architecture with 32 billion active parameters per token, a 256K context window, native multimodal input, and mandatory thinking mode. It's priced at 0.95 dollars per million input tokens and 4 dollars per million output tokens, making it roughly 5x cheaper than Claude Opus 4.8. The model weights are open on Hugging Face at moonshotai/Kimi-K2.7-Code under a Modified MIT license. For context on the broader open-source field this release enters, our running open-source LLMs collection tracks every major release across the GLM, Qwen, DeepSeek, and Kimi families in one place.
1. What Is Kimi K2.7 Code and Why Did Moonshot Build It?
Kimi K2.7 Code is the latest iteration of Moonshot AI's K2 series, released June 12, 2026 as a coding-focused, agentic model built directly on top of the Kimi K2.6 architecture. It is not a general-purpose model. Moonshot has been explicit about this: K2.7 Code is designed for long-horizon software engineering tasks, and for general use, K2.6 remains the recommended model in the family.
Moonshot AI is a Beijing-based artificial intelligence company founded in March 2023 by Zhilin Yang, a Tsinghua University alumnus who built the business around the Kimi chatbot. The company is backed by Alibaba and was valued at approximately 4.8 billion dollars as of its last round. Kimi, which launched in October 2023 with a then-groundbreaking 128,000-token context window, now has more than 36 million monthly active users and has expanded its reach from China into global developer communities through the Hugging Face releases that began with the K2 series in mid-2025.
The strategic logic behind K2.7 Code is straightforward. K2.6 established Moonshot as a genuine open-source challenger by posting 80.2 percent on SWE-bench Verified and 58.6 percent on SWE-bench Pro in April 2026. Those numbers made K2.6 the strongest open-source coding model in the world at the time of its release. But the SWE-bench Pro score of 58.6 percent sat right next to Claude Opus 4.7's 64.3 percent and GPT-5.5's terminal-bench dominance. The gap was real. K2.7 Code's job is to close it specifically in coding and agentic use cases, where model efficiency and reasoning-token cost determine whether a team can afford to run the model in production loops without the cost becoming prohibitive.
2. The K2 Family Timeline: From K2 to K2.7 in Under a Year
Understanding K2.7 Code requires understanding the pace Moonshot has maintained. The K2 series has produced five major releases in eleven months, each building on the same trillion-parameter MoE backbone while targeting specific capability gaps.
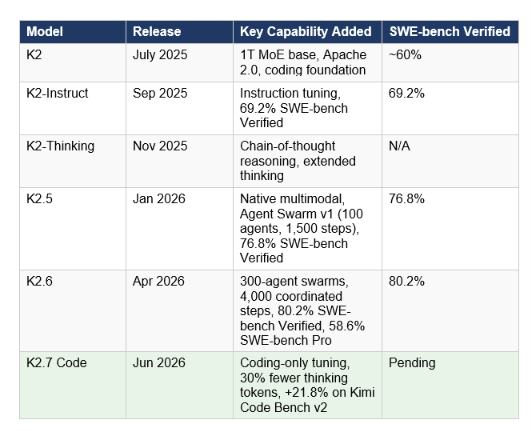
The trajectory is important context for K2.7 Code. Each release has targeted a measurable gap: K2.5 added multimodal and agent swarms, K2.6 scaled the agent system to 300 sub-agents and broke the open-source SWE-bench Pro record, and K2.7 Code bets that token efficiency at the inference layer is now the most meaningful lever available without a full architecture change. That's a sensible hypothesis. Reasoning models burn a substantial share of their output budget on thinking tokens, and in long agentic loops that call the model hundreds of times, a 30 percent reduction in those tokens directly lowers cost and latency for every single step in the workflow.
3. Architecture Deep Dive: 1 Trillion Parameters, 32B Active, MoonViT
Kimi K2.7 Code inherits the same base architecture as K2.5 and K2.6, which means existing deployments can swap weights without reconfiguring the inference stack. That backward compatibility is a meaningful practical benefit for teams already running K2.6 in production.
The architecture is a Mixture-of-Experts design with 1 trillion total parameters and 32 billion activated per token. The model uses 384 experts per layer, with 8 experts selected per token plus 1 shared expert, across 61 transformer layers including 1 dense layer. Attention uses Multi-head Latent Attention, which compresses the KV cache compared with standard multi-head attention, directly reducing the memory overhead of the 256,000-token context window. The feed-forward layers use the SwiGLU activation function.
Vision input comes through MoonViT, a 400 million-parameter vision encoder that handles both image and video inputs. Video input is flagged as experimental through third-party vLLM deployments and is only fully supported through the official Kimi API at launch. MoonViT is what separates Kimi's multimodal capability from most open-source coding models, which still treat vision as bolt-on rather than integrated.
One architectural constraint worth knowing upfront: Kimi K2.7 Code forces thinking mode to true and forces preserve_thinking to true. You cannot disable the thinking trace. If you attempt to override these parameters through the API, you will receive an error. This is by design. The model is built to reason before every tool call and code edit, and disabling that reasoning trace would break the internal chain-of-thought that the model depends on for the improved performance Moonshot reports. The implication for cost budgeting is that you will always pay for thinking tokens, and the 30 percent efficiency gain over K2.6 is your only lever for reducing that fixed overhead.
Native INT4 quantization ships with the model, which is the practical enabler for the hardware requirements. Running K2.7 Code locally via vLLM requires 8 H200 GPUs or an equivalent aggregate VRAM of approximately 640 gigabytes. At 32B active parameters per inference, the actual compute cost is comparable to running a 32B dense model, which is what makes the Kimi API pricing at 0.95 dollars per million input tokens economically viable for a model of this nominal scale.
4. Kimi K2.7 Benchmark Results: What's Confirmed and What's Pending
This section is the most important one to read carefully, because the distinction between what Moonshot published and what has been independently verified is the difference between a buying decision and a bet.
What is confirmed: Moonshot published gains over K2.6 on their own internal benchmarks, run through Kimi Code CLI with thinking enabled at temperature 1.0, top-p 0.95, and the full 262,144-token context length. The comparison models for GPT-5.5 were run in Codex at xhigh mode, and Claude Opus 4.8 was run in Claude Code at xhigh mode.
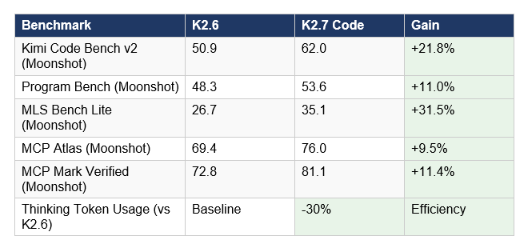
What is NOT yet confirmed: as of June 15, 2026, no independent third-party results exist for K2.7 Code on SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, LiveCodeBench, GPQA Diamond, AIME, or any other public leaderboard that runs all models under the same controlled conditions. The model has not been submitted to DeepSWE either, which is now regarded as one of the more discriminating independent coding benchmarks with a 70-point spread across models compared with SWE-bench Pro's 30-point spread.
The honest interpretation: the Moonshot-reported gains are directionally meaningful and the benchmark methodology is transparent, but Kimi Code Bench v2 is a proprietary benchmark only Moonshot reports. Wait for SWE-bench Pro re-runs before treating these numbers as settled. K2.6 set open-source SOTA at 58.6 on SWE-bench Pro in April 2026, and if K2.7 Code's internal 21.8 percent gain even partially translates to that benchmark, it would meaningfully pressure the closed frontier, but that is an extrapolation from first-party data, not a confirmed result.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Kimi K2.7 vs GPT-5.5: Open Source Against the Frontier
GPT-5.5 is OpenAI's current flagship, released April 23, 2026, and the top performer on terminal-native agentic tasks with an 82.7 percent score on Terminal-Bench 2.0. On SWE-bench Verified, OpenAI reports 88.7 percent while third-party trackers show approximately 82.6 percent. For a full picture of how GPT-5.5 sits in the May 2026 field, our best AI models leaderboard has the most current rankings by task.
On the Moonshot-published benchmarks, the gap between K2.7 Code and GPT-5.5 has narrowed but not closed. On Kimi Code Bench v2, K2.7 Code scores 62.0 versus GPT-5.5's 69.0. On Program Bench, K2.7 Code scores 53.6 versus GPT-5.5's 69.1. That 7-point gap on Kimi's own benchmark and the 15.5-point gap on Program Bench are real, and Program Bench is a particularly stringent test: agents must reproduce a program's behavior using only a compiled binary and its documentation, without source code access, decompilation, or internet search. The fact that GPT-5.5 leads by 15 points on that benchmark suggests the closed frontier still has a meaningful edge on the hardest reasoning-under-constraint scenarios.
Where the comparison shifts is cost and licensing. GPT-5.5 at OpenAI's API costs 5 dollars per million input tokens and 30 dollars per million output tokens. Kimi K2.7 Code costs 0.95 dollars per million input tokens and 4 dollars per million output tokens. That's 5x cheaper on input and 7.5x cheaper on output. In a long agentic loop that burns 10 million output tokens per week, the difference is 380 dollars versus 2,850 dollars per week for the same task volume. At that scale, the remaining performance gap on Program Bench might not be the deciding factor.
The MCP tool-use story is also worth noting. K2.7 Code scores 81.1 on MCP Mark Verified versus GPT-5.5's score of 74.3 on the same benchmark. MCP Mark Verified measures precise tool invocation accuracy across model context protocol connections, which is the exact pattern that matters for agent pipelines that integrate with databases, APIs, and development toolchains. Beating GPT-5.5 on MCP tool accuracy while running at a fraction of the cost is the specific argument Moonshot is making for production agentic workflows.
6. Kimi K2.7 vs Claude Opus 4.8: Tool Use, Context, and Cost
Claude Opus 4.8 is Anthropic's current flagship as of mid-2026, carrying a 1-million-token context window and an 88.6 percent score on SWE-bench Verified. It remains the go-to model for enterprise coding reliability. Our full Kimi K2.6 vs Qwen vs Opus vs GPT-5.5 comparison laid out how the K2 family stacks up across every benchmark that matters for production agentic work, and K2.7 Code's arrival updates that picture on the coding-specific benchmarks.
The most striking data point in the K2.7 Code launch materials is the MCP Mark Verified score: K2.7 Code at 81.1 versus Claude Opus 4.8 at 76.4. That is a 4.7-point lead on an agentic tool-use benchmark, achieved by a model that costs roughly 6x less per output token. Claude Opus 4.8 is priced at 5 dollars per million input tokens and 25 dollars per million output tokens. K2.7 Code is 0.95 and 4 dollars respectively.
Where Opus 4.8 still leads significantly is on MLS Bench Lite, the test that measures a model's ability to invent novel machine learning methods. Opus 4.8 scores 81.3 on this benchmark versus K2.7 Code's 35.1. That 46-point gap is the clearest signal that K2.7 Code is not a replacement for Claude in research and scientific reasoning workloads. The model is tuned for software engineering execution, not research creativity.
The context window difference is also real. Claude Opus 4.8's 1-million-token window is four times K2.7 Code's 256,000-token limit. For workflows that require loading an entire large monorepo or processing hundreds of pages of documentation in a single context, that gap matters. For most standard software engineering workflows, 256,000 tokens is more than sufficient, but teams that have specifically built around Claude's extended context window will find K2.7 Code more limiting.
Honest verdict on K2.7 vs Opus 4.8: if your workload is tool-heavy agentic coding at scale and your budget matters, K2.7 Code is the stronger value. If your workload includes scientific reasoning, very long documents, or you need the highest proven benchmark scores with minimal risk, Claude Opus 4.8 is still the safer choice.
7. Kimi K2.7 vs GLM-5.1 and DeepSeek V4: The Open-Source Rivalry
The most interesting comparison for most developers is not Kimi K2.7 Code against GPT-5.5 or Claude Opus 4.8 - it is Kimi K2.7 Code against the other open-source Chinese AI models competing for the same workloads. The GLM-5.1 Code Arena breakdown established that GLM-5.1 from Z.ai hit 58.4 percent on SWE-bench Pro in April 2026, the highest any open-source agentic coding model had achieved on that benchmark at the time, while also reaching third place on Code Arena with a 1530 Elo, behind only two Claude Opus 4.6 variants.
The GLM-5.1 comparison is the honest open-source rival for K2.7 Code right now. GLM-5.1 scored 58.4 on SWE-bench Pro, K2.6 scored 58.6. K2.7 Code has not yet posted an independent SWE-bench Pro result. On the MCP tool-use side, K2.7 Code claims 81.1 on MCP Mark Verified while GLM-5.1 does not have a published MCP Mark Verified score. The picture is genuinely mixed and the models are targeting similar deployment scenarios from similar starting points.
The clearer differentiation: Kimi K2.7 Code has native multimodal input through MoonViT, a 256K context window, and the 30 percent token-efficiency improvement. GLM-5.1 runs a 200K context window but has demonstrated more reliable structured output and fewer hallucinations in independent evaluations. For teams choosing between them, the practical answer is: test both on your specific task distribution. The benchmark numbers are too close and too incomplete to justify choosing on specs alone.
Against DeepSeek V4 Pro, the comparison is more lopsided in DeepSeek's favor on raw coding benchmarks. DeepSeek V4 Pro posts approximately 85 percent on SWE-bench Verified and costs 0.44 dollars per million input tokens and 0.87 dollars per million output tokens, which is substantially cheaper than K2.7 Code even at K2.7's already competitive pricing. The main advantage K2.7 Code has over DeepSeek V4 is the larger context window (256K versus 128K) and the MCP Mark Verified tool-use lead. For pure cost-per-benchmark-point in coding, DeepSeek V4 Pro currently wins. For tool-heavy agent pipelines that need broader context, K2.7 Code is the stronger choice.
8. Token Efficiency: The 30 Percent Reduction and What It Actually Means
The efficiency story is the most operationally interesting aspect of the K2.7 Code launch, and it is worth unpacking carefully because it compounds in ways the headline number undersells.
Reasoning models generate two types of output tokens: the visible response text and the hidden thinking tokens that constitute the model's internal chain-of-thought. Thinking tokens are generated before every tool call and code edit, and in a long agentic session running hundreds of iterations, they can account for the majority of total token cost. When Moonshot says K2.7 Code uses 30 percent fewer thinking tokens than K2.6 while scoring higher on benchmarks, they are saying the model is generating better answers with a more efficient reasoning process, not that it is reasoning less deeply.
In a concrete production scenario: a coding agent running 500 iterations per day against K2.6 might burn 50 million thinking tokens per day at 4 dollars per million, costing 200 dollars per day in thinking-token overhead alone. At 30 percent lower consumption, that drops to approximately 140 dollars per day, a savings of 60 dollars per day or 1,800 dollars per month from a single efficiency improvement with no code changes required. For teams running larger agent fleets or higher iteration counts, the savings scale proportionally.
The efficiency gain also affects latency. Fewer thinking tokens means faster time-to-first-token-of-actual-response in each iteration. In interactive coding sessions where a developer is waiting for the agent to respond before reviewing and continuing, that latency difference is noticeable. Moonshot specifically reports that the new CLI completes the same tasks faster than K2.6 in internal runs, and the thinking-token reduction is the primary driver of that improvement.
One important technical constraint to understand: because thinking mode is mandatory and cannot be disabled in K2.7 Code, the 30 percent efficiency gain is the only lever available to control thinking-token costs. There is no instant mode in K2.7 Code, unlike in K2.6 and K2.5 where instant mode could skip the thinking trace entirely. Teams that were using instant mode in K2.6 for low-complexity tasks will find K2.7 Code more expensive for those use cases, even with the efficiency improvement.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. Pricing, API Access, and Local Deployment
Kimi K2.7 Code is available through three main access paths, each with different trade-offs on cost, control, and setup complexity.
Kimi API (Managed)
The official Kimi API at platform.moonshot.ai is the simplest entry point. The API is OpenAI-compatible and also provides an Anthropic-compatible endpoint, so you can drop it into most existing LLM client code without switching SDKs.
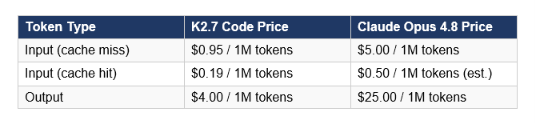
The cache-hit pricing at 0.19 dollars per million is particularly important for production deployments. In agentic loops where the system prompt and tool definitions are constant across many calls, aggressive context caching can reduce effective input token cost by 80 percent or more, making K2.7 Code's real-world cost in cache-heavy agent designs even lower than the headline pricing suggests.
Third-Party Providers
K2.7 Code is available on OpenRouter, Cloudflare Workers AI, and the Vercel AI Gateway, providing redundancy and alternative pricing structures. The open-weight release also means the model will appear on more inference providers as they ingest the Hugging Face weights.
Self-Hosted via vLLM or SGLang
The full model weights at moonshotai/Kimi-K2.7-Code can be deployed locally using vLLM version 0.19.1 or later or SGLang. The verified INT4 setup requires 8 H200 GPUs or equivalent aggregate VRAM of approximately 640 gigabytes. The vLLM command with the correct parsers looks like this:
vllm serve moonshotai/Kimi-K2.7-Code \
--tensor-parallel-size 8 \
--mm-encoder-tp-mode data \
--trust-remote-code \
--tool-call-parser kimi_k2 \
--enable-auto-tool-choice \
--reasoning-parser kimi_k2The kimi_k2 tool-call parser and reasoning parser flags are required. Without them, tool calling and chain-of-thought extraction will not work correctly. Transformers version 4.57.1 or later is required but versions below 5.0.0.
10. How to Use Kimi K2.7 Code: Claude Code, Cline, OpenCode, and vLLM
K2.7 Code is compatible with the major AI coding agents through their OpenAI-compatible provider settings. The model ID to use is kimi-k2.7-code and the base URL is https://api.moonshot.ai/v1.
Claude Code
Configure Claude Code by pointing the Sonnet or Opus model slots at the Kimi API endpoint and setting the model to kimi-k2.7-code in the environment configuration. The recommended effort setting is max for coding tasks, which maps to K2.7 Code's thinking-intensive mode.
Cline and RooCode
In Cline or RooCode settings, select Moonshot AI as the API provider, enter api.moonshot.ai as the base URL, paste your Kimi platform API key, and select kimi-k2.7-code as the model. Disable browser tool usage if your workflow does not require web access, as it can add latency and token cost to each iteration.
OpenCode
opencode auth login
# Select Moonshot AI as the provider
# Enter your Kimi API key opencode
# Select Kimi K2.7 Code from /modelsAPI Call Example (Python)
from openai import OpenAI client = OpenAI(
api_key="your_kimi_api_key",
base_url="https://api.moonshot.ai/v1" )
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[{"role": "user", "content": "Refactor this function to handle edge cases."}],
temperature=1.0,
top_p=0.95,
max_tokens=4096 )Note: do not override temperature below 1.0 or top_p below 0.95 for thinking mode. The recommended parameters match the evaluation conditions Moonshot used for the published benchmarks, and deviating from them can reduce output quality.
11. Strengths, Weaknesses, and Our Honest Verdict
Strengths
Strongest MCP tool-use score among open-source models, beating Claude Opus 4.8 at 81.1 vs 76.4 on MCP Mark Verified
30 percent lower reasoning-token usage than K2.6, directly reducing production cost and latency in agentic loops
Native multimodal input through MoonViT (image and video), rare among open-source coding models
256K context window, larger than GLM-5.1's 200K and DeepSeek V4 Pro's 128K
Open weights on Hugging Face under Modified MIT license, with self-hosting rights for most commercial use cases
OpenAI and Anthropic-compatible API, enabling drop-in replacement in existing agent stacks
Automatic context caching at 0.19 dollars per million cache-hit tokens, making production deployments significantly cheaper in practice
Weaknesses
- No independent benchmark scores at launch. All published results are from Moonshot's own benchmark suites. SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, and Code Arena scores are pending
- Thinking mode cannot be disabled, removing the option to run cheaper instant mode calls for low-complexity tasks
- MLS Bench Lite score of 35.1 versus Opus 4.8's 81.3 confirms this is not a model for research or scientific reasoning tasks
- Local deployment requires 640 GB VRAM in INT4 quantization, which puts it beyond consumer hardware or small GPU clusters
- No separate Instruct or general variant at launch. K2.7 is coding-only; K2.6 remains the recommended general model
- Context window of 256K is 4x smaller than Claude Opus 4.8's 1M window, limiting applicability to very large codebase analysis in single sessions
- Video input is still experimental on third-party API deployments and only fully supported through the official Kimi API
Verdict
Kimi K2.7 Code is the best open-source coding model for MCP tool-use-heavy agent pipelines as of June 2026, priced at a level that makes production scale economically viable. The 30 percent token-efficiency gain over K2.6 is real and operationally meaningful. The benchmark story is incomplete, and teams making architecture decisions should wait for independent SWE-bench Pro and Terminal-Bench 2.0 results before drawing conclusions about where K2.7 Code sits relative to GLM-5.1, DeepSeek V4 Pro, and the closed frontier. For teams that are cost-sensitive, already running K2.6, and specifically targeting tool-integrated agentic workflows, K2.7 Code is worth testing immediately. The model ID is kimi-k2.7-code and the swap from K2.6 is a one-line change. For the full picture of where K2.7 Code fits in the current model landscape, our monthly best AI models guide will be updated as independent benchmark results land.
Frequently Asked Questions
What is Kimi K2.7 Code?
Kimi K2.7 Code is the latest open-source AI coding model from Moonshot AI, released June 12, 2026. It is a coding-focused, agentic model built on the Kimi K2.6 architecture, targeting long-horizon software engineering tasks with improved token efficiency (roughly 30 percent fewer thinking tokens than K2.6) and better performance on Moonshot's internal coding benchmarks. It is available on Hugging Face at moonshotai/Kimi-K2.7-Code under a Modified MIT license.
How does Kimi K2.7 Code compare to GPT-5.5?
On Moonshot's own benchmarks, K2.7 Code has narrowed but not closed the gap with GPT-5.5: 62.0 versus 69.0 on Kimi Code Bench v2 and 53.6 versus 69.1 on Program Bench. GPT-5.5 still leads on Terminal-Bench 2.0 at 82.7 percent (no independent K2.7 number yet). However, K2.7 Code beats GPT-5.5 on MCP Mark Verified tool-use accuracy (81.1 vs 74.3) and is roughly 7x cheaper per output token. For cost-sensitive agent pipelines with heavy tool use, K2.7 Code is the stronger value.
Is Kimi K2.7 Code open source?
Yes. The model weights are published on Hugging Face at moonshotai/Kimi-K2.7-Code under a Modified MIT license that permits commercial use and self-hosting. The modification requires companies exceeding 100 million monthly active users or 20 million dollars in monthly revenue to display Kimi branding. For the vast majority of developers and startups, this functions as standard MIT with full commercial rights.
How many parameters does Kimi K2.7 Code have?
Kimi K2.7 Code has 1 trillion total parameters in a Mixture-of-Experts architecture, with 32 billion parameters activated per token. The model uses 384 experts per layer, selects 8 per token plus 1 shared expert, and runs across 61 layers including 1 dense layer. A 400 million-parameter MoonViT encoder handles image and video inputs.
What benchmark scores did Kimi K2.7 Code achieve?
As of June 15, 2026, Kimi K2.7 Code has been tested only on Moonshot's own benchmark suites: 62.0 on Kimi Code Bench v2 (plus 21.8 percent over K2.6), 53.6 on Program Bench (plus 11.0 percent), 35.1 on MLS Bench Lite (plus 31.5 percent), 76.0 on MCP Atlas, and 81.1 on MCP Mark Verified. Independent SWE-bench Verified, SWE-bench Pro, and Terminal-Bench 2.0 results are pending.
How do I access Kimi K2.7 Code via API?
Get an API key at platform.moonshot.ai. Use the OpenAI-compatible endpoint at https://api.moonshot.ai/v1 with model ID kimi-k2.7-code. Pricing is 0.95 dollars per million input tokens and 4.00 dollars per million output tokens, with cache hits at 0.19 dollars per million. The model is also available on OpenRouter and Cloudflare Workers AI.
Can I run Kimi K2.7 Code locally?
Yes, but hardware requirements are substantial. Self-hosting requires vLLM 0.19.1 or later and approximately 640 GB of VRAM in INT4 quantization, which translates to 8 H200 GPUs or equivalent. You must include the kimi_k2 tool-call parser and reasoning parser flags in your vLLM serve command. Transformers version 4.57.1 to below 5.0.0 is required.
Is Kimi K2.7 Code better than DeepSeek V4?
It depends on the task. DeepSeek V4 Pro scores approximately 85 percent on SWE-bench Verified and costs significantly less per token (0.44 dollars input, 0.87 dollars output). K2.7 Code has a larger context window (256K versus 128K) and a higher MCP Mark Verified tool-use score. For pure coding benchmark value, DeepSeek V4 Pro is currently ahead. For MCP-integrated agent workflows with broader context needs, K2.7 Code has the advantage.
Recommended Blogs
- Kimi K2.6: Open-Source Just Beat GPT-5.5 at Coding
- Kimi K2.5 Review: Is It Better Than Claude for Coding? (2026)
- Kimi K2.6 vs Qwen 3.6 vs Opus 4.7 vs GPT-5.5: Which Wins? (2026)
- GLM-5.1: #1 Open Source AI Model? Full Review (2026)
- Best AI Models of May 2026: Full Leaderboard and Rankings
- Best Open-Source LLMs 2026 - Qwen, GLM, DeepSeek and Llama Compared
References
- Moonshot AI - Kimi K2.7 Code Official Model Page (kimi.com/resources/kimi-k2-7-code)
- Hugging Face - moonshotai/Kimi-K2.7-Code Model Card and Weights
- Moonshot AI - Kimi API Platform Model List and Pricing (platform.kimi.ai)
- MarkTechPost - Moonshot AI Releases Kimi K2.7-Code: a Coding Model Reporting +21.8% on Kimi Code Bench v2 Over K2.6
- VentureBeat - Kimi K2.7-Code Cuts Thinking Tokens 30% - But Practitioners Say the Benchmarks Don't Check Out
- The Decoder - Open Model Kimi K2.7 Code Undercuts GPT-5.5 and Claude by Up to 12x on Price Per Token
- Crypto Briefing - Kimi AI Releases Open-Source K2.7 Code Model With 1 Trillion Parameters
Codersera - Kimi K2.7 Code: The Complete Guide - Benchmarks, Pricing and How to Use (2026)

