




GLM-5.1: The First Open-Weight Model to Break Into Code Arena's Top 3
In 2023, open-source AI was two years behind the frontier. In 2024, one year. In 2025, six months. On April 10, 2026, Z.ai's GLM-5.1 posted a 1530 Elo score on Code Arena — sitting third in the world, behind only Anthropic's claude-opus-4-6-thinking (1548) and claude-opus-4-6 (1542), ahead of every GPT and Gemini model on the board.
That gap just closed.
I want to be precise about what happened here because the hype is running fast and some of the hot takes I've seen are both underselling and overselling it simultaneously. GLM-5.1 is not the best overall AI model. It does not beat Claude at everything. But it is the first open-weight model to crack the top three on one of the most human-validated coding leaderboards in AI — and it did it with a +90-point jump over its predecessor in a single release.
That is the story. Let me walk you through all of it.
What Is GLM-5.1? (And What Is Z.ai?)
GLM-5.1 is the latest flagship model from Z.ai, the international developer brand of Zhipu AI, a Chinese AI lab spun out of Tsinghua University. Z.ai released GLM-5.1 on April 7, 2026, specifically targeting agentic engineering: long-running coding tasks, autonomous optimization loops, and complex software projects that require sustained effort across hundreds of iterations.
The GLM stands for General Language Model — a model architecture Zhipu has been building since 2021. GLM-5.1 is an incremental post-training upgrade to GLM-5, which itself launched on February 11, 2026.
The company context matters here: Zhipu AI completed a Hong Kong IPO on January 8, 2026, raising roughly HKD 4.35 billion (approximately $558 million USD), making it the first publicly traded foundation model company in the world. Market capitalization at listing: around $52.83 billion. That capital infusion visibly accelerated their release pace. GLM-5 launched February 11. GLM-5-Turbo on March 15. GLM-5.1 API on March 27. Open-source weights on April 7. Four significant model events in eight weeks.
One more thing worth knowing: Zhipu AI has been on the US Entity List since January 2025. They cannot legally purchase Nvidia hardware. Every training run you will read about in this post was done on 100,000 Huawei Ascend 910B chips with zero Nvidia involvement. That is not a side note — it is one of the most strategically significant facts in AI hardware right now.
The Code Arena Result: What 1530 Elo Actually Means
On April 10, 2026, Arena.ai (formerly LMArena, initiated by UC Berkeley) confirmed GLM-5.1 at 1530 Elo on Code Arena — third place globally on their agentic webdev leaderboard.
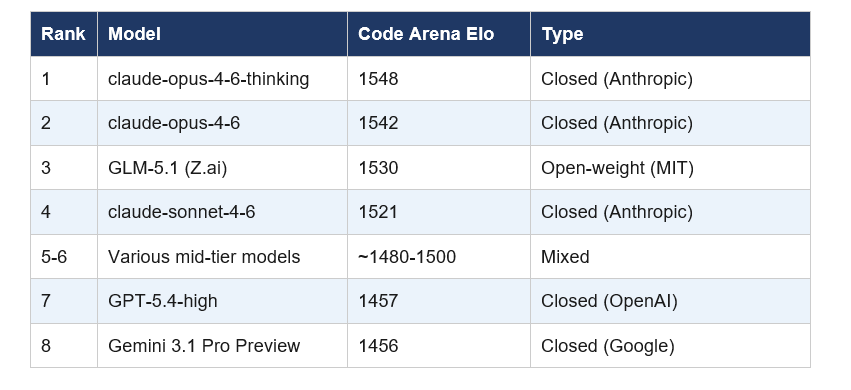
Code Arena ranks AI models on agentic web development tasks using blind human evaluations. Real developers rate model outputs without knowing which model produced them. It is one of the more ecologically valid benchmarks available, because it captures genuine developer judgment on genuine tasks — not curated test sets that training data might have touched.
The +90-point jump: GLM-5.1 is +90 points over its predecessor GLM-5 and +100 points over Kimi K2.5 Thinking. On a leaderboard where ten points separates meaningful model tiers, a 90-point single-release gain is not normal. That is a step change, not an iteration.
Arena.ai added GLM-5.1 to the Code leaderboard on April 9, 2026 — two days after Z.ai released the open weights. The community ranking followed within 24 hours of real user voting.
Full Benchmark Breakdown: GLM-5.1 vs Claude, GPT-5.4, Gemini 3.1 Pro
The Code Arena result is the headline, but the full benchmark picture is more nuanced. Here is every major benchmark with available data as of April 11, 2026:
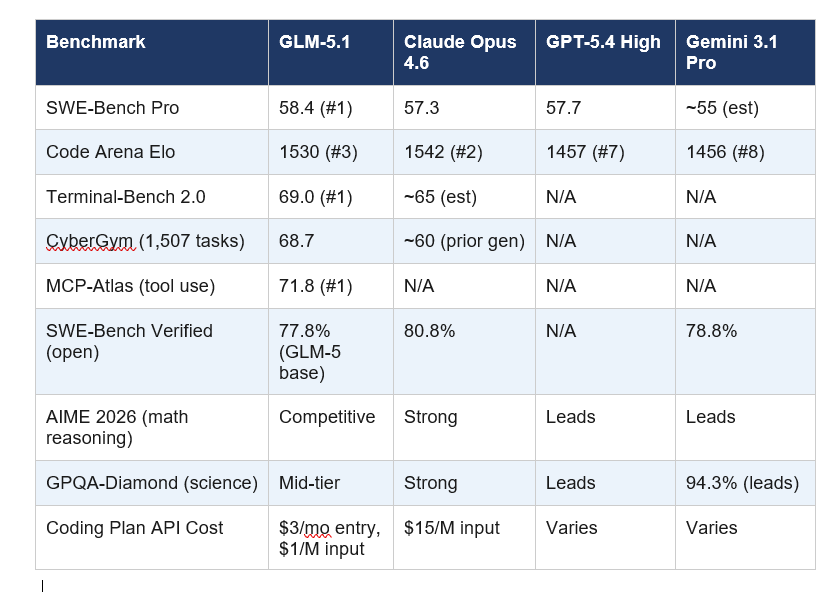
The honest read on these numbers: GLM-5.1 leads or ties on coding-specific benchmarks (SWE-Bench Pro, Terminal-Bench, Code Arena) and trails on reasoning-heavy benchmarks (AIME 2026, GPQA-Diamond). This is a coding model, and it performs like one.
My take on the SWE-Bench Pro result: The 58.4 vs 57.3 lead over Claude Opus 4.6 is narrow — 1.1 points. Z.ai's own broader coding composite (Terminal-Bench + NL2Repo combined) still puts Claude Opus 4.6 at 57.5 versus GLM-5.1 at 54.9. So 'beats Claude' is accurate on one benchmark and not the full picture. Independent evaluations peg GLM-5.1 at roughly 94.6% of Claude Opus 4.6's overall coding capability. That is the number I'd use. The gap closed to 5.4%. Twelve months ago it was a chasm.
The Long-Horizon Agentic Story: Why This Model Is Different
Here is the thing about most coding AI models that nobody talks about enough: they plateau. You give them a hard problem, they make fast early progress, then they run out of ideas. After 30 or 40 tool calls, they start looping. You end up babysitting the agent or accepting a half-finished result.
GLM-5.1 was built specifically to break that pattern. Z.ai's internal testing ran the model on tasks for up to eight hours of autonomous operation. The results from three publicly demonstrated scenarios are what convinced me this is more than a benchmark story.
Scenario 1 — Vector Database Optimization:
Z.ai gave GLM-5.1 a vector search optimization task using the SIFT-1M dataset. Standard models (including GLM-5 and Claude Opus 4.6) were run for 50 rounds with a best result of 3,547 queries per second. GLM-5.1 was given unlimited attempts and an outer loop to self-manage. After 600+ iterations and over 6,000 tool calls, it reached 21,500 queries per second — roughly 6x the previous best. The model fundamentally changed strategy six times during the run, identifying dead ends and switching approaches on its own without human instruction.
Scenario 2 — GPU Kernel Optimization:
GLM-5.1 was asked to rewrite machine learning code for faster GPU execution. It achieved a 3.6x speedup over the baseline implementation and continued making measurable progress in later phases of the run. Most models hit diminishing returns by iteration 20. GLM-5.1 was still improving at iteration 240.
Scenario 3 — Linux Desktop Environment from Scratch:
Z.ai demonstrated GLM-5.1 building a complete Linux desktop environment autonomously, running 655 iterations and increasing vector database query throughput to 6.9 times the initial production baseline.
These scenarios are all Z.ai's internal tests, so treat them as vendor claims until independent verification appears. But the structural argument is sound: the model's reinforcement learning pipeline (Zhipu calls it 'Slime RL') was specifically trained on long-horizon agentic data, not just code generation. That is a different training distribution than what produced models that plateau.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Architecture: 744B Parameters, Zero Nvidia Hardware
GLM-5.1 inherits the GLM-5 base architecture. The core specs:
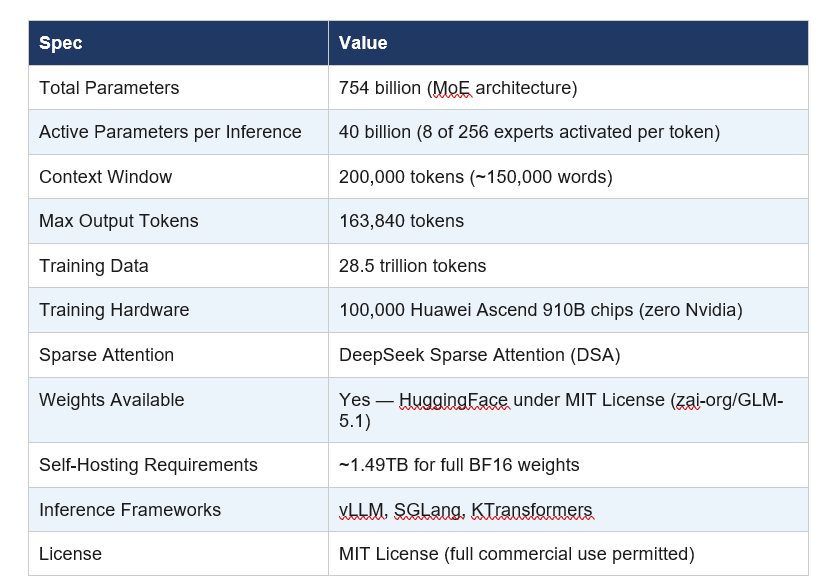
The MoE architecture means GLM-5.1 has 754 billion total parameters but only activates 40 billion per token during inference. Computational cost scales with active parameters, not total — which is how Z.ai offers frontier-adjacent performance at non-frontier pricing.
The Huawei Ascend story deserves a paragraph: Zhipu AI has been on the US Entity List since January 2025. They could not buy Nvidia H100s legally if they wanted to. So they trained the entire GLM-5 family on 100,000 Huawei Ascend 910B chips — manufactured by SMIC using 7nm DUV lithography. Industry estimates put SMIC's 7nm yield at 30-50% versus TSMC's 90%. Training GLM-5 required approximately 15% more compute time than an equivalent Nvidia run for a similar-scale model. They compensated through cluster scale and software optimization. And still shipped a frontier-competitive model. Whatever you think of the geopolitical backdrop, the technical achievement is objective.
Industry Adoption: Factory AI, Windsurf, and More
Within 48 hours of GLM-5.1's release, multiple developer tooling companies had already integrated it. This adoption velocity matters more than it looks — it signals that real engineering teams are putting this model into production workflows, not just running it on benchmarks.
Factory AI: Factory AI confirmed GLM-5.1 availability in Droid on April 10, 2026. Factory AI builds software engineering agents for enterprise teams. Their early user feedback cites GLM-5.1's handling of legacy code and complex multi-file refactoring at roughly half the cost of comparable closed models.
Windsurf: Windsurf (the AI coding IDE formerly known as Codeium) had already added GLM-5 to its model roster in February 2026 with limited-time promotional pricing. GLM-5.1 follows the same integration path and is now available in Windsurf's Arena Mode battle groups for Frontier Arena and Hybrid Arena comparisons.
Venice.ai: Venice.ai, a privacy-focused AI API provider, made GLM-5.1 available via their API under the model name 'zai-org-glm-5-1' — a choice that signals how open-weight model ecosystems work. No central distribution required; any compliant host can serve the weights.
GLM-5.1 works with all major coding assistant frameworks: Claude Code, Cline, Kilo Code, Roo Code, OpenCode, and Factory AI's Droid. For Claude Code users specifically, you change a single line in ~/.claude/settings.json to point to GLM-5.1 via the Z.ai API. Setup time: under two minutes.
Pricing: $3/Month vs $200/Month — The Cost Story
This is where GLM-5.1 creates the most disruption, and I think most coverage is underselling it.
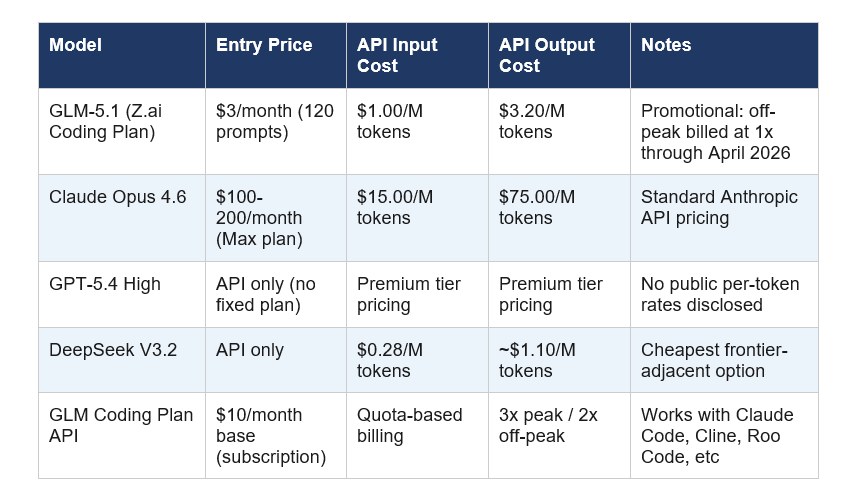
The relevant number for engineering teams: running GLM-5.1 at $1.00/M input tokens versus Claude Opus 4.6 at $15.00/M input tokens means a 15x cost reduction for 94.6% of the coding benchmark performance. For teams running high-volume agentic pipelines, that arithmetic determines budget allocation, not preference.
A contrarian note: The $3/month entry price is a promotional Coding Plan rate for 120 prompts — not a full unlimited API subscription. Enterprise teams doing real volume should price off the per-token rates, which put GLM-5.1 at $1.00/$3.20 per million tokens (input/output). That is still dramatically cheaper than Opus 4.6, but manage expectations on the headline number.
Where GLM-5.1 Falls Short — Honest Limitations
Every model release comes with a promotional filter on the numbers. Here is what the data actually shows on GLM-5.1's weaknesses:
- Reasoning benchmarks: On AIME 2026 (mathematical reasoning) and GPQA-Diamond (advanced science), GLM-5.1 is mid-tier. Gemini 3.1 Pro leads GPQA-Diamond at 94.3%. GPT-5.4 leads AIME 2026. If your use case is pure reasoning rather than coding, this is not your model.
- Text-only modality: GLM-5.1 does not support image, audio, or video input. Claude, GPT-5.4, and Gemini 3.1 Pro are all multimodal. For multimodal workflows, you need a different model.
- Self-reported benchmarks: As of April 11, 2026, the SWE-Bench Pro and long-horizon task results come exclusively from Z.ai's internal testing. No independent third-party evaluation lab has published corroborating results. Treat the specific numbers as preliminary claims, not verified facts.
- Self-hosting is non-trivial: The full BF16 model requires approximately 1.49TB of storage. Self-hosting GLM-5.1 is not a weekend project for most teams — you are looking at serious infrastructure requirements.
- No VBA or Office macro support: For teams relying on Excel macros or Office automation, GLM-5.1 has no meaningful advantage over specialized options.
None of these limitations invalidate the Code Arena result or the cost story. They do mean GLM-5.1 is a specialized tool, not a universal replacement. The framing matters.
How to Access GLM-5.1: API, Download, and Coding Tool Setup
There are three ways to use GLM-5.1 depending on what you are building:
Option 1 — GLM Coding Plan (easiest for developers):
Subscribe at z.ai for $10/month base. Update the model name in your Claude Code, Cline, or Roo Code configuration file to 'GLM-5.1'. For Claude Code specifically, edit ~/.claude/settings.json. Peak usage (14:00-18:00 UTC+8) is billed at 3x quota; off-peak at 2x (1x promotional through end of April 2026).
Option 2 — BigModel API (bigmodel.cn):
The primary developer API. Use model name 'glm-5.1' in your API requests. Priced at $1.00/M input tokens and $3.20/M output tokens. Works with any OpenAI-compatible API client. Full documentation at docs.z.ai.
Option 3 — Self-hosted (full control):
Download weights from HuggingFace at zai-org/GLM-5.1 under MIT license. Also available on ModelScope. Run with vLLM or SGLang inference frameworks. Deployment documentation is at the official GitHub repository at github.com/zai-org/GLM-5. Requirements: approximately 1.49TB storage for full BF16. FP8 quantized weights are available for reduced memory deployment.
Frequently Asked Questions
What is GLM-5.1 and who made it?
GLM-5.1 is Z.ai's flagship open-weight AI model released on April 7, 2026, built specifically for agentic engineering and long-horizon coding tasks. Z.ai is the international developer brand for Zhipu AI, a Tsinghua University spinoff that became the first publicly traded foundation model company after its Hong Kong IPO in January 2026.
Is GLM-5.1 better than Claude Opus 4.6 for coding?
On SWE-Bench Pro, GLM-5.1 scores 58.4 versus Claude Opus 4.6's 57.3 — a 1.1-point lead. On the broader coding composite including Terminal-Bench and NL2Repo, Claude Opus 4.6 still leads at 57.5 vs GLM-5.1's 54.9. Independent evaluations put GLM-5.1 at roughly 94.6% of Claude Opus 4.6's overall coding benchmark score. On Code Arena's human evaluation, GLM-5.1 ranks 3rd (1530 Elo) versus Claude Opus 4.6's 2nd place (1542 Elo).
What is Code Arena and how does it rank AI models?
Code Arena (arena.ai/code), maintained by Arena.ai (formerly LMArena, UC Berkeley), ranks AI models on agentic web development tasks using blind human evaluations. Real developers rate outputs without knowing which model produced them, generating an Elo-style ranking. It is considered one of the more ecologically valid AI benchmarks because it reflects genuine developer judgment on real tasks.
Is GLM-5.1 open source and free to download?
Yes. GLM-5.1 weights are available under the MIT License on HuggingFace at zai-org/GLM-5.1. MIT is one of the most permissive open-source licenses, allowing commercial use, fine-tuning, modification, and redistribution with no royalty fees. Self-hosting requires approximately 1.49TB storage for the full BF16 weights.
How does GLM-5.1 compare to GPT-5.4 on benchmarks?
On SWE-Bench Pro, GLM-5.1 scores 58.4 versus GPT-5.4's 57.7 — GLM-5.1 leads. On Code Arena Elo, GLM-5.1 scores 1530 versus GPT-5.4 High's 1457 — GLM-5.1 leads by 73 points. On mathematical reasoning (AIME 2026) and science (GPQA-Diamond), GPT-5.4 leads. The comparison depends heavily on which task category you care about.
Can I use GLM-5.1 with Claude Code or Cursor?
Yes. GLM-5.1 is compatible with Claude Code, Cline, Kilo Code, Roo Code, OpenCode, and Factory AI's Droid. For Claude Code, update the model name to GLM-5.1 in ~/.claude/settings.json and point to the Z.ai API endpoint. Setup documentation is available at docs.z.ai.
What is Z.ai — is it the same as Zhipu AI?
Z.ai is the international developer brand for Zhipu AI's model platform. The underlying research organization is Zhipu AI, a Tsinghua University spinoff. Z.ai is the name used for their international developer API (docs.z.ai, bigmodel.cn) and model releases like GLM-5.1. Inside China, the platform is known primarily as BigModel.
What does SWE-Bench Pro measure and why does it matter?
SWE-Bench Pro is an advanced software engineering benchmark that tests AI models on real-world GitHub issue resolution tasks, requiring models to understand existing codebases, identify bugs, and produce working fixes. It is considered harder and more representative of real engineering work than standard SWE-Bench. GLM-5.1 scores 58.4 on SWE-Bench Pro, leading GPT-5.4 (57.7), Claude Opus 4.6 (57.3), and Gemini 3.1 Pro.
Recommended Reading
References
- Z.ai - GLM-5.1 Official Announcement, April 7, 2026:
- Arena.ai - Code Arena Leaderboard Changelog, April 9-10, 2026:
- Arena.ai on X - GLM-5.1 #3 in Code Arena, April 10, 2026:
- OfficeChai - China's GLM-5.1 Ranks 3rd On Code Arena:
- The Decoder - Zhipu AI's GLM-5.1 Can Rethink Its Own Coding Strategy:
- WaveSpeed AI - GLM-5.1 vs Claude, GPT, Gemini, DeepSeek Comparison:

