




Best AI Models of May 2026: Full Leaderboard, Benchmarks & Rankings
Three separate models claimed the #1 position on different benchmarks in a single week of April 2026. Then a fourth arrived and reshuffled the leaderboard again. LLM Stats logged 255 model releases in Q1 2026 alone — roughly three significant releases every single day. The benchmark you bookmarked three weeks ago is almost certainly wrong by now.
This guide is the current picture. Every model that matters in May 2026, ranked by the benchmarks that actually reflect real-world performance — not marketing slides. Closed frontier, open-weight, budget-tier, and the hidden models that are quietly beating everything at a fraction of the cost. Pricing is verified from official sources as of May 17, 2026.
This post updates the April + May 2026 leaderboard with the latest releases and benchmark data. For task-specific recommendations, see Every AI Model Compared: Best One Per Task.
Master Comparison Table: Every Major Model in May 2026
All benchmark scores are third-party verified unless noted. Stars (★) indicate the benchmark leader. Pricing is confirmed from official API pages as of May 17, 2026.
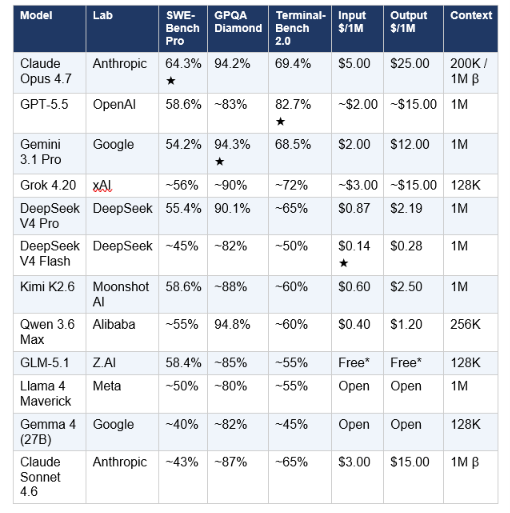
*GLM-5.1 available free on Hugging Face under MIT license. Hosted API pricing varies by provider. ~ = community consensus estimate; official scores not published.
⚡ The One-Sentence Verdict
No single model wins May 2026. Claude Opus 4.7 for complex coding. GPT-5.5 for agentic terminal work. Gemini 3.1 Pro for reasoning and multimodal at the lowest major-lab price. DeepSeek V4-Flash when cost is the primary constraint. Kimi K2.6 for the best open-weight coding value.
1. The 30-Day Benchmark War: What Just Happened
The April–May 2026 window was the most competitive in AI history. Here is the timeline that matters:

Unreleased model scores 93.9% SWE-bench Verified; restricted to Glasswing partners
Three things stand out from this window. First: the pace. Eight major events in 17 days is not a news cycle — it's a compression of model generations. Second: open-weight models are no longer chasing closed models. Kimi K2.6 and GLM-5.1 are competing at the benchmark frontier. Third: the pricing collapse is accelerating. DeepSeek V4-Flash at $0.14 per million input tokens versus GPT-5.5's estimated $2.00 is not a minor difference. It's a 14x gap at comparable benchmark performance on many tasks.
For the full context on what set up this month — the March 2026 launches of GPT-5.4, Grok 4.20, and Gemini 3.1 Pro — see the 12+ AI Models That Dropped in March 2026 breakdown.
2. Top 5 Closed Frontier Models Ranked
🏆 #1 — Claude Opus 4.7 (Anthropic)
The strongest coding model in the world — same price as the model it replaced
Claude Opus 4.7 launched April 16, 2026 with the biggest single-version improvement on SWE-bench Pro of any model in 2026: a 10.9-point jump from Opus 4.6's 53.4% to 64.3%. For context, that gap means Opus 4.7 autonomously resolves roughly 200 more software engineering tasks per 1,865-task test set than its predecessor. And Anthropic didn't raise the price.
Key Benchmarks
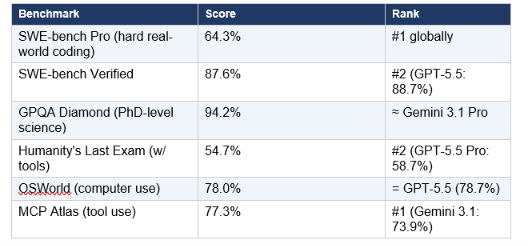
Michael Truell, CEO of Cursor, confirmed that Opus 4.7 lifted resolution by 13% over Opus 4.6 on Cursor's internal 93-task benchmark — solving four tasks that neither Opus 4.6 nor Sonnet 4.6 could touch. The JetBrains developer adoption survey from January 2026 put Claude Code at 91% satisfaction and NPS of 54 — the highest product loyalty metrics in the AI coding category.
Pricing
$5.00 input / $25.00 output per million tokens — identical to Opus 4.6 pricing. Standard context: 200K tokens. 1M token context window is in beta. Available through Amazon Bedrock, Google Vertex AI, and Microsoft Foundry alongside the Anthropic API.
Best for: Complex multi-file coding, PR review, long-horizon agentic tasks, and any production workflow where getting the code right matters more than latency. The default model in Claude Code.
⚡ #2 — GPT-5.5 (OpenAI)
Rebuilt from scratch — the strongest agentic terminal model available
GPT-5.5 arrived April 23, 2026 — and it's not an increment on GPT-5.4. OpenAI rebuilt the architecture, pretraining corpus, and training objectives from scratch for the first time since GPT-4.5. The result: the highest score on the Artificial Analysis Intelligence Index (composite across benchmarks), the strongest Terminal-Bench 2.0 result, and a 60% drop in hallucinations compared to GPT-5.4 on Vectara's evaluation. It became the default ChatGPT model on May 5, 2026.
Key Benchmark
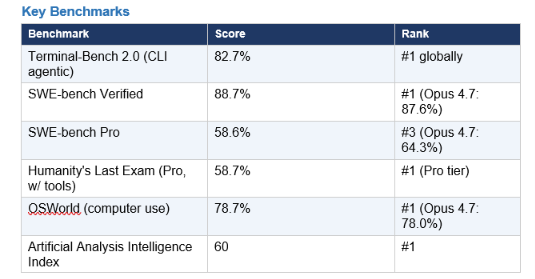
One number that gets less attention than it should: GPT-5.5 burns 35% less token quota than GPT-5.4 for equivalent quality output. Under subscription billing (ChatGPT Pro, $200/month), that efficiency compound is significant over a month of heavy use. The agentic terminal leadership is GPT-5.5's most differentiating capability — a 13-point lead over Gemini 3.1 Pro on Terminal-Bench 2.0 is not noise.
Best for: Terminal-heavy DevOps workflows, CLI agentic tasks, autonomous task execution via Codex, and any application where computer use autonomy is the primary requirement.
🔬 #3 — Gemini 3.1 Pro (Google DeepMind)
The scientific reasoning leader — and the cheapest major-lab frontier model
Gemini 3.1 Pro launched February 19, 2026 and has been the most consistent overperformer at its price point in the months since. At $2 input / $12 output per million tokens (for prompts under 200K), it sits 60% cheaper than Claude Opus 4.7 on input and leads GPQA Diamond — the most demanding publicly available science benchmark — with 94.3%. That's the highest score of any model in this comparison. For the full Claude Opus 4.7 vs Gemini 3.1 Pro breakdown, see the DataCamp comparison.
Key Benchmarks
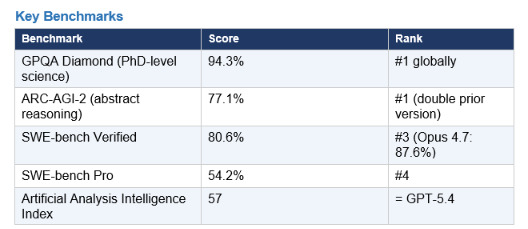
Gemini 3.1 Pro generates more tokens per task than Claude or GPT — roughly 20-40% more depending on query type — which erodes its price advantage at high output volume. The model card reports 80.6% on SWE-bench Verified, keeping it competitive on coding even as Claude leads. Native multimodal input (text, images, audio, video) and 1M-token context at the $2/$12 price point make it the default recommendation for large-document processing and research-heavy workflows where cost discipline matters.
Best for: Scientific reasoning, research, multimodal applications, large-document analysis, and any workflow where $2/$12 per million tokens beats the alternative at comparable quality.
🔥 #4 — Grok 4.20 (xAI)
The hallucination-averse frontier model — and the one that tied for IQ #1
Grok 4.20 scored 145 on TrackingAI's April 2026 Mensa Norway benchmark, tying with OpenAI GPT-5.4 Pro for the top spot on that evaluation. xAI's model family distinguishes itself in one critical dimension: Grok-4-fast-reasoning holds the top position on Humanity's Last Exam for frontier knowledge questions at 50.7%. However, the same variant hallucinated at 20.2% on Vectara's evaluation set — the highest rate of any model in the top 10. The tradeoff is real and documented.
Best for: Frontier knowledge questions at the absolute edge of training data, and applications where real-time X/Twitter data is a required input. Approach with caution for factual-precision-critical use cases — verify the hallucination rate against your specific workload.
Use when: Cutting-edge scientific knowledge retrieval and real-time social data matter. Flag the hallucination rate for any use case requiring factual precision.
💼 #5 — Claude Sonnet 4.6 (Anthropic)
The best value for everyday coding and professional work — $3/$15 per million
Claude Sonnet 4.6 is the workhorse of the 2026 Claude family. At $3/$15 per million tokens, it delivers approximately 90% of Opus 4.7's quality at 40% of the price. It's the default model on Claude.ai Free and Pro plans, the model powering GitHub Copilot's coding agent, and in Claude Code head-to-head testing, developers preferred it over Opus 4.5 (the previous flagship) 59% of the time. The GDPval-AA Elo benchmark — measuring performance across 44 professional knowledge work occupations — puts Sonnet 4.6 at 1,633 Elo, the highest of any mid-tier model and ahead of several flagship models. For the complete Sonnet 4.6 comparison, see the Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro breakdown.
Best for: Everyday coding, writing, document analysis, and professional knowledge work. The default recommendation for any team that needs Opus-level quality for most tasks at Sonnet pricing.
3. Top 5 Open-Weight Models Ranked
The open-source story in 2026 is no longer about catching up. On multiple benchmarks, open-weight models are leading. The gap with closed-source proprietary models has narrowed to 5-15 benchmark points on most tasks — and those points can be closed by fine-tuning on domain-specific data.
🌟 #1 — Kimi K2.6 (Moonshot AI)
The open-weight model that beat GPT-5.5 and Gemini at coding — at $0.60/M input
Kimi K2.6 is the most significant open-weight release of April 2026. It's a 1.6-trillion-parameter MoE model (31B active) from Moonshot AI that scored 58.6% on SWE-bench Pro — within 6 points of Claude Opus 4.7, beating GPT-5.5 (58.6%) on the same benchmark, and matching Gemini 3.1 Pro. It won a programming challenge that Claude, GPT-5.5, and Gemini all failed. Agent Swarm, Kimi K2.6's multi-agent architecture, scales to 300 parallel sub-agents for long-horizon tasks. API pricing at $0.60/M input, $2.50/M output is roughly 8x cheaper than Opus 4.7. For the full technical breakdown, see the Kimi K2.6 review at Build Fast with AI.
Best for: High-volume production coding workloads where Claude Opus 4.7 quality is unaffordable. The open-weight coding value leader of May 2026.
🔓 #2 — DeepSeek V4 Pro (DeepSeek)
1.6 trillion parameters, MIT license, 34x cheaper output than GPT-5.5
DeepSeek V4 Pro (April 24, 2026) runs 1.6 trillion total parameters with 49 billion active per forward pass on Huawei Ascend chips — zero NVIDIA GPU hardware. MIT license means full commercial use with no restrictions. At $0.87/M output, it's 34x cheaper than GPT-5.5's estimated $30/M output while scoring 80.6% on SWE-bench Verified and 55.4% on SWE-bench Pro. V4-Flash (284B total / 13B active) drops the per-token cost further to $0.14/$0.28 — the cheapest useful frontier-quality model available.
Data sovereignty note: DeepSeek processes data through Chinese infrastructure under Chinese law. For regulated industries or client data, self-host under the MIT license on your own infrastructure — this eliminates the data sovereignty concern while keeping the cost advantage.
Best for: High-volume API workloads where cost is the primary constraint and quality requirements sit at the 80% SWE-bench Verified level. Self-host for regulated environments.
🧠 #3 — Qwen 3.5 / 3.6 Family (Alibaba)
The most architecturally interesting release — frontier coding at $0.40/M
Alibaba's Qwen family had the busiest April of any lab. Qwen 3.6-72B-dense (April 11): 94.8% HumanEval, 68.2% SWE-bench Verified, 71.4% LiveCodeBench — beating Gemma 4 on every coding benchmark. Qwen 3.5 (397B total / 17B active, Apache 2.0) uses a hybrid Gated DeltaNet + MoE architecture that delivers 8-19x faster decoding than its predecessor at 60% lower cost. GPQA Diamond score of 88.4% puts it competitive with GPT-5.5 on scientific reasoning. Apache 2.0 license means no licensing headaches for commercial deployment.
Data sovereignty note: Alibaba Cloud API routes data through Singapore by default. Self-host under Apache 2.0 for regulated industries.
Best for: Cost-sensitive production workloads requiring open weights. The best price-to-performance ratio among non-Chinese-datacenter-required models when self-hosted.
🦙 #4 — Llama 4 Scout (Meta)
10 million token context window — the largest of any model, open or closed
Llama 4 Scout holds the largest context window of any model on the leaderboard at 10 million tokens. For processing book-length documents, massive codebases, or multi-year conversation histories, no other model matches this. The trade-off: raw reasoning scores are lower than frontier closed models (approximately 80% GPQA Diamond). But the 10M context window fundamentally changes what's possible for large-scale document processing applications. MIT license with Meta's community terms.
Best for: Any application requiring multi-million-token context at zero API cost. Legal document review, entire codebase ingestion, long-running research threads.
🏃 #5 — GLM-5.1 (Z.AI)
The model that made history — first open-weight to lead SWE-bench Pro
GLM-5.1 from Z.AI (formerly Zhipu AI) entered the history books on April 7, 2026 as the first open-weight model to ever hold the #1 position on SWE-bench Pro, scoring 58.4%. It held that position for nine days before Claude Opus 4.7 arrived. The model is a 744-billion-parameter MoE with 40 billion active parameters, trained entirely on Huawei Ascend 910B chips. MIT license. Available free on Hugging Face. Long-horizon agentic execution capability: GLM-5.1 can sustain autonomous task execution for up to eight hours without performance degradation. The model is on the US Entity List via its parent company — evaluate infrastructure and data implications before deployment in regulated environments.
Best for: Long-horizon agentic tasks requiring sustained autonomous execution. Zero-cost access on Hugging Face makes it the only frontier-class model with truly free weights at MIT license.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
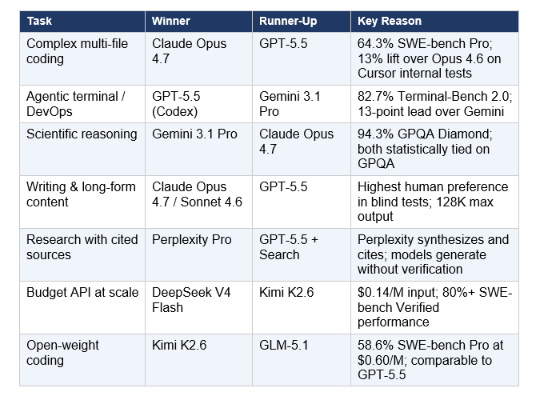
4. Model by Use Case: Which One Wins Each Task
This is the practical decision grid. For the full task-by-task breakdown across 12 categories including image generation, video, voice, and embeddings, see the Every AI Model Compared: Best One Per Task guide. The table below covers the most commonly searched use cases.
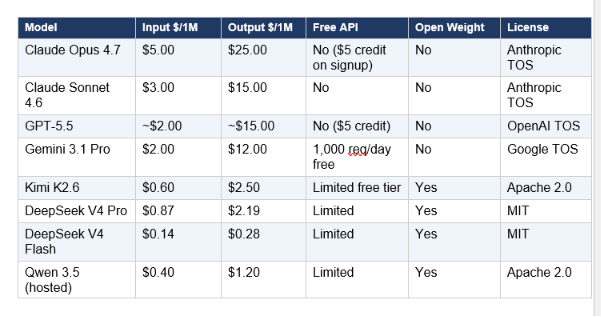
5. Pricing Analysis: The Cost Collapse Is Real
The Western/Chinese pricing gap reached 5–25x at equivalent benchmark performance in May 2026. That number deserves to sit with you for a moment. On output tokens — where most production costs accumulate — DeepSeek V4-Flash ($0.28/M) versus GPT-5.5's estimated $30/M is a 107x difference. Even factoring in the task routing and quality differences, no serious production team is ignoring this.
The routing math that most teams are not running: a production system routing 70% of traffic to DeepSeek V4-Flash ($0.14/M input), 25% to Claude Sonnet 4.6 ($3/M), and 5% to Claude Opus 4.7 ($5/M) achieves overall performance indistinguishable from all-frontier routing at approximately 15% of the cost. That 85% savings at scale is not a future hypothesis — teams implementing it are reporting it today.
6. The Multi-Model Routing Strategy (The Smart Architecture for 2026)
Any application hardcoded to a single model in May 2026 is accumulating technical debt in real time. With 255+ model releases in Q1 alone, the "best" model three months ago may not be the best model today. The AI Agent Frameworks guide at Build Fast with AI covers how to wire multi-agent, multi-model systems into production. Here is the practical routing architecture.
Recommended Production Routing Stack
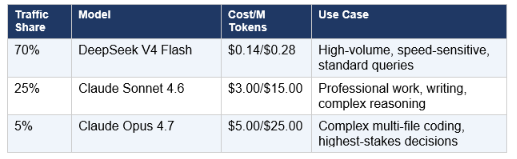
Result: Overall performance equivalent to all-frontier routing at approximately 15% of all-frontier cost. The routing layer — not the model selection — is where most teams now find the largest remaining productivity and cost gains.
Why Model-Agnostic Infrastructure Is Non-Negotiable
- LLM Stats tracked 255 major releases in Q1 2026 — roughly one meaningful model per day
- The April–May window had 8 significant events in 17 days, with multiple benchmark reshuffles
- Any team hardcoded to one provider faced a migration decision 3-4 times in the past 90 days
- A unified API layer where switching is a parameter change (not a refactor) pays dividends every quarter
- The models arriving in Q3 2026 (GPT-6, Claude Next, Gemini 3.5) will reset this table again
7. What's Coming Next: GPT-6, Claude Next, Gemini 3.5
The post-May 2026 model pipeline is already partially visible. Here's what's confirmed or strongly signaled:
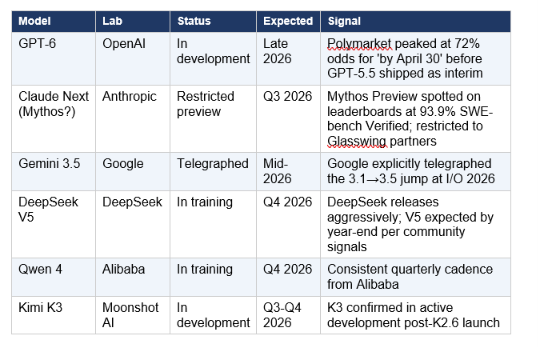
Sam Altman identified long-term memory as the headline feature of the next GPT generation — the ability to maintain coherent context across unlimited sessions. Anthropic's focus, per internal signals, is reliability: reducing the 20-30% task failure rate on complex agentic workflows that still affects all frontier models.
Frequently Asked Questions
What is the best AI model in May 2026?
There is no single best AI model. The answer depends entirely on your task. Claude Opus 4.7 leads on complex multi-file coding at 64.3% SWE-bench Pro. GPT-5.5 leads on agentic terminal workflows at 82.7% Terminal-Bench 2.0. Gemini 3.1 Pro leads on scientific reasoning at 94.3% GPQA Diamond. DeepSeek V4 Flash leads on cost at $0.14/M input. For everyday professional work, Claude Sonnet 4.6 at $3/M delivers near-Opus quality at 40% of the price. The most productive strategy is routing across 2-3 models based on task type, not committing to one.
GPT-5.5 vs Claude Opus 4.7 — which is better?
GPT-5.5 leads on SWE-bench Verified (88.7% vs 87.6%), Terminal-Bench 2.0 (82.7% vs 69.4%), and computer use/OSWorld (78.7% vs 78.0%). Claude Opus 4.7 leads on SWE-bench Pro (64.3% vs 58.6%) — the harder, less contaminated benchmark that better reflects real-world software engineering. Claude also leads on hallucination reliability: 36% hallucination rate versus GPT-5.5's 86% on Artificial Analysis's evaluation. For most coding workflows, Claude Opus 4.7 is the better choice. For terminal-heavy DevOps agents, GPT-5.5 via Codex has a documented lead.
What is SWE-bench and why does it matter?
SWE-bench Verified is a benchmark of 500 real GitHub issues from popular Python repositories (Django, Flask, Matplotlib, Requests). A model is given the issue description and must resolve it autonomously — writing code, running tests, fixing failures — without human intervention. An 87.6% score means the model resolved 438 of 500 real-world software engineering challenges. SWE-bench Pro is the harder version: 1,865 tasks across 41 repositories in Python, Go, TypeScript, and JavaScript, with stronger contamination controls. Pro scores are more predictive of real production performance.
What is the cheapest frontier AI model?
DeepSeek V4 Flash is the cheapest model with frontier-competitive performance, at $0.14 per million input tokens and $0.28 per million output tokens. It scores approximately 79-80% on SWE-bench Verified — within 8 points of GPT-5.5. For pure free access with MIT license, GLM-5.1 on Hugging Face is technically free for weights. Gemini 3.1 Pro ($2/$12 per million) is the cheapest major-lab frontier option from a Western provider.
Is DeepSeek V4 better than GPT-5.5?
Not overall, but competitively on specific benchmarks at a fraction of the cost. DeepSeek V4 Pro scores 80.6% on SWE-bench Verified (vs GPT-5.5's 88.7%) and 90.1% on GPQA Diamond (vs GPT-5.5's ~83%). GPT-5.5 leads decisively on Terminal-Bench 2.0 (82.7% vs ~65% for DeepSeek). At $0.87/M output versus GPT-5.5's estimated $15-30/M, DeepSeek V4 Pro is the default choice for any high-volume production API workload that can tolerate the 8-point SWE-bench performance difference.
What is the best open-source AI model in 2026?
Kimi K2.6 leads for coding with 58.6% on SWE-bench Pro at $0.60/M input — comparable to GPT-5.5 and beating Gemini 3.1 Pro on that benchmark. DeepSeek V4 Pro leads for overall open-weight capability at MIT license. GLM-5.1 is technically free on Hugging Face and holds a historic SWE-bench Pro leadership record. For the largest context window in open weights, Llama 4 Scout's 10 million tokens is unmatched. Apache 2.0 models (Qwen 3.5, Gemma 4) are the safest commercial choice with minimal licensing constraints.
Which AI model has te lowest hallucination rate?
Non-reasoning models generally hallucinate less than reasoning models on factual tasks. Gemini Flash Lite scores 3.3% on Vectara's hallucination evaluation — the lowest among commonly tested models. Every reasoning model tested in May 2026 exceeded 10% hallucination rate. Grok-4-fast-reasoning sits highest at 20.2%. GPT-5.5 improved hallucination rate by 60% over GPT-5.4, but still exceeds 10% in reasoning mode. For factual precision tasks, use non-reasoning mode or pair any model with Perplexity for citation verification.
How do I build a model routing stack for my application?
Start with this three-tier pattern: a high-volume cheap tier (DeepSeek V4 Flash at $0.14/M) handling routine queries; a mid-tier (Claude Sonnet 4.6 at $3/M) for professional work; and a frontier tier (Claude Opus 4.7 at $5/M) for the 5% of queries requiring maximum capability. Routing logic can be as simple as token count and task category classification. For production implementation patterns including multi-agent coordination and provider fallback logic, the gen-ai-experiments agent orchestration notebooks cover multi-model implementation with Claude, GPT, Gemini, and DeepSeek.
Final Verdict: The May 2026 Model Decision Framework
Three conclusions from this month's model landscape that matter more than any individual benchmark:
- The leaderboard has fractured by task. The correct question is no longer 'which model is best?' It's 'which model is best for this specific task?' That shift has been true in theory for a year. It's now unavoidably true in practice.
- Open-weight models crossed a threshold. The week GLM-5.1 held #1 on SWE-bench Pro was a signal. Closed models no longer have a lock on leading benchmarks. Kimi K2.6 within 6 points of Claude Opus 4.7 at 8x lower cost is not a catch-up story — it's a competitive market.
- Model-agnostic infrastructure is the decision that compounds. Every team that hardcoded a provider dependency in the last 90 days faced at least one migration decision. The teams shipping best in Q3 2026 will be the ones who built routing into their architecture in Q
The benchmark leaderboard will be reshuffled again within 60-90 days. For the most current rankings, follow Build Fast with AI for monthly model updates, and subscribe to the monthly newsletter for the breakdown as each major release lands.
Recommended Blogs
- Best AI Models: April + May 2026 Leaderboard (Full April Context)
- Every AI Model Compared: Best One Per Task (2026)
- Kimi K2.6: Open-Source Just Beat GPT-5.5 at Coding
- Best AI Models for Frontend UI Development 2026
- AI Agent Frameworks 2026: LangGraph, CrewAI, AutoGen & More
- Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro: Best All-Rounder?
References
- Anthropic — Claude Opus 4.7 System Card and Launch Post (April 16, 2026)
- OpenAI — GPT-5.5 Release and Benchmark Documentation (April 23, 2026)
- Google DeepMind — Gemini 3.1 Pro Technical Report (February 19, 2026)
- DeepSeek — V4 Pro and V4 Flash Preview Release Notes (April 24, 2026)
- Moonshot AI — Kimi K2.6 Model Card (Hugging Face)
- Artificial Analysis — Intelligence Index May 2026
- SWE-bench — Public Leaderboard (May 2026)
- DataCamp — Claude Opus 4.7 vs Gemini 3.1 Pro Full Comparison
- FutureAGI — Best LLMs May 2026 Complete Analysis
- Stanford HAI — AI Index Report 2026

