





NVIDIA Nemotron 3 Ultra Review 2026: Benchmarks, Architecture & Real-World Performance
The open-weight AI race just got a new American champion. On June 1, 2026, Jensen Huang walked onto the Computex stage in Taipei and unveiled Nemotron 3 Ultra — 550 billion total parameters, 55 billion active per token, over 300 tokens per second, and an Intelligence Index score of 48 that makes it the most capable US-developed open model ever released. That is a big claim. Let's stress-test it.
For most of 2026, the open-source leaderboard has been a Chinese competition: Kimi K2.6 (54 on the Index), GLM-5.1, Qwen 3.5. The US open-weight tier was stuck at 33–36 — capable but clearly behind. Nemotron 3 Ultra doesn't close that gap entirely, but it closes it meaningfully, and it does so while offering inference efficiency that no comparable model can match right now. For teams running agent infrastructure at scale, that combination is genuinely interesting.
I've pulled every available benchmark, read the technical report, and mapped Ultra against the competitive landscape as of early June 2026. Here is the honest picture.
1. What Is NVIDIA Nemotron 3 Ultra?
Nemotron 3 Ultra is a 550-billion-parameter open-weight language model released by NVIDIA on June 4, 2026, first announced at Computex 2026. It is the largest model in the Nemotron 3 family, which launched at GTC in March 2026 with the Nano and Super variants. Ultra is purpose-built for long-running agentic workflows: multi-step coding agents, enterprise document RAG, research automation, and complex orchestration pipelines where context, accuracy, and inference cost all matter simultaneously.
Key specifications at a glance:
- 550B total parameters, 55B active per forward pass (A55B MoE)
- Hybrid Mamba-Transformer architecture with LatentMoE expert routing
- 262k token context window (BF16 weights); 1M token context with NVFP4 quantization on Blackwell
- Trained on 20 trillion tokens
- Intelligence Index score: 48 — highest of any US open-weight model
- Output speed: 300+ tokens per second (DeepInfra, BF16)
- Licensed under OpenMDW-1.1 (Linux Foundation permissive license)
- Weights, post-trained checkpoints, reward models, quantized variants, and training recipes all released publicly
For a broader view of where Nemotron 3 Ultra fits into NVIDIA's overall model strategy — including Nano Omni and Super — the NVIDIA AI Models 2026 full guide covers the complete family with deployment context.
2. Architecture Deep Dive: Hybrid Mamba-Transformer MoE
Nemotron 3 Ultra's architecture is the most technically distinctive thing about it, and it is where NVIDIA has made the biggest bet. Understanding it matters if you are evaluating this model for production.
Hybrid Mamba-Transformer Design
Pure transformer models are powerful but memory-hungry at long context. Pure state space models like Mamba are memory-efficient but have known accuracy ceilings on complex reasoning tasks. NVIDIA's bet is a hybrid: Mamba layers handle efficient long-range sequence modeling (critical for 200k+ token contexts), while transformer layers handle the dense reasoning and attention patterns that benchmarks reward. The combination is designed to outperform both pure architectures in production agentic workloads — and the performance data suggests the bet is paying off.
LatentMoE: Smarter Expert Routing
The Mixture-of-Experts design activates only 55B of the 550B parameters per token — a 10x sparsity ratio. NVIDIA calls their routing mechanism LatentMoE, which routes tokens to experts based on a latent representation rather than raw token embeddings. The practical effect is more intelligent expert selection without the routing collapse problems that have plagued naive MoE implementations. This is why Ultra achieves its quality-per-active-parameter ratio; the right experts are getting activated.
NVFP4 Quantization and Blackwell Integration
Ultra ships in both BF16 and NVFP4 quantized formats. The NVFP4 format, designed for NVIDIA's Blackwell GPU architecture, delivers up to 5x higher throughput compared to standard FP16 inference on competing open models. This is not a minor optimization — it is the infrastructure reason NVIDIA can claim 5x efficiency without sacrificing meaningful accuracy. BF16 shows a mean training loss gap of under 0.4% against the BF16 baseline, meaning quantization essentially trades negligible accuracy for massive throughput gains.
Multi-Token Prediction
Ultra uses multi-token prediction during generation, which improves throughput in multi-turn conversational and agentic scenarios. For agents that run dozens of turns per task, the compound effect is meaningful. NVIDIA reports that Ultra completes SWE-bench and Terminal Bench 2.0 tasks using fewer total tokens per run than comparable models — lowering per-task cost by approximately 30%.
3. Benchmark Results: The Full Picture
Ultra achieves 48 on the Artificial Analysis Intelligence Index — a composite benchmark covering reasoning, knowledge, mathematics, and coding across 10 evaluation categories including GPQA Diamond, Humanity's Last Exam, Terminal-Bench Hard, SciCode, IFBench, and AA-Omniscience. That is the highest score of any US open-weight model, sitting well ahead of the previous US leader (Gemma 4 31B at 39), Nemotron 3 Super (36), and GPT-OSS 120B (33).
The honest caveat: Chinese-led open models still lead overall. Kimi K2.6 scores 54 on the same index. GLM-5.1 leads SWE-bench Pro. The US-vs-China framing matters for some use cases (data residency, export compliance, supply chain risk), but if raw intelligence score is your only metric, Kimi K2.6 is still the global open-weight leader as of June 2026.
Here is how the key models compare on the benchmarks that matter most for agentic workflows:
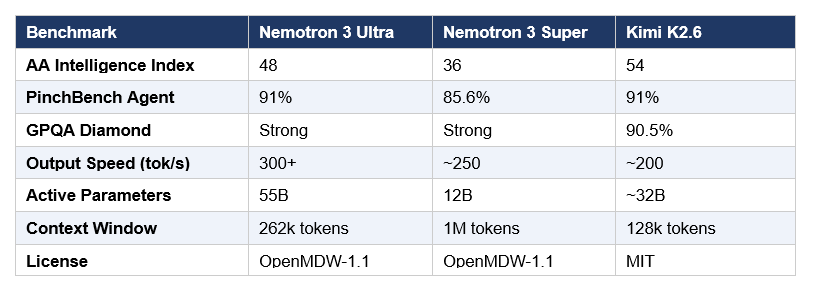
A few benchmark signals worth highlighting specifically:
- PinchBench Agent Productivity: Ultra scores 91%, matching Kimi K2.6 and ahead of Qwen 3.5 — strong evidence for agentic workflow quality parity with the best Chinese open model on task completion.
- Terminal Bench 2.0: Ultra completes tasks using fewer tokens per turn than competing models, validating the efficiency claim independently.
- CodeRabbit self-hosted benchmark (June 2026): Ultra showed 7:06 mean latency per full review trace, compared to 8:31 for the baseline — consistent with NVIDIA's throughput claims in a real developer workflow.
- MMLU-Pro: Adding NVIDIA's synthetic benchmark-oriented pretraining data improved scores from 64.8 to 66.6, a measurable and intentional uplift.
For a deep-dive comparison of how these numbers translate to real coding tasks, the best AI for coding 2026 benchmark analysis covers SWE-bench performance across Nemotron Super, GPT, and Claude side by side.
4. Speed and Inference Efficiency
This is where Nemotron 3 Ultra's case is strongest, and where NVIDIA's hardware advantage becomes directly relevant.
On a pre-release DeepInfra endpoint, Ultra served over 300 tokens per second using BF16 weights. With NVFP4 quantization on Blackwell, throughput climbs significantly higher — NVIDIA claims up to 5x faster inference versus competing open models at similar intelligence levels. For reference, Kimi K2.6 and GLM-5.1 both score higher on the Intelligence Index, but neither matches Ultra's throughput numbers on current-generation NVIDIA hardware.
Why does speed matter this much? Because agentic workloads are not single-turn queries. A coding agent running 50-turn task completion sequences, or a RAG pipeline processing 10,000 document chunks across a work day, generates inference bills that compound rapidly. At 300+ tokens per second with 30% lower per-task token usage, the economics shift materially.
Hot take: the inference efficiency story is undersold in most Computex coverage. Everyone talks about the Intelligence Index score; the throughput story is where Ultra actually differentiates against Chinese competitors for enterprise deployment. Kimi K2.6 scores higher — but if you are running it on US infrastructure at scale, the serving costs will be higher too.
To understand how open-weight efficiency compares against closed models on the cost curve, the best AI models May 2026 leaderboard breaks down cost-per-task across the full frontier.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Nemotron 3 Ultra vs the Competition
The competitive landscape for open-weight models as of June 2026 is primarily defined by four models: Nemotron 3 Ultra, Kimi K2.6, GLM-5.1, and Qwen 3.5. Here is the honest breakdown:
Nemotron 3 Ultra vs Kimi K2.6
Kimi K2.6 is the global open-weight intelligence leader at 54 on the Index vs Ultra's 48. On SWE-bench Pro and GPQA Diamond, Kimi K2.6 edges ahead. The gap in raw intelligence scores is real. However, Kimi K2.6 is available at $0.30 per million tokens — competitive on cost — but its throughput on commodity US GPU infrastructure does not match Ultra's 300+ tok/s on Blackwell. If you are US-based, prioritize compliance and data residency, need maximum throughput, and can accept a slightly lower benchmark ceiling, Ultra wins. If you need the absolute highest reasoning scores and cost is the primary constraint, Kimi K2.6 is still the pick.
Nemotron 3 Ultra vs Nemotron 3 Super
Nemotron 3 Super (12B active, 120B total) scores 36 on the Intelligence Index versus Ultra's 48 — a 12-point gap that reflects Ultra's larger parameter budget. Super's 1M token context window (vs Ultra's 262k in BF16) is actually larger at base, though Ultra can match it with NVFP4 quantization on Blackwell. Super's SWE-bench score of 60.47% was impressive at launch, but Ultra's broader capability set and higher reasoning scores make it the better choice for general-purpose agentic work. Super remains the practical workhorse for cost-sensitive or compute-constrained deployments.
Nemotron 3 Ultra vs Gemma 4 31B
The comparison with Google's Gemma 4 31B is stark. Ultra at 48 on the Intelligence Index is nine points ahead of Gemma 4 31B's 39, and it does so with MoE efficiency that makes the comparison even more favorable when normalized for inference cost. Gemma 4 31B is a strong model for its parameter count, but Ultra is not competing in the same tier.
For a comprehensive view of where these models fit in the broader open-source landscape, the full open-source LLM hub on Build Fast with AI tracks rankings, benchmarks, and deployment patterns across all major open-weight models.
6. Real-World Use Cases and Early Adopter Results
NVIDIA secured a group of enterprise partners for early access before the public launch: Accenture, CrowdStrike, and Perplexity. The use case signals from these three organizations are telling.
- Accenture: Enterprise workflow automation and large-scale document processing pipelines — exactly the long-context, multi-turn agentic use cases Ultra is architected for.
- CrowdStrike: Cybersecurity threat analysis and automated triaging — a domain requiring both long-context retention and high reasoning accuracy under cost constraints.
- Perplexity: Search augmentation and research synthesis — Ultra's 300+ tok/s throughput matters when serving thousands of concurrent users.
For the developer community, CodeRabbit's benchmark (released June 4, 2026) is the most concrete independent test available. Ultra delivered accurate and fast throughput in self-hosted AI code reviews, completing review traces at 7:06 mean latency versus 8:31 for the baseline — a 16% speed improvement in a real-world production workflow.
Early developer feedback on OpenRouter and Discord highlights the model's capability-to-efficiency ratio as one of the strongest currently available in the US open-weight tier. Autonomous coding agents, long-running software engineering tasks, research workflows, and enterprise AI assistants are the consistent themes in early testing reports.
If you are evaluating Ultra specifically for software engineering workflows, the step-by-step experiments in the Build Fast with AI gen-ai-experiments cookbook provide a practical framework for testing agentic pipelines against your actual tasks.
7. How to Access and Deploy Nemotron 3 Ultra
NVIDIA has taken an unusually open approach to this release. Everything is publicly available as of June 4, 2026:
- Base model weights on Hugging Face (nvidia/Nemotron-3-Ultra-550B-A55B-Base)
- Post-trained checkpoints (instruction-tuned and reasoning variants)
- Reward models used in RLHF post-training
- NVFP4 quantized variants optimized for Blackwell
- Training recipes, datasets, and evaluation code
- Deployment cookbooks for vLLM, SGLang, and TensorRT-LLM
For API access without managing your own GPU infrastructure:
- DeepInfra: Pre-release endpoint already active; pricing at $0.37/M input and $1.08/M output (better than median for this size tier)
- OpenRouter: Already indexed and accessible to developers
- NVIDIA NIM microservices: Enterprise integration via build.nvidia.com
Hardware requirements for self-hosting are substantial. The BF16 weights of a 550B-parameter model will require multi-GPU configurations (8xH100 or equivalent). The NVFP4 format on Blackwell offers a more practical self-hosting path for teams with newer infrastructure. If you do not have access to H100-class hardware, API access via DeepInfra or OpenRouter is the practical starting point.
8. Honest Verdict: Who Should Use Nemotron 3 Ultra?
Nemotron 3 Ultra is a genuinely impressive model release, but not for every use case. Here is the honest split:
Use Nemotron 3 Ultra if:
- You need the strongest US-developed open-weight model for compliance or data residency reasons
- Inference throughput and per-task cost are operational constraints — Ultra's efficiency profile is the best in its intelligence tier
- You are building long-running coding agents, enterprise RAG systems, or multi-agent orchestration pipelines
- You are already on NVIDIA Blackwell infrastructure and want to leverage NVFP4 optimization
- You want full transparency — weights, training data, recipes, reward models, all open
Consider alternatives if:
- You need maximum raw intelligence scores — Kimi K2.6 at 54 leads Ultra's 48 on the Index
- You need a 1M+ token context window without NVFP4 hardware — Nemotron 3 Super actually has a longer native context at BF16
- You are running on non-NVIDIA hardware — Ultra is specifically optimized for NVIDIA infrastructure
- Your budget is tight and Tier A coding quality at lower cost is the priority — Kimi K2.6 at $0.30/M input is cheaper
My overall take: the Intelligence Index gap with the Chinese open-weight frontier is real, but narrowing. Ultra is a 12-point improvement over Nemotron 3 Super, and it is clearly NVIDIA's most serious LLM bet to date. For US enterprises running agent infrastructure on NVIDIA hardware, this is the model to benchmark against your production workflows right now. For teams without hardware constraints or compliance requirements, Kimi K2.6 remains the raw benchmark leader.
If you are deciding between Ultra and other frontier models for a specific use case, the complete best AI model per task guide for 2026 breaks down model selection by workflow type, cost range, and deployment constraint.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Frequently Asked Questions
What is NVIDIA Nemotron 3 Ultra?
Nemotron 3 Ultra is NVIDIA's largest open-weight language model, announced at Computex 2026 on June 1 and released on June 4. It has 550 billion total parameters with 55 billion active per forward pass, uses a hybrid Mamba-Transformer MoE architecture, and scores 48 on the Artificial Analysis Intelligence Index — the highest score of any US-developed open-weight model as of June 2026.
How does Nemotron 3 Ultra compare to Kimi K2.6?
Kimi K2.6 scores 54 on the Intelligence Index compared to Ultra's 48, and leads on several reasoning benchmarks including GPQA Diamond. However, Ultra delivers 300+ tokens per second throughput on NVIDIA hardware, offers 30% lower per-task cost due to token efficiency, and is the clear choice for US-based enterprises with data residency requirements. On PinchBench agent productivity, the two models are essentially tied at 91%.
What is the difference between Nemotron 3 Super and Ultra?
Nemotron 3 Super has 120B total parameters with 12B active and scores 36 on the Intelligence Index. Ultra has 550B total parameters with 55B active and scores 48 — a 12-point capability jump. Super launched at GTC in March 2026; Ultra launched at Computex in June 2026. Super has a native 1M token context window in BF16, while Ultra supports 262k in BF16 and 1M with NVFP4 on Blackwell hardware. Super is the more cost-efficient choice for constrained deployments; Ultra is for maximum capability.
Can I run Nemotron 3 Ultra locally?
The BF16 weights require significant GPU infrastructure — multi-GPU setups with H100-class hardware are required for practical inference. NVIDIA's NVFP4 quantized format on Blackwell GPUs offers a more accessible path. For most developers without enterprise-grade GPU clusters, API access through DeepInfra ($0.37/M input) or OpenRouter is the practical starting point. The weights are fully open and downloadable from Hugging Face.
What is the Nemotron 3 Ultra context window?
In BF16 precision, the context window is 262,000 tokens. With NVFP4 quantization on NVIDIA Blackwell hardware, it extends to 1 million tokens. For comparison, Nemotron 3 Super supports 1M tokens natively in BF16.
Is Nemotron 3 Ultra open source?
Yes. NVIDIA has released the base model weights, post-trained checkpoints, reward models, NVFP4 quantized variants, training recipes, and datasets under the OpenMDW-1.1 license — a permissive open AI model license from the Linux Foundation. This is one of the most complete open releases from a major AI lab in recent memory.
What is the Nemotron 3 Ultra Intelligence Index score?
Nemotron 3 Ultra scores 48 on the Artificial Analysis Intelligence Index v4.0, which evaluates models across 10 categories including GPQA Diamond, Humanity's Last Exam, SciCode, Terminal-Bench Hard, IFBench, and AA-Omniscience. This is the highest score of any US-developed open-weight model as of June 2026, ahead of Gemma 4 31B (39), Nemotron 3 Super (36), and GPT-OSS 120B (33).
Recommended Reading
- NVIDIA AI Models 2026: Full Guide, Rankings & Comparisons — buildfastwithai.com
- Best AI for Coding 2026: Nemotron vs GPT-5.3 vs Claude Opus 4.6 — buildfastwithai.com
- NVIDIA Nemotron 3 Nano Omni: Full Review, Benchmarks & How to Run (2026) — buildfastwithai.com
- Every AI Model Compared: Best One Per Task (2026) — buildfastwithai.com
- Best AI Models May 2026: Winners, Losers & Full Comparison — buildfastwithai.com
- Best AI Models April + May 2026 Leaderboard — buildfastwithai.com
References
- NVIDIA Developer Blog — NVIDIA Nemotron 3 Ultra: Powers Faster, More Efficient Reasoning for Long-Running Agents
- Artificial Analysis — Nemotron 3 Ultra Launch Analysis & Intelligence Index Score
- Artificial Analysis — Nemotron 3 Ultra Model Profile: Intelligence, Performance & Pricing
- NVIDIA Research — Nemotron 3 Ultra Technical Report (PDF)
- NVIDIA Forums — Introducing Nemotron 3: Open Models for Agentic AI
- CodeRabbit Blog — Nemotron 3 Ultra Makes the Case for Fast, Open Coding Models
- ExplainX — NVIDIA Computex 2026: Complete Recap — Nemotron 3 Ultra, Cosmos 3
- Memeburn — NVIDIA Nemotron 3 Ultra: America's Best Open AI Model 2026

