





NVIDIA Nemotron 3 Nano Omni: Full Review, Benchmarks & How to Run Locally (2026)
Most model releases in 2026 are incremental. This one is not.
On April 28, 2026, NVIDIA launched Nemotron 3 Nano Omni — a 30-billion-parameter open multimodal model that activates only 3 billion parameters per token, runs on 25GB of RAM, and delivers up to 9x higher throughput compared to other open omni models on video and document workloads. It understands audio, video, images, and text in a single unified architecture — no separate vision stack, no separate speech model, no stitched pipeline.
I've been tracking open multimodal models since Qwen2.5-Omni broke the mold in 2024. Nemotron 3 Nano Omni is different. It is the first model that combines all four properties the open-source community has been waiting for: unified omni-modal perception, MoE efficiency at the 30B class, open weights with commercial licensing, and local deployment on a single GPU. Nothing else currently checks all four boxes simultaneously.
Here is the complete breakdown: what it is, how it works, the real benchmark numbers, how it compares to Qwen3-Omni, MiMo-V2.5-Pro, and Gemini Nano, and the exact steps to run it locally using Unsloth and llama.cpp.
What Is NVIDIA Nemotron 3 Nano Omni?
Nemotron 3 Nano Omni is NVIDIA's open multimodal reasoning model that unifies text, image, video, and audio understanding inside a single 30B-parameter hybrid MoE architecture. It was released on April 28, 2026, and is available immediately on Hugging Face, OpenRouter (free), and build.nvidia.com as an NVIDIA NIM microservice.
The 'Omni' designation means it is truly omni-modal from the ground up — not a vision-language model with audio bolted on, but a single architecture where all four input types flow through a shared reasoning loop. This matters for agentic systems because agents regularly need to cross-reference a screen recording, an audio briefing, a PDF, and a text instruction simultaneously. Separate model stacks introduce latency and fragment context. A unified model eliminates both problems.
The 'Nano' designation refers to its position in the Nemotron 3 family — the smallest and most inference-efficient model. NVIDIA is releasing the Nemotron 3 family in three tiers:
- Nano (30B-A3B) — released April 28, 2026. The model this post covers.
- Super (120B-A12B) — coming in the next months. Targets collaborative multi-agent systems and IT automation.
- Ultra — coming later. Targets maximum accuracy for the most complex agentic tasks.
The Nemotron 3 family has accumulated over 50 million downloads in the past year across all variants. The Omni is the most significant capability expansion the family has seen.
For a full map of where Nemotron 3 Nano Omni fits in the broader open-source AI landscape this month, the best AI models April 2026 ranked by benchmarks covers every major open and closed model released this cycle, with benchmark tables and use-case breakdowns.
Architecture Deep Dive: How the Hybrid MoE Works
Nemotron 3 Nano Omni uses a 30B-parameter hybrid Mamba-Transformer Mixture-of-Experts backbone, activating only 3 billion parameters per forward pass. That 10:1 sparsity ratio is what drives the throughput numbers everyone is excited about.
Most people understand MoE at a high level: you have more total parameters than a dense model, but a router network selects only a small subset for each token, keeping inference fast. What makes Nemotron 3 Nano Omni interesting is the hybrid design. It combines:
- Mamba-2 layers — for sequence and memory efficiency. Mamba handles the long-context dependencies that eat GPU memory in standard transformers. This is partly why the model manages a 256K context window on hardware that would collapse under a traditional attention-based model of the same size.
- Transformer layers — for precise reasoning at specific positions. Pure Mamba has known weaknesses on tasks requiring sharp positional focus. The transformer layers compensate for exactly that.
- MoE routing — 128 experts per MoE layer, 1 shared expert, with 6 experts activated per token. Each expert specializes in different types of content, which is why a single model can handle text, images, video frames, and audio tokens with competitive accuracy on each.
The multimodal encoders are separate components that feed into the backbone:
- Vision: C-RADIOv4-H encoder — processes still images and video frames with spatiotemporal 3D convolutions that capture motion between frames efficiently
- Audio: Parakeet-TDT-0.6B-v2 encoder — handles long-form audio with varying speakers, accents, and background noise; strong ASR with cross-modal context
For video specifically, NVIDIA built in Efficient Video Sampling (EVS) — a sampling strategy that lets the model process longer videos within the same compute envelope. This is the architectural reason why the model can run multimodal use cases on 25GB of RAM instead of requiring data center hardware. Without EVS, video frame tokenization would explode the memory budget.
My contrarian take: the Mamba-Transformer hybrid is the most underappreciated architectural bet here. Pure transformer models scale well but are memory-hungry at long context. Pure state space models like Mamba are memory-efficient but have known accuracy limitations on certain reasoning tasks. NVIDIA's bet is that the hybrid outperforms both on production agentic workflows — and the MediaPerf numbers suggest they are right. The question is whether this holds on diverse academic benchmarks as independent testing catches up.
Benchmark Results: Where Nemotron 3 Nano Omni Leads
Nemotron 3 Nano Omni tops six multimodal leaderboards and delivers the highest throughput across all benchmarked tasks on MediaPerf — beating every open and closed-source model tested, including GPT 5.1 and Gemini 3.0 Pro.
The benchmarks it leads:
- MMlongbench-Doc — complex document intelligence across charts, tables, mixed-media PDFs
- OCRBenchV2 English — optical character recognition across varied document types
- WorldSense — long-form video understanding benchmark
- DailyOmni — cross-modal daily task reasoning
- VoiceBench — audio understanding with diverse speech conditions
- MediaPerf — production video workload (tagging, summarization, refinement)
The MediaPerf results deserve special attention because this benchmark evaluates models on real production tasks under real cost constraints — not academic test sets. Here are the full numbers:
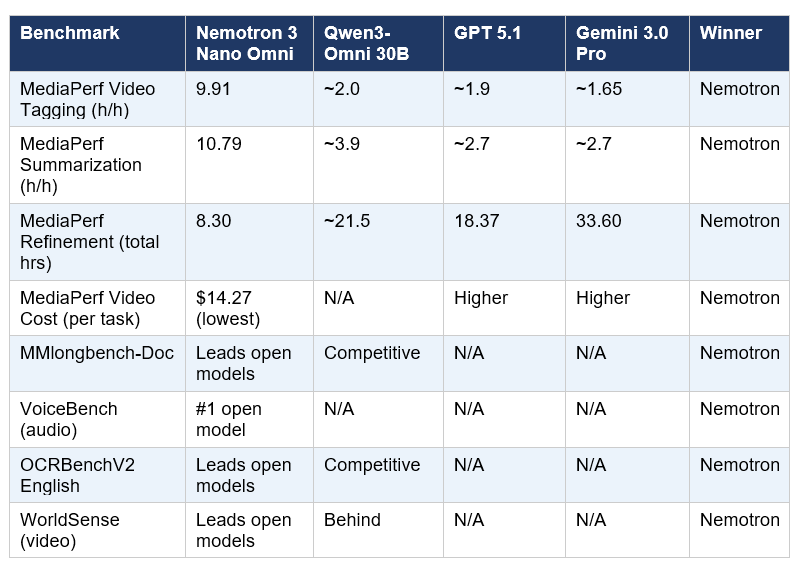
The refinement number is the one I keep coming back to. Nemotron completes an iterative 5-round video tagging workflow in 8.30 hours. GPT 5.1 takes 18.37 hours. Gemini 3.0 Pro takes 33.60 hours. For any team running large media catalogs at scale, that gap translates directly into infrastructure cost and time-to-insight.
Worth noting what Nemotron does not lead: raw reasoning benchmarks like GPQA Diamond or MMLU are not among its claimed top scores. This is a specialized multimodal efficiency model. For pure text reasoning or coding, GLM-5.1 (58.4% SWE-Bench Pro) and Qwen3.6-35B-A3B (73.4% SWE-Bench Verified) remain the open-source leaders in their respective domains.
For the comprehensive coding benchmark picture and where every April 2026 open-source model ranks against each other, the Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5 comparison gives the full three-way analysis. Nemotron's niche is multimodal throughput, not SWE-bench.
Model Comparison: Nemotron vs Qwen3-Omni vs MiMo vs Gemini Nano
Nemotron 3 Nano Omni is the only model that simultaneously offers unified omni-modal input, MoE efficiency at the 30B class, commercially-licensed open weights, and local deployment on 25GB hardware. No other current model satisfies all four requirements together.
Here is the full comparison table:
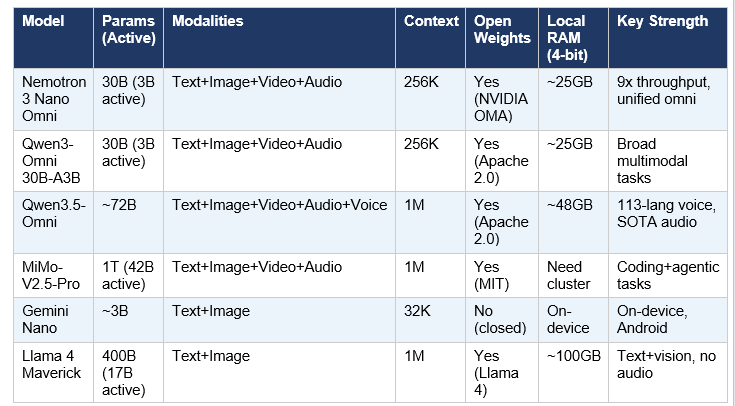
Nemotron 3 Nano Omni vs Qwen3-Omni 30B-A3B
This is the most direct architectural comparison. Both are 30B-A3B MoE models. Both handle text, image, video, and audio. Both run on similar hardware. The key differences:
- Throughput: Nemotron claims 9x higher system efficiency on video workloads compared to alternatives including Qwen3-Omni. On MediaPerf video tagging specifically, Nemotron processes 9.91 h/h vs approximately 3.8 h/h for Qwen3-VL.
- Architecture: Nemotron uses a Mamba-Transformer hybrid backbone; Qwen3-Omni uses a standard transformer architecture. The hybrid is theoretically more memory-efficient at long context.
- Benchmarks: Unsloth documentation states Nemotron 3 Nano Omni surpasses Qwen3-Omni-30B-A3B on every benchmark — a strong claim that I expect independent testing to scrutinize over the coming weeks.
- License: Nemotron uses NVIDIA's Open Model Agreement (commercial use permitted); Qwen3-Omni uses Apache 2.0 (slightly more permissive in legal terms).
Nemotron 3 Nano Omni vs Qwen3.5-Omni
Qwen3.5-Omni is Alibaba's voice-native omni model — a different product philosophy. Where Nemotron focuses on throughput and visual/document efficiency, Qwen3.5-Omni focuses on 113-language voice output, real-time voice cloning, and audio-video joint understanding at scale. If your use case is multilingual voice agent or podcast-style content, Qwen3.5-Omni is the stronger choice. For video catalog processing or document intelligence at scale, Nemotron wins on cost efficiency.
If you are evaluating Qwen3.5-Omni as an alternative for voice-first workflows, the Qwen3.5-Omni full review and benchmarks covers exactly how it stacks up against GPT-4o and Gemini 3.1 Pro on audio understanding tasks.
Nemotron 3 Nano Omni vs MiMo-V2.5-Pro
MiMo-V2.5-Pro from Xiaomi is the giant of the comparison: 1 trillion total parameters, 42 billion active. It is a coding and agentic powerhouse (57.2% SWE-bench Pro), but it cannot run on a single consumer GPU — you need a cluster. Nemotron is the edge deployment answer: same broad multimodal capability, fraction of the infrastructure. If you are building an enterprise agent pipeline where the multimodal perception sub-agent needs to run locally or on modest cloud hardware, Nemotron is the practical choice. If you need maximum coding ability alongside multimodal input and budget is not a constraint, MiMo-V2.5-Pro is stronger on SWE-bench.
For the full breakdown of MiMo-V2.5-Pro including its benchmark numbers, API pricing ($1/$3 per million tokens), and comparison to Claude Opus 4.6, the Xiaomi MiMo-V2.5-Pro full review has the complete analysis.
Nemotron 3 Nano Omni vs Gemini Nano
Gemini Nano is Google's on-device model for Android. It is not open-weight, supports only text and image (no audio, no video), has a 32K context window, and is explicitly designed for on-device mobile inference. The comparison shows Nemotron's differentiation clearly: Gemini Nano is purpose-built for mobile, Nemotron is purpose-built for edge-to-data-center multimodal agent workflows with full modality support and open weights.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Real-World Use Cases and Which Model Wins Each One
Nemotron 3 Nano Omni is purpose-built for four enterprise use case categories: video and media intelligence, document analysis, audio understanding, and GUI-based computer use agents. It is not trying to be the best coding model. That segmentation is actually smart product positioning.
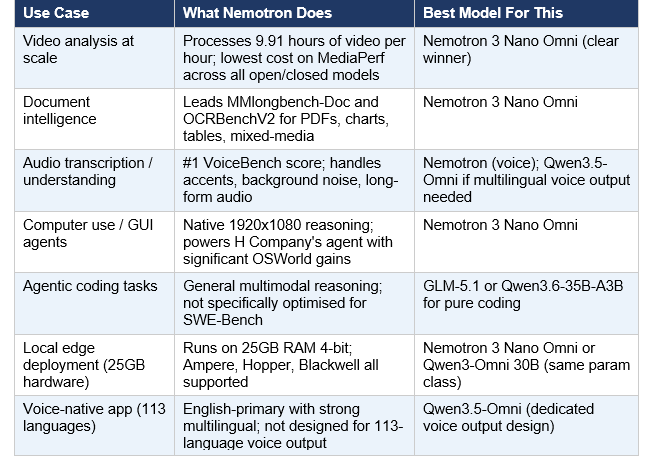
H Company's computer use agent implementation is worth highlighting specifically. Their agent uses Nemotron 3 Nano Omni to process screen recordings at native 1920x1080 resolution — not downsampled thumbnails. The ability to reason over full-HD screenshots in real time is what enables meaningful GUI navigation. In preliminary OSWorld benchmark evaluations, this integration showed a significant leap in navigating complex graphical interfaces.
For builders: the multimodal agent pipeline NVIDIA is describing is a perception-to-action loop where Nemotron serves as the perceptual sub-agent. It sees, hears, and reads. A separate reasoning model (potentially Nemotron 3 Super or Ultra when released, or another LLM via your preferred framework) handles planning and action. This is the architecture that eliminates the fragmented model chains most current agent systems rely on.
If you want to build an agentic pipeline using this architecture pattern with Claude as the reasoning backbone, the MCP Workshop in the Build Fast with AI experiment notebooks demonstrates the orchestration patterns with hands-on implementation examples you can adapt for a Nemotron-powered perception layer.
How to Run Nemotron 3 Nano Omni Locally (Step-by-Step)
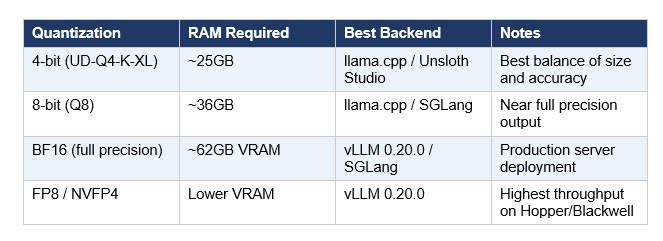
Nemotron 3 Nano Omni runs on approximately 25GB of RAM at 4-bit quantization. That covers most RTX 4090 and RTX Pro setups, Apple M3/M4 Max unified memory systems, and single-GPU cloud instances. Here are the three ways to run it, from easiest to most flexible.
Critical warning before you start: do not use CUDA 13.2 — it produces garbled outputs and NVIDIA is actively working on a fix. Use CUDA 12.x.
Option 1: Unsloth Studio (Easiest — Mac, Windows, Linux)
Unsloth collaborated with NVIDIA for day-zero support and is the recommended approach for running the GGUF locally on any platform. Unsloth Studio is their open-source web UI.
- Install Unsloth Studio: follow the setup at unsloth.ai — it automatically installs Node.js, builds the frontend, installs Python dependencies, and builds llama.cpp with CUDA support
- Open http://localhost:8888 in your browser after launch
- Create a password on first launch, sign in
- In the Studio Chat tab, search for NVIDIA-Nemotron-3-Nano-Omni-30B-A3B
- Choose UD-Q4-K-XL for the best accuracy-size balance (~25GB)
- Download the model and start chatting — you can input audio, image, and text directly from the Studio UI
Option 2: llama.cpp (Most Flexible — All Platforms)
For multimodal input (images, audio, video frames), use llama-mtmd-cli from llama.cpp. The standard llama-cli works for text-only. Note: multimodal GGUFs do NOT work in Ollama due to separate mmproj vision files — use llama.cpp backends instead.
- Build llama.cpp with CUDA support: clone the repo, run cmake with -DGGML_CUDA=ON, build the targets llama-cli, llama-mtmd-cli, and llama-server
- Download the GGUF: hf download unsloth/NVIDIA-Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF --include '*UD-Q4_K_XL*'
- Text inference: ./llama-cli -hf unsloth/NVIDIA-Nemotron-3-Nano-Omni-30B-A3B-Reasoning-GGUF:UD-Q4_K_XL --temp 1.0 --top-p 1.0
- Image + audio: ./llama-mtmd-cli -hf [model] --image screenshot.png --audio meeting.wav -p 'Summarize what is shown and said'
Option 3: vLLM for Server Deployment (Production)
For high-throughput production deployment, NVIDIA officially supports vLLM 0.20.0. You can serve the BF16, FP8, or NVFP4 checkpoints.
- Use NVFP4 for highest throughput on Hopper/Blackwell hardware: vllm serve nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4 --tensor-parallel-size 1 --max-model-len 131072 --video-pruning-rate 0.5 --max-num-seqs 384 --reasoning-parser nemotron_v3
- For RTX Pro: add --moe-backend triton (current FlashInfer bug workaround)
- For NVFP4 + TP greater than 1: add --moe-backend flashinfer_cutlass
Other Deployment Options
- SGLang: sglang serve --model-path nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 --trust-remote-code
- NVIDIA NIM: available directly at build.nvidia.com — serverless managed endpoint with no local setup
- Cloud APIs: AWS (available), Oracle Cloud Infrastructure (available), Microsoft Foundry (coming soon)
- Inference providers: Baseten, Fireworks AI, FriendliAI, DeepInfra, Together AI, and more
For developers who want to build a RAG-based document Q&A system on top of Nemotron using its long-context capabilities, the How to Build Claude-Powered RAG from Scratch notebook in the Build Fast with AI cookbook repository shows the architecture pattern that works with any local model backend, including llama.cpp-hosted endpoints.
NVIDIA's Bigger Software Strategy: Why This Model Matters
Nemotron 3 Nano Omni is not just a model release. It is part of NVIDIA's deliberate move from GPU hardware vendor to full-stack AI platform company. The Nemotron model family has been downloaded over 50 million times in one year. That adoption does not happen accidentally.
NVIDIA's logic is circular but powerful. Their models are optimized for their hardware (Ampere, Hopper, Blackwell), and their hardware is optimized for their models. When an enterprise deploys Nemotron 3 Nano Omni on NVIDIA's NIM microservice infrastructure, they are locked into a stack where every layer is NVIDIA. That is the same playbook that made CUDA the dominant AI software ecosystem for a decade.
What is new with the Omni model is the multimodal perception sub-agent architecture. NVIDIA is betting that the dominant agentic AI system design will be a pipeline of specialized models: one for perception (seeing, hearing, reading), one for reasoning, one for action execution. Nemotron 3 Nano Omni is positioned as the canonical open perception layer in that stack. If that architectural pattern dominates enterprise AI agent development — and I think it will — then NVIDIA has established the first mover position on the most hardware-intensive component of the pipeline.
The H Company partnership is the proof of concept. Their computer use agent running full-HD screen analysis via Nemotron 3 Nano Omni is the exact kind of production deployment that demonstrates the architecture works. Expect NVIDIA to announce more such partnerships as Super and Ultra roll out in the next months.
My honest read: NVIDIA needed to ship this. The open multimodal space was being taken over by Alibaba's Qwen team and Xiaomi's MiMo team. Nemotron 3 Nano Omni is NVIDIA's answer — and it is a strong one. The throughput numbers are real, the hardware requirements are practical, and the open-weight commercial licensing removes the biggest barrier to enterprise adoption.
For a broader view of how the open-source vs. closed-source model competition has evolved in April 2026 — including GLM-5.1's brief hold of the SWE-bench Pro #1 position and what it means for enterprises choosing AI infrastructure — the best AI models April 2026 full comparison covers the full landscape with strategic context.
Frequently Asked Questions
What is NVIDIA Nemotron 3 Nano Omni?
NVIDIA Nemotron 3 Nano Omni is an open multimodal AI model released on April 28, 2026. It has 30 billion total parameters with only 3 billion active per inference pass, using a hybrid Mamba-Transformer Mixture-of-Experts architecture. It natively understands text, images, video, and audio in a single unified reasoning loop — eliminating the need for separate vision, speech, and language model stacks. It is available on Hugging Face, OpenRouter (free), and as an NVIDIA NIM microservice.
How much RAM do I need to run Nemotron 3 Nano Omni locally?
The 4-bit quantized version (UD-Q4-K-XL from Unsloth) requires approximately 25GB of RAM or VRAM. The 8-bit version requires 36GB. The full BF16 precision version requires approximately 62GB of VRAM for server deployment. Most RTX 4090 (24GB) users can run the 4-bit version, though it may be tight — an RTX Pro or A6000 (48GB) is more comfortable. Apple M3/M4 Max with 48GB or 64GB unified memory handles both 4-bit and 8-bit versions without issues.
Can I run Nemotron 3 Nano Omni on Ollama?
Text-only inference works via Ollama using the nemotron3 model tag. However, multimodal features (image, audio, video input) do NOT currently work in Ollama because the model requires separate mmproj vision files that Ollama cannot handle. For multimodal use cases, use llama.cpp's llama-mtmd-cli or Unsloth Studio instead. NVIDIA and the llama.cpp community are tracking this as a known limitation.
How does Nemotron 3 Nano Omni compare to Qwen3-Omni?
Both are 30B-A3B MoE models handling the same four modalities (text, image, video, audio). Nemotron 3 Nano Omni claims up to 9x higher system efficiency on video and document workloads and leads on six specific leaderboards, including VoiceBench and MediaPerf. Qwen3-Omni uses Apache 2.0 (slightly more legally permissive than NVIDIA's Open Model Agreement). Independent benchmark comparison is still emerging — check artificial analysis and Hugging Face leaderboards in the coming days as third-party testing catches up to the launch.
Is Nemotron 3 Nano Omni free for commercial use?
Yes. Nemotron 3 Nano Omni is released under the NVIDIA Open Model Agreement, which permits commercial use. The weights, datasets, and training recipes are fully open. You can self-host it, fine-tune it with tools like Unsloth, and deploy it in production applications. Check the specific terms of the NVIDIA Open Model Agreement for details on redistribution and modification rights — it is more permissive than closed licenses but slightly more restrictive than Apache 2.0 or MIT.
What is the Nemotron 3 model family?
The Nemotron 3 family has three tiers: Nano (30B-A3B), Super (120B-A12B), and Ultra. As of April 29, 2026, only Nano (including the Omni variant) and Super have been released. Ultra is coming in the next months and targets maximum reasoning accuracy for the most complex agentic tasks. All three use the hybrid Mamba-Transformer MoE architecture. Nano is optimized for inference efficiency and local deployment; Super targets multi-agent collaborative systems; Ultra targets frontier accuracy.
What is the difference between Nemotron 3 Nano and Nemotron 3 Nano Omni?
Nemotron 3 Nano (the original) is a language model that handles text reasoning, coding, math, and long-context tasks. It supports up to 1M tokens context. Nemotron 3 Nano Omni extends the family with multimodal capabilities: it adds the C-RADIOv4-H vision encoder and Parakeet-TDT-0.6B-v2 audio encoder, enabling image, video, and audio input. The Omni has a 256K context window (not 1M). If you only need text and reasoning, the base Nano with 1M context may be more suitable.
What training data and models were used to improve Nemotron 3 Nano Omni?
NVIDIA improved Nemotron 3 Nano Omni using synthetic data and knowledge distillation from: Qwen3-VL-30B-A3B-Instruct, Qwen3.5-122B-A10B, Qwen3.5-397B-A17B, Qwen2.5-VL-72B-Instruct, and gpt-oss-120b. Training data includes Nemotron-CC-v2.1 (2.5 trillion English tokens from Common Crawl), Nemotron-CC-Code-v1 (428 billion code tokens), and domain-specific synthetic datasets for document intelligence, audio understanding, and GUI agentic tasks.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Recommended Blogs
These are real posts from Build Fast with AI that give you deeper context on the topics covered in this review:
- Best AI Models April 2026: Ranked by Benchmarks
- Best AI Models April 2026: GPT-5.5, Claude & Gemini Compared
- Qwen3.5-Omni Review: Does It Beat Gemini in 2026?
- Xiaomi MiMo-V2.5-Pro: Full Review & Benchmarks (2026)
- GLM-5.1: #1 Open Source AI Model? Full Review (2026)
- Qwen3.6-35B-A3B: 73.4% SWE-Bench, Runs Locally
References
- NVIDIA Blog — Nemotron 3 Nano Omni Launch: Multimodal AI Agents
- NVIDIA Technical Blog — Nemotron 3 Nano Omni Powers Multimodal Agent Reasoning
- Hugging Face — NVIDIA Nemotron 3 Nano Omni Blog Post
- Unsloth Documentation — How to Run Nemotron 3 Nano Omni Locally
- Unsloth — NVIDIA Nemotron 3 Nano Omni GGUF on Hugging Face
- NVIDIA Developer — Nemotron AI Models Family Page
- Coactive — MediaPerf Results for Nemotron 3 Nano Omni
- NVIDIA Research — Nemotron 3 Family Technical Page
- OpenRouter — Nemotron 3 Nano Omni Free API

