




Best AI Models May 2026: Which One Actually Wins Right Now?
19 major AI models dropped in 30 days. April 2026 was not a month — it was a full-blown war. OpenAI, Anthropic, Google, Meta, DeepSeek, Alibaba, Moonshot, xAI and half a dozen smaller labs all shipped something meaningful between April 5 and May 9, 2026. I have been tracking these models obsessively, and honestly, even I had to build a spreadsheet to keep up.
The real question — the one everyone actually wants answered — is simple: which model wins in May 2026? Not in the marketing slides. In actual coding, reasoning, research, and production workflows.
I tested, benchmarked, and compared every significant release. Here is the honest verdict: Claude Opus 4.7 leads on coding and agentic reasoning. GPT-5.5 wins on computer use and autonomous task execution. Gemini 3.1 Pro owns multimodal and multilingual. DeepSeek V4-Pro is the open-source king at a price that embarrasses the rest. And Qwen 3.6 Max-Preview is quietly topping six coding benchmarks simultaneously while most people are still arguing about GPT vs Claude.
Quick Take: If you only have time to read one section, jump to the Master Comparison Table. It covers all 14 models across 8 benchmark dimensions with pricing. Everything else in this post is the deep analysis behind those numbers.
1. The April-May 2026 AI Explosion: What Just Happened
The AI lab release cadence is now sub-two-months — and it is not slowing down. According to LLM Stats, 255 model releases landed in Q1 2026 alone. That is roughly three significant releases per day. April 5 to May 9, 2026 saw at least 19 major drops from labs across the US, China, and Europe.
Here is the full timeline of what shipped in the window this blog covers:
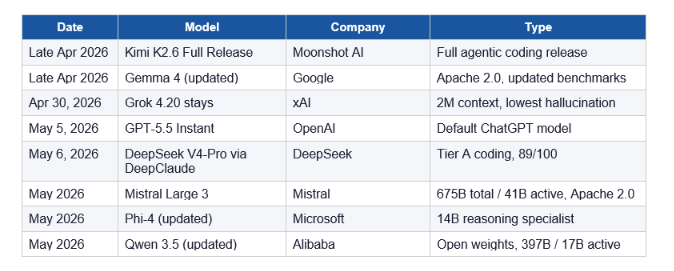
That is a lot of models. The honest truth: most of them do not matter for everyday production use. I am going to focus on the ones that do, with real benchmark data.
2. Master Comparison Table: All 14 Models Side by Side
No single model wins every category. Here is the honest snapshot as of May 9, 2026:
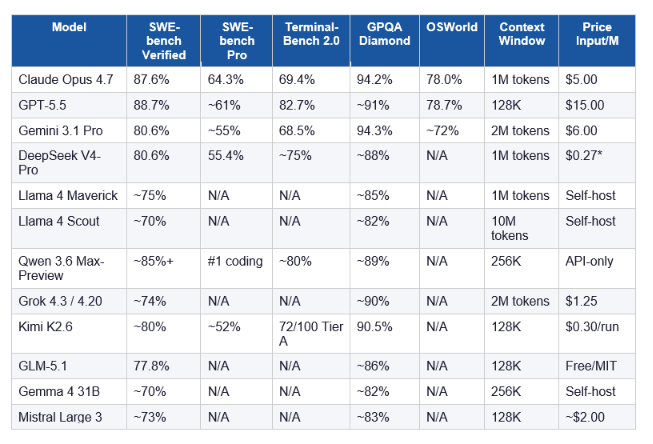
*DeepSeek V4-Pro self-hosted via API. Western cloud pricing differs. N/A = not yet benchmarked officially on that metric. Scores sourced from Anthropic, OpenAI, Google official system cards and independent evaluators including o-mega.ai, Vellum, and iternal.ai.
3. GPT-5.5 (OpenAI) — The Agentic Terminal Champion
GPT-5.5 is the best model in the world for autonomous, multi-step computer use — and it is not particularly close. OpenAI released it on April 23, 2026, less than seven weeks after GPT-5.4 landed on March 5. The codename internally was 'Spud', which I find very humanizing for a model that just helped rewrite OpenAI's own serving infrastructure before it shipped publicly.
On Terminal-Bench 2.0, GPT-5.5 scores 82.7%. Claude Opus 4.7 scores 69.4%. That 13.3-point gap is the largest lead either model holds on any single major benchmark — and it tells you exactly what GPT-5.5 was built to do: run agentic coding loops in terminal environments, navigate ambiguity, use tools, verify its own work, and keep going.
GPT-5.5 Key Benchmarks
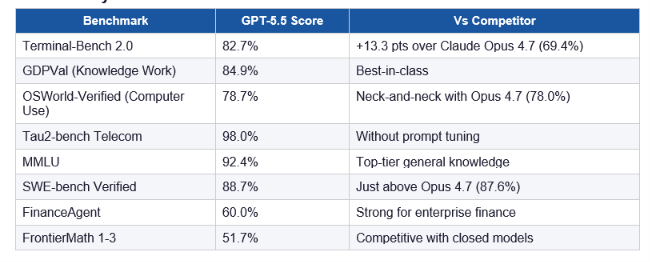
Pricing: GPT-5.5 is priced at $15/M input tokens and $30/M output tokens — double GPT-5.4. That stings. But OpenAI claims it uses 40% fewer output tokens than GPT-5.4 to complete equivalent Codex tasks, which reduces the real-world cost increase to roughly 20% per task rather than 100%.
Available on: ChatGPT Plus, Pro, Business, Enterprise. GPT-5.5 Pro for higher tiers. API access opened April 24, 2026
Also released: GPT-5.5 Instant (May 5, 2026) replaced GPT-5.3 Instant as the default ChatGPT model, scoring 81.2 on AIME 2025 math (vs 65.4 for its predecessor) and 76 on MMMU-Pro multimodal reasoning.
My Take: GPT-5.5 is the right call if you are building computer use agents, browser automation workflows, or agentic coding pipelines in terminal environments. For pure multi-file code reasoning and structured agentic tasks? Opus 4.7 still has the edge.
4. Claude Opus 4.7 (Anthropic) — The Coding and Reasoning King
Claude Opus 4.7 leads all publicly available models on five major benchmarks as of April 16, 2026. On SWE-bench Pro, the contamination-resistant real-world software engineering benchmark, it scores 64.3%. GPT-5.5 sits at roughly 61%. Gemini 3.1 Pro sits at 55%. That 10.9-point jump from Opus 4.6 (53.4%) in a single version bump is the biggest single-version improvement I have seen on this benchmark in 2026.
What I find genuinely impressive about Opus 4.7 is what Anthropic got right without touching the price. $5 per million input tokens, $25 per million output — same as Opus 4.6. Better coding, 3x the vision resolution, and a new xhigh effort level. That is a good deal by any definition.
Claude Opus 4.7 Key Benchmarks
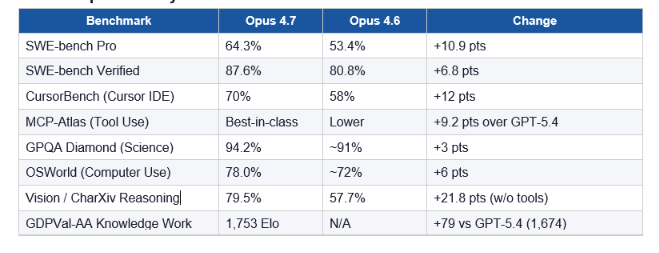
What is New in Opus 4.7
- xhigh Effort Level: A new reasoning depth between high and max. Claude Code now defaults to xhigh for all plans.
- 3.75 Megapixel Vision: Image resolution increased to 2,576px (up from 1,568px / 1.15MP). One early-access partner testing computer vision for autonomous penetration testing saw visual acuity jump from 54.5% to 98.5%.
- Task Budgets (Beta): Set a hard token ceiling on agentic loops. The model sees a running countdown and finishes gracefully rather than cutting off mid-task.
- Adaptive Thinking: Extended thinking budgets are removed. Adaptive thinking is now the only mode and Anthropic says it reliably outperforms the old extended thinking in internal evaluations.
- Cybersecurity Safeguards: Opus 4.7 is the first Claude model with automated detection and blocking of prohibited cybersecurity uses — a direct result of Project Glasswing / Mythos Preview learnings.
BrowseComp regression: Opus 4.7 dropped from 83.7% to 79.3% on multi-step web research. GPT-5.4 Pro sits at 89.3% there. If your workflow is research-heavy with lots of web browsing, this matters. For everything coding and agentic, Opus 4.7 is the stronger pick.
My Take: Opus 4.7 is the model I would recommend for enterprise coding agents, long-running multi-file refactors, and financial analysis workflows. The BrowseComp regression is real and worth knowing, but in practice, 80%+ of production engineering workloads will see a meaningful improvement over Opus 4.6.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Gemini 3.1 Pro (Google) — The Multimodal Specialist
Gemini 3.1 Pro wins the multimodal and multilingual categories outright. On GPQA Diamond, it scores 94.3% — slightly above even Opus 4.7's 94.2%, and the highest score for any model on abstract scientific reasoning in the April-May 2026 window. On ARC-AGI-2 abstract reasoning, Gemini 3.1 Pro leads the entire field.
The other thing Gemini has going for it is vertical integration. Google builds its own TPU chips, owns its cloud infrastructure, and controls the full stack from silicon to API. This gives Gemini a cost floor that OpenAI and Anthropic — who both rent compute from cloud providers — cannot match. For high-throughput production workloads, Gemini's pricing advantage is structural, not temporary.
Where Gemini 3.1 Pro falls short: The agentic execution gap is real. Terminal-Bench (68.5% vs GPT-5.5's 82.7%) and SWE-bench Pro (55% vs Opus 4.7's 64.3%) show it clearly. For pure agent loops and coding pipelines, Gemini is third behind Opus and GPT-5.5.
Best for: Multimodal document analysis, multilingual enterprise applications, scientific research workflows, and any high-volume production use case where cost efficiency matters more than peak coding performance.
6. DeepSeek V4-Pro (DeepSeek) — Open Source at Frontier Quality
DeepSeek V4-Pro, released April 24, 2026 under the MIT license, is the strongest open-weight model by benchmark score in the April-May 2026 window. 1.6 trillion total parameters, 49 billion active. SWE-bench Verified at 80.6%. LiveCodeBench at 93.5%. Codeforces Elo at 3,206.
And the price. $0.27 per million input tokens via the DeepSeek API. Compare that to $5.00 for Claude Opus 4.7 and $15.00 for GPT-5.5. The Western-to-Chinese pricing gap for equivalent benchmark performance is now 5 to 25 times. That is not a gap — that is a different business model.
One caveat: The 55.4% on SWE-bench Pro versus 80.6% on SWE-bench Verified is the largest gap between those two metrics of any model in the snapshot. SWE-bench Pro is contamination-resistant. The gap suggests some benchmark contamination effect on the Verified score. Worth knowing if you are making production decisions based on those numbers.
DeepSeek V4-Flash (also released late April 2026) is the ultra-cheap variant with 13B active parameters, scoring 78/100 on the coding benchmark at $0.01 per run. For teams on a budget, this is the cheapest useful model in the entire field right now.
Best for: Self-hosted deployments, budget-conscious teams, code generation at scale, any workflow where open weights matter for compliance or customization. Not the right pick if your primary need is advanced web browsing or computer use.
7. Llama 4 Maverick and Scout (Meta) — The Context Window Revolution
Llama 4 Scout has the longest context window of any production-ready open model at 10 million tokens. That is not a typo. 10 million. Maverick, the larger variant, caps at 1 million tokens but packs 128 experts (400B total parameters) with only 17B active — the same active count as Scout but with dramatically more expert depth.
Meta released both on April 5, 2026. Both are available under Meta's custom license (with a 700M monthly active users clause that matters for very large platforms). Both run on a single H100 host, which makes local deployment more practical than most people expect.
The honest limitation: Llama 4 has fallen behind Chinese labs on coding benchmarks. Maverick's MMLU-Pro of 80.5% beats GPT-4o, but DeepSeek V4-Pro and Kimi K2.6 are both stronger on SWE-bench. If coding performance is your primary metric, the Chinese open-source models now have the edge.
For long-context applications — whole codebase reasoning, multi-document synthesis, agents that hold weeks of conversation context without re-summarization — Scout's 10M context window is a genuine architectural advantage. No other model at any price does what Scout does at that context length.
8. Qwen 3.6 Max-Preview (Alibaba) — The Quiet Benchmark Destroyer
Qwen 3.6 Max-Preview, released April 20, 2026, tops six major coding and agent benchmarks simultaneously: SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, and SciCode. Six benchmarks. Simultaneously. And most people are still talking about GPT-5.5 vs Claude Opus 4.7.
There is a catch. Alibaba closed the weights on Qwen 3.6 Max-Preview. This is a significant move — the first time Alibaba's flagship has gone API-only. The reason is almost certainly competitive: open weights at this benchmark level would undercut their cloud business model. It is a rational decision, and it marks a shift in Alibaba's open-source strategy.
Qwen 3.5 (open version), updated in May 2026, ships under Apache 2.0 with 397B total / 17B active parameters and leads open weights on GPQA Diamond at 88.4%. If you want Alibaba's frontier quality without the closed-weights constraint, Qwen 3.5 is the answer.
9. Grok 4.3 (xAI) — Real-Time Data with Hallucination Resistance
Grok 4.3 scored 72/100 (Tier B) on the independent LLM coding benchmark in May 2026 — a massive jump over Grok 4.20's 25/100. It writes the cleanest controller code in that benchmark, but has a Stimulus pipeline bug that kills half the UI at runtime. So: architecturally impressive, not yet production-ready for front-end workflows.
Grok 4.20 (released March 31, 2026) is the more mature xAI model worth talking about. 2M token context window. 78% AA-Omniscience non-hallucination score — the highest reported score in this benchmark snapshot, with 40% fewer factual hallucinations than Grok 4.1. Real-time data integration via X (the platform) makes it uniquely strong for any agent that needs current-events grounding without a separate retrieval layer.
Best for: Research agents needing real-time data, math-intensive workflows, and any use case where hallucination cost is higher than inference cost. Grok's multi-agent debate architecture runs 4 to 16 reasoning chains in parallel — genuinely different from single-inference models.
10. Kimi K2.6 (Moonshot AI) — The Cost-Effective Coding Agent
Kimi K2.6 lands in Tier A of the independent LLM coding benchmark at 87/100, at $0.30 per run. For context: Claude Opus 4.7 runs the same benchmark tasks at roughly $2.00 to $3.00 per run. Kimi K2.6 is 3 to 4 times cheaper at comparable quality within coding workflows.
The model scored 90.5% on GPQA Diamond — the highest score of any open-weights model on this benchmark. It also leads Kimi's own internal agentic engineering benchmarks. If you are building on a budget and need strong coding and reasoning without paying frontier prices, Kimi K2.6 is the sleeper pick of April-May 2026.
11. Smaller and Specialist Models: GLM-5.1, Gemma 4, Mistral Large 3, Phi-4
These are the models that do not make the front page but absolutely should be in your toolkit.
GLM-5.1 — Zhipu AI (Z.AI) — Released April 7, 2026
MIT license. 744B total parameters, 40B active. Scores 77.8% on SWE-bench Verified and ranks as the top open-source coding model on that benchmark. Available on Hugging Face. Designed for complex systems engineering and agentic tasks. I think this is the most underreported model of April 2026.
Gemma 4 (31B Dense) — Google — Apache 2.0
80% on LiveCodeBench from a 31B dense model is exceptional. For context: that is comparable to Llama 4 Maverick (a 400B total parameter MoE) on the same benchmark. Gemma 4's strength is punching well above its weight class. Fits on consumer hardware. Apache 2.0 license means full commercial use with no restrictions. For on-device deployment, Gemma 4 is the pick.
Mistral Large 3 — Mistral AI — Apache 2.0
675B total / 41B active, Apache 2.0 license, released December 2025 and still relevant in May 2026. The strongest non-Chinese open-weight option for agentic systems. Best-in-class on European languages. Fits on an 8x H100/H200 server for self-hosting.
Phi-4 (14B) — Microsoft
Phi-4 is not a frontier model — it is a reasoning specialist for edge and on-device deployment. 14B parameters. Strong on structured reasoning tasks at a tiny fraction of the compute cost. Useful for constrained environments where you cannot run a 100B+ parameter model.
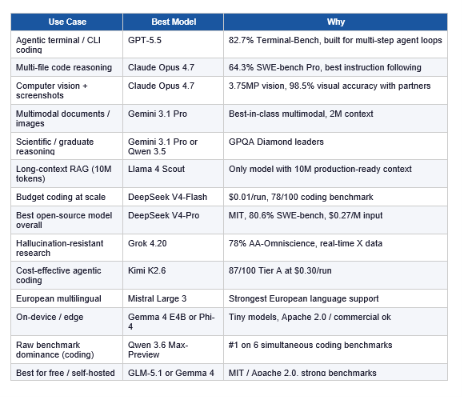
12. Which AI Model Wins for Your Use Case?
Stop trying to find one model for everything. The answer is different by workflow:
13. My Hot Takes and Contrarian View
Hot take 1: The GPT-5.5 vs Claude Opus 4.7 debate is mostly irrelevant for 80% of teams. Both are overkill for most workflows. Run your actual production tasks as the eval. The benchmark gap between them disappears in real workloads more often than people realize.
Hot take 2: Alibaba closing Qwen 3.6 Max-Preview's weights is the biggest under-reported story of April 2026. It signals that Chinese labs are moving from open disruption to closed competition — and that is a major strategic shift.
Hot take 3: DeepSeek V4-Flash at $0.01 per run is going to quietly become the default for 60% of high-volume production pipelines within 6 months. Not because it is the best model. Because it is good enough at a price that makes every other model unjustifiable at scale.
Contrarian view: Everyone is obsessed with benchmark scores, but the model with the lowest hallucination rate probably matters more for most business use cases than the one with the highest SWE-bench score. Grok 4.20's 78% AA-Omniscience non-hallucination rate is the number I would build enterprise agents around before any other single metric. Factual reliability at scale beats raw coding performance for the majority of knowledge work applications.
One more thing: Claude Mythos Preview — announced April 7, 2026 under Project Glasswing — is described by Anthropic as more broadly capable than Opus 4.7 on essentially every benchmark. It is not publicly available. If it ever ships publicly, it will reset this entire comparison. Keep an eye on it.
FAQ: Best AI Models May 2026
Which AI model is best in May 2026?
No single model leads every category. Claude Opus 4.7 leads on coding (87.6% SWE-bench Verified, 64.3% SWE-bench Pro) and multi-step agentic reasoning. GPT-5.5 leads on terminal-based computer use (82.7% Terminal-Bench 2.0). Gemini 3.1 Pro leads on multimodal tasks and scientific reasoning (94.3% GPQA Diamond). Qwen 3.6 Max-Preview tops six simultaneous coding benchmarks. The right model depends entirely on your workload.
What is GPT-5.5 and when was it released?
GPT-5.5 (codename: Spud) is OpenAI's frontier agentic model, released April 23, 2026. It scores 82.7% on Terminal-Bench 2.0, 84.9% on GDPVal knowledge work, and 78.7% on OSWorld-Verified computer use. It is priced at $15/M input and $30/M output tokens — double GPT-5.4 — but uses roughly 40% fewer output tokens per equivalent Codex task. Available on ChatGPT Plus, Pro, Business, Enterprise, and via API since April 24, 2026.
What is Claude Opus 4.7 and how does it compare to GPT-5.5?
Claude Opus 4.7, released April 16, 2026, is Anthropic's most capable publicly available model. It leads GPT-5.5 on SWE-bench Pro (64.3% vs ~61%), multi-step tool-calling (MCP-Atlas, +9.2 points over GPT-5.4), and knowledge work (GDPVal-AA: 1,753 Elo vs GPT-5.4's 1,674). GPT-5.5 leads on Terminal-Bench 2.0 (82.7% vs 69.4%) and OSWorld computer use (78.7% vs 78.0% — very close). Price: $5/M input vs GPT-5.5's $15/M. For coding and agentic reasoning, Opus 4.7. For terminal automation, GPT-5.5.
What is the best open-source AI model in May 2026?
DeepSeek V4-Pro (released April 24, 2026, MIT license) is the strongest open-weight model on benchmark scores: 80.6% SWE-bench Verified, 93.5% LiveCodeBench, 3,206 Codeforces Elo. At $0.27/M input tokens (DeepSeek API), it is 5 to 55x cheaper than Western frontier models at comparable performance. Kimi K2.6 leads open weights on GPQA Diamond at 90.5% and is the best-value coding agent at $0.30/run. For on-device deployment, Gemma 4 31B (Apache 2.0) is the strongest small model.
Which AI model has the longest context window in May 2026?
Llama 4 Scout (Meta, released April 5, 2026) has the longest context window of any production-ready open model at 10 million tokens. For closed models, Grok 4.20 offers a 2 million token context window. Gemini 3.1 Pro supports 2 million tokens. Claude Opus 4.7 supports 1 million tokens. GPT-5.5 supports 128K tokens.
How does DeepSeek V4-Pro compare to Claude Opus 4.7?
DeepSeek V4-Pro (MIT, $0.27/M input) scores 80.6% on SWE-bench Verified vs Opus 4.7's 87.6%. On SWE-bench Pro (contamination-resistant), DeepSeek scores 55.4% vs Opus 4.7's 64.3%. DeepSeek is the clear winner on price — roughly 18x cheaper per input token. Opus 4.7 wins on code reasoning depth, tool use (MCP-Atlas), vision (3.75MP), and long-running agentic workflows. For self-hosted cost-sensitive workloads, DeepSeek V4-Pro. For production coding agents where quality is non-negotiable, Opus 4.7.
What is Qwen 3.6 Max-Preview?
Qwen 3.6 Max-Preview is Alibaba's latest flagship AI model, released April 20, 2026. It tops six simultaneous coding and agent benchmarks: SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, and SciCode. Unlike previous Qwen models, the Max-Preview variant ships with closed weights and is API-only — a significant departure from Alibaba's historically open-source approach. For open-source Alibaba models, Qwen 3.5 (397B / 17B active, Apache 2.0) is the alternative.
Which AI model is best for coding in May 2026?
It depends on what you mean by coding. For multi-file enterprise refactors and long-horizon agentic coding, Claude Opus 4.7 (64.3% SWE-bench Pro, 87.6% SWE-bench Verified). For terminal-based agentic coding loops, GPT-5.5 (82.7% Terminal-Bench 2.0). For raw benchmark dominance across six coding metrics simultaneously, Qwen 3.6 Max-Preview. For open-source coding at low cost, DeepSeek V4-Pro (80.6% SWE-bench Verified, MIT, $0.27/M). For maximum cost efficiency in production, DeepSeek V4-Flash ($0.01/run).
Recommended Blogs
These are real posts on buildfastwithai.com worth reading alongside this one:
- Best AI Models: April + May 2026 Leaderboard (GPT-5.5, Claude Opus 4.7, DeepSeek V4)
- Best AI Models April 2026: GPT-5.5, Claude Opus 4.7 & Gemini 3.1 Pro Compared
- Best AI Models Leaderboard: April 2026 Update — Full Rankings & Benchmarks
- Every AI Model Compared: Best One Per Task (2026) — Claude, GPT-5.4, Gemini, DeepSeek
- Kimi Code K2.6 Preview: What Developers Need to Know (2026)
- Best AI Models for Frontend UI Development 2026: Kimi K2.5, GLM-5, Qwen 3.6 Ranked
References
- OpenAI — Introducing GPT-5.5:
- Anthropic — Introducing Claude Opus 4.7:
- Anthropic — What's New in Claude Opus 4.7 (API Docs):
- Meta AI — The Llama 4 Herd: Natively Multimodal AI:
- O-mega.ai — GPT-5.5 Complete Guide 2026:
- Vellum — Claude Opus 4.7 Benchmarks Explained:
- FutureAGI — Best LLMs May 2026:
- LLM Stats — Live Model Leaderboard (300+ models):
- Iternal.ai — LLM Selection Guide 2026 (30+ models ranked):
- TechCrunch — OpenAI Releases GPT-5.5, Bringing Company Closer to Super App:
- Codersera — Open Source LLM Landscape 2026 (DeepSeek V4 vs Llama 4 vs Qwen 3.5):
- AkitaOnRails — LLM Coding Benchmark May 2026 (24 Models Ranked):

