





Gemini 3.1 Flash TTS: Google's Most Controllable AI Voice Model
Google just redefined what developers can expect from a text-to-speech model. On April 15, 2026, Google DeepMind launched Gemini 3.1 Flash TTS - not another robot-voice API, but a genuinely expressive, direction-based speech engine that lets you write stage directions for your AI narrator. The question isn't whether this changes the TTS market. It does. The question is whether it changes it enough to unseat ElevenLabs as the default choice for serious audio applications.
This guide covers everything: what the model actually does, how audio tags work in practice, benchmark positioning, access options, pricing implications, and an honest comparison against the top competitors.
1. What is Gemini 3.1 Flash TTS?
Gemini 3.1 Flash TTS is Google DeepMind's most advanced text-to-speech model to date, launched in public preview on April 15, 2026. It converts text into high-fidelity spoken audio and - crucially - lets you direct that speech the same way a film director instructs an actor: with scene context, emotional cues, pacing commands, and style instructions embedded directly inside the text prompt.
The model is accessed via the Gemini API using the model ID gemini-3.1-flash-tts-preview. Unlike traditional TTS APIs that accept raw text and output robotic speech, Gemini 3.1 Flash TTS accepts structured prompt-style inputs that define speaker personality, environment, emotional arc, and line-by-line delivery.
This isn't a small increment on 2.5 Flash TTS. Google has repositioned TTS away from 'text conversion' entirely and toward 'AI vocal performance.' Whether that framing translates into real production value is what the rest of this article will show you.
If you want broader context on where this fits in Google's 2026 AI stack, the Best AI Models April 2026 benchmark guide covers Gemini 3.1 Pro, Flash, and the full family side by side with independent benchmark data.
2. Audio Tags: The Feature That Changes Everything
The single biggest differentiator in Gemini 3.1 Flash TTS is audio tags - natural language commands embedded directly inside the text you send to the model. Using square bracket syntax, you can control exactly how the model delivers each line, right down to the syllable.
How Audio Tags Work
The formula is: [pacing tag] + spoken text + [expressive tag] + more spoken text + [pause tag] + spoken text.
Every tag must be enclosed in square brackets. Tags must be separated by text or punctuation - you cannot place two
tags directly adjacent to each other. All tags are written in English, even if the spoken text is in another language.
[excited] This is the biggest launch of the quarter!
[whispers] Don't tell anyone I said this.
[cautious] L'ombre avança lentement dans la pièce silencieuse.
[long pause] And then - silence.
[British RP] Good evening, and welcome to the programme.
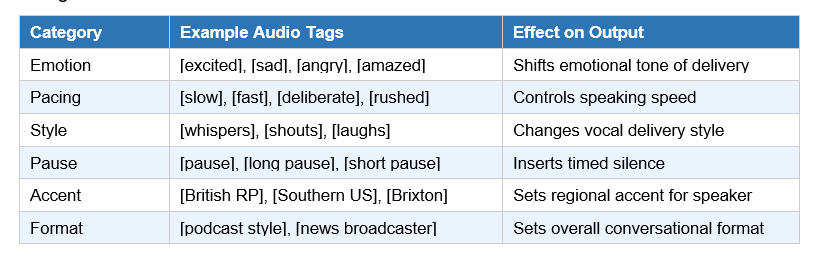
Audio Tag Categories
Gemini 3.1 Flash TTS supports 200+ audio tags, organized across these key categories:
Director-Level Controls in AI Studio
Beyond inline tags, Google AI Studio gives developers a 'director's chair' interface with three additional control layers. Scene direction lets you write a full narrative context - defining the studio environment, the speaker's physical state, and dialogue stakes. Speaker-level controls let you assign specific voices, accents, and personality profiles to different characters. Format templates let you pre-configure the entire output as a podcast conversation, audiobook narrator, news broadcast, language tutor, or voice assistant style - and then export those settings as API-ready code.
3. Benchmark Performance - Elo 1,211 and What It Means
On the Artificial Analysis TTS leaderboard - a benchmark built on thousands of blind human preference votes - Gemini 3.1 Flash TTS scored an Elo of 1,211, placing it second overall as of April 15, 2026. ElevenLabs holds the top position. Every other major TTS provider, including OpenAI and Amazon Polly, ranks below Gemini 3.1 Flash TTS on this human-preference metric.
More significantly, Artificial Analysis placed Gemini 3.1 Flash TTS in its 'most attractive quadrant' - the zone where high-quality speech output meets low cost-per-request. That's the metric that actually matters for production systems, not just lab benchmarks.
My take: An Elo of 1,211 from 1,700 human votes is genuinely impressive for a first-preview release. For comparison, see how Google's multimodal approach extends to the Gemini Embedding 2 multimodal model - the strategy of building unified AI outputs across modalities is clearly a deliberate Google architecture decision, not a one-off product launch.
Hot take: The benchmark matters less than the API design. A model with an Elo of 1,200 and 200 audio tags beats a model with an Elo of 1,280 and no tags, because the lower-rated model gives you directorial control. The ranking ceiling may be lower today, but the capability floor is much higher.
4. Language & Accent Support: 70+ Languages Explained
Gemini 3.1 Flash TTS supports 70+ languages, of which 24 are designated as high-quality evaluated languages. These 24 include Japanese, Hindi, Arabic, German, French, Spanish, Portuguese, and more - languages covering the majority of global digital commerce.
The accent system is one of the more technically interesting elements of this release. Rather than tying accent to the language setting (which previous TTS APIs did), Gemini 3.1 Flash TTS treats accent as a style prompt. You trigger accent through the tag system, not by selecting a language code. This means you can write English text and instruct the model to deliver it with a Transatlantic accent, a Southern US cadence, or a Brixton (South London) tone - all within the same API call.
Available English accents include American Valley, American Southern, British RP, British Brixton, and Transatlantic. This level of accent granularity has not been available in any Google TTS product before.
For developers building globally distributed applications, this complements the broader Gemini ecosystem. Google AI Studio's vibe coding platform explored in this Google AI Studio vibe coding full guide already supports multilingual output - TTS now makes voice-first, multilingual experiences equally accessible.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Multi-Speaker Dialogue: Why Native Matters
Traditional TTS pipelines require separate API calls for each speaker in a multi-character dialogue. This creates disjointed pacing - the audio equivalent of bad video editing cuts. Each voice gets its own response latency, its own call overhead, and there is no shared conversational context between characters.
Gemini 3.1 Flash TTS handles multi-speaker dialogue natively. You define multiple speakers inside a single prompt, assign individual voice profiles, personality traits, and emotional arcs to each, and the model maintains their 'in-character' consistency across turns. The result is more natural conversational flow - characters actually react to each other, not to their isolated text snippets.
The use cases here are concrete: podcast generation, audiobook narration with multiple characters, interactive voice assistants with distinct agent personalities, and dramatic scripts for gaming or entertainment. For any application that needed two or more distinct voices, native multi-speaker eliminates a significant engineering workaround.
6. How to Access Gemini 3.1 Flash TTS
Gemini 3.1 Flash TTS launched in public preview across four access paths on April 15, 2026:
Google AI Studio
The fastest path. Go to aistudio.google.com, select the Audio Playground, and choose gemini-3.1-flash-tts-preview as your model. No code required. Ideal for testing audio tags, exporting API configurations, and prototyping voice designs before production deployment.
Gemini API
Model ID: gemini-3.1-flash-tts-preview. Accessible via the google-genai Python SDK. Unlike standard Gemini API calls that return text, the TTS endpoint returns audio file output only. Structure your prompt with scene direction at the top, speaker profiles below, and tagged dialogue as the main content block.
Vertex AI
Enterprise-grade deployment with Google Cloud's security, IAM, audit logging, and scalability guarantees. Vertex AI is the recommended path for any production workload exceeding prototype volume, for regulated industries, and for teams that need HIPAA or SOC 2 compliance on their audio pipeline.
Google Vids
Consumer and Workspace access. Google Vids (part of Google Workspace) integrates Gemini 3.1 Flash TTS for users creating AI-narrated video content without API access. This makes the model accessible to non-developers inside enterprise Workspace subscriptions.
For teams already running Gemini in productivity tools, the Gemini in Google Workspace features guide explains how Gemini integrations work across Gmail, Docs, Slides, and Meet - context that helps you understand where TTS fits in the broader Workspace AI stack.
Quick-Start Code Snippet
The following illustrates the basic structure of a Gemini 3.1 Flash TTS API call (Python):
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-tts-preview",
contents="[excited] Welcome to the show! [pause] Tonight we cover..."
)If you want hands-on experience with Google's open AI models before committing to the Gemini API, the Gemma 4 hands-on cookbook gets you from zero to inference with Google's open-weight model in under 10 minutes - a fast way to understand the Google AI SDK before wiring up TTS.
7. SynthID Watermarking: Google's AI Audio Safety Play
Every audio file generated by Gemini 3.1 Flash TTS is embedded with a SynthID watermark. SynthID is Google's imperceptible AI-content tagging system - listeners cannot detect the watermark, but Google's detection tools can reliably identify any audio clip as AI-generated.
The design has two stated priorities: imperceptibility (the watermark does not degrade the listening experience) and reliable detection (it enables identification of AI-generated content to help prevent misinformation).
In the context of the 2026 AI landscape, where AI-generated audio is increasingly used in political content, scam calls, and synthetic media, SynthID watermarking is more than a compliance checkbox. It's the infrastructure layer that lets responsible developers say: every audio file our application produces is traceable.
My take: Mandatory watermarking will eventually be a regulatory requirement, not just a responsible-AI best practice. Google building it in at the model level - rather than leaving it to developer implementation - is the right architectural decision. It also puts pressure on competitors who don't yet have equivalent systems.
8. Gemini TTS vs ElevenLabs, OpenAI, Azure - Full Comparison
![from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-tts-preview",
contents="[excited] Welcome to the show! [pause] Tonight we cover..."
)](https://oukdqujzonxvqhiefdsv.supabase.co/storage/v1/object/public/blogs/gemini-3-1-flash-tts-google-ai-voice-model/1776321794900.png)
The table tells most of the story, but a few points need honest color commentary:
• ElevenLabs holds the #1 Elo position and has a more mature voice-cloning ecosystem. If your use case requires voice cloning from a sample, ElevenLabs is still the technical leader.
• OpenAI TTS-4o is deeply integrated with the GPT ecosystem. If you're already running GPT-5.4 for content generation, OpenAI TTS reduces your integration surface area.
• Azure Neural TTS has 140+ languages and SSML support - but SSML is XML-based markup, not the natural language audio tags Gemini introduces. The developer experience gap is real.
• Amazon Polly is the legacy enterprise option: reliable, broadly supported, but without any of the expressive control that defines the 2026 generation of TTS.
• Gemini 3.1 Flash TTS wins on: audio tag granularity, native multi-speaker dialogue, Artificial Analysis 'most attractive quadrant' positioning, and Google ecosystem integration.
For developers building AI audio alongside AI video, Google's full generative media stack is worth understanding. The Google Veo 3.1 AI video generation review covers the video side of the same infrastructure - and both TTS and video generation are now available in Google Vids for Workspace users.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
9. My Honest Take: Where Gemini TTS Wins (and Where It Doesn't)
Where Gemini 3.1 Flash TTS wins:
• Narrative and creative audio - podcasts, audiobooks, dramatic scripts, gaming dialogue
• Multi-character applications where native speaker switching eliminates engineering complexity
• Global deployment across 70+ languages with granular accent control
• Google Workspace integrations - teams already in the Workspace ecosystem get TTS inside Google Vids
• Developer experience - the Audio Playground in AI Studio with code export is genuinely well-built
Where it still lags:
• Voice cloning from user-provided samples - ElevenLabs still leads here
• Preview status means production SLAs aren't guaranteed - not ready for high-stakes real-time enterprise voice yet
• Some developers reported tricky access during the initial rollout hours -typical for preview launches
• Audio tags are English-only for the tags themselves, even when the spoken text is in another language - a minor but real constraint for non-English teams
Contrarian point: The 'most controllable TTS model yet' framing is accurate but slightly misleading. Control requires investment - you have to write detailed prompts, scene directions, and speaker profiles. If you just want clean, simple narration from plain text, OpenAI TTS-4o or even Google's own older TTS products are less friction for that use case. Gemini 3.1 Flash TTS is for builders who want a vocal performance, not just audio output.
Frequently Asked Questions
What is Gemini 3.1 Flash TTS?
Gemini 3.1 Flash TTS is Google DeepMind's newest text-to-speech model, launched April 15, 2026. It converts text to natural, expressive speech using audio tags - natural language commands in square brackets that control vocal style, pacing, and delivery. It supports 70+ languages, 30 distinct voices, and native multi-speaker dialogue.
How do audio tags work in Gemini 3.1 Flash TTS?
Audio tags are square-bracket commands embedded directly in the text you send to the model. Example: [excited] Welcome to our biggest event! [pause] The results are in. Tags must be separated by text or punctuation, never placed adjacent to each other. Over 200 audio tags are available, spanning emotions, pacing, accent styles, and format templates.
Is Gemini 3.1 Flash TTS free to use?
Gemini 3.1 Flash TTS is currently in public preview via Google AI Studio, the Gemini API, and Vertex AI. Google AI Studio provides free-tier access for prototyping. Production and enterprise-scale usage via Vertex AI is subject to Google Cloud pricing. Check the official Vertex AI pricing page for current rates, as preview pricing may differ from GA pricing.
What is the model ID for Gemini 3.1 Flash TTS in the API?
The model ID is gemini-3.1-flash-tts-preview. Access it via the google-genai Python SDK or the Gemini REST API. Note that this model outputs audio files only - it does not return text responses.
How does Gemini 3.1 Flash TTS compare to ElevenLabs?
ElevenLabs ranks #1 on the Artificial Analysis TTS leaderboard (Elo ~1,280), while Gemini 3.1 Flash TTS is #2 (Elo 1,211). ElevenLabs has a stronger voice-cloning feature set. Gemini wins on audio tag granularity (200+ tags vs limited controls), native multi-speaker dialogue, language breadth (70+ vs ~32), and Google ecosystem integration.
What is SynthID watermarking?
SynthID is Google's imperceptible AI-content watermarking system. All audio generated by Gemini 3.1 Flash TTS contains a SynthID watermark embedded in the audio waveform - listeners cannot detect it, but Google's tools can reliably identify the audio as AI-generated. This helps prevent misuse and supports responsible AI transparency.
Can Gemini 3.1 Flash TTS handle multi-speaker conversations?
Yes. Gemini 3.1 Flash TTS supports native multi-speaker dialogue in a single API call. You define each speaker's voice profile, personality, and emotional arc inside the prompt. The model maintains each character's consistency across turns, producing natural conversational flow without the disjointed pacing caused by separate API calls per speaker.
Which languages are supported at the highest quality?
24 of the 70+ supported languages are designated as high-quality evaluated languages. These include Japanese, Hindi, Arabic, German, French, Spanish, Portuguese, Korean, Chinese (Simplified), Italian, and others covering major global markets. The remaining languages are supported but may have lower quality evaluations.
Related Cookbooks & Resources
• Gemma 4 Hands-On Cookbook - Google AI model from zero to inference in 10 minutes
• Kimi K2.5 Cookbook (OpenRouter) - Multi-modal API tutorial with voice context
• Qwen 3.6 Plus Cookbook - Open-weight multilingual model comparison notebook
Recommended Blogs
• How to Use Lyria 3 by Google: Free Access and Pricing (2026)
• Gemini Embedding 2: First Multimodal Embedding Model (2026)
• Google Veo 3.1 Review (2026): Lite vs Fast, Pricing, Prompts & API Guide
• Gemini in Google Workspace: Every Feature Explained (2026)
• Gemini 3.1 Flash Lite vs 2.5 Flash: Speed, Cost & Benchmarks (2026)
References
- Google DeepMind - Gemini 3.1 Flash TTS launch blog:
- Google Cloud Blog - Gemini 3.1 Flash TTS on Vertex AI:
- MarkTechPost - Gemini 3.1 Flash TTS analysis:
- SiliconANGLE - Gemini 3.1 Flash TTS feature coverage:
- Simon Willison - Gemini 3.1 Flash TTS developer notes:
- Artificial Analysis TTS Leaderboard:
- Google AI Studio Audio Playground:
- Vertex AI - Gemini 3.1 Flash TTS docs:

