




Three separate AI models. One morning. Gone.
On April 29, 2026, Mistral shipped Medium 3.5 and quietly retired Magistral (their reasoning model), Devstral 2 (their coding model), and Medium 3.1 (their chat model). Three product lines folded into a single 128B dense model with a reasoning toggle. That is the actual story. Not the benchmark number, not the lobster emoji, not the pricing math (though I will get to all of that). The story is that Mistral just ran the same consolidation play that OpenAI ran with GPT-5.5 and Anthropic ran with Opus 4.7, and they did it with open weights.
I think that last part changes the calculus for a lot of teams. Here is the honest breakdown.
What Is Mistral Medium 3.5?
Mistral Medium 3.5 is a dense 128B parameter model released on April 29, 2026, that handles instruction-following, reasoning, and coding in a single set of weights. It replaces three previously separate Mistral models: Medium 3.1, Magistral, and Devstral 2.
The word "dense" is doing real work in that sentence. Most frontier labs in 2026 have been building Mixture-of-Experts (MoE) models, where only a fraction of parameters activate per token. DeepSeek V4 activates 49B of 1.6T parameters. Qwen 3.6 activates 3B of 35B. That sparsity is what makes those models cheap to serve at scale. Mistral went the other direction: all 128B parameters are active on every single forward pass. That is a conservative architectural bet, and Mistral's reasoning for it is straightforward. Dense models are more predictable in output quality and simpler to evaluate, fine-tune, and deploy. If you are running a production workload and need consistent behavior, dense wins on predictability.
Key specs at a glance:
- Parameters: 128B dense (all active per token)
- Context window: 256K tokens (larger than Claude Sonnet 4.6 at 200K, twice GPT-4o at 128K)
- Multimodal: text + image input, text output; vision encoder trained from scratch
- Reasoning: configurable per request via reasoning_effort parameter
- Release date: April 29, 2026
- License: Modified MIT (commercial use allowed; high-revenue enterprises must use Mistral's paid channel)
If you are building AI pipelines and still deciding which model tier fits your use case, the every AI model compared by task guide has the clearest breakdown I have seen for matching model to workflow.
The configurable reasoning is genuinely useful. You can send a quick chat message at low reasoning_effort and get a fast answer, then switch the same model to high reasoning_effort for a complex debugging task. One deployment, two modes, no model routing. That is what the three-in-one consolidation actually buys you in practice.
The Benchmark Reality: 77.6% and What It Actually Means
Mistral Medium 3.5 scores 77.6% on SWE-Bench Verified, the standard benchmark for resolving real GitHub issues across popular open-source repositories. That is the headline number, and it needs context before you do anything with it.
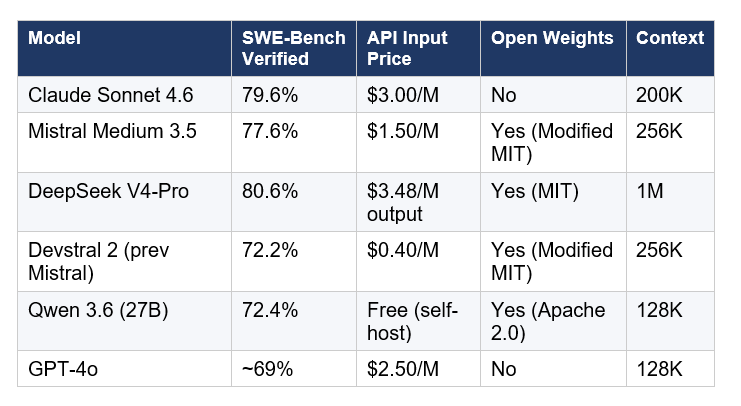
Three things jump out of that table.
First, Medium 3.5 is not the benchmark leader. Claude Sonnet 4.6 beats it by 2 points and DeepSeek V4-Pro beats it by 3 points. A UW professor named Pedro Domingos put this bluntly on social media: "Regular AI companies brag about how much better their model is on benchmarks. Only Mistral brags about how much worse its one is." I think that is a little unfair, but it is not wrong. Mistral is not claiming #1.
Second, the price gap is significant. At $1.50 per million input tokens versus Sonnet's $3.00, you are getting coding performance within 2 points of the best closed-source option at half the cost. For teams with meaningful inference volume, that is a real number.
Third, the uncomfortable comparison is Qwen 3.6. It is a 27B MoE model (Apache 2.0 license, free to self-host), scores 72.4%, and the weights are available with zero licensing friction. If you need self-hosted and cost is the constraint, Qwen 3.6 at 5 points below Medium 3.5 on SWE-Bench is a genuinely hard argument to dismiss. I will be honest: if I were running a startup on a tight budget with no European data residency requirements, I would test Qwen 3.6 before defaulting to Medium 3.5.
Medium 3.5 also scores 91.4% on the tau-cubed-Telecom agentic benchmark, which tests multi-step tool use in specialized environments. That is a strong number and suggests the model is well-suited for the agent workflows that Vibe is built around.
For the full picture of where Medium 3.5 sits in the current open-weight landscape, the best AI models May 2026 leaderboard has every major model ranked with independent benchmark citations.
Vibe Remote Agents: The Feature Nobody Is Talking About Enough
Vibe remote agents are the most interesting thing Mistral shipped on April 29, and they are getting less coverage than the model itself. The shift is simple: coding sessions used to run on your laptop. Now they run in the cloud, in parallel, while you are away from the terminal.
Here is the practical workflow. You start a task from the Vibe CLI:
vibe remote start --task "Add pagination to the /users endpoint"
The agent runs in an isolated cloud sandbox. You can start several of these in parallel. Each one has access to file diffs, tool call logs, and progress states you can inspect at any time. When the work is done, the agent opens a pull request on GitHub and notifies you. You review the result instead of watching every step it takes.
Session teleportation is the detail that makes this practical rather than just impressive on paper. If you already have a local Vibe session running, you can move it to the cloud mid-task without losing session history, task state, or pending approvals. You do not abandon the work in progress. You just move it off your machine.
The integration list is solid: GitHub for code and pull requests, Linear and Jira for issues, Sentry for incidents, Slack and Teams for reporting. These are not toy integrations. Mistral built this for their own in-house development environment first, then shipped it to enterprise customers, and is now opening it to everyone on Pro, Team, and Enterprise Le Chat plans.
- Module refactors across multiple files
- Test generation for existing code
- Dependency upgrades with CI checks
- Bug fixes from Sentry incident data
- CI failure investigation and resolution
If you are new to agentic coding workflows and want the conceptual foundation before jumping into Vibe, the Building Smart AI Agents guide explains the ReAct reasoning loop that underpins how tools like Vibe execute multi-step tasks.
My honest assessment: Vibe is now a direct competitor to Claude Code. Not on raw benchmark scores, Medium 3.5 trails Sonnet 4.6 there, but on the workflow. A cloud-native, async, PR-generating coding agent at half the per-token cost with open weights is a serious value proposition for teams that can live with 2 benchmark points below the current closed-source leader.
Le Chat Work Mode: Mistral's Answer to ChatGPT Agents
Le Chat Work Mode is a new agentic chat interface in Mistral's consumer product, Le Chat, released as a preview alongside Medium 3.5 on April 29. It is the non-developer entry point to everything Medium 3.5 enables.
Work Mode flips the default connector behavior. In a standard chat session, you manually choose which tools to connect for each conversation. In Work Mode, connectors are on by default. The agent reaches into your email, calendar, documents, and connected apps automatically, because it needs that context to do the work correctly.
Three workflow categories Mistral highlights:
- Cross-tool catch-ups: process email, calendar, and messages in a single session; prepare meeting briefs with attendee context, recent news, and talking points
- Research and synthesis: pull from the web, internal docs, and connected tools; produce a structured brief you can edit before exporting or sending
- Team coordination: triage inbox, create Jira issues from customer discussions, post summaries to Slack
Transparency is built in by design. Every tool call and the agent's reasoning rationale is visible. Work Mode asks for explicit approval before taking sensitive actions, such as sending a message, writing a document, or modifying data. That approval gate matters more than people realize. An agent that can reach into your inbox and draft replies is genuinely useful. An agent that sends those replies without your sign-off is an incident waiting to happen.
I think Work Mode is Mistral's clearest move against ChatGPT's Agents product and Anthropic's Projects feature. The differentiation is the EU angle. Mistral is a Paris-based company. They borrowed 830 million euros to build a 13,800-GPU data center outside Paris. For teams with European data residency requirements, a capable agentic chat product from a European lab with on-prem options is not just a feature, it is a procurement unlocker.
If you are evaluating whether an agentic workflow like Work Mode makes sense for your team, the build your first AI agent and automation guide walks through the exact kind of multi-step automation flows that Work Mode automates at the chat layer.
Pricing and Licensing: The Honest Math
Mistral Medium 3.5 costs $1.50 per million input tokens and $7.50 per million output tokens through the Mistral API. That is exactly half the input cost of Claude Sonnet 4.6 ($3.00/$15.00) and 40% cheaper on input than GPT-4o ($2.50/$10.00).
For subscription access: Le Chat Pro at $14.99 per month includes Vibe CLI with Medium 3.5. Le Chat Team is $24.99 per seat per month. Both plans include Work Mode access.
The licensing is the part that requires careful reading. Medium 3.5 ships under a Modified MIT license. Commercial use is permitted. You can download the weights, modify them, and build products on top. The carve-out: high-revenue companies above a certain revenue threshold must use Mistral's paid API channel rather than self-hosting freely. Mistral has not published the exact threshold publicly, but this is the same pattern they used with Devstral 2 and is consistent with how European AI labs are trying to capture commercial value while staying technically open.
For self-hosting: at Q4 quantization, Medium 3.5 fits in approximately 70GB of VRAM, runnable on 4 H100-class GPUs or a Mac Studio with 128GB of unified memory. Mistral also released an EAGLE speculative decoding draft head (Mistral-Medium-3.5-128B-EAGLE) for latency-bound single-user inference. NVIDIA NIM containers are available for enterprise deployment.
For a direct comparison of where Medium 3.5 sits against the current open-weight leaderboard including GLM-5.1, Qwen 3.6, and DeepSeek V4, the DeepSeek V4-Pro full review and pricing analysis has the detailed cost math for production-scale workloads.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Who Should Actually Use Mistral Medium 3.5?
The honest answer to "should I use Medium 3.5" depends on exactly one question: do open weights matter to you?
Use Medium 3.5 if:
- You need open weights and a self-hostable model at near-frontier coding performance (77.6% SWE-Bench is within 2 points of the current best closed model)
- You have European data residency requirements — Mistral is the only frontier-capable EU-based lab with open weights
- You want to consolidate your model routing stack. If you were already using Magistral for reasoning and Devstral 2 for coding, Medium 3.5 replaces both with a toggle
- You are running Vibe CLI and want the best supported model for async cloud coding agents with GitHub integration
- You need a 256K context window for large codebase ingestion — bigger than Sonnet and twice GPT-4o
Look elsewhere if:
- You need the absolute highest coding benchmark score and API-only is fine — Claude Sonnet 4.6 at 79.6% still leads and DeepSeek V4-Pro at 80.6% is MIT-licensed
- You are cost-constrained and open weights matter more than the top tier — Qwen 3.6 at Apache 2.0 is free to self-host at 72.4% SWE-Bench, a 5-point gap for significantly lower cost
- You are building on OpenAI's or Anthropic's native tooling ecosystem — the integrations, fine-tuning pipelines, and safety features are more mature
I already covered how the Chinese open-source models, specifically GLM-5.1, Qwen 3.6, and Kimi K2.5, stack up as alternatives in the best Chinese AI models for coding 2026 comparison — worth reading before you commit to the Medium 3.5 pricing tier.
The context window deserves a separate mention. 256K tokens is enough to ingest a full mid-sized codebase, its documentation, its test suite, and your full conversation history in a single prompt. For teams doing repository-level analysis, that extra context depth over Sonnet's 200K and GPT-4o's 128K is a real workflow difference, not just a spec sheet number.
Frequently Asked Questions
What is Mistral Medium 3.5?
Mistral Medium 3.5 is a 128B dense open-weight language model released by Mistral AI on April 29, 2026. It replaces three prior Mistral models (Medium 3.1, Magistral, and Devstral 2) in a single unified set of weights with configurable reasoning effort per request. The model scores 77.6% on SWE-Bench Verified and 91.4% on the tau-cubed-Telecom agentic benchmark, and is available on Hugging Face under a Modified MIT license.
How does Mistral Medium 3.5 compare to Claude Sonnet 4.6?
Claude Sonnet 4.6 scores 79.6% on SWE-Bench Verified versus Medium 3.5's 77.6%, a 2-point gap. Sonnet costs $3.00 per million input tokens versus Medium 3.5's $1.50, twice the price. Sonnet has a 200K context window; Medium 3.5 has 256K. Sonnet is closed-source and API-only; Medium 3.5 has open weights you can self-host on 4 GPUs. If you need the highest benchmark number and API-only works for you, Sonnet leads. If open weights or lower cost matter, Medium 3.5 is the stronger case.
Is Mistral Medium 3.5 open source?
Medium 3.5 is open-weight under a Modified MIT license, meaning the model weights are freely downloadable and commercially usable. High-revenue enterprises above an unpublished threshold must use Mistral's paid API channel rather than self-hosting freely. This is sometimes called "open weights" rather than strictly open source, since the full training data and pipeline are not published. The weights are available on Hugging Face at mistralai/Mistral-Medium-3.5-128B.
How many GPUs does Mistral Medium 3.5 need to run?
Mistral states Medium 3.5 is self-hostable on as few as 4 GPUs. At Q4 quantization, the model fits in approximately 70GB of VRAM, which is achievable on 4 H100-class GPUs or a Mac Studio with 128GB of unified memory. For production serving, Mistral recommends vLLM or SGLang with tensor parallelism of 8. NVIDIA NIM containers are available for enterprise deployments.
What is Mistral Vibe and how do remote agents work?
Mistral Vibe is a cloud coding agent platform available via CLI and Le Chat. Remote agents, launched with Medium 3.5 on April 29, 2026, run coding sessions in the cloud rather than on your local machine. You start a session with vibe remote start --task "description", the agent executes in an isolated sandbox, and when complete it opens a GitHub pull request and notifies you. Multiple sessions can run in parallel. Local sessions can be teleported to the cloud mid-task using the --remote flag, preserving session history and task state.
What is Le Chat Work Mode?
Le Chat Work Mode is an agentic chat mode in Mistral's Le Chat product, released as a preview on April 29, 2026. It is powered by Mistral Medium 3.5 and enables multi-step, cross-tool workflows: catching up on email and calendar, creating Jira issues from discussion threads, producing research briefs from web and internal sources, and posting team summaries to Slack. Connectors are enabled by default rather than manually chosen per session. Explicit approval is required before sensitive actions such as sending messages or modifying data.
How much does Mistral Medium 3.5 cost via API?
Mistral Medium 3.5 is priced at $1.50 per million input tokens and $7.50 per million output tokens through the Mistral API (console.mistral.ai). For subscription access, Le Chat Pro costs $14.99 per month and includes Vibe CLI with Medium 3.5 access. Le Chat Team costs $24.99 per seat per month. The model weights are free to download from Hugging Face for eligible users under the Modified MIT license; infrastructure costs for self-hosting (GPU compute) apply separately.
What replaced Magistral and Devstral 2?
Both are replaced by Mistral Medium 3.5. Magistral was Mistral's dedicated reasoning model; Devstral 2 was their dedicated coding agent model at 72.2% SWE-Bench Verified. Medium 3.5 handles both use cases through a configurable reasoning_effort parameter per API request. Setting reasoning_effort to none delivers fast responses for chat tasks; setting it to high enables extended chain-of-thought for complex coding, debugging, and multi-step planning.
Recommended Blogs
These are real posts on buildfastwithai.com that go deeper on the topics covered here:
- Best AI Models: April + May 2026 Leaderboard — where Medium 3.5 ranks against every major model
- DeepSeek V4-Pro Review 2026 — the MIT-licensed open-weight model that beats Medium 3.5 on SWE-Bench
- Qwen vs GLM vs Kimi: Best Chinese AI for Coding 2026 — the free and near-free open-weight alternatives
- Best AI Models April 2026: Ranked by Benchmarks — full benchmark context for the open-source coding landscape
- Building Smart AI Agents — the ReAct loop and tool-use patterns that power coding agents like Vibe
- Build Your First AI Agent and Automation — beginner guide to agentic workflows and task automation
References
- Mistral AI — Remote Agents in Vibe, Powered by Mistral Medium 3.5 (Official Announcement)
- Hugging Face — mistralai/Mistral-Medium-3.5-128B Model Card
- MarkTechPost — Mistral AI Launches Remote Agents in Vibe and Mistral Medium 3.5 with 77.6% SWE-Bench Verified
- The Decoder — Mistral's New Flagship Medium 3.5 Folds Chat, Reasoning, and Code Into One Model
- Nerd Level Tech — Mistral Medium 3.5: 128B Open-Weight Frontier Coder (Benchmarks + Architecture)
- DEV Community — Mistral Medium 3.5 Review: A 128B Open-Weight Model With a Coding Agent That Opens PRs
- BenchLM.ai — Claude Sonnet 4.5 vs Mistral Medium 3.5 128B: AI Benchmark Comparison 2026
- Lushbinary — Mistral Medium 3.5 vs Claude Sonnet 4 vs GPT-4o Compared

